7.4 数据保存的过程
注意:数据的存储,都需要注意Region的分裂
- HDFS:数据的平衡 ——> 数据的移动(拷贝)
- HBase:数据越来越多 ——> Region的分裂 ——> 数据的移动(拷贝)

业务越来越大,数据越来越大,必然会发生Region的分裂。
运维:可以通过增加节点,或者预分配的方式
7.5 HBase的过滤器
过滤器:相当于SQL语句中的where查询条件
使用下面java程序操作HBase,仅需要修改IP地址
package demo.filter;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Test;
public class DataInit {
@Test
public void testCreateTable() throws Exception{
//指定的配置信息: ZooKeeper
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.157.111");
//创建一个HBase客户端: HBaseAdmin
HBaseAdmin admin = new HBaseAdmin(conf);
//创建一个表的描述符: 表名
HTableDescriptor hd = new HTableDescriptor(TableName.valueOf("emp"));
//创建列族描述符
HColumnDescriptor hcd1 = new HColumnDescriptor("empinfo");
//加入列族
hd.addFamily(hcd1);
//创建表
admin.createTable(hd);
//关闭客户端
admin.close();
}
@Test
public void testPutData() throws Exception{
//指定的配置信息: ZooKeeper
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.157.111");
//客户端
HTable table = new HTable(conf, "emp");
//第一条数据
Put put1 = new Put(Bytes.toBytes("7369"));
put1.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("SMITH"));
Put put2 = new Put(Bytes.toBytes("7369"));
put2.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("800"));
//第二条数据
Put put3 = new Put(Bytes.toBytes("7499"));
put3.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("ALLEN"));
Put put4 = new Put(Bytes.toBytes("7499"));
put4.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1600"));
//第三条数据
Put put5 = new Put(Bytes.toBytes("7521"));
put5.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("WARD"));
Put put6 = new Put(Bytes.toBytes("7521"));
put6.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1250"));
//第四条数据
Put put7 = new Put(Bytes.toBytes("7566"));
put7.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("JONES"));
Put put8 = new Put(Bytes.toBytes("7566"));
put8.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("2975"));
//第五条数据
Put put9 = new Put(Bytes.toBytes("7654"));
put9.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("MARTIN"));
Put put10 = new Put(Bytes.toBytes("7654"));
put10.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1250"));
//第六条数据
Put put11 = new Put(Bytes.toBytes("7698"));
put11.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("BLAKE"));
Put put12 = new Put(Bytes.toBytes("7698"));
put12.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("2850"));
//第七条数据
Put put13 = new Put(Bytes.toBytes("7782"));
put13.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("CLARK"));
Put put14 = new Put(Bytes.toBytes("7782"));
put14.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("2450"));
//第八条数据
Put put15 = new Put(Bytes.toBytes("7788"));
put15.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("SCOTT"));
Put put16 = new Put(Bytes.toBytes("7788"));
put16.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("3000"));
//第九条数据
Put put17 = new Put(Bytes.toBytes("7839"));
put17.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("KING"));
Put put18 = new Put(Bytes.toBytes("7839"));
put18.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("5000"));
//第十条数据
Put put19 = new Put(Bytes.toBytes("7844"));
put19.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("TURNER"));
Put put20 = new Put(Bytes.toBytes("7844"));
put20.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1500"));
//第十一条数据
Put put21 = new Put(Bytes.toBytes("7876"));
put21.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("ADAMS"));
Put put22 = new Put(Bytes.toBytes("7876"));
put22.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1100"));
//第十二条数据
Put put23 = new Put(Bytes.toBytes("7900"));
put23.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("JAMES"));
Put put24 = new Put(Bytes.toBytes("7900"));
put24.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("950"));
//第十三条数据
Put put25 = new Put(Bytes.toBytes("7902"));
put25.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("FORD"));
Put put26 = new Put(Bytes.toBytes("7902"));
put26.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("3000"));
//第十四条数据
Put put27 = new Put(Bytes.toBytes("7934"));
put27.add(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"), Bytes.toBytes("MILLER"));
Put put28 = new Put(Bytes.toBytes("7934"));
put28.add(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), Bytes.toBytes("1300"));
//构造List
List<Put> list = new ArrayList<Put>();
list.add(put1);
list.add(put2);
list.add(put3);
list.add(put4);
list.add(put5);
list.add(put6);
list.add(put7);
list.add(put8);
list.add(put9);
list.add(put10);
list.add(put11);
list.add(put12);
list.add(put13);
list.add(put14);
list.add(put15);
list.add(put16);
list.add(put17);
list.add(put18);
list.add(put19);
list.add(put20);
list.add(put21);
list.add(put22);
list.add(put23);
list.add(put24);
list.add(put25);
list.add(put26);
list.add(put27);
list.add(put28);
//插入数据
table.put(list);
table.close();
}
}

常见的过滤器
列值过滤器:select * from emp where sal = 3000;
列名前缀过滤器:查询员工的姓名 select ename form emp;
多个列名前缀过滤器:查询员工的姓名、薪水 select ename, sal from emp;
行键过滤器:通过Row可以查询,类似通过Get查询数据
组合几个过滤器查询数据:where 条件1 and(or)条件2
public class TestHBaseFilter {
@Test
public void testSingleColumnValueFilter() throws Exception{
//列值过滤器: 查询薪水等于3000的员工
// select * from emp where sal=3000
//配置ZooKeeper
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.157.111");
//得到客户端
HTable table = new HTable(conf,"emp");
//定义一个过滤器
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("empinfo"), //列族
Bytes.toBytes("sal"), //列名
CompareOp.EQUAL, //比较运算符
Bytes.toBytes("3000")); //值
//定义一个扫描器
Scan scan = new Scan();
scan.setFilter(filter);
//查询数据:结果中只有员工姓名
ResultScanner rs = table.getScanner(scan);
for(Result r:rs){
String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
System.out.println(name);
}
table.close();
}
@Test
public void testColumnPrefixFilter() throws Exception{
//列名前缀过滤器 查询员工的姓名: select ename from emp;
//配置ZooKeeper
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.157.111");
//得到客户端
HTable table = new HTable(conf,"emp");
//定义一个过滤器
ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes("ename"));
//定义一个扫描器
Scan scan = new Scan();
scan.setFilter(filter);
//查询数据:结果中只愿员工的姓名
ResultScanner rs = table.getScanner(scan);
for(Result r:rs){
String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
//获取员工的薪水
String sal = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));
System.out.println(name+"\t"+sal);
}
table.close();
}
@Test
public void testMultipleColumnPrefixFilter() throws Exception{
//多个列名前缀过滤器
//查询员工信息:员工姓名 薪水
//配置ZooKeeper
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.157.11");
//得到客户端
HTable table = new HTable(conf,"emp");
//二维数组
byte[][] names = {Bytes.toBytes("ename"),Bytes.toBytes("sal")};
//定义一个过滤器
MultipleColumnPrefixFilter filter = new MultipleColumnPrefixFilter(names);
//定义一个扫描器
Scan scan = new Scan();
scan.setFilter(filter);
//查询数据
ResultScanner rs = table.getScanner(scan);
for(Result r:rs){
String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
//获取员工的薪水
String sal = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));
System.out.println(name+"\t"+sal);
}
table.close();
}
@Test
public void testRowFilter() throws Exception{
//查询员工号7839的信息
//配置ZooKeeper
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.157.11");
//得到客户端
HTable table = new HTable(conf,"emp");
//定义一个行键过滤器
RowFilter filter = new RowFilter(CompareOp.EQUAL, //比较运算符
new RegexStringComparator("7839")); //使用正则表达式来代表值
//定义一个扫描器
Scan scan = new Scan();
scan.setFilter(filter);
//查询数据
ResultScanner rs = table.getScanner(scan);
for(Result r:rs){
String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
//获取员工的薪水
String sal = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));
System.out.println(name+"\t"+sal);
}
table.close();
}
@Test
public void testFilter() throws Exception{
/*
* 查询工资等于3000的员工姓名 select ename from emp where sal=3000;
* 1、列值过滤器:工资等于3000
* 2、列名前缀过滤器:姓名
*/
//配置ZooKeeper
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.157.11");
//得到客户端
HTable table = new HTable(conf,"emp");
//第一个过滤器 列值过滤器:工资等于3000
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(Bytes.toBytes("empinfo"), //列族
Bytes.toBytes("sal"), //列名
CompareOp.EQUAL, //比较运算符
Bytes.toBytes("3000")); //值
//第二个过滤器:列名前缀 姓名
ColumnPrefixFilter filter2 = new ColumnPrefixFilter(Bytes.toBytes("ename"));
//创建一个FliterList
//Operator.MUST_PASS_ALL 相当于 and
//Operator.MUST_PASS_ONE 相当于 or
FilterList list = new FilterList(Operator.MUST_PASS_ALL);
list.addFilter(filter1);
list.addFilter(filter2);
//定义一个扫描器
Scan scan = new Scan();
scan.setFilter(list);
//查询数据
ResultScanner rs = table.getScanner(scan);
for(Result r:rs){
String name = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename")));
//获取员工的薪水
String sal = Bytes.toString(r.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal")));
System.out.println(name+"\t"+sal);
}
table.close();
}
}

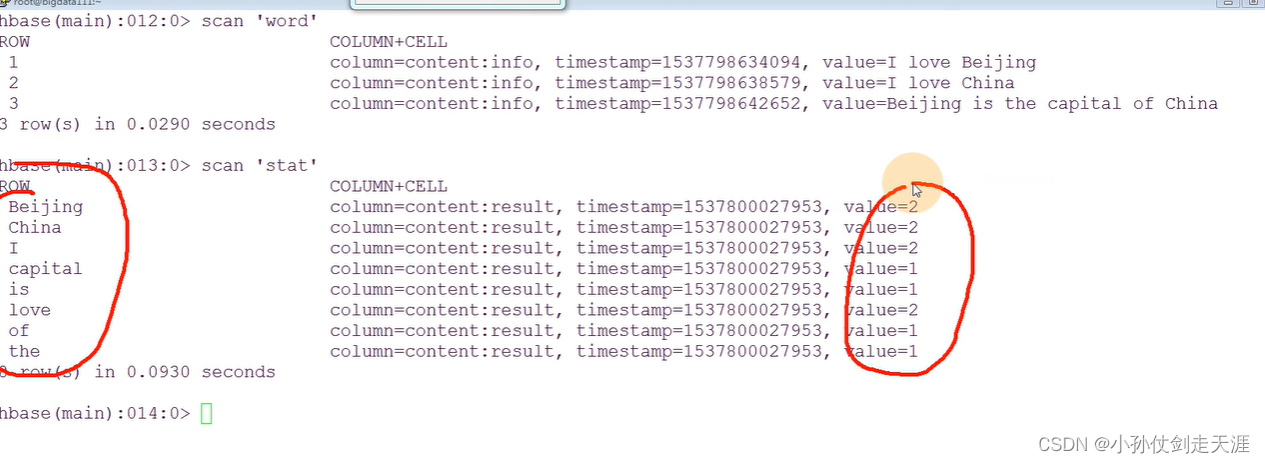
7.6 HBase上的MapReduce
1、建立输入的表
create 'word','content'
put 'word','1','content:info','I love Beijing'
put 'word','2','content:info','I love China'
put 'word','3','content:info','Beijing is the capital of China'
2、输出表:
create 'stat','content'
注意:export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:$CLASSPATH
Mapper程序
//这时候处理的就是HBase表的一条数据
//没有k1和v1,<k1 v1>代表输入,因为输入的就是表中一条记录
public class WordCountMapper extends TableMapper<Text, IntWritable> {
@Override
protected void map(ImmutableBytesWritable key, Result value,Context context)
throws IOException, InterruptedException {
/*
* key和value代表从表中输入的一条记录
* key: 行键
* value:数据
*/
//获取数据: I love beijing
String data = Bytes.toString(value.getValue(Bytes.toBytes("content"), Bytes.toBytes("info")));
//分词
String[] words = data.split(" ");
for(String w:words){
context.write(new Text(w), new IntWritable(1));
}
}
}
Reducer程序
// k3 v3 keyout代表输出的一条记录:指定行键
public class WordCountReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3,Context context)
throws IOException, InterruptedException {
// 对v3求和
int total = 0;
for(IntWritable v:v3){
total = total + v.get();
}
//输出:也是表中的一条记录
//构造一个Put对象,把单词作为rowkey行键
Put put = new Put(Bytes.toBytes(k3.toString()));
put.add(Bytes.toBytes("content"), //列族
Bytes.toBytes("result"), //列
Bytes.toBytes(String.valueOf(total))
);
//输出
context.write(new ImmutableBytesWritable(Bytes.toBytes(k3.toString())), //把这个单词作为key 就是输出的行键
put); //表中的一条记录,得到的结果
}
}
main程序
public class WordCountMain {
public static void main(String[] args) throws Exception {
//获取ZK的地址
//指定的配置信息: ZooKeeper
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "192.168.157.111");
//创建一个任务,指定程序的入口
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountMain.class);
//定义一个扫描器 只读取:content:info这个列的数据
Scan scan = new Scan();
//可以使用filter,还有一种方式来过滤数据
scan.addColumn(Bytes.toBytes("content"), Bytes.toBytes("info"));
//指定mapper,使用工具类设置Mapper
TableMapReduceUtil.initTableMapperJob(Bytes.toBytes("word"), //输入的表
scan, //扫描器,只读取想要处理的数据
WordCountMapper.class,
Text.class,
IntWritable.class,
job);
//指定Reducer,使用工具类设置Reducer
TableMapReduceUtil.initTableReducerJob("stat", WordCountReducer.class, job);
//执行任务
job.waitForCompletion(true);
}
}
将编写的程序打包成jar包,上传到全分布或者伪分布环境下,启动环境运行,会有一个exception异常。
在Hadoop集群上会去访问HBase,需要HBase依赖

注意:export HADOOP_CLASSPATH= H B A S E H O M E / l i b / ∗ : HBASE_HOME/lib/*: HBASEHOME/lib/∗:CLASSPATH