目录
1. 合并区间
2. 单词接龙
3. N皇后
附录:回溯算法
基本思想
一般步骤
1. 合并区间
难度:★★
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]] 输出:[[1,6],[8,10],[15,18]] 解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]] 输出:[[1,5]] 解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
提示:
1 <= intervals.length <= 104intervals[i].length == 20 <= starti <= endi <= 104
代码:
class Interval(object):
def __init__(self, s=0, e=0):
self.start = s
self.end = e
class Solution(object):
def list2interval(self, list_interval):
ret = []
for i in list_interval:
interval = Interval(i[0], i[1])
ret.append(interval)
return ret
def interval2list(self, interval):
ret = []
x = [0,0]
for i in interval:
x[0] = i.start
x[1] = i.end
ret.append(x)
x = [0,0]
return ret
def merge(self, intervals):
"""
:type intervals: List[Interval]
:rtype: List[Interval]
"""
if intervals is None:
return
ls = len(intervals)
if ls <= 1:
return intervals
intervals = self.list2interval(intervals)
intervals.sort(key=lambda x: x.start)
pos = 0
while pos < len(intervals) - 1:
if intervals[pos].end >= intervals[pos + 1].start:
next = intervals.pop(pos + 1)
if next.end > intervals[pos].end:
intervals[pos].end = next.end
else:
pos += 1
intervals = self.interval2list(intervals)
return intervals
if __name__ == '__main__':
s = Solution()
print(s.merge(intervals = [[1,4],[4,5]]))
print(s.merge(intervals = [[1,3],[2,6],[8,10],[15,18]]))
输出:
[[1, 5]]
[[1, 6], [8, 10], [15, 18]]
2. 单词接龙
难度:★★★ (BFS)
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
- 序列中第一个单词是
beginWord。 - 序列中最后一个单词是
endWord。 - 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典
wordList中的单词。
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
示例 1:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] 输出:5 解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
示例 2:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] 输出:0 解释:endWord "cog" 不在字典中,所以无法进行转换。
提示:
1 <= beginWord.length <= 10endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord和wordList[i]由小写英文字母组成beginWord != endWordwordList中的所有字符串 互不相同
代码:
class Solution:
def ladderLength(self, beginWord, endWord, wordList):
"""
:type beginWord: str
:type endWord: str
:type wordList: List[str]
:rtype: int
"""
if endWord not in wordList:
return 0
if beginWord in wordList:
wordList.remove(beginWord)
wordDict = dict()
for word in wordList:
for i in range(len(word)):
tmp = word[:i] + "_" + word[i + 1 :]
wordDict[tmp] = wordDict.get(tmp, []) + [word]
stack, visited = [(beginWord, 1)], set()
while stack:
word, step = stack.pop(0)
if word not in visited:
visited.add(word)
if word == endWord:
return step
for i in range(len(word)):
tmp = word[:i] + "_" + word[i + 1 :]
neigh_words = wordDict.get(tmp, [])
for neigh in neigh_words:
if neigh not in visited:
stack.append((neigh, step + 1))
return 0
if __name__ == '__main__':
s = Solution()
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log","cog"]
print(s.ladderLength(beginWord, endWord, wordList))
wordList = ["hot","dot","dog","lot","log"]
print(s.ladderLength(beginWord, endWord, wordList))
输出:
5
0
3. N皇后
难度:★★★ (回溯)
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例 1:
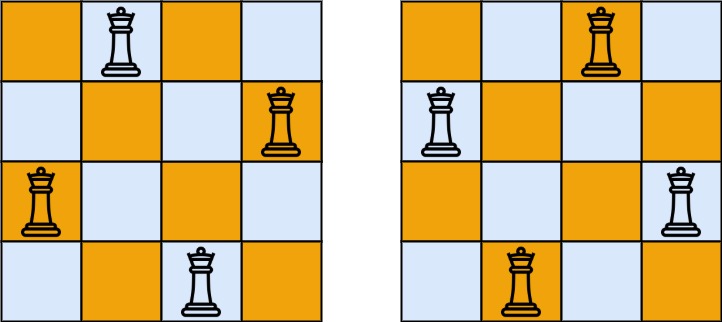
输入:n = 4 输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]] 解释:如上图所示,4 皇后问题存在两个不同的解法。
示例 2:
输入:n = 1 输出:[["Q"]]
提示:
1 <= n <= 9- 皇后彼此不能相互攻击,也就是说:任何两个皇后都不能处于同一条横行、纵行或斜线上。
代码:
class Solution(object):
def solveNQueens(self, n):
if n == 0:
return 0
res = []
board = [['.'] * n for t in range(n)]
self.do_solveNQueens(res, board, n)
return res
def do_solveNQueens(self, res, board, num):
if num == 0:
res.append([''.join(t) for t in board])
return
ls = len(board)
pos = ls - num
check = [True] * ls
for i in range(pos):
for j in range(ls):
if board[i][j] == 'Q':
check[j] = False
step = pos - i
if j + step < ls:
check[j + step] = False
if j - step >= 0:
check[j - step] = False
break
for j in range(ls):
if check[j]:
board[pos][j] = 'Q'
self.do_solveNQueens(res, board, num - 1)
board[pos][j] = '.'
if __name__ == '__main__':
s = Solution()
print(s.solveNQueens(4))
print(s.solveNQueens(1))
输出:
[['.Q..', '...Q', 'Q...', '..Q.'], ['..Q.', 'Q...', '...Q', '.Q..']]
[['Q']]
附录:回溯算法
回溯算法也叫试探法,是一种系统地搜索问题的解题方法。实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
基本思想
从一条路往前走,能进则进,不能进则退回来,换一条路再试。八皇后问题就是回溯算法的典型,第一步按照顺序放一个皇后,然后第二步符合要求放第2个皇后,如果没有位置符合要求,那么就要改变第一个皇后的位置,重新放第2个皇后的位置,直到找到符合条件的位置就可以了。回溯在迷宫搜索中使用很常见,就是这条路走不通,然后返回前一个路口,继续下一条路。回溯算法说白了就是穷举法。不过回溯算法使用剪枝函数,剪去一些不可能到达 最终状态(即答案状态)的节点,从而减少状态空间树节点的生成。回溯法是一个既带有系统性又带有跳跃性的的搜索算法。它在包含问题的所有解的解空间树中,按照深度优先的策略,从根结点出发搜索解空间树。算法搜索至解空间树的任一结点时,总是先判断该结点是否肯定不包含问题的解。如果肯定不包含,则跳过对以该结点为根的子树的系统搜索,逐层向其祖先结点回溯。否则,进入该子树,继续按深度优先的策略进行搜索。回溯法在用来求问题的所有解时,要回溯到根,且根结点的所有子树都已被搜索遍才结束。而回溯法在用来求问题的任一解时,只要搜索到问题的一个解就可以结束。这种以深度优先的方式系统地搜索问题的解的算法称为回溯法,它适用于解一些组合数较大的问题。
一般步骤
1、针对所给问题,定义问题的解空间,它至少包含问题的一个(最优)解。
2、确定易于搜索的解空间结构,使得能用回溯法方便地搜索整个解空间。
3、以深度优先的方式搜索解空间,并且在搜索过程中用剪枝函数避免无效搜索。
确定了解空间的组织结构后,回溯法就从开始结点(根结点)出发,以深度优先的方式搜索整个解空间。这个开始结点就成为一个活结点,同时也成为当前的扩展结点。在当前的扩展结点处,搜索向纵深方向移至一个新结点。这个新结点就成为一个新的活结点,并成为当前扩展结点。如果在当前的扩展结点处不能再向纵深方向移动,则当前扩展结点就成为死结点。此时,应往回移动(回溯)至最近的一个活结点处,并使这个活结点成为当前的扩展结点。回溯法即以这种工作方式递归地在解空间中搜索,直至找到所要求的解或解空间中已没有活结点时为止。