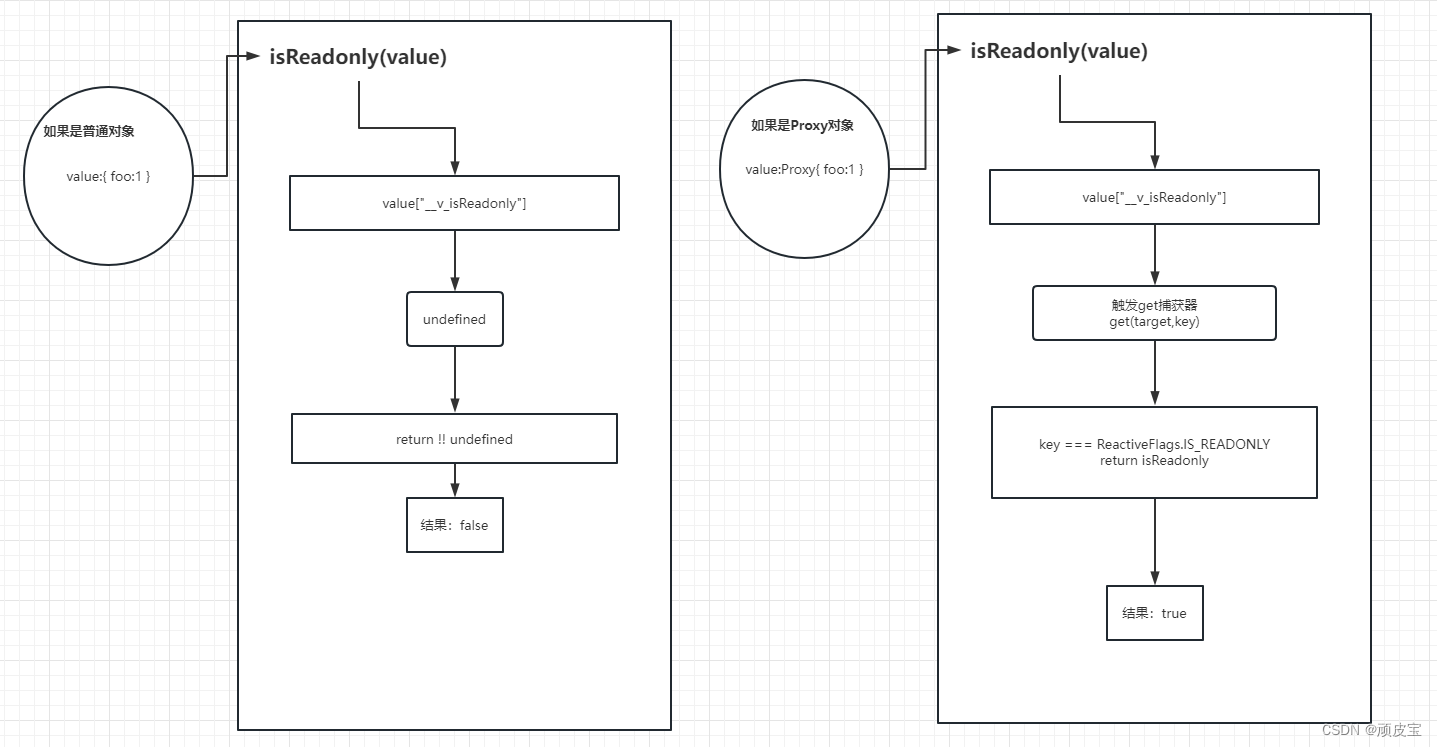
摘要
- 近年来,自我增强成为在低资源场景下提升命名实体识别性能的研究热点。
- Token substitution and mixup (token替换和表征混合)是两种有效提升NER性能的自增强方法。
- 明显,自增强方法得到的增强数据可能由潜在的噪声。
- 先前的研究针对特定的自增强方法设计特定的基于规则约束来降低噪声。
- 在这篇文章中,我们反思了这两个典型的针对NER的自增强方法。提出来提出了一个联合的 meta-reweighting 的策略去实现自然整合。
- 我们的方法很容易扩展到其他自增强方法,
- Experiments on different Chinese and English NER benchmarks。我们的方法可以有效的提升自增强方法的表现。
介绍
-
NER目的是从一些无结构文本中提取预训练命名实体。是NLP的一个基础任务。几十年来,都已经被广泛的研究。
-
近期,supervised sequence labeling neural models推动NER不断取得效果。
-
基于神经网络的方法推动NER任务不断取得更好的表现,但是其通常需要大规模标注数据,这在真实场景中是不现实的,
-
the low-resource setting with only a small amount of annotated corpus available普遍应用是更加切合实际的,
-
The major motivation is to generate a pseudo training example set deduced from the original gold-labeled training data automatically
- a pseudo training example set: 伪训练示例集。
- 由原始的基于标签的训练数据集自动推导。
-
a token-level task,
- token substitution.
- mixup.
- the ground-level inputs and the high-level hidden representations (低层次的输入和高层次的隐藏表示)
数据自增强是一个小样本任务可行的解法,对于 token-level 的 NER 任务,token 替换和表征混合是常用的方法。但自增强也有局限性,我们需要为每种特定的自增强方法单独进行一些设计来降低自增强所带来的噪声,缓解噪声对效果的影响。本文提出了 meta-reweighting 框架将各类方法联合起来。
尽管如此,我们尝试放宽前人方法中的约束,得到更多的伪训练示例。这样必然会产生更多低质量增强样本。这可能会降低模型的效果。此,我们提出 meta reweighting 策略来控制增强样本的质量。同时,使用 example reweighting 机制可以很自然的将两种方法结合在一起。
数据集
最后,on several Chinese and English NER benchmark datasets
our Approach
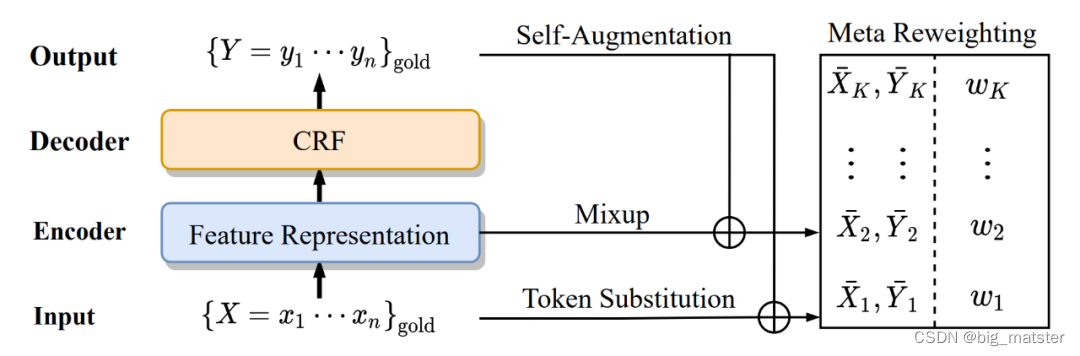
Baseline model
基准模型架构 BERT-BiLSTM-CRF
input representation
- 输入序列 X = ( x 1 , x 2 , ⋯ , x N ) X = (x_1,x_2,\cdots,x_N) X=(x1,x2,⋯,xN) of length n
- 使用预训练BERT,将其转换为 sequential hidden vectors
e 1 , e 2 , ⋯ , e N = B E R T ( x ) e_1,e_2,\cdots,e_N = BERT(x) e1,e2,⋯,eN=BERT(x)
BiLSTM encoding
h 1 , h 2 , ⋯ , h n = B i L S T M ( e 1 , e 2 , ⋯ , e N ) h_1,h_2,\cdots,h_n = BiLSTM(e_1,e_2,\cdots,e_N) h1,h2,⋯,hn=BiLSTM(e1,e2,⋯,eN)
CRF decoding
最后解码过程使用 CRF 进行解码,先将得到的表征过一层线性层作为初始的标签分数,定义一个标签转移矩阵
T
T
T 来建模标签之间的依赖关系**。对于一个标签序列 ,其分数 计算如下:
o
i
=
w
h
i
+
b
,
o_i = wh_i + b,
oi=whi+b,
s
(
Y
∣
X
)
=
∑
i
=
1
n
(
T
y
i
−
1
,
y
i
+
o
i
[
y
i
]
)
s(Y|X) = \sum^n_{i = 1}(T_{y_{i -1},y_i} + o_i[y_i])
s(Y∣X)=i=1∑n(Tyi−1,yi+oi[yi])
标签转移矩阵
T
T
T
其中
W
,
b
,
T
W,b,T
W,b,T都是模型参数,最后使用维比特算法**得到最佳的标签序列,训练的损失函数采用句子级别的交叉熵损失,
对于给定的监督样本对
(
X
,
Y
)
(X,Y)
(X,Y),其条件概率
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)计算公式如下:
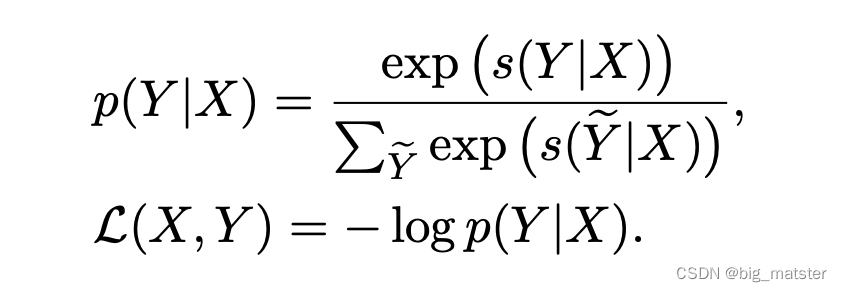
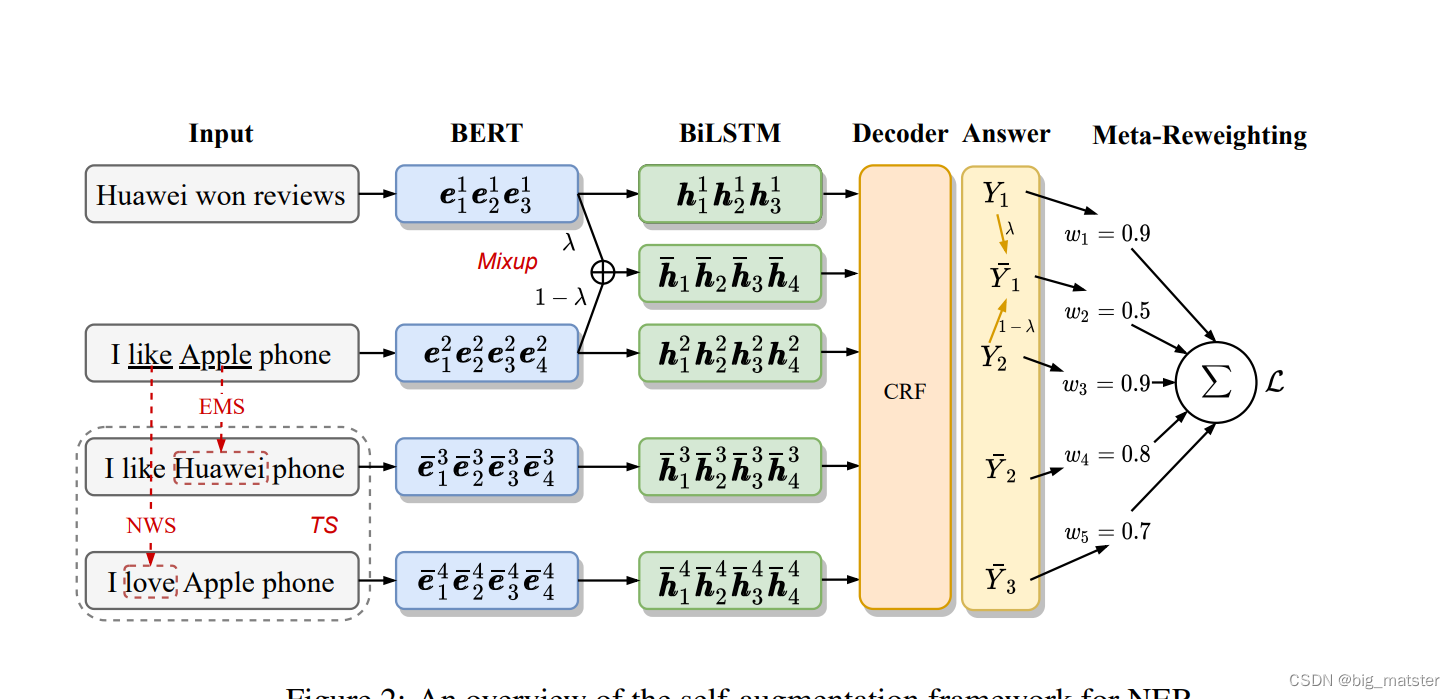
自增强方法
- 自增强方法减少了大规模的人工标注需求,这能够被应用在
- the input level and the representation level.
- Token substitution and mixup 是命名实体识别的两个有效的方法,因此,我们去尝试扩展这两个有效的方法。
Token Substitution
t
o
k
e
n
token
token替换是在原始的训练文本中对部分
t
o
k
e
n
token
token进行替换得到伪样本,本文通过构建同义词词典来进行token替换。
a
s
y
n
o
n
y
m
d
i
c
t
i
o
n
a
r
y
a synonym dictionary
asynonymdictionary:同一词词典。
词典中即包含实体词也包含大量的普通词,遵循前人的设置,我们将所有属于同一实体类型的词当做同义词。 并且添加到实体词典中,作者将其称为entity mention substitution (EMS)。同时我们也将将 token 替换扩展到了“O”类型中,作者将其称为 normal word substitution (NWS)。作者使用
w
o
r
d
2
v
e
c
word2vec
word2vec方法,在 wikidata 上通过余弦相似度找到 k 个最近邻的词作为“O”类型词的同义词。
这里作者设置了参数,来平衡 EMS 和 NWS 的比率,在 entity diversity 和 context diversity 之间达到更好的 trade-off。
Mixup for CRF
不同与 t o k e n token token替换在原始文本上做增强,mixup 是在表征上进行处理。
-
heuristic rules 启发式算法。
本文将mixup方法扩展到CRF层。 -
the gold-labeled training set 给出示例 ( X 1 , Y 1 ) (X_1,Y_1) (X1,Y1)和 ( X 2 , X 2 ) (X_2,X_2) (X2,X2)
-
the linear interpolation: 线性插值法。
-
形式上,给定一个样本对,首先用 B E R T BERT BERT得到其向量和,然后通过参数将两个样本混合。
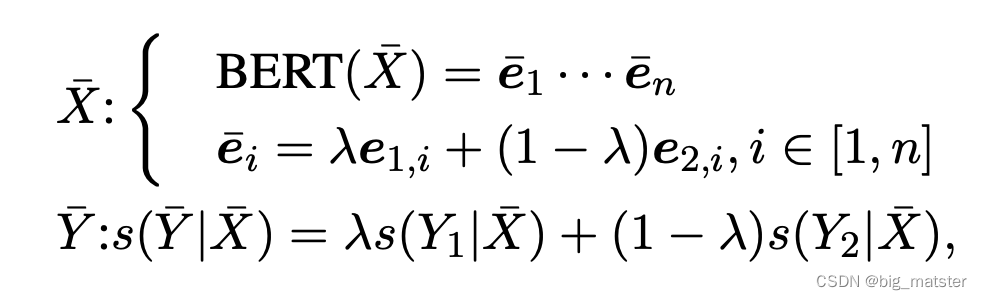
损失函数可以被计算为:
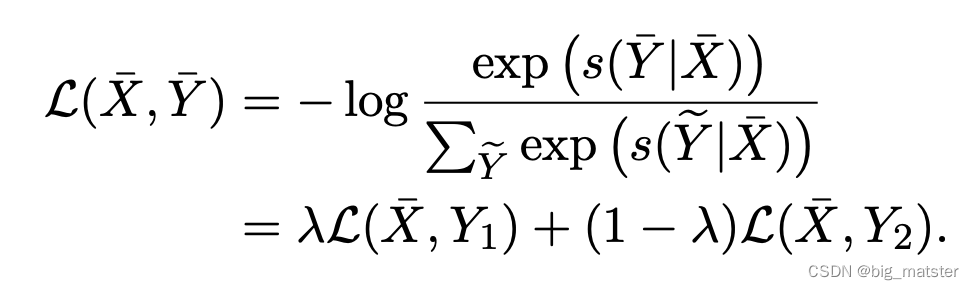
重点关注mixup和词替换方法。
Meta Reweighting
- 自增强技术可以有效的产生大量的伪样本,
- 如何控制增强示例的质量是一个不容忽视的挑战。
- sentence-level classification task: 句子级别的分类任务。
- the semantics of the context. 上下文信息.
作者使用 meta reweighting 策略为 mini batch 中的训练数据分配样本级的权重。 - Intuitively 直觉上看。
- the meta-data set, 标注样本
- the example-wise weights: 样本级别权重。
在少样本设置中,我们希望少量的标注样本能够引导增强样本进行模型参数更新,觉上看,如果增强样本的数据分布和其梯度下降的方向与标注样本相似,说明模型能够从增强样本中学到更多有用的信息。
算法流程如下:

实验
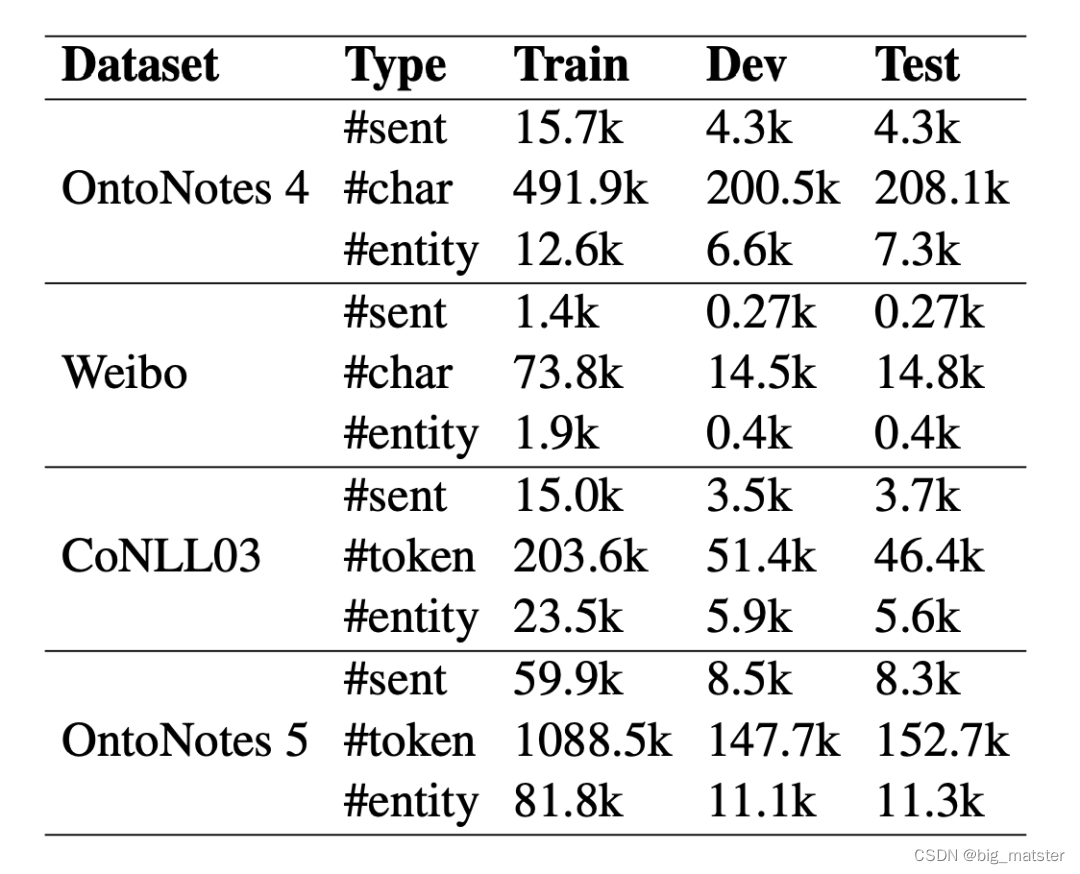
数据集采用 OntoNotes 4、OntoNotes 5、微博和 CoNLL03,所有数据集均采用 BIOES 标注方式。
执行细节
- Gradient clipping 梯度裁剪
- manual annotations 手工标注
- sophisticated model architecture 复杂的模型架构。
运行模型
the BiLSTM-CRF mode
pre-trained BERT
自增强主流的方法
- token substitution
- paraphrasing
- mixup
文章灵感激发
- Many previous studies have explored the example weighting mechanism in domain adaption looked into the example weighting methods for cross-domain tasks。
- Ren et al. (2018) adapted the MAML algorithm (Finn et al., 2017) and proposed a meta-learning algorithm to automatically weight training examples of the noisy label using a small unbiased validation set.
-
结论
- 本文提出了 meta reweighting 策略来增强伪样本的效果。是一篇很有启发性的文章,从梯度的角度出发,结合类似于 MAML 中 gradient by gradient 的思想,用标注样本来指导伪样本训练,为伪样本的损失加权,对伪样本的梯度下降的方向进行修正使其与标注样本更加相似。
经验
- 同一个技术,使用的跟前人不一样,就叫做创新。
- 罗列常见的数据增强方法,换种方法后续都能发文章。
- 借鉴其他领域的主流方法,换个话题用到之知识图谱中,比如,领域自适应中的the example weighting mechanism,应用到命名实体识别中。
- 现在做的小步骤,都是复现代码,然后再代码上做微小的改动。
- 继续的多调试代码,反复读文章,将文章精度、读烂读透都行啦的理由与打算。