【Python】Numpy数组的切片、索引详解:取数组的特定行列
文章目录
- 【Python】Numpy数组的切片、索引详解:取数组的特定行列
- 1. 介绍
- 2. 切片索引
- 2.1 切片索引先验知识
- 2.1 一维数组的切片索引
- 2.3 多维数组的切片索引
- 3. 数组索引(副本)
- 3.1 一维数组的数组索引
- 3.2 多维数组的数组索引
- 3.2.1 对于索引数组数量小于被索引数组维度的情况
- 3.2.2 红色标记的元素为待索引元素,对应结果数组分别为一维和二维数组c, d:
- 3.2.3 需索引数组的指定行列(红色标记位置),对应结果数组为二维数组e:(这个比较重要感觉)
- 3.2.4 通过扩展可知,对于三维数组
- 3.3 如何选取数组的特定行列
- 3.3.1 函数ix_()快速索引指定行列
- 4. 切片和数组的组合索引(副本)
- 5. 布尔数组索引
- 6. 结构化索引工具
- 7. 利用索引给数组赋值
- 8. 参考
1. 介绍
Numpy的数组除了可使用内置序列的索引方式之外,提供了更多的索引能力。
- 如通过切片、整数数组和布尔数组等方式进行索引。
这使得Numpy索引功能很强大,但同时也带来了一些复杂性和混乱性,尤其是多维索引数组。
- Numpy数组的切片索引,不会复制内部数组数据,仅创建原始数据的新视图,以引用方式访问数据。
- 而使用数组索引进行索引时,返回数据副本,而不是创建视图。索引可避免在数组中循环各元素,从而大大提高了性能。
2. 切片索引
Numpy数组的切片索引,不会复制内部数组数据,仅创建原始数据的新视图,以引用方式访问数据。
- 切片索引适用于有规律的查找指定位置的元素(元素位置位于等差序列);
- 当切片的数量少于数组维度时,缺失的维度索引被认为是一个完整切片,省略、“:”、“…”三者等价;
2.1 切片索引先验知识
对于一维数组来说,python原生的list和numpy的array的切片操作都是相同的,记住一个规则
arr[start: end: step]
下面是几个特殊的例子:
- [:] 表示复制源列表。
- 负的index表示,从后往前。-1表示最后一个元素。
import numpy as np
data = np.arange(20).reshape(4,5)
#array([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]])
data[1,:] #data[i,:] 获取第i行元素 同理data[:,i] 获取第i列元素
#array([5, 6, 7, 8, 9])
data[:,-3:] #获取所有的行中倒数第三个到最后的元素
#array([[ 2, 3, 4],
# [ 7, 8, 9],
# [12, 13, 14],
# [17, 18, 19]])
data[:,:3] #获取所有的行中从0到2的元素(注意时左闭右开)
#array([[ 0, 1, 2],
# [ 5, 6, 7],
# [10, 11, 12],
# [15, 16, 17]])
#取一个数据块
data[0:2,0:3] # 注意,时左闭右开原则
#array([[0, 1, 2],
# [5, 6, 7]])
2.1 一维数组的切片索引
>>> a = np.arange(16)
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
>>> a[::-1] # 逆序
array([15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
>>> a[...] # 索引全部元素,与a[:]等价
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
>>> a[2:6:2] # 索引位置2,4的两个元素, 从2到6(不包括6),步长为2
array([2, 4])
2.3 多维数组的切片索引
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> b[:, ::-1] # 轴2逆序,即列逆序
array([[ 3, 2, 1, 0],
[ 7, 6, 5, 4],
[11, 10, 9, 8],
[15, 14, 13, 12]])
>>> b[1:3] # 轴1位置0,1,即第1,2行
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> b[1:3, :4:2] # 第1,2行,第0,2列
array([[ 4, 6],
[ 8, 10]])
>>> c = np.arange(24).reshape(2,3,4)
>>> c
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
>>> c[:, 0, :2]
array([[ 0, 1],
[12, 13]])
3. 数组索引(副本)
Numpy的数组索引,返回数据副本,而不是创建视图。相比切片索引,整数数组的索引更具有通用性,因为其不要求索引值具有特定规律。
- 对于索引数组中未建立索引的维度(索引数组中的索引集数目小于被索引数组维度),默认被全部索引;
- 索引结果数组的形状由索引数组的形状与被索引数组中所有未索引的维的形状串联组成,也就是说,若对数组的所有维度建立索引,则索引数组的形状等于结果数组的形状;
- 若索引数组具有匹配的形状,即索引数组个数(索引集数)等于被索引数组的维度,此时结果数组与索引数组具有相同形状,且这些结果值对应于各维索引集的索引在索引数组中的位置;
3.1 一维数组的数组索引
>>> a = np.arange(16)
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
>>>a[[0,1]] # 第0,1位置的元素,结果数组维度为1,与a[[[0,1]]]等价
array([0, 1])
>>> a[np.array([[0,1]])] # 第0,1位置的元素,结果数组1*2,与a[[[[0,1]]]]等价
array([[0, 1]])
>>> a[np.array([[0,1], [2,3]])] # 第0,1,2,3位置的4个元素,结果数组2*2
array([[0, 1],
[2, 3]])
3.2 多维数组的数组索引
由于二维数组的整数索引用途广泛,在此做详细介绍。被索引的二维数组/矩阵b,如下:
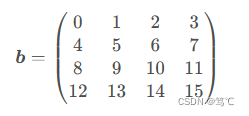
3.2.1 对于索引数组数量小于被索引数组维度的情况
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> b[[1,3]] # 轴2缺省(长度为4),被索引全部,索引数组一维长度为2,结果数组二维2*4
array([[ 4, 5, 6, 7],
[12, 13, 14, 15]])
>>> b[np.array([[0,1], [0,2]])] # 轴2缺省(长度为4),被索引全部,索引数组二维2*2,结果数组三维2*2*4
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]]])
3.2.2 红色标记的元素为待索引元素,对应结果数组分别为一维和二维数组c, d:
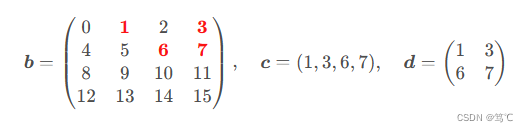
>>> c = b[[0,0,1,1], [1,3,2,3]] # 与结果数组同形,长度为4的一维数组
>>> c
array([1, 3, 6, 7])
>>> d = b[[[0,0],[1,1]], [[1,3],[2,3]]] # 与结果数组同形,2*2,等价于b[[[0],[1]], [[1,3],[2,3]]](广播)
>>> d
array([[1, 3],
[6, 7]])
3.2.3 需索引数组的指定行列(红色标记位置),对应结果数组为二维数组e:(这个比较重要感觉)
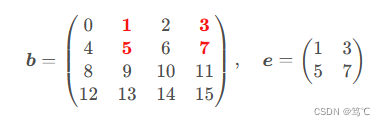
>>> i = [[0], [1]]
>>> j = [[1,3]]
>>> b[i, j] # b[[[0],[1]], [[1,3]]],等价于b[[[0,0], [1,1]], [[1,3], [1,3]]]
array([[1, 3],
[5, 7]])
上述结果反映了整数数组索引同样具有广播性质,即b[[[0,0], [1,1]], [[1,3], [1,3]]] 可简写为b[[[0], [1]], [[1,3]]]。
显然,用切片索引b[:2, 1::2]更容易实现上述结果,但切片索引要求被索引的行列顺序符合等差分布,不适用于无序的行列索引。
假设需要索引数组b bb的第0,2,3行的第0,1,3列,一种简单的想法是行列分开索引,即b[[0,2,3]][:, [0,1,3]]。显然结果正确。但此种索引方式效率低下,因为第一步索引创建了临时数组,第二步索引在新的临时数组中执行。
效率更高的实现是使用整数数组索引,即b[[[0],[2],[3]], [[0,1,3]]]:
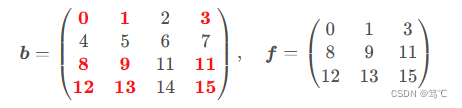
>>> b[[0,2,3]][:, [0,1,3]]
array([[ 0, 1, 3],
[ 8, 9, 11],
[12, 13, 15]])
>>> f = b[[[0],[2],[3]], [[0,1,3]]]
>>> f
array([[ 0, 1, 3],
[ 8, 9, 11],
[12, 13, 15]])
3.2.4 通过扩展可知,对于三维数组
>>> c = np.arange(24).reshape(2,3,4)
>>> c
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
>>> c[[0]]
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]]])
>>> c[[0],[0,1]]
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
>>> c[[0],[0,2],[2,3]]
array([ 2, 11])
>>> c[[[[0,0], [0,0]]], [[[0,0],[1,1]]], [[[0,1],[0,1]]]]
array([[[0, 1],
[4, 5]]])
>>> c[[[[0]]], [[[0],[1]]], [[[0,1]]]]
array([[[0, 1],
[4, 5]]])
>>> c[0, [[0],[1]], [0,1]] # 形状 1-2*1-1*2 -> 2*2
array([[0, 1],
[4, 5]])
3.3 如何选取数组的特定行列
通过上述例子发现,对于二维数组b,若索引数组的第0,1行的第1,3列,完整形式记作:b[[[0,0], [1,1]], [[1,3], [1,3]]],但通过利用整数数组索引的广播性质,简写为b[[[0],[1]], [[1,3]]]。
因此,若给定行号列表x=[0,2,3]和列号列表y=[0,13],建立二维数组索引的方法如下:
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> x = [0,2,3]
>>> y = [0,1,3]
>>> b[np.array([x]).T, [y]] # 等价于b[np.array([x]).T, y]
array([[ 0, 1, 3],
[ 8, 9, 11],
[12, 13, 15]])
3.3.1 函数ix_()快速索引指定行列
Numpy提供的函数ix_()可帮助我们更快地实现索引指定行列,如下:
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> i,j = np.ix_([0,2,3],[0,1,3])
>>> i
array([[0],
[2],
[3]])
>>> j
array([[0, 1, 3]])
>>> b[i,j]
array([[ 0, 1, 3],
[ 8, 9, 11],
[12, 13, 15]])
>>> c = np.arange(24).reshape(2,3,4)
>>> c
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
>>> i,j,z = np.ix_([0], [0,1], [0, 1])
>>> i
array([[[0]]])
>>> j
array([[[0],
[1]]])
>>> z
array([[[0, 1]]])
>>> c[i,j,z]
array([[[0, 1],
[4, 5]]])
4. 切片和数组的组合索引(副本)
整数数组索引可以和切片索引组合使用,实际上切片是被转换为索引数组,该数组与索引数组一起广播以产生结果数组。因此易知,使用组合索引,返回的是原数组数据的副本。
>>> b = np.arange(16).reshape(4,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> d = b[[0,1],:2]
>>> d
array([[0, 1],
[4, 5]])
>>> d[0,0] = 100 # 非引用,不改变被索引数组的数据
>>> d
array([[100, 1],
[ 4, 5]])
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
5. 布尔数组索引
当我们使用整数数组索引时,我们提供了要选择的索引列表。
- 而使用布尔值作为索引时,我们明确地选择数组中需要的元素。
布尔数组用途十分广泛,如元素筛选、元素赋值等,如下:
>>> a = np.arange(8)
>>> a > 4
array([False, False, False, False, False, True, True, True])
>>> a[a>4]
array([5, 6, 7])
>>> (a > 4) & (a < 7)
array([False, False, False, False, False, True, True, False])
>>> a[(a > 4) & (a < 7)]
array([5, 6])
>>> a[(a > 4) & (a < 7)] += 10
>>> a
array([ 0, 1, 2, 3, 4, 15, 16, 7])
>>> b = np.arange(6).reshape(2,3)
>>> b
array([[0, 1, 2],
[3, 4, 5]])
>>> b > 2
array([[False, False, False],
[ True, True, True]])
>>> b[b>2]
array([3, 4, 5])
>>> np.where(b>2)
(array([1, 1, 1], dtype=int64), array([0, 1, 2], dtype=int64))
6. 结构化索引工具
为了便于将数组形状与表达式和赋值相匹配,可在数组索引中使用newaxis对象来添加大小为1的新维度。可以参考:np.newaxis函数详解
>>> x = np.arange(5)
>>> x
array([0, 1, 2, 3, 4])
>>> x[:,np.newaxis]
array([[0],
[1],
[2],
[3],
[4]])
>>> x[np.newaxis,:]
array([[0, 1, 2, 3, 4]])
>>> x + x[:, np.newaxis]
array([[0, 1, 2, 3, 4],
[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7],
[4, 5, 6, 7, 8]])
7. 利用索引给数组赋值
如前所述,可以使用单个索引、切片索引、整数数组索引以及布尔数组索引来选择数组的子集。若通过这些索引修改原数组数据,需要注意以下几点:
- 分配给索引数组的值必须与索引数组的维度一致(可实现广播规则的除外);
- 不能将较高精度的数据赋值给较低精度的数组元素,因为数组中元素占用内存已固定;
- 可通过切片索引得到的子数组修改原数组数据,但不能通过整数数组索引得到的子数组修改原数组数据;
- 当索引列表包含重复时,赋值完成多次,但仅保留最后一次的赋值结果;
>>> a = np.arange(5)
>>> a
array([0, 1, 2, 3, 4])
>>> a[:2] += 4
>>> a
array([4, 5, 2, 3, 4])
>>> a[:2] -= [4,4]
>>> a
array([0, 1, 2, 3, 4])
>>> a[:2] += 1.0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Cannot cast ufunc add output from dtype('float64') to dtype('int32') with casting rule 'same_kind'
>>> a[[0,0,1]] += 1 # 仅保留最后依次结果,未执行两次
>>> a
array([1, 2, 2, 3, 4])
>>> a[[0,0,1]] -= [2,1,1]
>>> a
array([0, 1, 2, 3, 4])
>>> a[a >2] += 10
>>> a
array([ 0, 1, 2, 13, 14])
>>> b = a[-2:]
>>> b
array([13, 14])
>>> b -= 10 # 切片索引得到的结果数组为原数组的视图
>>> a
array([0, 1, 2, 3, 4])
>>> b = a[[-2,-1]]
>>> b
array([3, 4])
>>> b += 100 # 整数数组索引得到的结果数组为原数组的副本
>>> b
array([103, 104])
>>> a
array([0, 1, 2, 3, 4])
8. 参考
【1】https://blog.csdn.net/sinat_34072381/article/details/84448307