CenterMask是一个anchor free的实例分割模型,
来自paper: CenterMask: Real-Time Anchor-Free Instance Segmentation
提起anchor free, 会想到FCOS模型,是用来目标检测的,
那么这里就用到了FCOS, 不过换了backbone,
在FCOS检测出目标框后,提取目标框内的特征,用了一个SAG Mask, 这是一个spatial attention module,
这个attention的输出会和输入端相乘,再上采样,过1x1 conv, 就得到了每个class的mask,
具体见下面的结构图:

backbone的改进
backbone用的是VoVNetV2, 改进自VoVNet(paper),这篇paper没有看,就不在这里展开了,但是有几个改进的点如下。
1.OSA模块添加residual connection
把OSA模块叠加之后,发现效果是下降的,比如VoVNetV1-99, 作者联想到和ResNet的原理有关,于是在每个OSA模块中都添加了residual connection, 提升了效果。
2.eSE channel attention
VoVNet中用的是SE(Squeeze-Excitation)channel attention, 作者发现FC layer会减少channel size, 引起channel信息的损失。所以将两个FC layer换成了一个,保持了channel的维度,防止信息的损失,提升了效果。
改进后成为effective SE (eSE).

前面说了,CenterMask是在FCOS预测的目标框基础上提取mask,
类似Mask R-CNN,
ROI是根据FPN中不同层的feature中预测的,所以ROI Align也应该从FPN的不同层中提取特征。
至于在哪个层中提取,有一个函数。
Adaptive RoI Assignment Function的改进
直觉上来说,大尺寸的ROI对应的感受野大,应该从FPN的高层中提取feature,反之同样。
在Mask R-CNN中,FPN的层数是这样指定的:

k0是4,w,h是每个ROI的宽和高。
224是imageNet的输入,这个是写S的。
也就是说,看ROI和input size的比例,以4层为中心移动,
如果刚好w和h都是224, 那么log项为0,就从第4层提取,如果w和h都是112,log项为-1,k=3。
但是这个公式不适用于FCOS,想必你们也能看出来,首先224写S的这一项就不符合,
如果input size变了呢。
另外,公式(1)中中心层设的是4,以第4层为中心移动,这个是two-stage detector适用的,
因为two-stage用的是P2~P5层。
但是one-stage用的是P3~P7层。
所以作者做了如下改进:

直接用了input size和ROI size的比例,用最大层去减,就不存在几个写S的问题。
这样做可以提高小目标的AP。
作者设
k
m
a
x
k_{max}
kmax为P5,
k
m
i
n
k_{min}
kmin为P3.
SAG Mask
这个是从ROI region中提取attention feature的部分。
再来看下结构图。

在object detection领域,attention被广泛应用,其中,
channel attention强调了注意哪个channel, 强调的是"what",
而spatial attention强调的是"where", 注意哪个region.
所以这里用的是spatial attention. 强调的是注意哪些pixel.
上面图中,ROI区域内的feature被ROI Align (14x14)提取,然后送给4个conv和SAG Mask。
设SAM的输入为
X
i
X_i
Xi, size为C x W x H,
可以看到SAM结构中,先把Xi分别过max pooling 和 avg pooling, 注意是沿channel进行pooling,
所以它们得到的结果都是1 x W x H, 把它们concatenate到一起,
再过一个3x3 conv, 再过一个sigmoid.
对应paper的如下部分:

当然了,现在得到的是一个attention map, 相当于一个权重map.
还需要和input的Xi相乘,会得到一个attention guided feature map.

然后这个feature map 会过一个2x2的deconv, 上采样到28x28.
最后过一个1x1 conv得到每个class对应的mask.
实现细节
FCOS的超参调整,positive score 阈值从0.05降到0.03, 因为在初始训练时positive ROI产生不是太好。
还用了mask score来进一步过滤mask。
Lite版本把FPN的channel从256降到128以提升效率。
centerness branch是被box branch shared.
conv layer 和 channel的削减。
训练
FCOS的detection box个数设为100个,其中score最高的放进SAG mask branch作为训练.
mask target选择和gt mask的ROI较大的。
损失函数加上
L
m
a
s
k
L_{mask}
Lmask, 也就是BCE loss。

Ablation study
SAM和Mask score.

Feature level的选取,
所以前面的
k
m
a
x
k_{max}
kmax取5,
k
m
i
n
k_{min}
kmin取3。

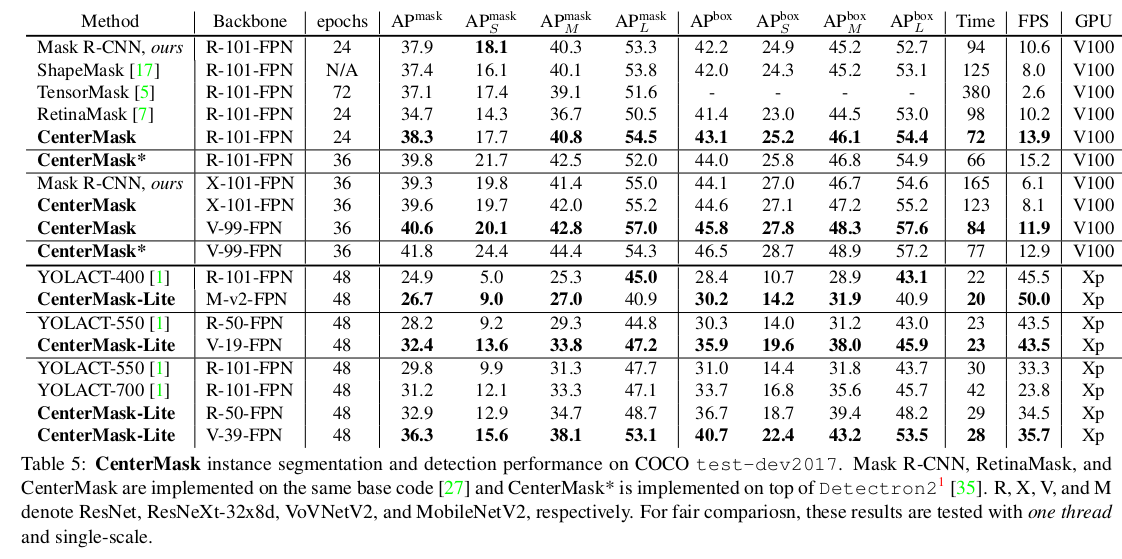
各种method比较