大数据常见应用场景及架构改进
- 大数据典型的离线处理场景
- 1.大数据数据仓库及它的架构改进
- 2.海量数据规模下的搜索与检索
- 3.新兴的图计算领域
- 4.海量数据挖掘潜在价值
- 大数据实时处理场景
大数据典型的离线处理场景
1.大数据数据仓库及它的架构改进
对于离线场景,最典型的就是数据仓库。它和传统的数仓不太一样。因为传统数仓它只能解决中小规模的数据存储与分析问题。大数据这一块要能承接海量的数据。
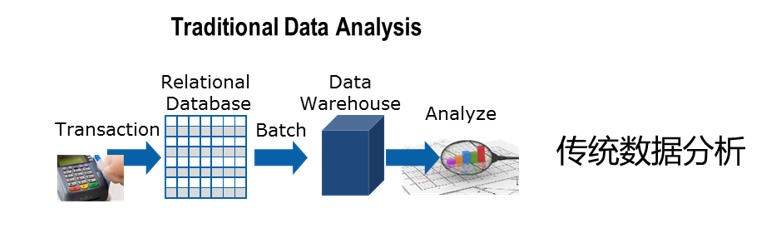
我们来看一下它们的基本架构。首先对于传统数仓的数据分析,业务数据产生之后会存在单机数据库里面。比如说mysql、oracle、DB2等等。ETL任务会定期把它们集中抽取到数据仓库中,进行一个汇总和管理。
数仓比较早的时候它是单节点的,单节点怎么能够存储较多的数据呢?大家可能都听过大型机这个概念,配置非常豪华的服务器,它的容量包括性能是足够ok的。
如果说单节点存不下,会使用mpp数据库架构,它是多节点架构。可以容纳中等规模的数据集。
但是它的节点数是存在上限的,不管是单节点还是mpp,它最大的问题在于扩展性能上限,导致数据容量是有上限的。
数据存到数仓里,基于数仓的数据在做一些分析时候,需要编写应用代码。代码在运行的时候,需要从数据仓库中进行数据的一个查询。将查询出来的数据做一个抽取,把数据抽取到计算程序所在的节点后再进行运算。运算得到结果最后做一个输出。
中间这个过程,因为要在网络上进行数据抽取,所以数据量一旦达到比较大的规模。比如说这个数据有100tb,对于网络的影响就比较高。而且它的抽取效率也是很慢的。当然中小规模数据集是没有问题的。
所以传统数据分析一旦数据量达到某一个规模之后,它分析起来其实性能就比较差了,会比较吃力一些。
对于大数据分析这一块,它是怎么去解决这个问题的?
首先数据源这里就比较丰富,体现了大数据场景的多样性。它有非结构化、半结构化、结构化数据。
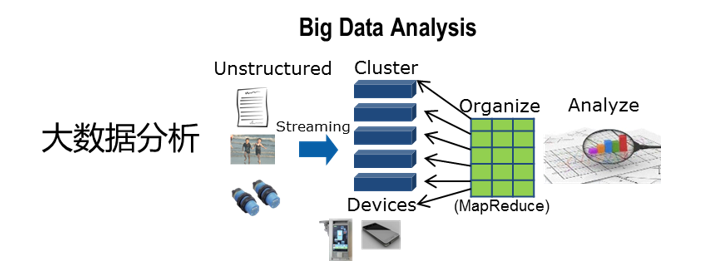
这些数据抽取过来,在进行存储的时候就是以完全分布式的方式进行存储。大数据的架构基本都是天然分布式的,这样的话它的扩展性能是非常好的。
现在我们有5台节点进行存储,如果容量达到了上限,我们可以新增一些节点,这样它的容量就会线性增加。
那如果我们单个文件比较大,比如说我们有一个文件,有1tb大小。这样的一个大文件在存的时候,大数据这里使用了分而治之的一个思想。它把大的文件拆分成非常多的小块,每一个数据块是128M。拆成这些小块以后,再均匀的打散到各个服务器节点中进行存储。
这样的话即使你这个文件再大,我都能够保存起来。这样的话就解决了数据存储这一块的问题。
接下来在计算的时候,因为单个文件就1tb,数据量比较大。那如果把这个数据经过网络进行移动,在进行分析运算的时候,性能会比较差。
这个时候我们换一种思路,去解决这个问题。怎么解决?
你数据移动开销比较高,那你数据就不要动。数据不要动,我的计算任务分发到数据节点进行一个运算。
计算任务它本身就是一个代码程序,它分发到各个节点效率或者速度是比较快的。计算任务在数据节点
直接进行运算,这样的话每个节点得到的结果一定是部分结果。为什么?
因为数据打散到各个节点,每个节点存储的是部分数据,部分数据计算的结果肯定是部分结果。部分结果得到以后,我们只需要再新增一个阶段,把这个部分结果汇总成最终结果再做一个输出就ok。
那部分结果的汇总,大家可想而知,它的开销或者代价一定是比较低的。
所以这是大数据的第二个思想,叫移动计算而非移动数据。这样的话它就解决了我们海量数据,在计算这一块的一个性能瓶颈。
但是这种架构,它对于这种中小规模的数据,其实是不太友好的。如果你这个数据1G它先要拆分,拆分后需要发送到各个节点存储,并且要存储多个副本保证容错。并且在计算的时候,计算任务要分发到这个节点再运算,运算完以后要汇总最终结果,最后再进行输出。整个调度流程就比较长。
而1G的文件放在传统数据处理架构里面,它就可以直接完成计算,效率还高得多。
所以大数据要发挥它的实力,一定是数据规模达到一定量级以后,当它的调度时间要远远小于它的计算时间。这个时候大数据的力量、威力或者价值,才可以发挥出来。这一点大家要留意。
2.海量数据规模下的搜索与检索
除了数仓之外,离线场景还有做搜索与检索。这也是一个常见的场景。
搜索与检索的话,其实就是把数据先存起来,然后对这个数据做一些检索。检索的话一般来说做模糊匹配、正则匹配或者语义匹配,服务端能够很快给我返回结果。
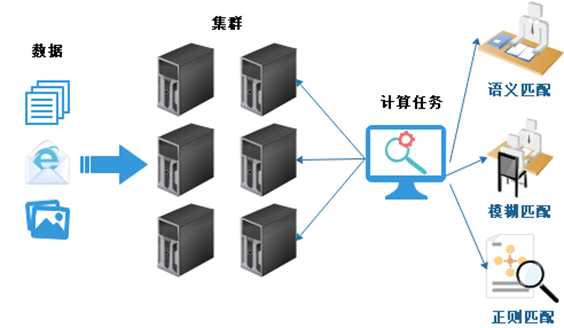
大数据这一块搜索检索,它首先在存储上,数据已经达到了海量规模。再一个在做计算的时候,在海量数据规模下要求在非常短的时间里,要给到反馈结果。
查询的时候,要进行语义、模糊、正则匹配,或者是多功能的一些复杂匹配,大数据这一块的压力是更重的。所以要求它的性能是更高的。
比如,公安场景,将多维度的人口信息储存起来,需要调用的时候,能够快速匹配并返回结果。以便辅助案件的侦破与办理。
3.新兴的图计算领域
对于图计算,它主要是展现数据之间的关系。比方说它可以展现公司之间的关系情况,在图中我们可以看到,a公司与b公司、c公司之间是没有联系的,而b公司和c公司之间是有一些联系的。
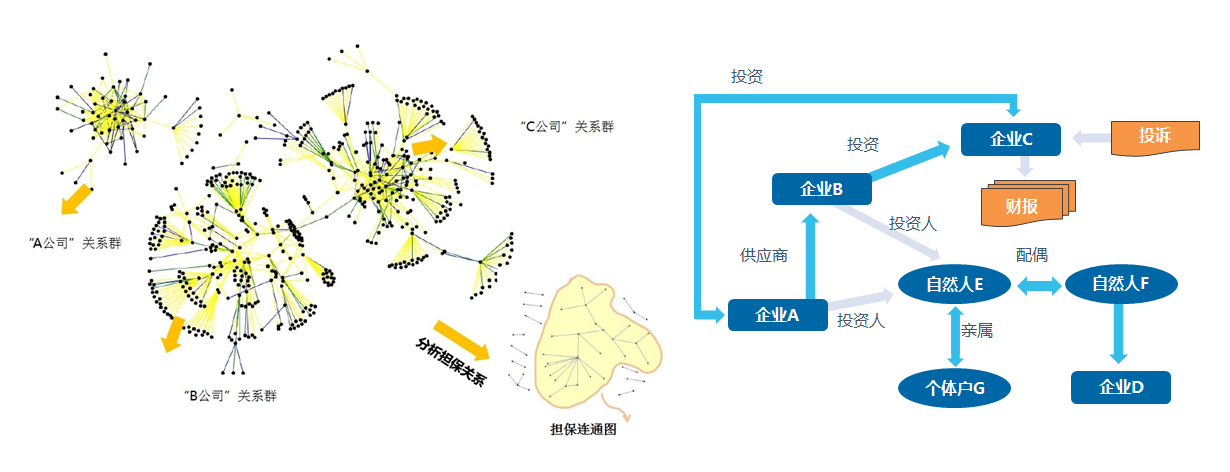
在金融领域,图计算可以挖掘一些比如担保链的异常,比如a公司给b公司担保,b公司给c公司担保,c公司又给a公司担保,形成这样的一个链条肯定是非常有风险的。
包括反洗钱,它也是洗完以后又洗回来了。包括企业之间互相投资,a投资b,b投资c,c再投资a,形成这样的一个链条。
这种情况在金融中,如果使用关系型数据库,它是很难发现的。及时能够实现,运算量也非常庞大。
但是用图计算的话,可以很直观的直接做一个展现,避免了这些风险。
4.海量数据挖掘潜在价值
当然基于数据,我们也可以做数据挖掘。海量的数据它里面潜在的价值是非常高的。比如说我们基于上海市的街头监控数据,进行数据挖掘分析,最后做一个图展现。
这个图展现出来的,就是目前上海市当前这个时间,各个地点的人流密集情况。目前看到7这个地方人流是最密集的,是人民广场,10和6这两个紧随其后。
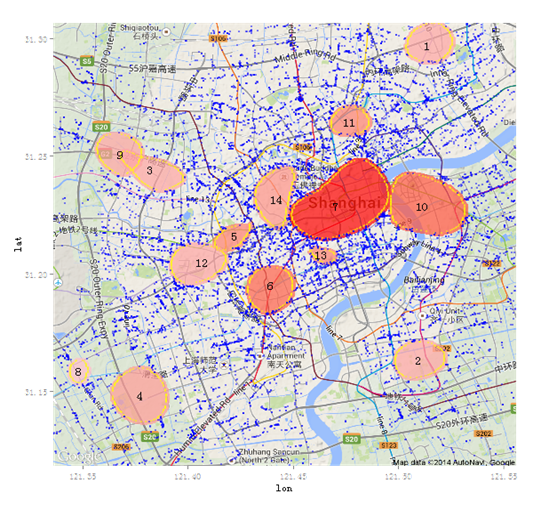
通过分析展现以后,可以辅助我们的治安工作的展开。比如说我们提前去派人力,去做人流的疏导。
当然如果它配上人工智能更是如虎添翼,人工智能厉害的是它可以做预测,它提前预测到某个地方,比如说10这个地方。也就是陆家嘴,在一个小时之后即将出现人流高峰。我们提前派警力,这样的话就可以杜绝一些风险的发生。
大数据实时处理场景
前面讲的都是我们的离线场景,对于实时场景的话,其实准确来说要实时处理数据,并产生结果。它有一个通用的架构与模式。
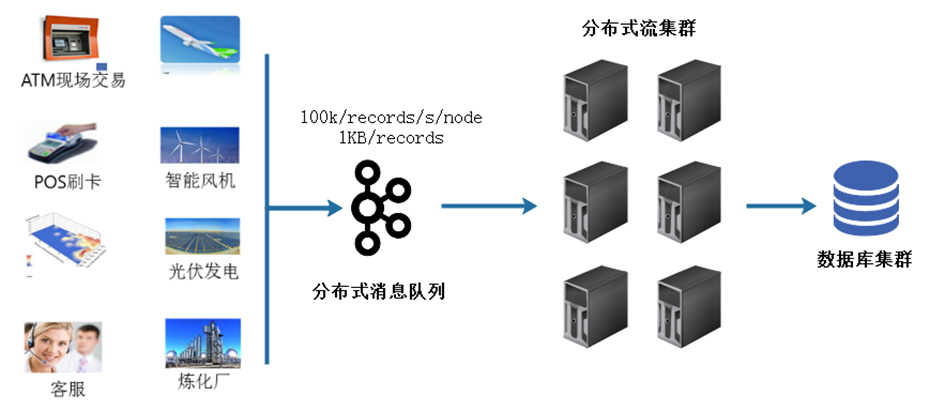
数据从数据源产生,数据源可以是ATM机的、POS机的、智能风机的,或者一些传感器。它们会实时产生数据,这些数据要先进入到一个分布式的消息队列里面做缓冲,而不是直接扔到大数据的分布式流处理集群里面进行运算。
为什么要先进入到分布式消息队列里面?它的目的主要是为了抗压,因为前面这些数据源,它在实时的产生数据。
那就有可能存在没办法预测的并发峰值,很典型的可以预测的峰值比如说618购物节、双11购物节、12306逢年过节抢票的时候。
这个时间的并发我们可以预测的,基本就是那个时间。
但是你比如说某个明星闹个绯闻,突然大量的流量涌上微博,这个是没办法预测的。
保不准哪个点流量涌上来以后,服务器直接就down掉了。这种没办法预测的峰值,如果直接扔到大数据平台,对大数据平台是会产生足够大的冲击的。大数据平台挂掉以后,大数据平台上面所有的业务都挂了,这个是风险很高的。
对于企业来说,一定要有抗压的这样的一个消息队列,这个消息队列它的抗压性能非常好,能够撑住足够的压力。如果说压力过大,我们可以通过扩展与新增节点来增加它的抗压性。
它扛住压力以后,分布式的大数据流处理集群,再从我们的分布式队列里面去取数据,取到数据后进行正常的处理,最后把结果做一个输出。
有这样的架构以后,大量消息涌上来以后,无非是在分布式消息队列里面多积压一会儿。但是只要是大数据的流处理集群没有挂,在规定时间里都是可以处理完的,而且避免了一个风险。
这是大数据常见的应用场景,这一节就和大家聊到这里,我们下期再会!视频内容可以在B站进行观看,传送门:数舟