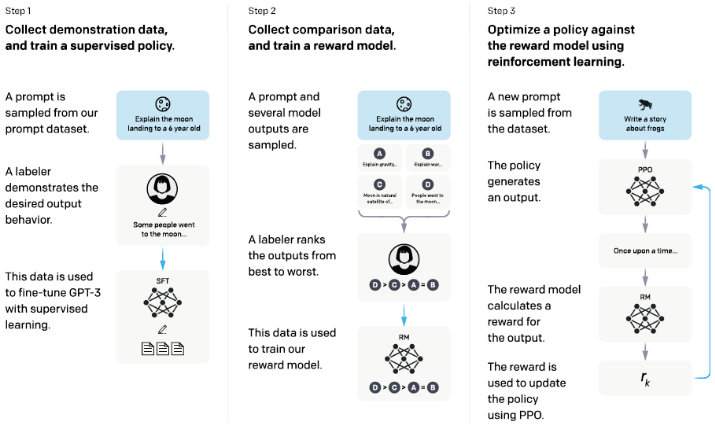
ChatGPT引领了生成式语言大模型的应用与技术热潮,首先简单回顾ChatGPT应用范式:将其应用于指定的下游任务时(如知识问答、翻译、编码),ChatGPT需要经历三个阶段的训练(增强人类语境的猜想):
使用人类标注数据微调,学习人类想要的答案;
训练Reward model,学习人类偏好或意图;
使用强化学习(PPO算法)微调大模型,对齐人类偏好。
ChatGPT是基于GPT3.5(1750亿参数规模)训练获得的,其模型结构为Decoder-only单向掩码架构,推理部署需要分布式推理调度的支持。其在单机A100上进行多卡分布式推理时,自回归解码的响应延迟在百毫秒到数秒量级,因此部署应用面临着响应延迟高、成本开销大的问题。模型压缩是实现ChatGPT小型化应用、减少部署成本的关键,但需要引入哪些压缩算法?具体有哪些技术挑战?实现高倍压缩,整体流程需要怎么设计?
从以下几个问题展开讨论:
大规模预训练阶段:通过在线蒸馏或自蒸馏,预训练小尺寸模型,需要考虑蒸馏的知识类型、助教模型的设计等;除Decoder-only模型结构外,小型化架构创新也非常关键;
下游迁移阶段的挑战:小样本学习的数据量少、训练周期数短,直接应用传统的结构剪枝、张量分解等结构化压缩方法,会引起较大的精度损失。一方面,基于少样本信息(Data-driven)与模型权重信息(Data-free),如何设计有效的压缩指示(Importance Indicator);另一方面,在少样本微调过程中,如何借助多种类型的教师知识设计蒸馏方法,也是辅助精度保持、泛化性保持的关键技术手段;
稀疏化压缩:由于大模型参数规模巨大,非结构(Element-wise)或半结构(Vector-wise, etc.)稀疏化的冗余度相对较高,相比于结构剪枝所面临的精度损失风险更低,有助于实现更高倍数压缩。一方面,也需要考虑如何设计有效的压缩指示,以支持高比例压缩(如90%稀疏度,10倍压缩),并且高参数效率的稀疏正则化有助于降低训练成本;另一方面,稀疏化压缩的推理部署,需要稀疏访存与计算算子的支持,为达成理想的压缩与加速收益(减少稀疏格式解码等开销),更需要DSA计算芯片架构的支持;
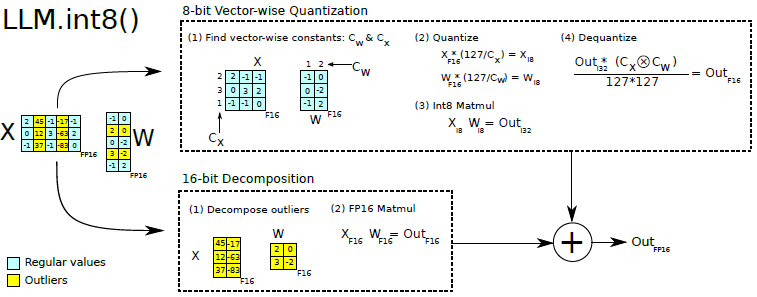
混合精度量化:生成式语言大模型(如OPT-175B、ChatGPT)的特征维度非常高(超过10000),特征当中的异常值(Outliers)占比通常超过1%,长尾分布显著。若对整个网络的不同Layer均采用相同位宽(如INT8)进行量化,将引起较大的量化精度损失。因此需要设计合理的混合精度量化方法以降低精度损失风险;并引入极低比特量化(如4/2-bit)提高压缩倍数,但1-bit量化可能需要设计针对Attention的二值化网络结构,二值化的精度收敛效果较难保证。混合精度量化以及极低比特量化,需要算子、硬件层面的软硬件协同支持。
参考:https://blog.csdn.net/nature553863/article/details/128177323?spm=1001.2014.3001.5502
组合压缩:涉及多种压缩策略时(剪枝、张量分解、量化与稀疏化等),设计有效的组合压缩方案,是实现千亿模型至少20倍压缩、单机单卡部署的关键。此外,Training-aware压缩方法,需要考虑占用更少的分布式训练开销。
有关Transformer类模型压缩的讨论,具体参考:
https://blog.csdn.net/nature553863/article/details/120292394?spm=1001.2014.3001.5502