文章目录
- 1. 创建数据库
- 2. 字符集和校验规则
- 3. 数据库的基本操作
- 3.1 查看数据库
- 3.2 显示创建数据库的语句
- 3.3 修改数据库
- 3.4 删除数据库
- 3.5 备份,还原数据库
- 4. 查看数据库的连接情况
1. 创建数据库
基本语法:
create database if not exists 数据库名 选项1 选项2
- if not exists ,可有可无,比如:你创建的表和已经存在的表重名了,如果不加if not exists,就会直接报错。如果加上了 if not exists,就不会报错,也不会替换原来的表。
- 数据库名,这个没得说,看的起名就行。
- 选项一: charset = ? 指定数据库采用的字符集
- 选项二:collate ?指定数据库字符集的校验规则

例子:
1.创建一个库,指定它的字符集为utf8:
create database if not exists db2 charset=utf8;
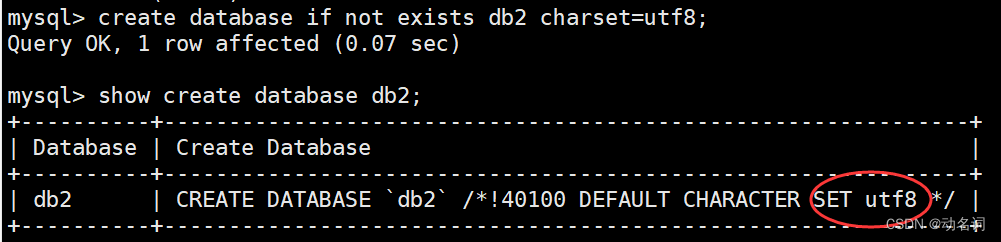
- 创建一个使用utf字符集,并带校对规则的数据库:
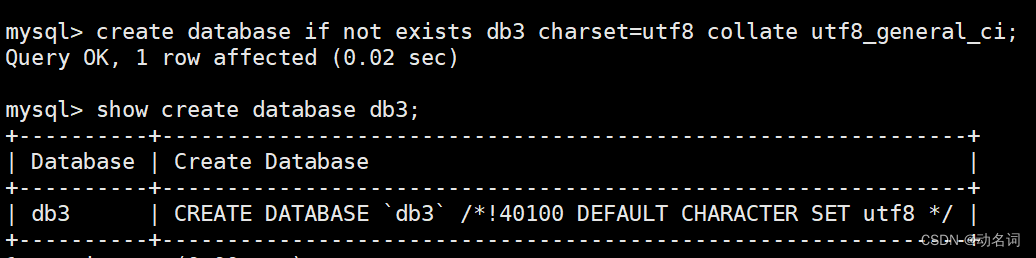
create database if not exists db3 charset=utf8 collate utf8_general_ci;
2. 字符集和校验规则
- 字符集:字符集其实就是一套文字符号及编码,对应的文字及编码,可以将人类可以识别的内容与计算机可以识别的信息进行互相转换。也就是说不同的字符集,它相应的文字和编码不同。比如:gbk是非常适用于中文环境,utf8中英文混合的环境,建议使用此字符集,目前使用的比较多。
- 校验规则:凡是涉及到字符类型比较或排序的地方,都和校验规则有关。
- 字符集和校验规则的关系:每个校验规则唯一对应一种字符集,但一个字符集可以对应多种校验规则,其中有一个是默认的。
Mysql的字符集和校验规则有4个级别的默认设置:服务器级,数据库级,表级和字段级。
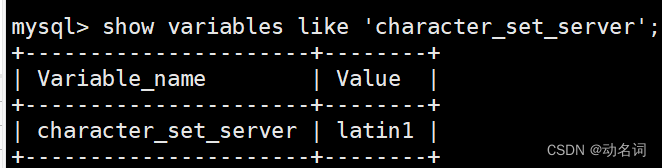
- 查看服务器级别的:
show variables like 'character_set_server';,这是字符集:
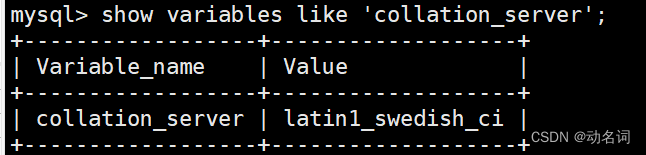
show variables like 'collation_server,这是查看校验规则:
- 查看数据库级别的:
show variables like ‘character_set_database’;
show variables like ‘collation_database’;
服务器级别,库级别,表级别,列级别:
- 服务器级别的字符集和校验规则,在my.cnf里可以设置,如果没有设置就是latin1和latin1_swedish_ci。
- 库级别:这个是在创建库的时候,可以在选项1和选项2中设置字符集和校验规则,如果没有设置,那么就使用系统默认的库级别字符集和校验规则。但是如果系统没有默认的,那么就使用服务器级别的字符集和校验规则。
- 表级别和列级别,都是在创建表的时候,可以填上字符集和校验规则。表如果没有设置的话,就使用库的字符集和校验规则。列级别如果没有设置的话,就使用表的字符集和校验规则。
查看数据库支持的字符集:
show charset;
查看数据库支持的校验规则:
show collation;
接下来,就来验证一下,校验规则对数据库的影响:
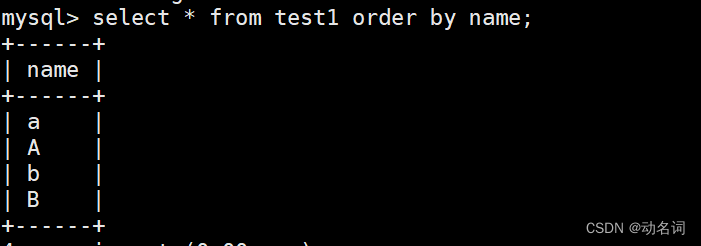
- 创建一个库w1,它的校验规则是用utf8_ general_ ci,这个是不区分字母大小写的。
create database w1 collate utf8_general_ci;
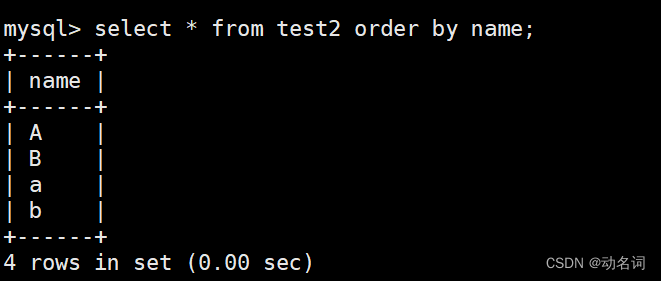
- 创建一个库w2,它的校验规则是用用utf8_ bin,这个是区分字母大小写的。
create database w2 collate utf8_bin;
在库w1和库w2,都创建一个表,表里面只有一个varchar,都插入"a",“b”,“A”,“B”:
use w1;
create table test1(name varchar(2));
insert into test1(name) values (“a”);
insert into test1(name) values (“b”);
insert into test1(name) values (“A”);
insert into test1(name) values (“B”);
w2和w1进行一样的操作,只不过w2中的表名为test2。
插入成功的test1和test2:
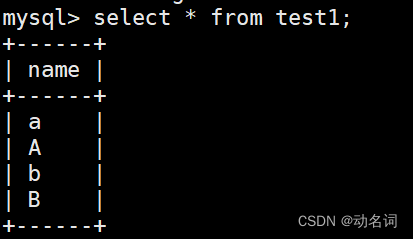
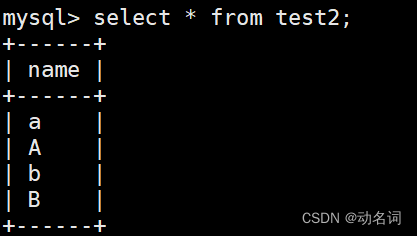
然后分别对test1和test2进行查询操作:
select * from test1 where name = “a”;
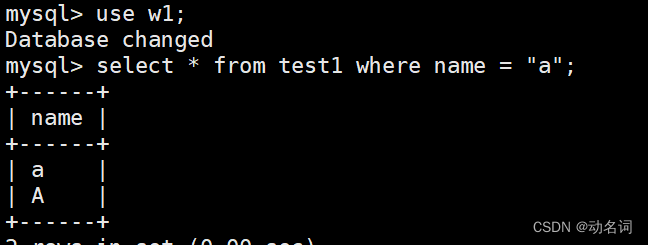
select * from test2 where name = “a”;
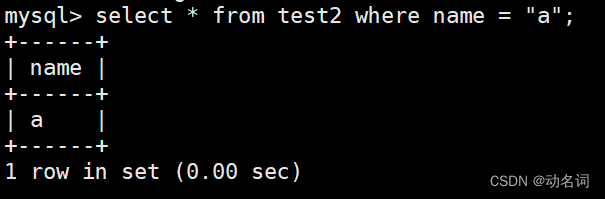
看到校验规则对查询的影响了吧,这里其实可以创建表的时候,设置表级别的校验规则,但是本章是讲库操作的,所以就直接设置库级别的校验规则,由于表并没有给定校验规则,所以默认使用库的校验规则。
像排序这种操作,校验规则也是有影响的:
3. 数据库的基本操作
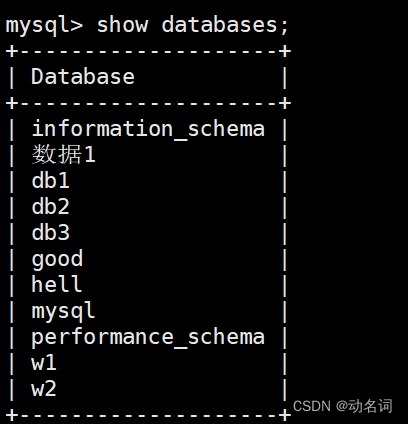
3.1 查看数据库
show databases;
3.2 显示创建数据库的语句
show create database w1;

注意:/ *…… * /,这个不是注释,它的意思是 如果当前的mysql的版本大于4.01,就执行此语句。
3.3 修改数据库
alter database 数据库名 + 选项1 选项2
这个主要是对数据库的字符集,校验规则进行修改,选项1 是 charset,选项2 是collocate。
比如:修改数据库的字符集,就修改w1数据库,上面可以看到它的字符集是utf8
alter database w1 charset=gbk

3.4 删除数据库
删除数据库的操作,尽量不要干,传说中的删库跑路就是这。但是Linux批量删除文件就是 rm -f /*,这就是将根目录下的所有文件删除。如果还是利用文件删除,无非就是删除一个目录,因为数据库在Linux视角下就是一个目录。
drop database 数据库名
执行删除之后的结果:
- 数据库内部看不到对应的数据库
- 对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
3.5 备份,还原数据库
删库前要备份数据库,这是我们该做的,切记 必须备份 数据库。
备份有两种方式:
- 物理备份,就是先将 /var/lib/mysql 中要备份的库(目录),进行打包操作,将此包保存在一个路径下,假如原来的库被删除了,那么还原的操作就是将此包拷贝到/var/lib/mysql中,然后解包。至于/var/lib/mysql 是我的服务器中 数据库的表和库保存的路径,至于大家的情况可能不一样,所以具体还要看my.cnf的配置。
- 逻辑备份,这个就是MySQL的内部操作了,它是利用的备份工具:mysqldump。之所以叫逻辑备份,因为它备份的是 你创建库 以及在库中创建表的SQL语句。它的还原操作就是将原来的SQL语句再次执行一遍。
- 对比以上备份方式,物理备份占用的物理空间大,但是还原的快;逻辑备份占用的物理空间小,但是还原的慢。
我们主要来看逻辑备份:
mysqldump –u 用户名称 –h 主机名称 –p密码 待备份的数据库名称[tbname, [tbname…]]> 数据库备份存储的文件路径+备份文件名称.sql
比如:对数据库w1进行备份:
mysqldump -uroot -p w1>w1.sql;
注意:mysqldump是备份工具,它的使用是在Linux命令行中的,可不敢在MySQL命令行里使用哈。
上面语句的意思就是在当下目录备份w1为w1.sql;

先来看看w1.sql里面是什么东东:
-- MySQL dump 10.13 Distrib 5.6.51, for Linux (x86_64)
--
-- Host: localhost Database: w1
-- ------------------------------------------------------
-- Server version 5.6.51
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `test1`
--
DROP TABLE IF EXISTS `test1`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `test1` (
`name` varchar(2) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `test1`
--
LOCK TABLES `test1` WRITE;
/*!40000 ALTER TABLE `test1` DISABLE KEYS */;
INSERT INTO `test1` VALUES ('a'),('A'),('b'),('B');
/*!40000 ALTER TABLE `test1` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
-- Dump completed on 2023-02-21 17:40:47
- 以/* !开头、*/结尾的语句为可执行的MySQL注释,这些语句可以被MySQL执行,但在其他数据库管理系统中被作为注释忽略,这可以提高数据库的可移植性;
- 文件开头指明了备份文件使用的MySQLdump工具的版本号10.13 ;接下来是备份账户的名称和主机信息,以及备份的数据库的名称;最后是MySQL服务器的版本号,5.6.51。
- 然后抛开/ *…… * /,看到内容大多数都是SQL语句。
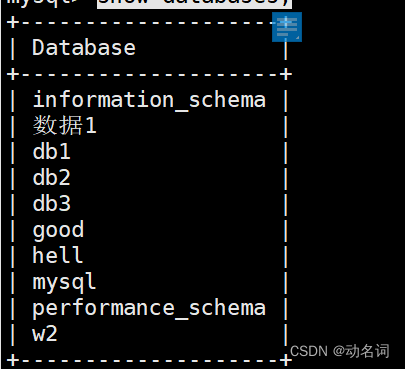
先去把w1库删除了:
drop database w1;
show databases;
可以看到没有w1库了。
还原w1库:
- 还原w1库前,先得创建一个w1的空库,这样才能使用source进行还原:create database w1;
- 有了w1空库后,在MySQL命令行输入:use w1;source w1.sql;这样就还原成功了:
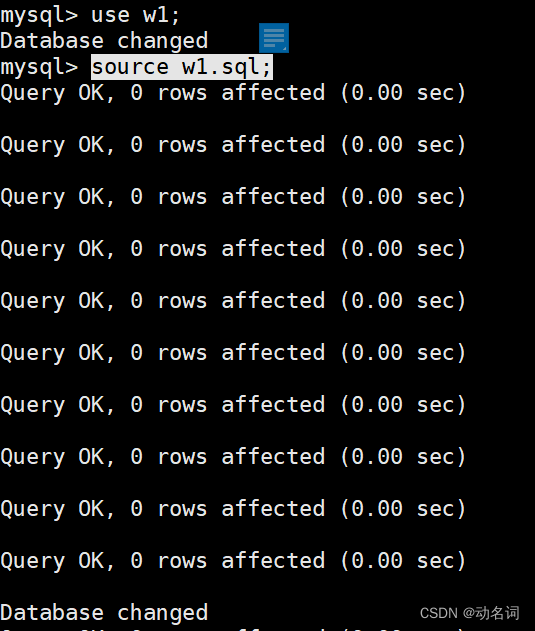
- 可以查看一下,w1库中的表test1:
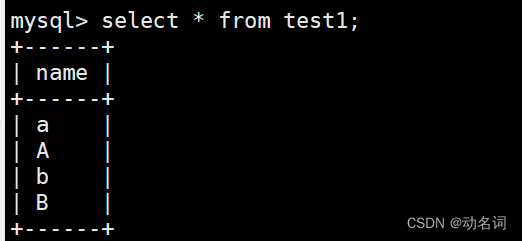
没有问题。
以上是备份一个单个库,但是还有其他的使用情况:
- 情况1:备份一个库,就是上面讲的例子。
- 情况2:备份一个库中的一张表,或多张表。
- 情况3:备份多个库。
我们来看情况2:我先创建一个库hh1,里面创建两张表:
创建库:
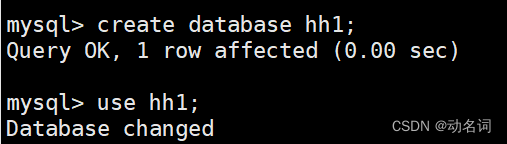
创建表:
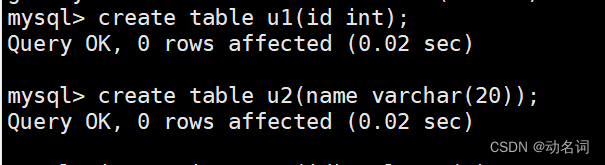
在表中插入数据:
退出mysql,使用mysqldump对hh1的表u1进行备份,不备份u2:
基本语法:mysqldump -u root -p 数据库名 表名1 表名2 > 路径+文件名.sql
mysqldump -uroot -p hh1 u1>hh1.sql
备份成功后,进入sql服务,因为这里还是只备份了一个库,所以在 备份前还需要创建一个新的空库 hh1;然后use hh1后,输入source hh1.sql;这样就完成了备份。
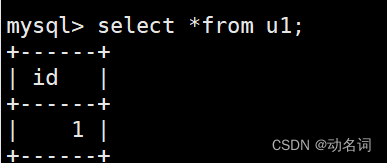
然后来看情况3,备份多个库:
基本语法: mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径+文件名.sql
注意,这里有一个选项非常重要,那就是 -B,这个选项其实在备份一个单库时也可以用,如果在单库备份里也加上-B参数,那么就不需要像上面那样建立一个空库。
比如:
我备份w1,w2 库:mysqldump -uroot -B -p w1 w2>w12.sql;
删除w1,w2 库后,再进行备份:直接在mysql命令行上输入,source w12.sql;
这样就备份成功了。
以上是关于备份还原的基本操作。
4. 查看数据库的连接情况
基本语法:
show processlist

可以看到,当前数据库只有我在使用,我新起一个窗口,连接mysql:

发现,这里连接用户变为2个了。
作用:就是可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是你正常登陆的,很有可能你的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况。