1. 强化学习概念和分类
强化学习,Reinforcement Learning
通过价值选行为:
- Q Learning
- Sarsa
- Deep Q Network
直接选行为:
- Policy Gradients
想象环境并从众学习:
- Model Based RL
1.1 通过环境分类
1.1.1 不理解环境 Model-Free RL
Model-free RL都是从环境中得到反馈,从而学习。
- Q Learning
- Sarsa
- Policy Gradients
Model-free RL只能等待现实环境反馈,从而一步一步进行学习。
1.1.2 理解环境 Model-Based RL
Model-based RL是对现实世界做虚拟环境建模,通过想象预判断接下来发生的所有情况,并从众选择效果最好的那种情况,并根据这种最好的情况来采取下一步策略。
1.2 根据感官分类
1.2.1 基于概率 Policy-Based RL
通过感官分析所处的环境,直接说出下一步行动的概率,并根据概率采取行动。
- Polic Gradients
能够处理连续动作
1.2.2 基于价值 Value-Based RL
根据感官输出所有动作的价值,并根据最高价值来选择动作。
- Q Learning
- Sarsa
不能处理连续动作
1.2.3 Actor-Critic RL
结合Policy-based RL和Value-Based RL方法优点,创造出一种更优秀的RL method:Actor-Critic。
Actor会基于概率做出动作,Critic会根据动作给出价值。
1.3 游戏更新
想要强化学习,就使它玩游戏
1.3.1 回合更新 Monte-Carlo update
回合更新是指游戏开始后,我们需要等待游戏结束,通过总结游戏中所有的转折点,然后更新我们的行为准则。
- 基础班 Policy Gradients
- Monte-Carlo Learning
1.3.2 单步更新 Temporal-Difference update
单步更新是指在游戏中进行的每一步都在进行更新,不用等待游戏结束。
- Q Learning
- Sarsa
- 升级版 Policy Gradients
单步更新更有效率,现在深度学习中大多数方法都是单步更新。
1.4 是否在线
1.4.1 在线学习 On-Policy
在线学习是指本人在场,在边玩边学习
- Sarsa
- Sarsa(λ)
1.4.2 离线学习 Off-Policy
离线学习是指你可以自己玩,也可以看着别人玩。通过看别人玩,来学习别人的行为准则。
- Q Learning
- Deep Q Network
离线学习可以先储存下来玩耍的记忆,晚上再学习。
2. RL Algorithm
2.1 Q-Learning
rules of conduct,行为准则,
e.g. "No watching TV before you finish your homework"
so under the state of doing homework,
- a good rule of conduct is continuing doing homework, then we can be rewarded when finish.
- a bad rule of conduct is watching TV without finishing the homework, then penalty.

Q-Learning is also a decision-making process.
- state 1: doing the homework
- action 1: watching TV; action 2: doing the homework
- underlying results: Q table

s1有两个行为a1和a2,在s1状态下,a2带来的潜在奖励要比a1高,这里的潜在奖励用含有s和a的Q表来表示,Q(s1,a1) < Q(s1,a2) --> a2 作为下一个行为 --> 现在状态更新为s2。
s2依然有两个行为a1和a2,重复上述过程。
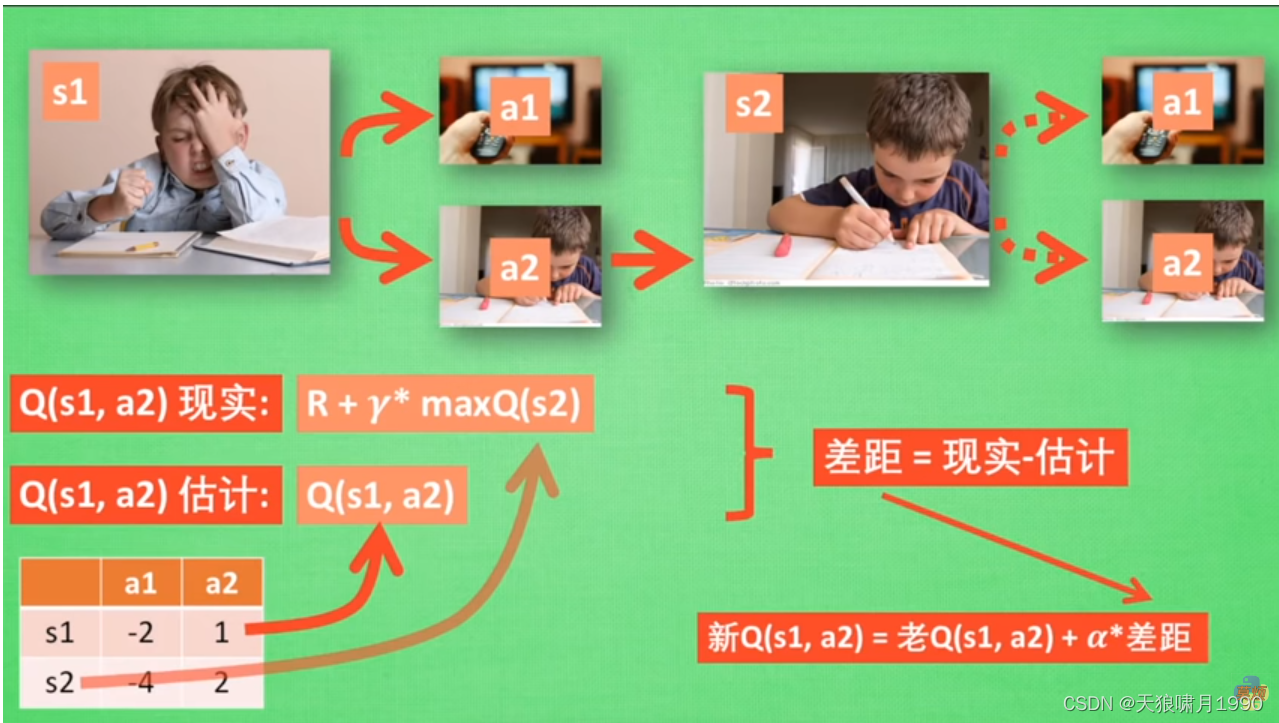
根据Q表的估计,现在在s1中a2的值比较大,通过之前的决策方法,我们会在s1选择a2的行动,并且到达s2,这时我们更新用于决策的Q表。接着,我们并没有在实例中采取任何行动, 而是在想象在s2上采取的哪种行动,分别看看两种行动哪一种的Q值比较大,比如说Q(s2,a2) > Q(s2,a1)
--》所以,我们会把大的Q(s2,a2) * 衰减值γ(e.g. 0.9) + 到达s2时所获得的奖励R (这时还没有获取到棒棒糖,所以实际奖励为0),因为这一次会获取实际奖励R,我们将这一次作为现实中Q(s1,a2)的值。但是,我们之前是根据Q表估计Q(s1,a2)的值,根据现实与估计的差距,将这个差距 * 学习率α,累加上老Q(s1,a2) = 新Q(s1,a2)。
Note that,我们虽然用了maxQ(s2)来估计下一个s2的状态,但还没有在状态s2做出任何的行为,s2的决策部分要等到更新完了以后再重新去做。
参考
https://www.youtube.com/watch?v=NVWBs7b3oGk&list=PLXO45tsB95cJYKCSATwh1M4n8cUnUv6lT&index=1
https://www.cnblogs.com/pinard/p/9385570.html