嗨害大家好鸭!我是小熊猫~
本来是不玩原神的,
但是实在是经不住诱惑鸭~
毕竟谁能拒绝可以爬树、炸鱼、壶里造房子、抓小动物、躲猫猫的对战游戏捏~

准备工具
源码资料电子书:点击此处跳转文末名片获取
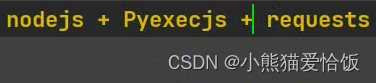
准备模块
import requests
import re
import execjs
请求链接

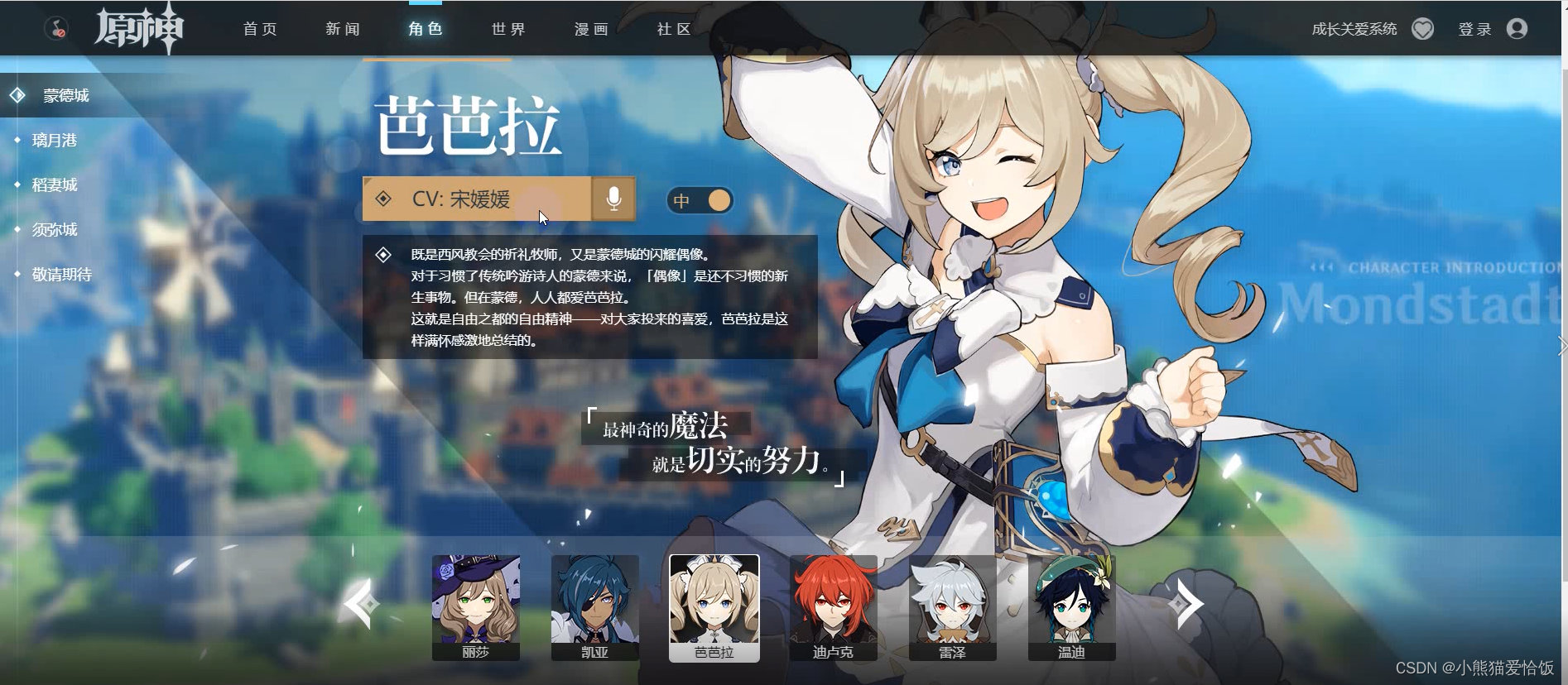
本次目标
所有角色的:
- 基础介绍
- 中日语音
- 图片
分析数据来源
1. 右键点击检查(开发者工具)
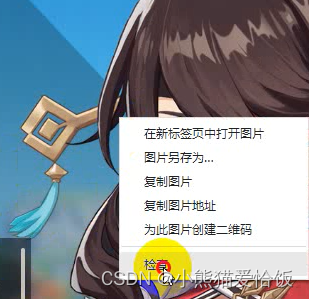
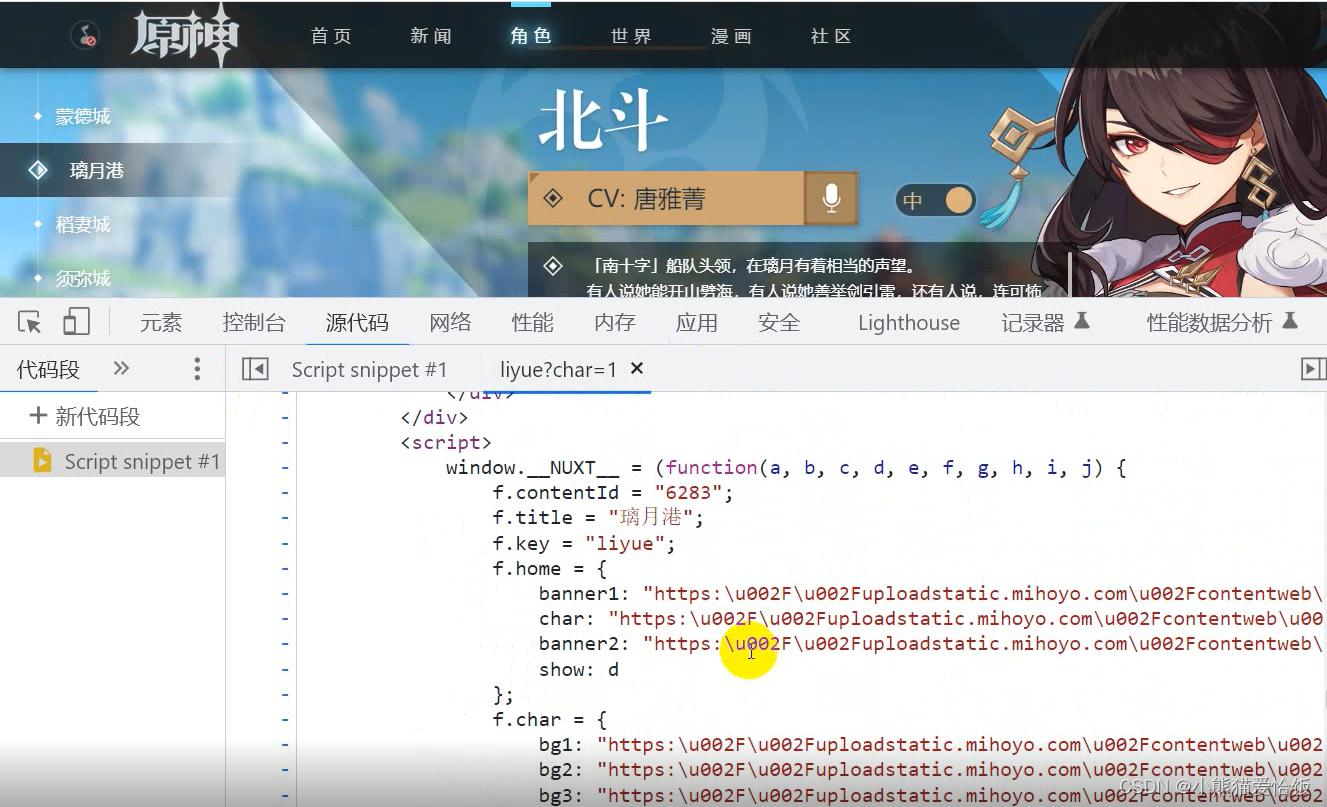
2.刷新网页,找准对应数据
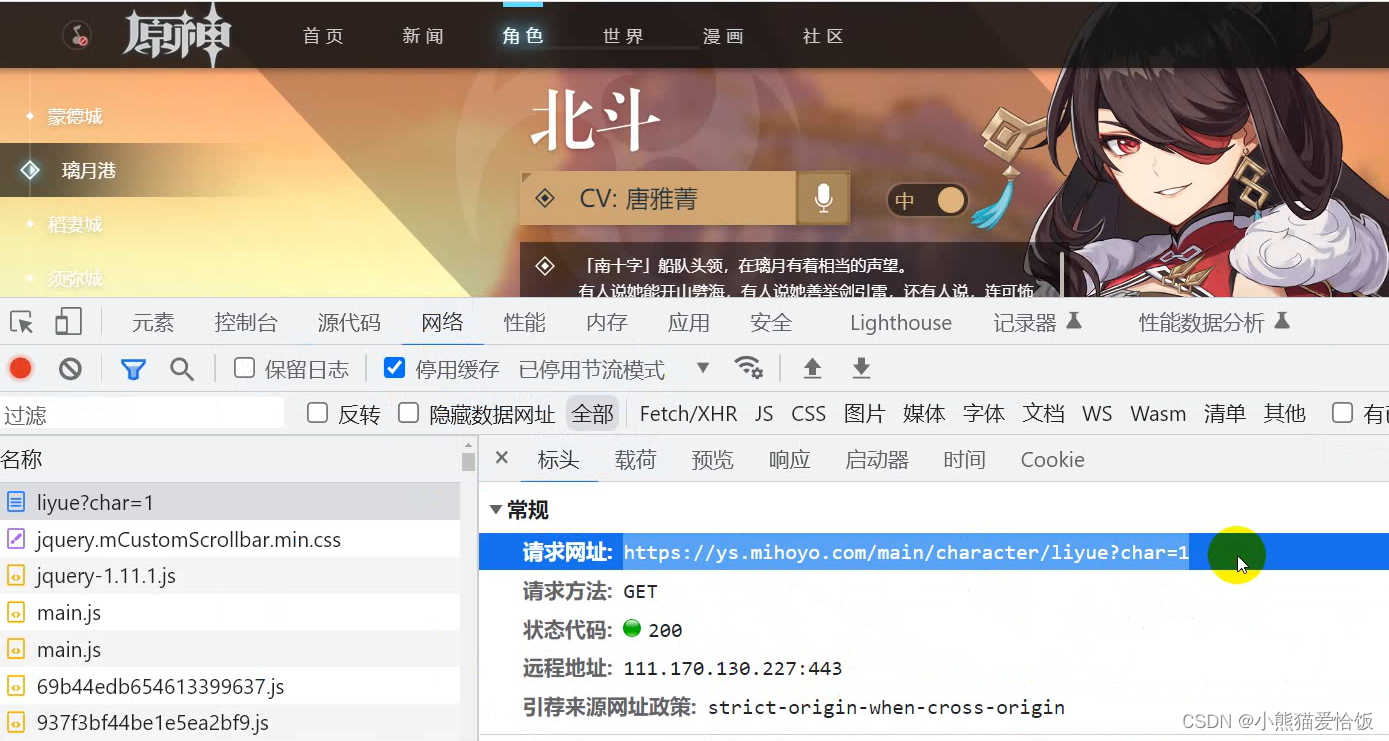
开始代码
url = 'https:///main/character/liyue?char=1'
html_data = requests.get(url).text
print(html_data)
源码资料电子书:点击此处跳转文末名片获取
筛选数据
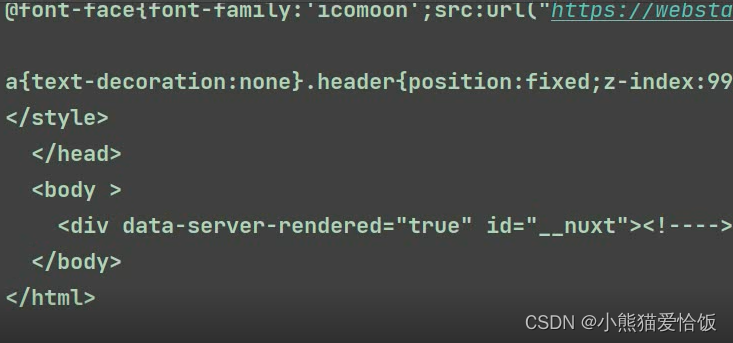
随便搜索网站内包含内容:“南十字”

使用正则表达式匹配数据内容

js_text = re.findall('window.__NUXT__=(.*);', html_data)[0]
执行结果
html_data = requests.get(url).text
js_text = re.findall('window.__NUXT__=(.*);', html_data)[0]
result = execjs.eval(js_text)
此时会出现编码问题
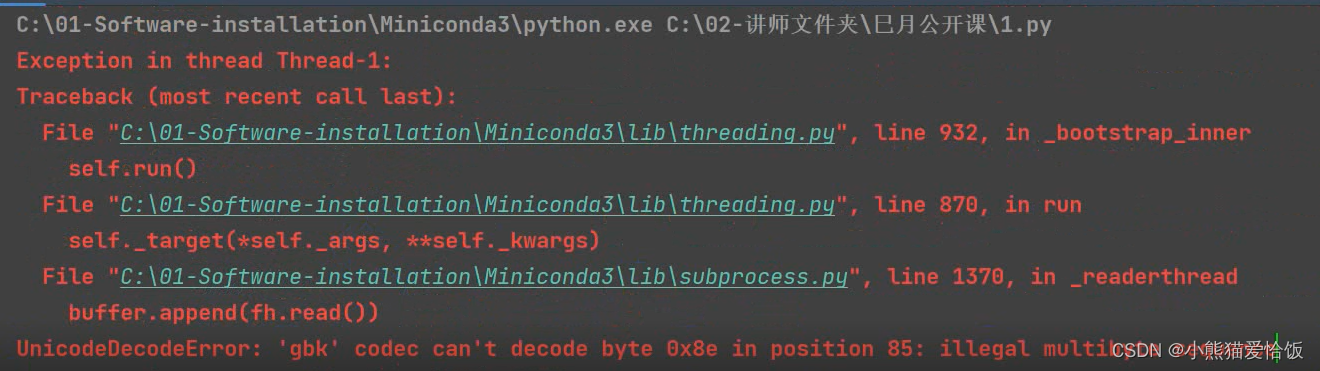
加指定编码
import subprocess
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
再次运行,无报错

使用pprint查看数据结构
pprint.pprint(result)
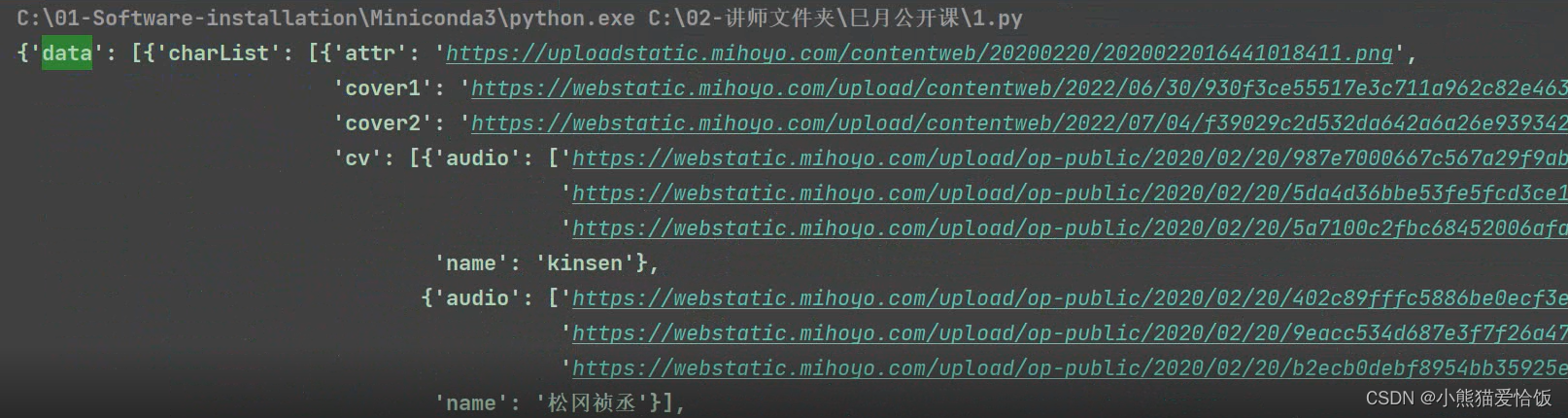
返回网页查看我们需要的内容

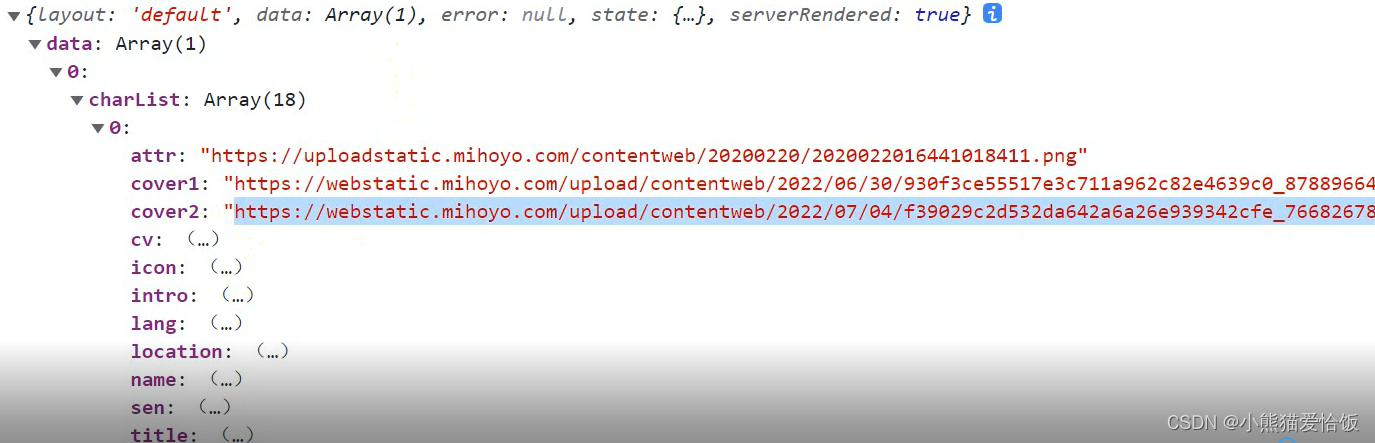
打印所需数据
charList = result['data'][0]['charList']
for char in charList:
cover1 = char['cover1']
title = char['title']
intro = char['intro']
audio_list = char['cv'][0]['audio']
print(title, intro, cover1, audio_list)
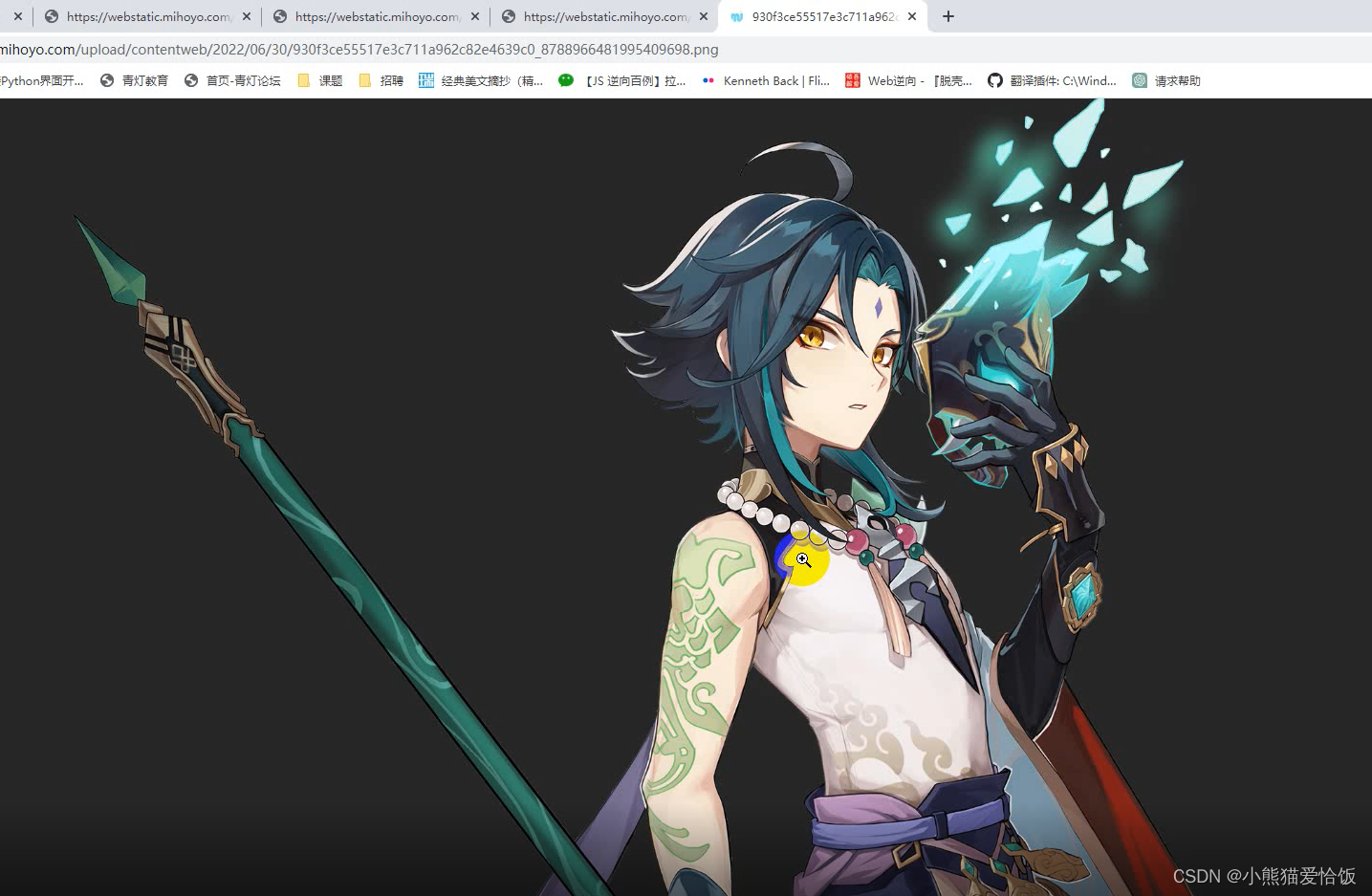
部分效果展示

全部代码
import requests
import re
import execjs
url = 'https://python学习交流:660193417/main/character/liyue?char=1'
html_data = requests.get(url).text
js_text = re.findall('window.__NUXT__=(.*);', html_data)[0]
result = execjs.eval(js_text)
# pprint.pprint(result)
charList = result['data'][0]['charList']
for char in charList:
cover1 = char['cover1']
title = char['title']
intro = char['intro']
audio_list = char['cv'][0]['audio']
print(title, intro, cover1, audio_list)