前言
大家早好、午好、晚好吖 ❤ ~

本次内容:
Python 采集世界大学排行榜 并做数据可视化
知识点:
-
动态数据抓包
-
requests发送请求
-
结构化+非结构化数据解析
开发环境:
-
python 3.8 运行代码
-
pycharm 2021.2 辅助敲代码
-
requests 第三方模块 pip install 模块名
本次文章案例教程、源码料找小钰老师微信: python5180
+ python安装包 安装教程视频
+ pycharm 社区版 专业版 及 免费
代码展示
数据采集
代码里网址被我删了好过审核, ( 源码、教程、文档、软件点击此处跳转跳转文末名片+找管理员领取呀~ )
import requests # 发送请求 第三方模块
import re
import csv
def replace(str):
str = re.sub('<.*?>', '', str)
return str
乱码和代码没关系, 软件有关系
每一个软件打开文件的编码方式不一样
f = open('排名.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.writer(f)
请求链接
url = 'https://www.***.cn/sites/default/files/qs-rankings-data/cn/2057712.txt?_=1669724480772'
发送请求
response = requests.get(url)
获取数据
.text: 获取文本数据的
.json(): 获取 {}/[] 所包裹的数据 字符串类型 ==> 字典/列表 Python基础里面的数据容器
.content: 获取 音频/视频/图片 数据的
json_data = response.json()
解析数据 提取数据
data_list = json_data['data']
for data in data_list:
country = data['country']
title = replace(data['title'])
ind_0 = replace(data['ind_0'])
ind_1 = replace(data['ind_1'])
ind_2 = replace(data['ind_2'])
rank_0 = data['rank_0']
rank_d_0 = replace(data['rank_d_0'])
rank_d_1 = replace(data['rank_d_1'])
score = data['score']
region = data['region']
print(country, title, ind_0, ind_1, ind_2, rank_0, rank_d_0, rank_d_1, score, region)
保存数据
csv_writer.writerow([country, title, ind_0, ind_1, ind_2, rank_0, rank_d_0, rank_d_1, score, region])
详情 / 相对应的安装包/安装教程/激活码/使用教程/学习资料/工具插件 可以点击免费领取
数据可视化
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
from pyecharts.components import Table
import re
import pandas as pd
df = pd.read_csv('rank.csv')
香港,澳门与中国大陆地区等在榜单中是分开的记录的,这边都归为china
df['loc'] = df['country']
df['country'].replace(['China (Mainland)', 'Hong Kong SAR', 'Taiwan', 'Macau SAR'],'China',inplace=True)
tool_js = """
<div style="border-bottom: 1px solid rgba(255,255,255,.3); font-size: 18px;padding-bottom: 7px;margin-bottom: 7px">
{}
</div>
排名:{} <br>
国家地区:{} <br>
加权总分:{} <br>
国际学生:{} <br>
国际教师:{} <br>
师生比例:{} <br>
学术声誉:{} <br>
雇主声誉:{} <br>
教员引用率:{} <br>
"""
t_data = df[(df.year==2021) & (df['rank']<=100)]
t_data = t_data.sort_values(by="total_score" , ascending=True)
university, score = [], []
for idx, row in t_data.iterrows():
tjs = tool_js.format(row['university'], row['rank'], row['country'],row['total_score'],
row['score_6'],row['score_5'], row['score_3'],row['score_1'],row['score_2'], row['score_4'])
if row['country'] == 'China':
university.append('🇨🇳 {}'.format(re.sub('(.*?)', '',row['university'])))
else:
university.append(re.sub('(.*?)', '',row['university']))
score.append(opts.BarItem(name='', value=row['total_score'], tooltip_opts=opts.TooltipOpts(formatter=tjs)))

bar = (Bar()
.add_xaxis(university)
.add_yaxis('', score, category_gap='30%')
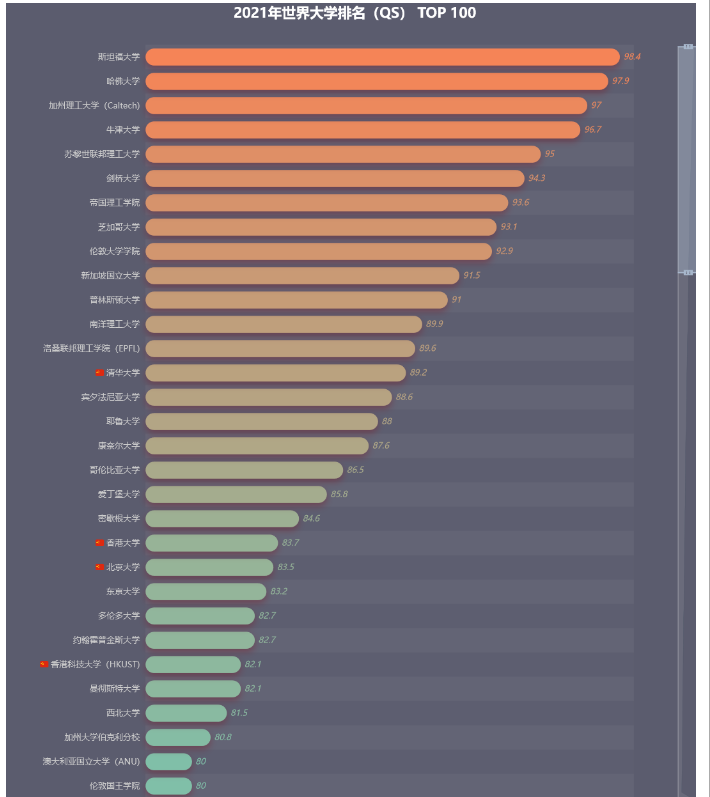
.set_global_opts(title_opts=opts.TitleOpts(title="2021年世界大学排名(QS) TOP 100",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(font_size=20)),
datazoom_opts=opts.DataZoomOpts(range_start=70, range_end=100, orient='vertical'),
visualmap_opts=opts.VisualMapOpts(is_show=False, max_=100, min_=60, dimension=0,
range_color=['#00FFFF', '#FF7F50']),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(is_show=False, is_scale=True),
yaxis_opts=opts.AxisOpts(axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(is_show=False),
axislabel_opts=opts.LabelOpts(font_size=12)))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='right',
font_style='italic'),
itemstyle_opts={"normal": {
"barBorderRadius": [30, 30, 30, 30],
'shadowBlur': 10,
'shadowColor': 'rgba(120, 36, 50, 0.5)',
'shadowOffsetY': 5,
}
}
).reversal_axis())
grid = (
Grid(init_opts=opts.InitOpts(theme='purple-passion', width='1000px', height='1200px'))
.add(bar, grid_opts=opts.GridOpts(pos_right='10%', pos_left='20%'))
)
grid.render_notebook()
tool_js = """
<div style="border-bottom: 1px solid rgba(255,255,255,.3); font-size: 18px;padding-bottom: 7px;margin-bottom: 7px">
{}
</div>
世界排名:{} <br>
国家地区:{} <br>
加权总分:{} <br>
国际学生:{} <br>
国际教师:{} <br>
师生比例:{} <br>
学术声誉:{} <br>
雇主声誉:{} <br>
教员引用率:{} <br>
"""
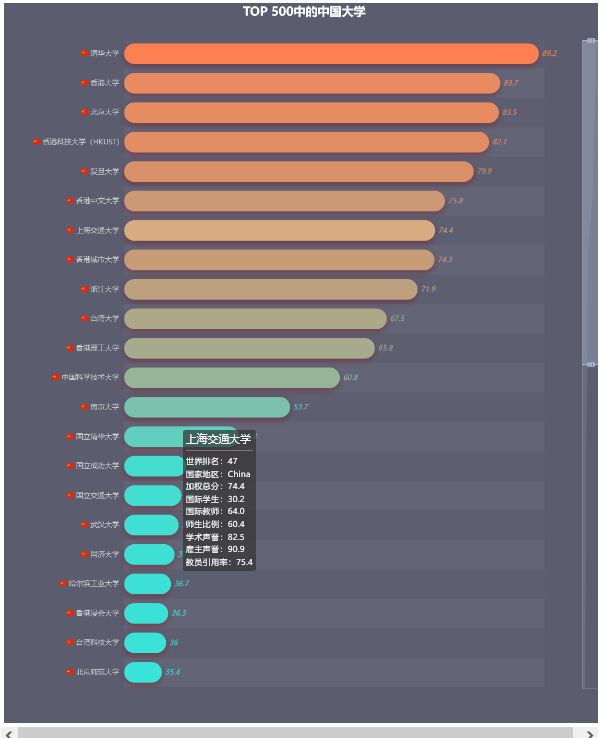
t_data = df[(df.country=='China') & (df['rank']<=500)]
t_data = t_data.sort_values(by="total_score" , ascending=True)
university, score = [], []
for idx, row in t_data.iterrows():
tjs = tool_js.format(row['university'], row['rank'], row['country'],row['total_score'],
row['score_6'],row['score_5'], row['score_3'],row['score_1'],row['score_2'], row['score_4'])
if row['country'] == 'China':
university.append('🇨🇳 {}'.format(re.sub('(.*?)', '',row['university'])))
else:
university.append(re.sub('(.*?)', '',row['university']))
score.append(opts.BarItem(name='', value=row['total_score'], tooltip_opts=opts.TooltipOpts(formatter=tjs)))

bar = (Bar()
.add_xaxis(university)
.add_yaxis('', score, category_gap='30%')
.set_global_opts(title_opts=opts.TitleOpts(title="TOP 500中的中国大学",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(font_size=20)),
datazoom_opts=opts.DataZoomOpts(range_start=50, range_end=100, orient='vertical'),
visualmap_opts=opts.VisualMapOpts(is_show=False, max_=90, min_=20, dimension=0,
range_color=['#00FFFF', '#FF7F50']),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(is_show=False, is_scale=True),
yaxis_opts=opts.AxisOpts(axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(is_show=False),
axislabel_opts=opts.LabelOpts(font_size=12)))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='right',
font_style='italic'),
itemstyle_opts={"normal": {
"barBorderRadius": [30, 30, 30, 30],
'shadowBlur': 10,
'shadowColor': 'rgba(120, 36, 50, 0.5)',
'shadowOffsetY': 5,
}
}
).reversal_axis())
grid = (
Grid(init_opts=opts.InitOpts(theme='purple-passion', width='1000px', height='1200px'))
.add(bar, grid_opts=opts.GridOpts(pos_right='10%', pos_left='20%'))
)
grid.render_notebook()

t_data = df[(df.year==2021) & (df['rank']<=1000)]
t_data = t_data.groupby(['region'])['university'].count().reset_index()
t_data.columns = ['region', 'num']
t_data = t_data.sort_values(by="num" , ascending=False)
bar = (Bar(init_opts=opts.InitOpts(theme='purple-passion', width='1000px', height='600px'))
.add_xaxis(t_data['region'].tolist())
.add_yaxis('出现次数', t_data['num'].tolist(), category_gap='50%')
.set_global_opts(title_opts=opts.TitleOpts(title="TOP 1000高校按大洲分布",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(font_size=20)),
visualmap_opts=opts.VisualMapOpts(is_show=False, max_=300, min_=0, dimension=1,
range_color=['#00FFFF', '#FF7F50']),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(is_show=False),
axislabel_opts=opts.LabelOpts(font_size=15)),
yaxis_opts=opts.AxisOpts(is_show=False))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='top',
font_size=15,
font_style='italic'),
itemstyle_opts={"normal": {
"barBorderRadius": [30, 30, 30, 30],
'shadowBlur': 10,
'shadowColor': 'rgba(120, 36, 50, 0.5)',
'shadowOffsetY': 5,
}
}
))
bar.render_notebook()

# 以下国家单独在地图上显示出来
country_list = ['China', 'United States', 'Brazil', 'United Kingdom', 'Canada', 'Russia', 'India']
# 对应国家的经纬度
loc = {
'Brazil': [-51.92528, -14.235004],
'Canada': [-106.346771, 56.130366],
'China': [104.195397, 35.86166],
'India': [78.96288, 20.593684],
'United Kingdom': [-3.435973, 55.378051],
'United States': [-95.712891, 37.09024],
'Russia': [116.8564, 65.067703],
}
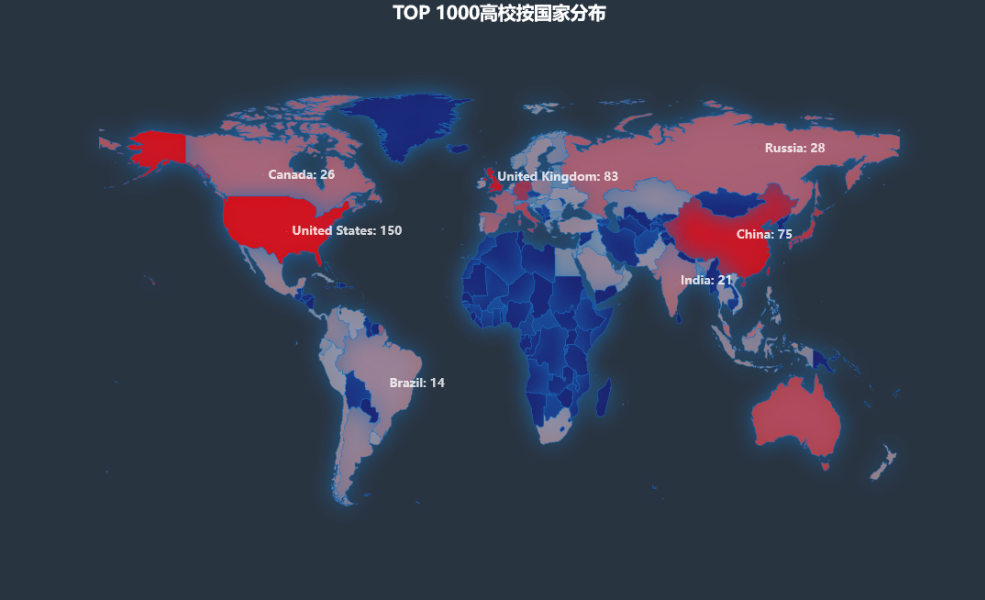
t_data = df[(df.year==2021) & (df['rank']<=1000)]
t_data = t_data.groupby(['country'])['university'].count().reset_index()
t_data.columns = ['country', 'num']
t_data = t_data.sort_values(by="num" , ascending=True)
data_pair = []
for idx, row in t_data.iterrows():
if row['country'] in ['China (Mainland)', 'Hong Kong SAR', 'Taiwan', 'Macau SAR']:
data_pair.append(['China', row['num']])
else:
data_pair.append([row['country'], row['num']])

fmt_js = """function (params) {return params.name+': '+Number(params.value[2]);}"""
mp = Map()
mp.add(
"高校数量",
data_pair,
"world",
is_map_symbol_show=False,
is_roam=False)
mp.set_series_opts(label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts={'normal': {
'areaColor': '#191970',
'borderColor': '#1773c3',
'shadowColor': '#1773c3',
'shadowBlur': 20,
'opacity': 0.8
}
})
mp.set_global_opts(
title_opts=opts.TitleOpts(title="TOP 1000高校按国家分布", pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(font_size=18)),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(is_show=False,
max_=100,
is_piecewise=False,
dimension=0,
range_color=['rgba(255,228,225,0.6)', 'rgba(255,0,0,0.9)', 'rgba(255,0,0,1)'])
)
data_pair = [[x, y] for x, y in data_pair if x in country_list]
geo = Geo()
# 需要先将几个国家的经纬度信息加入到geo中
for k, v in loc.items():
geo.add_coordinate(k, v[0], v[1])
# 这里将geo的地图透明度配置为0
geo.add_schema(maptype="world", is_roam=False, itemstyle_opts={'normal': {'opacity': 0}})
geo.add("", data_pair, symbol_size=1)
# 显示标签配置
geo.set_series_opts(
label_opts=opts.LabelOpts(
is_show=True,
position='right',
color='white',
font_size=12,
font_weight='bold',
formatter=JsCode(fmt_js)),
)
grid = (
Grid(init_opts=opts.InitOpts(theme='chalk', width='1000px', height='600px'))
.add(mp, grid_opts=opts.GridOpts(pos_top="12%"))
.add(geo, grid_opts=opts.GridOpts(pos_bottom="12%"))
)
grid.render_notebook()
t_data = df[(df.year==2021) & (df['rank']<=1000)]
t_data = t_data.groupby(['region', 'country'])['university'].count().reset_index()
t_data.columns = ['region', 'country', 'num']
#t_data.num = round(t_data.num.div(t_data.num.sum(axis=0), axis=0) * 100, 1)
data_pair = [
{"name": 'Europe',
"label":{"show": True},
"children": []},
{"name": 'Asia',
"label":{"show": True},
"children": []},
{"name": 'North America',
"label":{"show": True},
'shadowBlur': 10,
'shadowColor': 'rgba(120, 36, 50, 0.5)',
'shadowOffsetY': 5,
"children": []},
{"name": 'Latin America',
"label":{"show": True},
"children": []},
{"name": 'Oceania',
"label":{"show": True},
"children": []},
{"name": 'Africa',
"label":{"show": False},
"children": []}
]
for idx, row in t_data.iterrows():
t_dict = {"name": row.country,
"label":{"show": True},
"children": []}
if row.num > 15:
child_data = {"name": row.country, "value":row.num, "label":{"show": True}}
else:
child_data = {"name": row.country, "value":row.num, "label":{"show": False}}
if row.region == "Europe":
data_pair[0]['children'].append(child_data)
elif row.region == "Asia":
data_pair[1]['children'].append(child_data)
elif row.region == "North America":
data_pair[2]['children'].append(child_data)
elif row.region == "Latin America":
data_pair[3]['children'].append(child_data)
elif row.region == "Oceania":
data_pair[4]['children'].append(child_data)
elif row.region == "Africa":
data_pair[5]['children'].append(child_data)
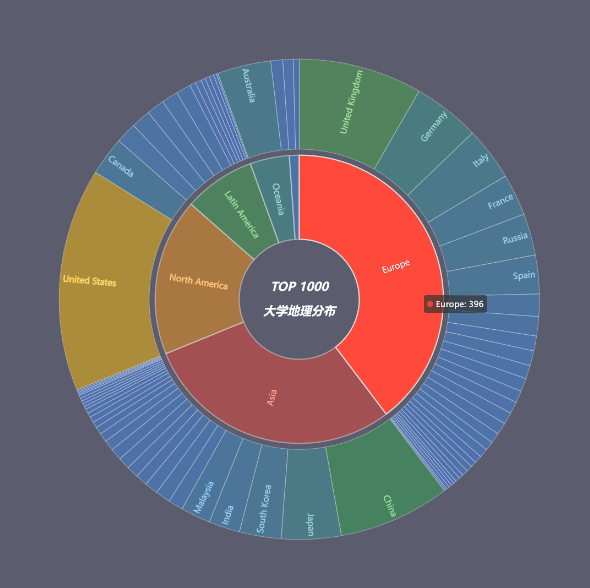
c = (Sunburst(
init_opts=opts.InitOpts(
theme='purple-passion',
width="1000px",
height="1000px"))
.add(
"",
data_pair=data_pair,
highlight_policy="ancestor",
radius=[0, "100%"],
sort_='null',
levels=[
{},
{
"r0": "20%",
"r": "48%",
"itemStyle": {"borderColor": 'rgb(220,220,220)', "borderWidth": 2}
},
{"r0": "50%", "r": "80%", "label": {"align": "right"},
"itemStyle": {"borderColor": 'rgb(220,220,220)', "borderWidth": 1}}
],
)
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(is_show=False, max_=300, min_=0, is_piecewise=False,
range_color=['#4285f4', '#34a853', '#fbbc05', '#ea4335', '#ea4335']),
title_opts=opts.TitleOpts(title="TOP 1000\n\n大学地理分布",
pos_left="center",
pos_top="center",
title_textstyle_opts=opts.TextStyleOpts(font_style='oblique', font_size=20),))
.set_series_opts(label_opts=opts.LabelOpts(font_size=14, formatter="{b}: {c}"))
)
c.render_notebook()

cn_data_x, cn_data_y = [], []
for idx, row in df[(df.country=='China') & (df['rank']<=1000)].iterrows():
cn_data_y.append([row['score_4'], row['score_1'], row['rank'], row['university']])
cn_data_x.append(row['score_3'])
un_data_x, un_data_y = [], []
for idx, row in df[(df.country=='United States') & (df['rank']<=1000)].iterrows():
un_data_y.append([row['score_4'], row['score_1'], row['rank'], row['university']])
un_data_x.append(row['score_3'])
uk_data_x, uk_data_y = [], []
for idx, row in df[(df.country=='United Kingdom') & (df['rank']<=1000)].iterrows():
uk_data_y.append([row['score_4'], row['score_1'], row['rank'], row['university']])
uk_data_x.append(row['score_3'])
tool_js = """
function (obj) {
var value = obj.value;
var schema = [{name: 'rank', index: 0, text: '总体排名'},
{name: 'score_1', index: 1, text: '学术声誉'},
{name: 'score_4', index: 2, text: '教员引用率'},
{name: 'score_3', index: 3, text: '师生比例'}];
return '<div style="border-bottom: 1px solid rgba(255,255,255,.3); font-size: 18px;padding-bottom: 7px;margin-bottom: 7px">'
+ value[4]
+ '</div>'
+ schema[0].text + ':' + value[3] + '<br>'
+ schema[1].text + ':' + value[2] + '<br>'
+ schema[2].text + ':' + value[1] + '<br>'
+ schema[3].text + ':' + value[0] + '<br>';
}
"""
itemStyle_1 = {
'opacity': 0.8,
'shadowBlur': 10,
'shadowOffsetX': 0,
'shadowOffsetY': 0,
'shadowColor': 'rgba(0, 0, 0, 0.5)',
'color': '#80F1BE'
}
itemStyle_2 = {
'opacity': 0.8,
'shadowBlur': 10,
'shadowOffsetX': 0,
'shadowOffsetY': 0,
'shadowColor': 'rgba(0, 0, 0, 0.5)',
'color': '#fec42c'
}
itemStyle_3 = {
'opacity': 0.8,
'shadowBlur': 10,
'shadowOffsetX': 0,
'shadowOffsetY': 0,
'shadowColor': 'rgba(0, 0, 0, 0.5)',
'color': '#dd4444'
}
visualMap = [
{
'left': 'right',
'top': '10%',
'dimension': 2,
'min': 20,
'max': 100,
'itemWidth': 30,
'itemHeight': 120,
'calculable': True,
'precision': 0.1,
'text': ['圆形大小:学术声誉'],
'textGap': 30,
'textStyle': {
'color': '#fff'
},
'inRange': {
'symbolSize': [10, 50]
},
'outOfRange': {
'symbolSize': [10, 50],
'color': ['rgba(255,255,255,.2)']
},
'controller': {
'inRange': {
'color': ['#c23531']
},
'outOfRange': {
'color': ['#444']
}
}
},
{
'left': 'right',
'bottom': '15%',
'dimension': 3,
'min': 1,
'max': 500,
'itemHeight': 120,
'precision': 0.1,
'text': ['明暗:总体排名'],
'textGap': 30,
'textStyle': {
'color': '#fff'
},
'inRange': {
'colorLightness': [0.5, 1]
},
'outOfRange': {
'color': ['rgba(255,255,255,.2)']
},
'controller': {
'inRange': {
'color': ['#c23531']
},
'outOfRange': {
'color': ['#444']
}
}
}
]
scatter1 = (Scatter(init_opts=opts.InitOpts(bg_color='#404a59',width='1000px', height='800px'))
.add_xaxis(cn_data_x)
.add_yaxis("中国", cn_data_y,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=itemStyle_3
)
.set_global_opts(yaxis_opts=opts.AxisOpts(name='教员引用率', type_="value", is_scale=True,
name_textstyle_opts={'color': '#fff', 'fontSize': 16},
axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(color='#eee'))),
xaxis_opts=opts.AxisOpts(name='师生比', type_="value", is_scale=True,
name_textstyle_opts={'color': '#fff', 'fontSize': 16},
axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(color='#eee'))),
tooltip_opts=opts.TooltipOpts(is_show=True, background_color='#222', border_color='#777', border_width=1, formatter=JsCode(tool_js)),
legend_opts=opts.LegendOpts(is_show=True, pos_right=10,
textstyle_opts=opts.TextStyleOpts(color='#fff',font_size=16)),
visualmap_opts=visualMap
)
)
scatter2 = (Scatter(init_opts=opts.InitOpts(bg_color='#404a59',width='1000px', height='800px'))
.add_xaxis(un_data_x)
.add_yaxis("美国", un_data_y,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=itemStyle_2
)
)
scatter3 = (Scatter(init_opts=opts.InitOpts(bg_color='#404a59',width='1000px', height='800px'))
.add_xaxis(uk_data_x)
.add_yaxis("英国", uk_data_y,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=itemStyle_1
)
)
scatter1.overlap(scatter2)
scatter1.overlap(scatter3)
scatter1.render_notebook()


cn_data_x, cn_data_y = [], []
for idx, row in df[(df.country=='China') & (df['rank']<=1000)].iterrows():
cn_data_y.append([row['score_6'], row['total_score'], row['rank'], row['university']])
cn_data_x.append(row['score_5'])
un_data_x, un_data_y = [], []
for idx, row in df[(df.country=='United States') & (df['rank']<=1000)].iterrows():
un_data_y.append([row['score_6'], row['total_score'], row['rank'], row['university']])
un_data_x.append(row['score_5'])
uk_data_x, uk_data_y = [], []
for idx, row in df[(df.country=='United Kingdom') & (df['rank']<=1000)].iterrows():
uk_data_y.append([row['score_6'], row['total_score'], row['rank'], row['university']])
uk_data_x.append(row['score_5'])
tool_js = """
function (obj) {
var value = obj.value;
var schema = [{name: 'rank', index: 0, text: '总体排名'},
{name: 'score_1', index: 1, text: '国际学生'},
{name: 'score_4', index: 2, text: '国际教师'},
{name: 'score_3', index: 3, text: '总体分数'}];
return '<div style="border-bottom: 1px solid rgba(255,255,255,.3); font-size: 18px;padding-bottom: 7px;margin-bottom: 7px">'
+ value[4]
+ '</div>'
+ schema[0].text + ':' + value[3] + '<br>'
+ schema[1].text + ':' + value[1] + '<br>'
+ schema[2].text + ':' + value[0] + '<br>'
+ schema[3].text + ':' + value[2] + '<br>';
}
"""
itemStyle_1 = {
'opacity': 0.8,
'shadowBlur': 10,
'shadowOffsetX': 0,
'shadowOffsetY': 0,
'shadowColor': 'rgba(0, 0, 0, 0.5)',
'color': '#80F1BE'
}
itemStyle_2 = {
'opacity': 0.8,
'shadowBlur': 10,
'shadowOffsetX': 0,
'shadowOffsetY': 0,
'shadowColor': 'rgba(0, 0, 0, 0.5)',
'color': '#fec42c'
}
itemStyle_3 = {
'opacity': 0.8,
'shadowBlur': 10,
'shadowOffsetX': 0,
'shadowOffsetY': 0,
'shadowColor': 'rgba(0, 0, 0, 0.5)',
'color': '#dd4444'
}
visualMap = [
{
'left': 'right',
'top': '10%',
'dimension': 2,
'min': 20,
'max': 100,
'itemWidth': 30,
'itemHeight': 120,
'calculable': True,
'precision': 0.1,
'text': ['圆形大小:总体分数'],
'textGap': 30,
'textStyle': {
'color': '#fff'
},
'inRange': {
'symbolSize': [10, 50]
},
'outOfRange': {
'symbolSize': [10, 50],
'color': ['rgba(255,255,255,.2)']
},
'controller': {
'inRange': {
'color': ['#c23531']
},
'outOfRange': {
'color': ['#444']
}
}
},
{
'left': 'right',
'bottom': '15%',
'dimension': 3,
'min': 1,
'max': 500,
'itemHeight': 120,
'precision': 0.1,
'text': ['明暗:总体排名'],
'textGap': 30,
'textStyle': {
'color': '#fff'
},
'inRange': {
'colorLightness': [0.5, 1]
},
'outOfRange': {
'color': ['rgba(255,255,255,.2)']
},
'controller': {
'inRange': {
'color': ['#c23531']
},
'outOfRange': {
'color': ['#444']
}
}
}
]
scatter1 = (Scatter(init_opts=opts.InitOpts(bg_color='#404a59',width='1000px', height='800px'))
.add_xaxis(cn_data_x)
.add_yaxis("中国", cn_data_y,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=itemStyle_3
)
.set_global_opts(yaxis_opts=opts.AxisOpts(name='国际学生', type_="value", is_scale=True,
name_textstyle_opts={'color': '#fff', 'fontSize': 16},
axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(color='#eee'))),
xaxis_opts=opts.AxisOpts(name='国际教师', type_="value", is_scale=True,
name_textstyle_opts={'color': '#fff', 'fontSize': 16},
axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(color='#eee'))),
tooltip_opts=opts.TooltipOpts(is_show=True, background_color='#222', border_color='#777', border_width=1, formatter=JsCode(tool_js)),
legend_opts=opts.LegendOpts(is_show=True, pos_right=10,
textstyle_opts=opts.TextStyleOpts(color='#fff',font_size=16)),
visualmap_opts=visualMap
)
)
scatter2 = (Scatter(init_opts=opts.InitOpts(bg_color='#404a59',width='1000px', height='800px'))
.add_xaxis(un_data_x)
.add_yaxis("美国", un_data_y,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=itemStyle_2
)
)
scatter3 = (Scatter(init_opts=opts.InitOpts(bg_color='#404a59',width='1000px', height='800px'))
.add_xaxis(uk_data_x)
.add_yaxis("英国", uk_data_y,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=itemStyle_1
)
)
scatter1.overlap(scatter2)
scatter1.overlap(scatter3)
scatter1.render_notebook()

t_data = df[(df['loc'] == 'China (Mainland)') & (df['rank'] <= 100)]
data_cn = []
for idx, row in t_data.iterrows():
data_cn.append([row['score_1'], row['score_2'], row['score_3'],
row['score_4'], row['score_5'], row['score_6'], row['university']])
t_data = df[(df['loc'] == 'United States') & (df['rank'] <= 100)]
data_un = []
for idx, row in t_data.iterrows():
data_un.append([row['score_1'], row['score_2'], row['score_3'],
row['score_4'], row['score_5'], row['score_6'], row['university']])
t_data = df[(df['loc'] == 'United Kingdom') & (df['rank'] <= 100)]
data_uk = []
for idx, row in t_data.iterrows():
data_uk.append([row['score_1'], row['score_2'], row['score_3'],
row['score_4'], row['score_5'], row['score_6'], row['university']
])
split_line_style = {'color': [
'rgba(238, 197, 102, 0.1)', 'rgba(238, 197, 102, 0.2)',
'rgba(238, 197, 102, 0.4)', 'rgba(238, 197, 102, 0.6)',
'rgba(238, 197, 102, 0.8)', 'rgba(238, 197, 102, 1)'
][::-1]
}
tool_js = """
function (obj) {
var value = obj.value;
var schema = [{name: 'score_1', index: 1, text: '学术声誉'},
{name: 'score_4', index: 2, text: '雇主声誉'},
{name: 'score_3', index: 3, text: '师生比'},
{name: 'score_3', index: 3, text: '教员引用率'},
{name: 'score_4', index: 2, text: '国际教师'},
{name: 'score_3', index: 3, text: '国际学生'}];
return '<div style="border-bottom: 1px solid rgba(255,255,255,.3); font-size: 18px;padding-bottom: 7px;margin-bottom: 7px">'
+ value[6]
+ '</div>'
+ schema[0].text + ':' + value[0] + '<br>'
+ schema[1].text + ':' + value[1] + '<br>'
+ schema[2].text + ':' + value[2] + '<br>'
+ schema[3].text + ':' + value[3] + '<br>'
+ schema[4].text + ':' + value[4] + '<br>'
+ schema[5].text + ':' + value[5] + '<br>';
}
"""
radar = Radar(init_opts=opts.InitOpts(theme='dark', bg_color='#161627', height='800px', width='1000px'))
radar.add_schema(shape='circle',
textstyle_opts=opts.TextStyleOpts(color='rgb(238, 197, 102)'),
axisline_opt=opts.LineStyleOpts(is_show=True, color='rgba(238, 197, 102, 1)'),
splitline_opt=opts.SplitLineOpts(is_show=True, linestyle_opts=split_line_style),
schema=[opts.RadarIndicatorItem(name='学术声誉', max_=100),
opts.RadarIndicatorItem(name='雇主声誉', max_=100),
opts.RadarIndicatorItem(name='师生比', max_=100),
opts.RadarIndicatorItem(name="教员引用率", max_=100),
opts.RadarIndicatorItem(name="国际教师", max_=100),
opts.RadarIndicatorItem(name="国际学生", max_=100)])
radar.add('中国', data_cn, symbol='none', is_selected=True,
label_opts=opts.LabelOpts(is_show=False),
linestyle_opts=opts.LineStyleOpts(color='#dd4444', width=1, opacity=0.5),
areastyle_opts=opts.AreaStyleOpts(color='#dd4444', opacity=0.05))
radar.add('美国', data_un, symbol='none', is_selected=False,
label_opts=opts.LabelOpts(is_show=False),
linestyle_opts=opts.LineStyleOpts(color='#fec42c', width=1, opacity=0.5),
areastyle_opts=opts.AreaStyleOpts(color='#fec42c', opacity=0.05))
radar.add('英国', data_uk, symbol='none', is_selected=False,
label_opts=opts.LabelOpts(is_show=False),
linestyle_opts=opts.LineStyleOpts(color='#80F1BE', width=1, opacity=0.5),
areastyle_opts=opts.AreaStyleOpts(color='#80F1BE',opacity=0.05))
radar.set_global_opts(legend_opts=opts.LegendOpts(is_show=True, selected_mode='multiple', pos_bottom=5),
tooltip_opts=opts.TooltipOpts(is_show=True, background_color='#222',
border_color='#777', border_width=1, formatter=JsCode(tool_js)),
title_opts=opts.TitleOpts(title="中英美——TOP100大学对比", pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(font_size=20)))
radar.render_notebook()


尾语 💝
好了,今天的分享就差不多到这里了!
完整代码、更多资源、疑惑解答直接点击下方名片自取即可。
有更多建议或问题可以评论区或私信我哦!一起加油努力叭(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!