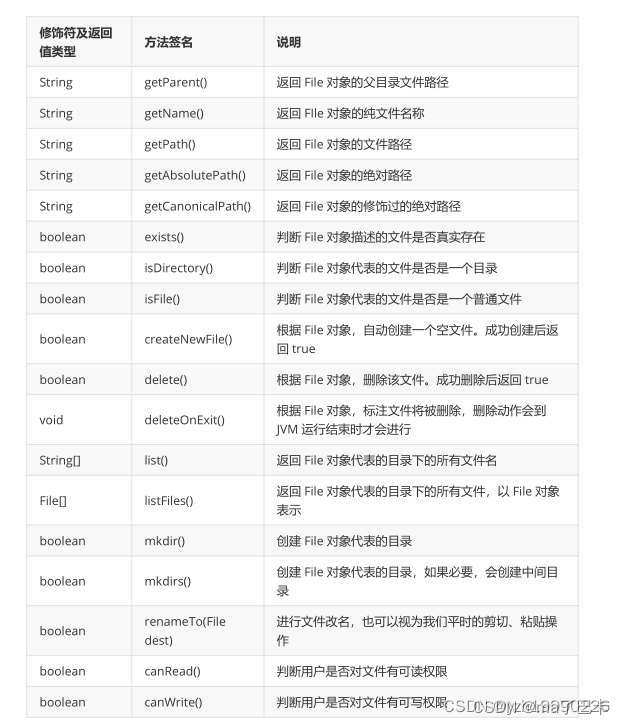
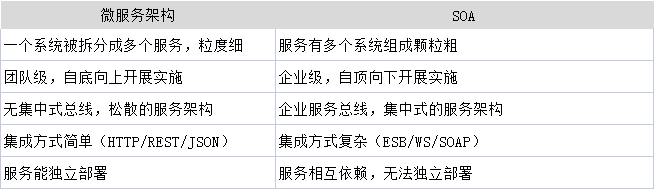
题目描述
给定一个长度为 N 的数组 A = [A_1,A_2,··· ,A_N],数组中有可能有重复出现的整数。
现在小明要按以下方法将其修改为没有重复整数的数组。小明会依次修改A_2,A_3,··· ,A_N当修改 A_i时,小明会检查 A_i是否在 A_1 ∼ A_i−1中出现过。如果出现过,则小明会给 A_i加上 1 ;如果新的 A_i仍在之前出现过,小明会持续给 A_i加 1 ,直 到 A_i没有在 A_1∼ A_i−1−1 中出现过。当 A_N也经过上述修改之后,显然 A 数组中就没有重复的整数了。
现在给定初始的 A 数组,请你计算出最终的 A 数组。
输入描述
第一行包含一个整数 N。
第二行包含 N 个整数 A_1,A_2,··· ,A_N。
其中,1≤N≤10^5
,1≤A i ≤10^6 。
输出描述
输出 N 个整数,依次是最终的 A_1,A_2,··· ,A_N 。
输入输出样例
示例
输入
5
2 1 1 3 4
输出
2 1 3 4 5
运行限制
最大运行时间:1s
最大运行内存: 256M
所需变量
int a[2000005] = 0;//定义一个长度为2000005长度的数组变量a
int b[100005];//定义一个b数组,方便接收每一个输入进来的数
int N;//代表有多少个数
int control;//用于去表示b[i],找到没有过的数,然后进行判断
总思路:我们首先接收N,表示有多少个数,然后一个一个接收这些数,当然啦,每接收一个我就判断以这个数为下标的数组a中是否已经有,如果没有,我们就把数组a中以这个数为小标的赋值为1,如果有的话,那么我们就不断往后寻找,知道寻找到不为1的数,然后将这个下标改为这个数(这个就是本题目的意思)
第一次代码如下(编译器是dev,语言是C语言):
#include <iostream>
using namespace std;
int main()
{
// 请在此输入您的代码
int a[2000005] = {0},b[100005];
int N,control = 0;
cin>>N;
for(int i = 0;i < N;i++){
cin>>b[i];
if(a[b[i]] == 0){
a[b[i]] = 1;
}else if(a[b[i]] == 1){
control = b[i];
while(a[control] == 1){
control++;
}
b[i] = control;
a[control] = 1;
}
}
for(int i = 0;i< N;i++){
if(i == 0){
cout<<b[i];
}else{
cout<<" "<<b[i];
}
}
//cout<<endl;
return 0;
}

这样做完后,发现运行超时,好家伙,我就觉得肯定是有一连串的1,举个例子,可能有很多个2输入进去,一直连续到1000,那么我们后面输入2,也还是从2开始不断地往后判断,3,4,5,6…一直到1001,这样其实是做不断循环的操作,那么我们对上面的代码进行改进,那就是,当2这个数出现后,一直判断到1000,那么我们就把数组a中的a[2]改为10001,这样他下次判断就直接从1001开始,如果还是很多个2,直到5000,那么a[2]的值就是5001,这样做完后,时间复杂度大大降低,因此我们也通过了此题目!
该算法本人认为还是比较优,如果有更好的想法,欢迎q我!
第二次修改后的代码如下(编译器是dev,语言是C语言):
#include <iostream>
using namespace std;
int main()
{
// 请在此输入您的代码
int a[2000005] = {0},b[100005];
int N,control = 0;
cin>>N;
for(int i = 0;i < N;i++){
cin>>b[i];
if(a[b[i]] == 0){
a[b[i]] = 1;
}else{
control = b[i];
if(a[control]!=1){
control = a[control];
}
while(a[control] != 0 ){
control++;
}
a[b[i]] = control;
b[i] = control;
a[control] = 1;
}
}
for(int i = 0;i< N;i++){
if(i == 0){
cout<<b[i];
}else{
cout<<" "<<b[i];
}
}
//cout<<endl;
return 0;
}