数据挖掘,计算机网络、操作系统刷题笔记51
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
【35】数据挖掘,计算机网络、操作系统刷题笔记35
【36】数据挖掘,计算机网络、操作系统刷题笔记36
【37】数据挖掘,计算机网络、操作系统刷题笔记37
【38】数据挖掘,计算机网络、操作系统刷题笔记38
【39】数据挖掘,计算机网络、操作系统刷题笔记39
【40】数据挖掘,计算机网络、操作系统刷题笔记40
【41】数据挖掘,计算机网络、操作系统刷题笔记41
【42】数据挖掘,计算机网络、操作系统刷题笔记42
【43】数据挖掘,计算机网络、操作系统刷题笔记43
【44】数据挖掘,计算机网络、操作系统刷题笔记44
【45】数据挖掘,计算机网络、操作系统刷题笔记45
【46】数据挖掘,计算机网络、操作系统刷题笔记46
【47】数据挖掘,计算机网络、操作系统刷题笔记47
【48】数据挖掘,计算机网络、操作系统刷题笔记48
【49】数据挖掘,计算机网络、操作系统刷题笔记49
【50】数据挖掘,计算机网络、操作系统刷题笔记50
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记51
- @[TOC](文章目录)
- 数据挖掘分析应用:人工神经网络:分类和回归
- 多道程序设计主要是能够宏观是是多个程序并行的结果
- 在( )中,每次分配时把既能满足要求,又是最小的空闲区分配给进程。
- 目录结构形式有以下这几种:
- 裸机是没有操作系统
- 下列哪一个选项是引入缓冲的原因()。
- 在 WINDOWS2000 操作系统中要查看本机的路由表,可在 MS-DOS 方式运行( )。
- 下列地址中属于网络地址的是?( )
- 403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求
- 总结
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记51
- @[TOC](文章目录)
- 数据挖掘分析应用:人工神经网络:分类和回归
- 多道程序设计主要是能够宏观是是多个程序并行的结果
- 在( )中,每次分配时把既能满足要求,又是最小的空闲区分配给进程。
- 目录结构形式有以下这几种:
- 裸机是没有操作系统
- 下列哪一个选项是引入缓冲的原因()。
- 在 WINDOWS2000 操作系统中要查看本机的路由表,可在 MS-DOS 方式运行( )。
- 下列地址中属于网络地址的是?( )
- 403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求
- 总结
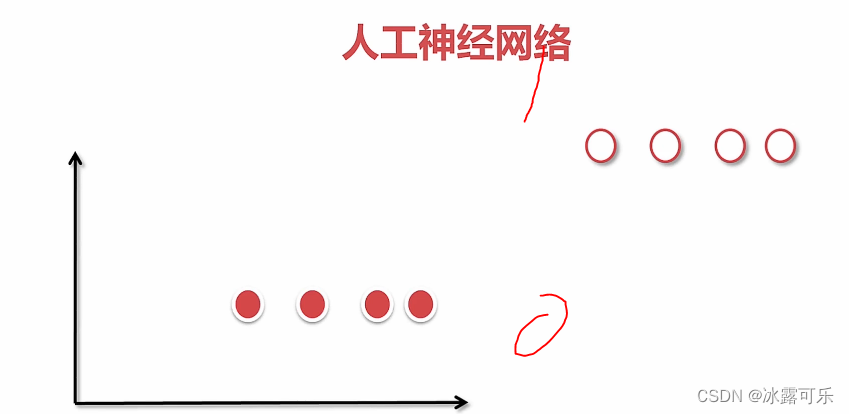
数据挖掘分析应用:人工神经网络:分类和回归
相似分布的输入,就得到差不多的输出
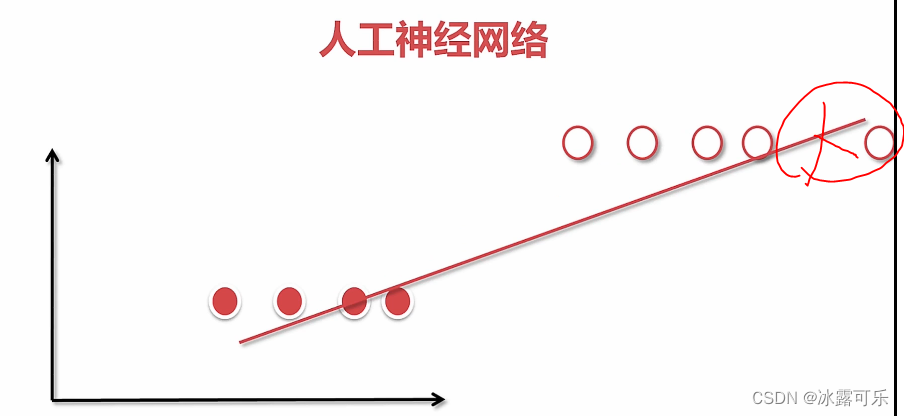
线性回归
有缺陷
逻辑回归有意义了
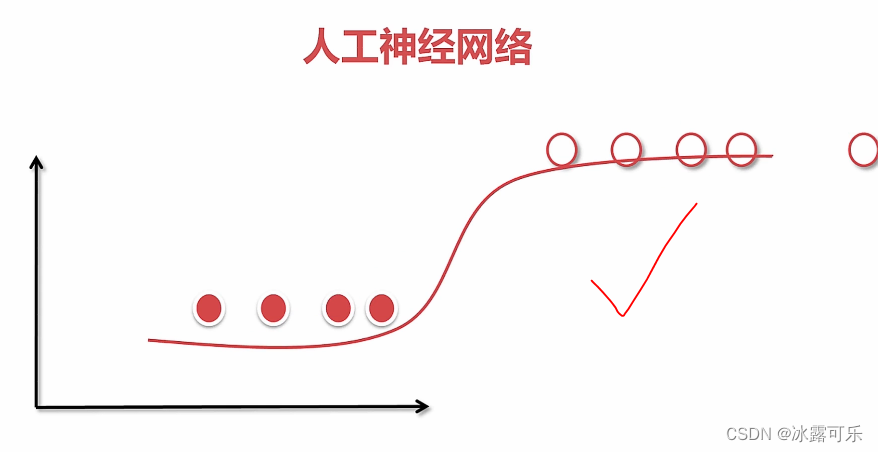
这样的分类器,就美滋滋了
整个函数的表达式就这样
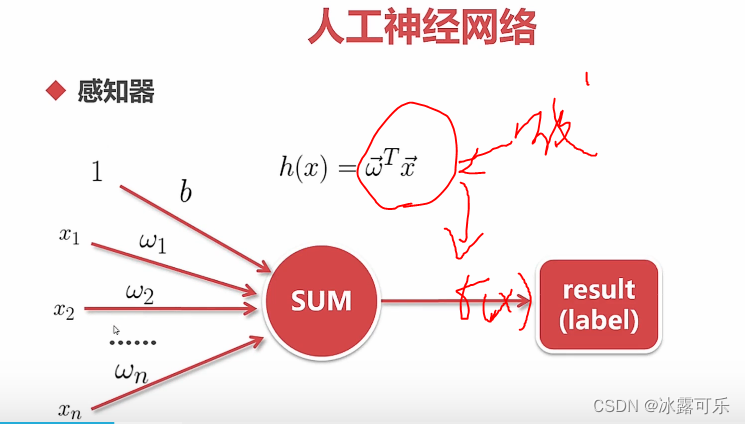
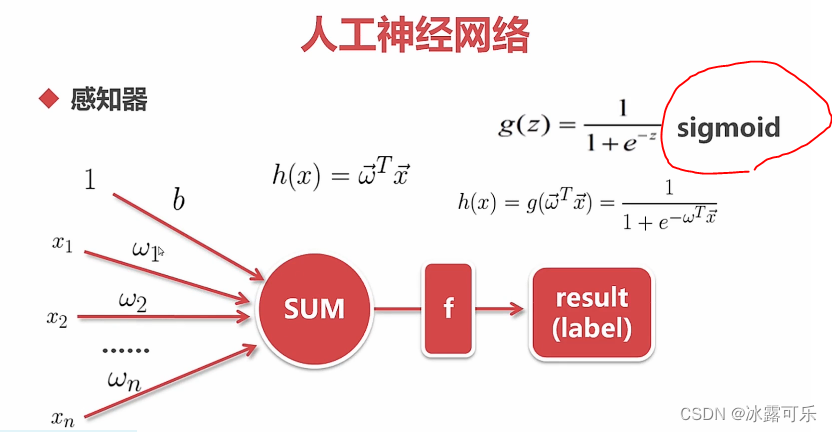
线性模型加入激活函数
就是非线性化的逻辑回归
美滋滋啊
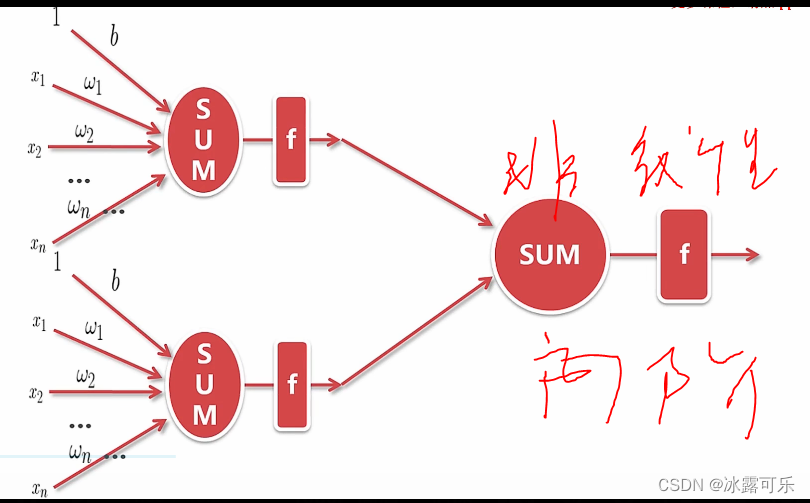
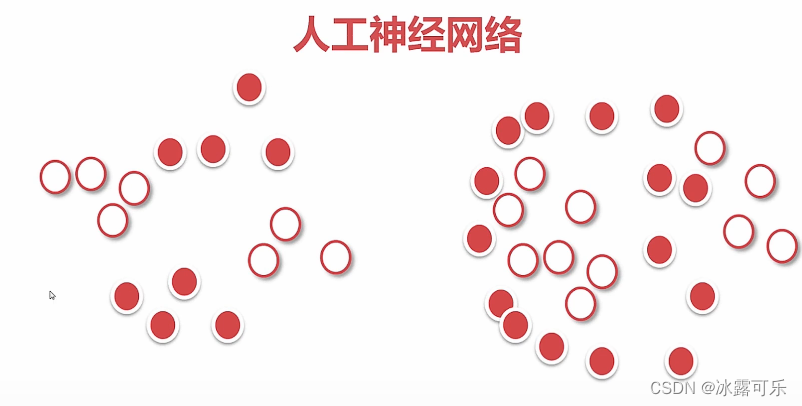
分类美滋滋
当很多网络胡乱链接的话,就是非线性模拟了。
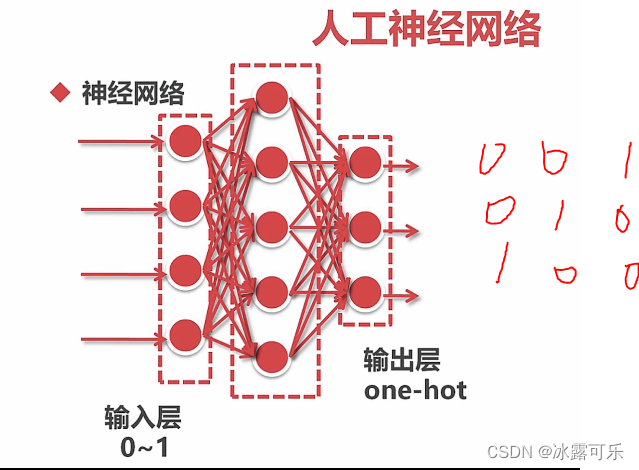
中间是是隐藏层
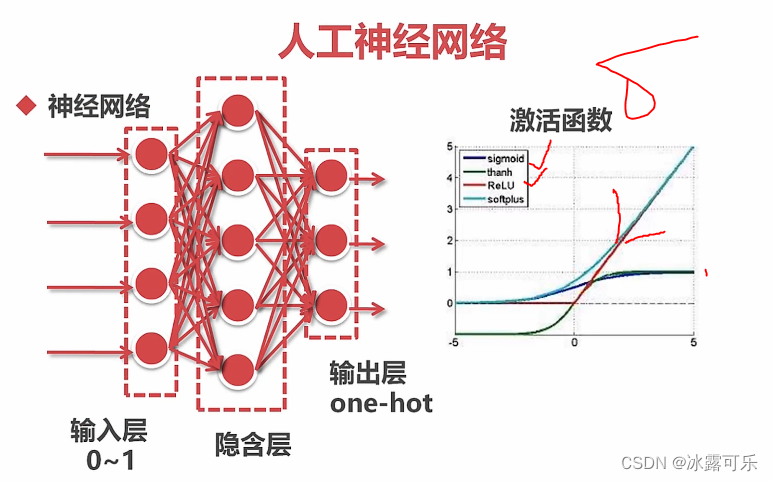
0-1是sigmoid,是01分类
relu取值是无限大
这些参数是用梯度下降法来求解的
耗费时间很大,后续要破解这个问题
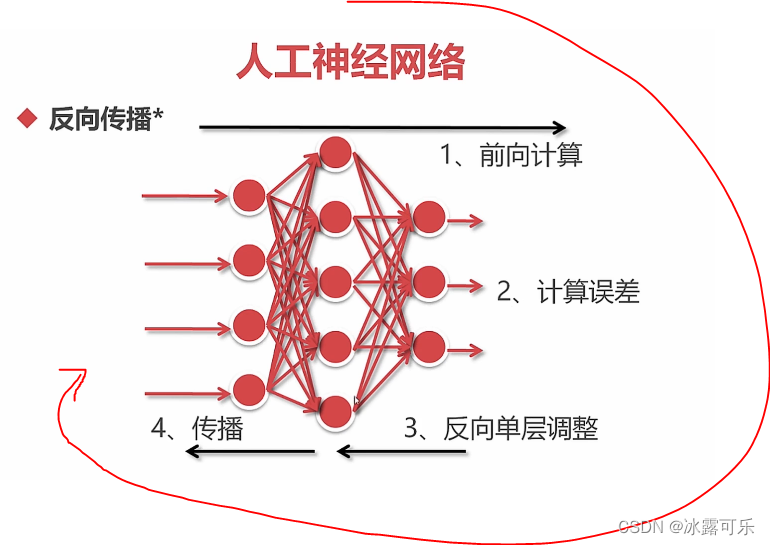
要反向传播算法
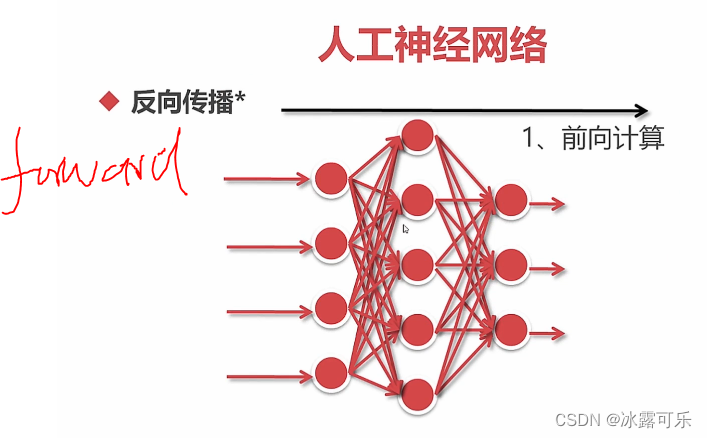
误差计算
反向单层调整
梯度调整,前面的不管,只看单层调整
还有就是随机梯度下降法,不要调整所有的参数
随机选取整个数据集中的部分样本去训练
收敛速度快,开销小
相对容易陷入局部最优解

离群点容易影响这个模型的参数更新
通过dropout搞定
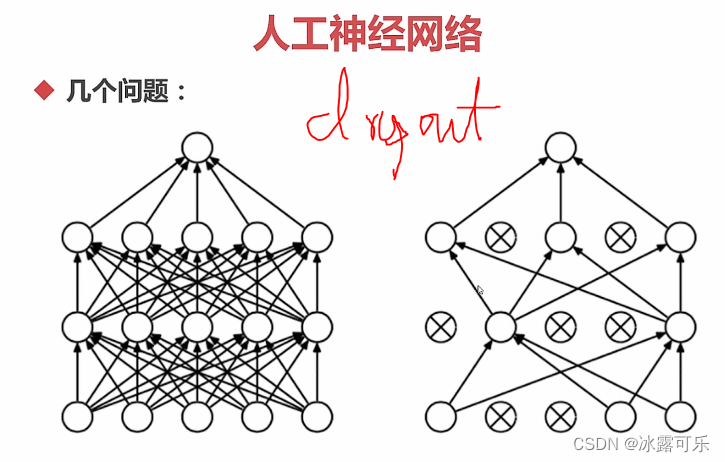
这样,相当于是集成学习,所学习分类器,组合成为一个强学习分类器


当特征维度不大时,数据不规整时,就别用神经网络

用pycharm的terminal来安装:
# 演示SVM--Random--adaboost
# 模型
def hr_modeling_all_saveDT_SVM(features, label):
from sklearn.model_selection import train_test_split
# 切分函数
#DataFrame
feature_val = features.values
label_val = label
# 特征段
feature_name = features.columns
train_data, valid_data, y_train, y_valid = train_test_split(feature_val, label_val, test_size=0.2) # 20%验证集
train_data, test_data, y_train, y_test = train_test_split(train_data, y_train, test_size=0.25) # 25%测试集
print(len(train_data), len(valid_data), len(test_data))
# KNN分类
from sklearn.neighbors import NearestNeighbors, KNeighborsClassifier
from sklearn.metrics import accuracy_score, recall_score, f1_score # 模型评价
from sklearn.naive_bayes import GaussianNB, BernoulliNB # 高斯,伯努利,都是对特征有严格要求,离散值最好
from sklearn.tree import DecisionTreeClassifier, export_graphviz # 决策树
from io import StringIO
import pydotplus
import os
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.ensemble import AdaBoostClassifier
from sklearn.linear_model import LogisticRegression
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from tensorflow.keras.optimizers import SGD
os.environ["PATH"] += os.pathsep+r'D:\Program Files\Graphviz\bin'
models = [] # 申请模型,挨个验证好坏
knn_clf = KNeighborsClassifier(n_neighbors=3) # 5类
bys_clf = GaussianNB()
bnl_clf = BernoulliNB()
DT_clf = DecisionTreeClassifier()
SVC_clf = SVC()
rdn_clf = RandomForestClassifier()
adaboost_clf = AdaBoostClassifier(n_estimators=100)
logi_clf = LogisticRegression(C=1000, tol=1e-10, solver="sag", max_iter=10000)
# models.append(("KNN", knn_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("GaussianNB", bys_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("BernoulliNB", bnl_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("Decision Tree", DT_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("SVM classifier", SVC_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("Random classifier", rdn_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("adaboost classifier", adaboost_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("logistic classifier", logi_clf)) # 代码一个个模型测--放入的是元祖
# 不同的模型,依次验证
for modelName, model in models:
print(modelName)
model.fit(train_data, y_train) # 指定训练集
# 又集成化数据集
data = [(train_data, y_train), (valid_data, y_valid), (test_data, y_test)]
for i in range(len(data)):
print(i)
y_input = data[i][0]
y_label = data[i][1] # 输入输出预测
y_pred = model.predict(y_input)
print("acc:", accuracy_score(y_label, y_pred))
print("recall:", recall_score(y_label, y_pred))
print("F1:", f1_score(y_label, y_pred))
print("\n")
# 不考虑存储,你看看这个模型就会输出仨结果
ann = Sequential()
ann.add(Dense(50, input_dim=len(feature_val[0]))) # 隐藏层
ann.add(Activation("sigmoid"))
ann.add(Dense(2)) # 输出层
ann.add(Activation("softmax"))
sgd = SGD(lr=0.01) # 优化器
ann.compile(loss="mse", optimizer=sgd) # 误差函数
y_truth = np.array([[0,1] if t == 1 else [1,0] for t in y_train]) # Onehot编码
ann.fit(train_data, y_truth, epochs=10, batch_size=2048)
# 又集成化数据集
data = [(train_data, y_train), (valid_data, y_valid), (test_data, y_test)]
for i in range(len(data)):
print(i)
y_input = data[i][0]
y_label = data[i][1] # 输入输出预测
y_pred = (ann.predict(y_input)>0.5).astype("int32") # 连续值转化为独热编码
print("acc:", accuracy_score(y_label, y_pred))
print("recall:", recall_score(y_label, y_pred))
print("F1:", f1_score(y_label, y_pred))
print("\n")
def regrfunc(features, label):
df = features[["number_project", "average_montly_hours"]]
y = features["last_evaluation"]
# print(df, y)
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.linear_model import LogisticRegression
reg_model = LinearRegression()
ridge_model = Ridge(alpha=0.95) # 参数
reg_model.fit(df.values, y.values)
ridge_model.fit(df.values, y.values)
y_pred = reg_model.predict(df.values)
y_pred_ridge = ridge_model.predict(df.values)
print("coef", reg_model.coef_)
print("coef", ridge_model.coef_)
from sklearn.metrics import mean_squared_error
print("reg mse:", mean_squared_error(y.values, y_pred))
print("ridge mse:", mean_squared_error(y.values, y_pred_ridge))
if __name__ == '__main__':
features, label = pre_processing(sl=True, le=True, npr=True, amh=True, wacc=True, pla=True, dep=False, sal=True,
lower_d=False, ld_n=3)
# print(features, label)
# 灌入模型
hr_modeling_all_saveDT_SVM(features, label)
# 回归分析
# regrfunc(features, label)
引入神经网络容器
密集层网络,激活函数,优化器
没成功gg
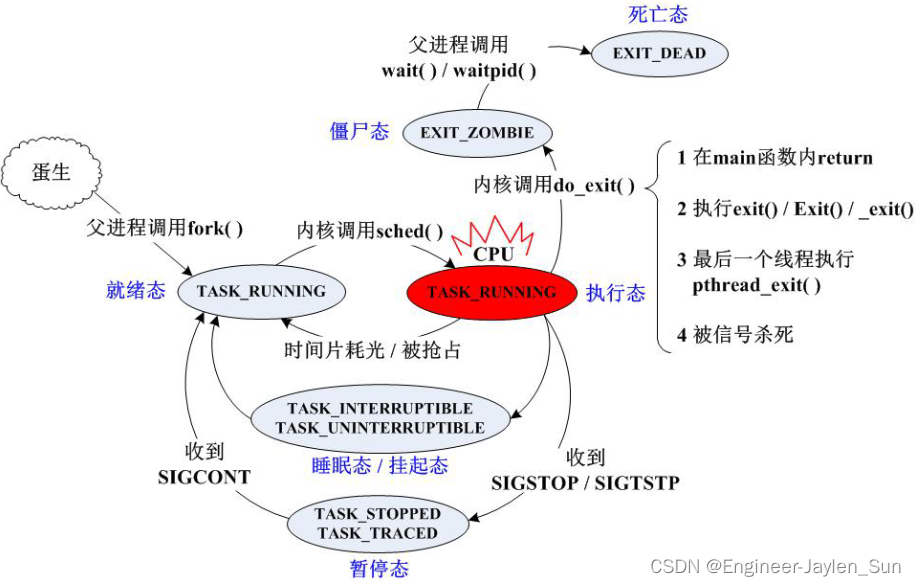
多道程序设计主要是能够宏观是是多个程序并行的结果
实质是对现场的中断和恢复操作,
CPU和通道并行工作只是减少了中断cpu的次数加快io传输的效率.
在( )中,每次分配时把既能满足要求,又是最小的空闲区分配给进程。
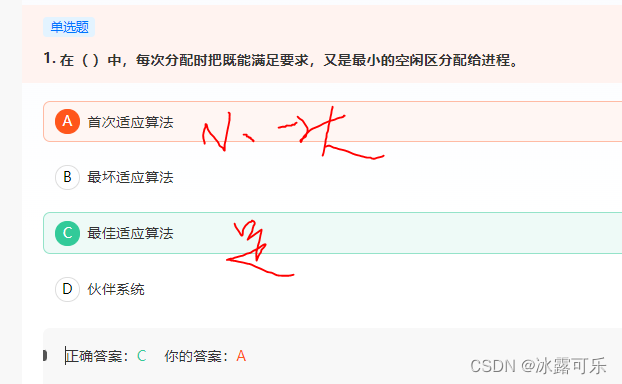
**首次适应算法(First Fit):该算法从空闲分区链首开始查找,直至找到一个能满足其大小要求的空闲分区为止。**然后再按照作业的大小,从该分区中划出一块内存分配给请求者,余下的空闲分区仍留在空闲分区链中。
最坏适应算法(Worst Fit):最坏适应算法是将输入的作业放置到主存中与它所需大小差距最大的空闲区中。空闲区大小由大到小排序。
**最佳适应算法(Best Fit):该算法总是把既能满足要求,又是最小的空闲分区分配给作业。**为了加速查找,该算法要求将所有的空闲区按其大小排序后,以递增顺序形成一个空白链。这样每次找到的第一个满足要求的空闲区,必然是最优的。孤立地看,该算法似乎是最优的,但事实上并不一定。因为每次分配后剩余的空间一定是最小的,在存储器中将留下许多难以利用的小空闲区。同时每次分配后必须重新排序,这也带来了一定的开销。
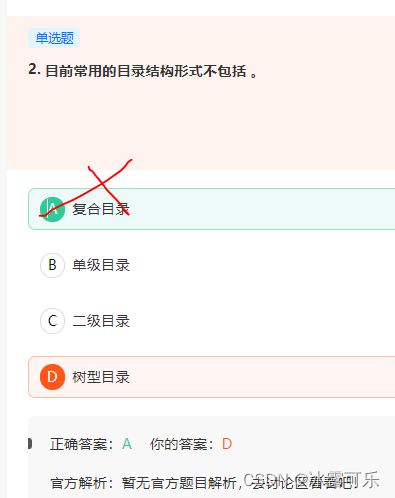
目录结构形式有以下这几种:
链接:https://www.nowcoder.com/questionTerminal/100d51c7bab3447695e9d9f60f8ee8ff
来源:牛客网
单层结构目录:所有文件都包含在同一目录,优点是便于理解和支持,缺点是多用户体验不好;
双层结构目录:先为每个用户做一个主文件目录(用户1,用户2,用户3…),用户n目录下才是用户的文件目录,比上面的就多了一个主文件目录而已;
树状结构目录:如果能理解将双层结构目录作为两层树来看待,那么将目录结构扩展为任意高度的树就显得自然了。树是最常用的目录结构,系统里的每个文件都有唯一的路径名。注意,树上不能有环。
无环图目录:虽然没有环,但是允许目录含有共享子目录的文件,同一文件或子目录可出现在两个不同的目录中。
通用图目录:可以形成环。(很少见)
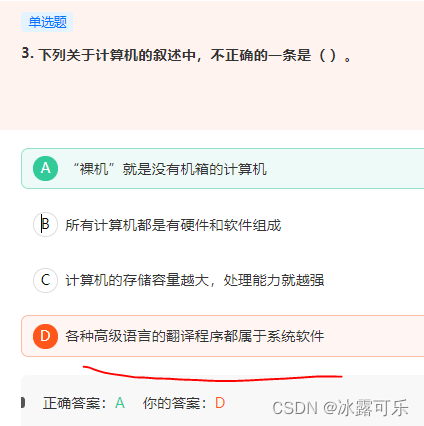
裸机是没有操作系统
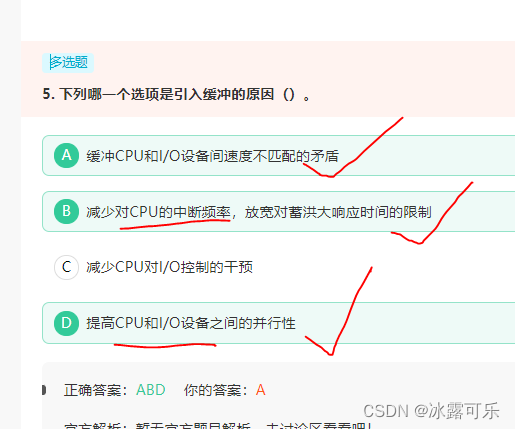
下列哪一个选项是引入缓冲的原因()。
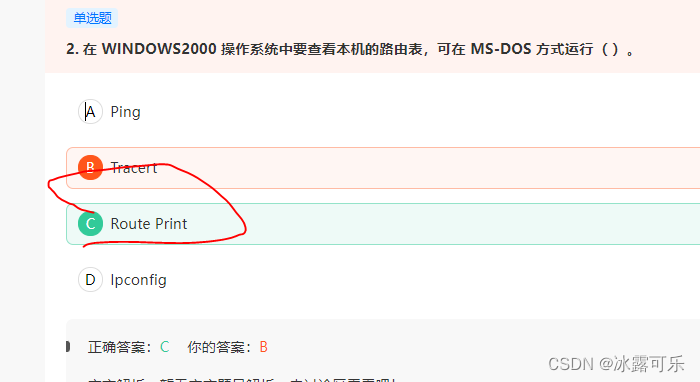
在 WINDOWS2000 操作系统中要查看本机的路由表,可在 MS-DOS 方式运行( )。
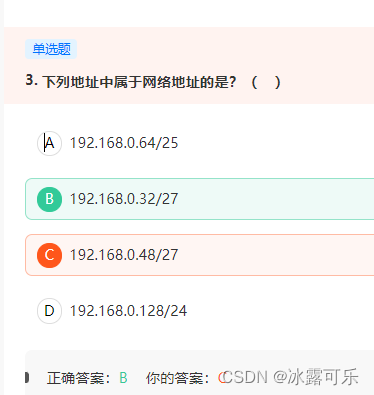
下列地址中属于网络地址的是?( )
链接:https://www.nowcoder.com/questionTerminal/bf23a30ca99b416c9da377c3fe71ca9b
来源:牛客网
网络号与主机号用空格分开
64/25 = 0 1000000
32/27 = 001 00000
48/27 = 001 10000
128/24 = 10000000
一般主机号全为0表示网络地址,主机号全为1表示广播地址。
属于网络地址的话,后边主机号全为0。只有B满足
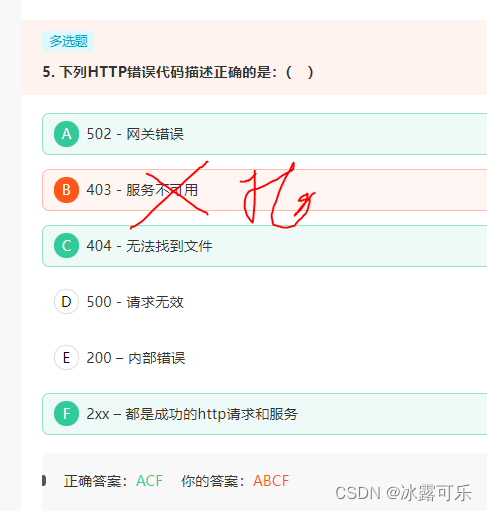
403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。