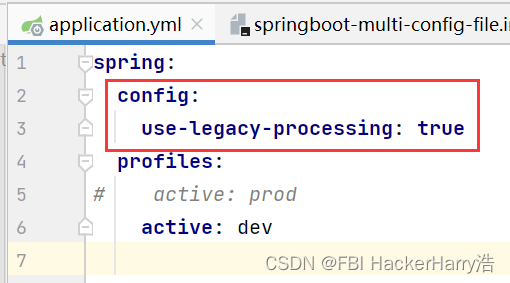
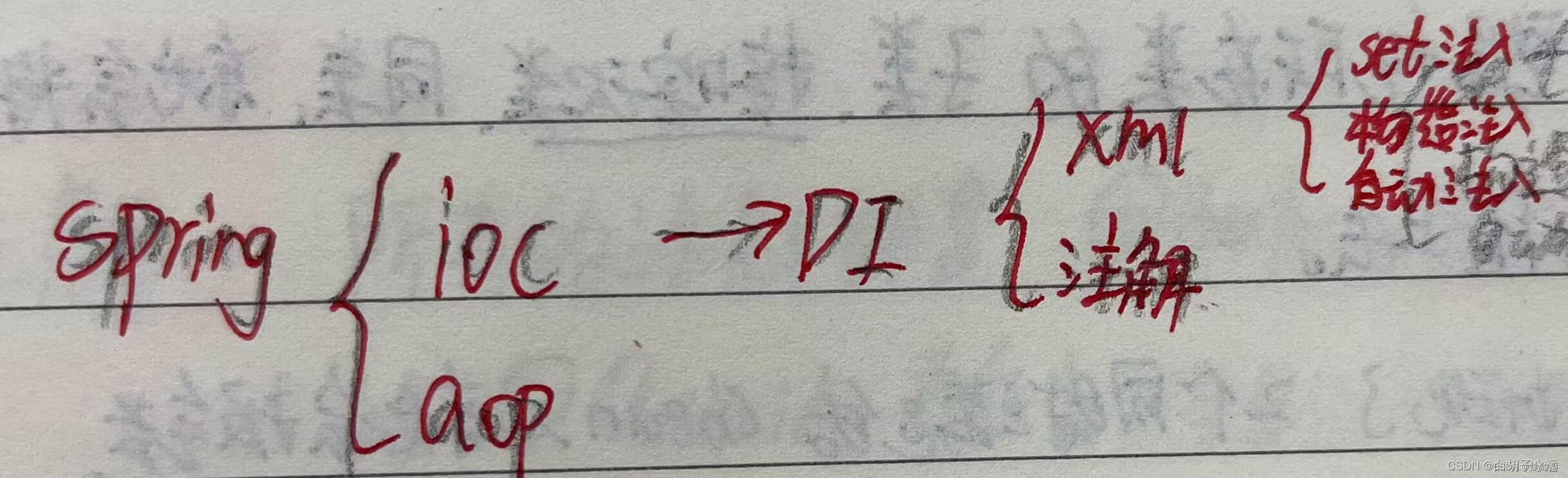目录
0摘要
1介绍
2预习
3治疗和指标
4深层因果模型的发展
4.1发展时间表
4.2模型分类
5典型的深层因果模型
6实验指南
6.1数据集
6.2code
6.3实验
7结论
参考
编码
1.自编码器(AE):
2.去噪自编码器(DAE)
3.变分自编码器VAE
4.去耦变分自编码
文章:A SURVEY OF DEEP CAUSAL MODELS
文章链接:https://export.arxiv.org/pdf/2209.08860v3.pdf
代码汇总:GitHub - alwaysmodest/A-Survey-of-Deep-Causal-Models-and-Their-Industrial-Applications
0摘要
因果关系概念在人类认知中起着重要的作用。在过去的几十年里,因果推理在许多领域得到了很好的发展,如计算机科学、医学、经济学和其他工业应用。随着深度学习的发展,它越来越多地应用于对反事实数据的因果推断。通常,深度因果模型将协变量的特征映射到表示空间,然后设计各种目标函数来无偏估计反事实数据。与现有机器学习中因果模型的研究不同,本文主要对深层因果模型进行了概述,其核心贡献如下:1)总结了多剂量治疗和连续剂量治疗下普遍采用的相关指标;2)我们从发展时间轴和方法分类角度对深层因果模型进行了全面概述;3)我们还努力对相关数据集、源代码和实验进行详细的分类和分析。
1介绍
一般来说,因果关系是指结果和原因之间的联系。这种现象的原因和后果很难定义,我们往往只能凭直觉意识到它们。因果推理是根据影响发生的环境对因果关系得出结论的过程,在现实场景中有多种应用[2]。观测数据为例,估算因果的影响在广告(3,4,5,6,7,8,9),发展与因果的推荐系统是高度相关的处理效应估计(10、11、12、13、14、15、16),学习医学患者最佳治疗规则17,18,19,尽管估计在强化学习(20日,9日,21日,22日,23日,24日,25日,26日,27日),在自然语言处理中因果推理任务(28、29、30、31、32、33),新兴的计算机视觉和语言交互任务[34,35,36,37,38],教育[39],政策决策[40,41,42,43,44],以及改进的机器学习[45]等。
深度学习应用于大数据时,极大地促进了人工智能的发展[46,47,48,49]。与传统机器学习相比,深度学习模型计算效率更高,精度更高,在各个领域都有很好的表现。然而,许多深度学习模型是可解释性较差的黑盒,因为它们对输入和输出的相关性更感兴趣,而不是因果关系[50,51,52]。近年来,深度学习模型被广泛用于挖掘数据的因果关系,而不是相关性[40,42]。因此,深层因果模型已成为基于无偏估计估计治疗效果的核心方法[19,43,44,53]。目前,因果推理领域的许多工作都是利用深层因果模型来进行选择。
随着大数据的出现,所有的趋势变量都趋于相关[58],因此发现潜在的因果关系成为一个具有挑战性的问题[59,60,61]。从统计学理论来看,通过随机对照试验(RCT)来推断因果关系是最有效的方法[62]。换句话说,样本被随机分配到治疗组或对照组。尽管如此,现实世界的RCT数据很少,并且存在一些严重的缺陷。涉及随机对照试验的研究需要大量特征变化很小的样本,这是难以解释的,并将不可避免地进一步涉及一些伦理问题。事实上,在药物开发过程中,选择受试者进行药物或疫苗的试验也是不明智的[63,64]。因此,因果效应通常直接使用观测数据来衡量。获得反事实结果的一个核心问题是如何处理观测数据[65]。在分析观察数据时,处理并不是随机分配的,处理后的样本与普通样本的表现有显著差异[40,42]。不幸的是,由于反事实的结果[66]无法被观察到,我们在理论上无法观察到其他的结果。长期以来,主流研究主要探索使用潜在结果框架作为解决观察数据因果推断问题的手段[67]。潜在结果框架也被称为鲁宾因果模型[68]。本质上,因果推理与深度学习密切相关,因为它是使用Rubin因果模型来概念化的。为了提高估计的准确性和无偏性,有一些工作试图将深度网络和因果模型结合起来。只是为了说明其中的几个,例如,考虑分布平衡表示的方法[40,42,43],利用协变量混淆学习的影响[53,69,70,71],基于生成对抗网络的方法[44,72,73,74],等等[57,33,75]。由于深度学习和因果推理的同时发展,深度因果模型问题变得更加开放和多样化[76,77,78]。
近年来,关于因果推断的各种观点被讨论[79,1,80,81,82,83,84,85,2,86]。在表1中,我们列出了一些现有的有代表性的调查及其亮点。综述[79]深入分析了因果推理的起源和发展,以及因果学习对因果推理发展的影响。紧接着,由于机器学习领域的迅速发展,在survey[80]中详细讨论了图形因果推断与机器学习的相关性。此外,在调查[1]中可以找到传统和前沿因果推理方法的概述,以及机器学习和因果学习的比较。机器学习的可解释性研究是近年来研究的热点之一,受到了广泛的关注。文献[81]将因果推理与机器学习相结合,对相关的可解释人工智能算法进行了分析总结。此外,随着因果表示学习的蓬勃发展,review[82]采用这种新的视角从低水平的观察中发现高水平的因果变量,加强了机器学习和因果推理之间的联系。在survey[86]中,对反事实干预的结构性因果模型进行了全面的解释和总结,并对因果机器学习下的五类问题进行了系统的分析和比较。此外,在综述[83]中,作者讨论了机器学习的最新进展应用于因果推理的方式,并深入解释了因果机器学习如何促进医疗保健和精准医疗的发展。如review[84]所述,因果发现方法可以基于深度学习进行改进和梳理,也可以从可变范式的角度进行考虑和探索。推荐系统中的因果推理是调查的重点[85],它解释了如何利用因果推理提取因果关系来增强推荐系统。长期以来,统计学中的潜在结果框架一直是因果推断和深度学习之间的桥梁。作为起点,回顾[2]分析和比较了满足这些假设的不同类别的传统统计算法和机器学习。鉴于深度学习的快速发展,现有文献在研究泛化问题时未能充分考虑深度因果模型。因此,我们从深度神经网络的角度,从时间进展和分类两方面总结了深层因果模型。特别是,本调查对近年来的深层因果模型进行了全面的回顾和分析,其核心贡献有三:1)总结了多剂量治疗和连续剂量治疗下普遍采用的相关指标;2)我们从时间发展和方法分类的角度对深层因果模型进行了全面概述;3)我们还尝试对相关数据集、源代码和实验进行详细的分类和分析。
本文的其余部分概述如下。第二节介绍了因果推理的相关定义和假设。然后,在第3节中,我们介绍了经典的例子和指标,包括二元处理,多干预,连续剂量治疗。深层因果模型将在第4节中全面阐述。接下来,我们在第5节中将深度因果建模方法分为五组,包括用于分布平衡的表示学习,协变量混淆学习,基于生成对抗网络的方法,时间序列因果估计问题,以及基于多治疗和连续剂量治疗模型的方法。在此之后,相关的实验指南在第6节中列出。最后,我们在第7节对本文进行总结。
2预习
在本节中,我们将介绍因果推断的背景知识,包括任务描述、数学概念和相关假设。基本上,因果推断的目的是估计如果实施不同的治疗方法将会发生的结果变化。假设有几种治疗方案A、B、C等,治愈率各不相同,治愈率的变化是治疗方案的结果。现实地说,我们不能同时对同一组患者采用不同的治疗方案。与随机对照研究相反,观察性研究需要解决的主要问题是缺乏反事实数据。换句话说,我们面临的挑战是如何根据患者过去的实验诊断和病史找到最有效的治疗方案。由于医疗保健[87,88,89]、社会学[90,91,92,93]、数字营销[94,4,5]和机器学习[95,96,9,97,98]等领域数据的广泛积累,观察性研究变得越来越重要。为了迎合这一趋势,深度因果模型神经网络也被广泛用于基于观察数据进行反事实估计,这可以进一步帮助在各个领域做出最佳治疗决策。
3治疗和指标
深层因果模型利用不同的度量来解决不同的实际问题。例如,在医学[40,42]、卫生保健[101,75]、市场[102]、求职[43,44]、社会经济[73,56]和广告[41,77]中,可能出现二元治疗问题、多重治疗问题或连续剂量治疗问题。本节对不同经典应用场景采用的不同性能指标进行分析和描述。除了调查[2]中的基本指标外,我们还将评估从二进制扩展到多个和连续剂量案例。

4深层因果模型的发展
在对因果推断的基本定义和模型度量有了深入的理解之后,本节将进入本文的核心部分。我们对过去几年的深层因果模型进行了概述,并对其进行了详细分类 。
4.1发展时间表
在过去的几年里,对深层因果模型的研究有了很大的进展,它们在估计因果效应方面变得更加准确和有效。在图1中,我们展示了2016年6月至2022年2月期间约40个经典深度因果模型的发展时间表。自2016年以来,深层因果模型已经出现。Johansson等首次发表了反事实推理的学习表示[40],提出了深度学习与因果效应估计相结合的算法框架BNN和BLR[40],将因果推理问题转化为领域适应问题。此后,人们提出了包括DCN-PD[110]、TARNet和CFRNet[42]在内的多个模型。值得注意的是,Louizos等人在2017年12月提出的基于经典结构变分自编码器(VAE)[111]的CEVAE[53]模型主要关注混杂因素对因果效应估计的影响。


2018年和2019年,人们对因果表征学习的兴趣日益浓厚,代表作包括Deep-Treat[19]和RCFR[112]模型。在GANITE[44]模型推出后,使用生成对抗模型[113]架构进行反事实估计成为因果推断领域的主流。根据前人的工作,在CFR-ISW[114]、CEGAN[72]、SITE[43]中提出了一些新的优化思路。
R-MSN[75]模型应用递归神经网络[115],旨在解决多治疗时间序列的连续剂量问题,开辟了深层因果模型的新理论。此外,2019年提出的PM[41]和TECE-VAE[105]试图解决估计与多个离散治疗相关的因果效应的问题。作为后续,CTAM[33]开始专注于估计文本数据的因果影响;Dragonnet[70]首次将正则化和倾向评分网络加入到因果模型中;ACE[54]尝试从表示空间中提取细粒度的相似度信息。RSB[116]模型采用深度表示学习网络和PCC[117]正则化进行协变量分解,使用工具变量控制选择偏倚,使用混杂因素和调节因素预测结果。
4.2模型分类
随着医疗,教育,经济,商业等数据的不断积累,深度学习在因果推断中也开始有了应用的空间 。那么深度学习的因果推断主要分为五类:
(1) 基于分布平衡的表示学习
(2) 协变量confounding
(3) 基于生成网络的因果推断
(4) 时间序列的因果预估问题
(5) 多treatment 和连续因果问题
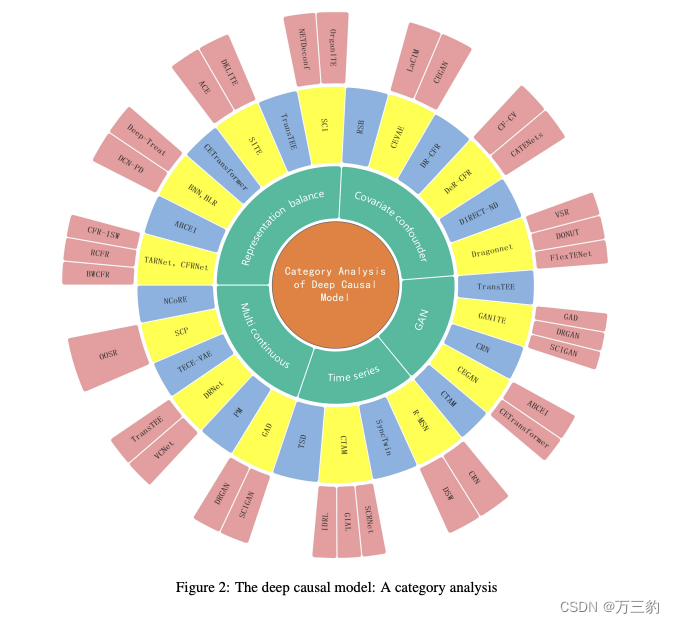

- 学习平衡表征:这种类型的方法长期以来一直是一个流行的研究。核心思想是使用编码器将协变量X映射到表示空间Φ,结合processingT,采用网络h预测输出结果Y,最小化事实结果与反事实结果之间的分布距离discH。经典的架构有BNN[40]、CFRNet[42]、SITE[43]、ACE[54]、DKLITE[55]、SCI[76]等。
- 协变量混淆学习(Covariate conflearning):这类方法在理论上旨在分解协变关系。它的主要应用方案是协变量的无偏估计和利用解耦、重加权、编解码器重构等方法去除混杂因素。典型的结构有CEVAE[53]、Dragonnet[70]、DeR-CFR[69]、LaCIM[125]、DONUT[130]、FlexTENet[131]等。
- 基于gan的反事实模拟:随着近年来GANs在数据合成方面的巨大成功,它也被广泛用于解决因果效应估计问题。利用GAN网络进行反事实模拟通常涉及两种方案,即生成反事实输出结果或平衡表示空间分布。经典框架包括GANITE[44]、CEGAN[72]、ABCEI[123]、CETtrnaformer[129]等。
- 时间序列因果估计:时间因果估计已得到广泛关注。使用rnn跟踪上下文协变量信息并处理时变混杂偏差是许多模型采用的长期解决方案。典型的架构有R-MSE[75]、CTAM[33]、CRN[121]、TSD[122]等。
- 多重治疗和连续剂量治疗:多重治疗和连续剂量治疗问题是深度因果学习领域最近的研究热点之一。一般来说,这些问题可以进一步简化和结构化,使用匹配、变分自编码器、分层鉴别器和多头注意机制等方案。经典模型有PM[41]、TECE-VAE[105]、DRNet[56]、SCIGAN[73]、VCNet[57]、TransTEE[77]等。
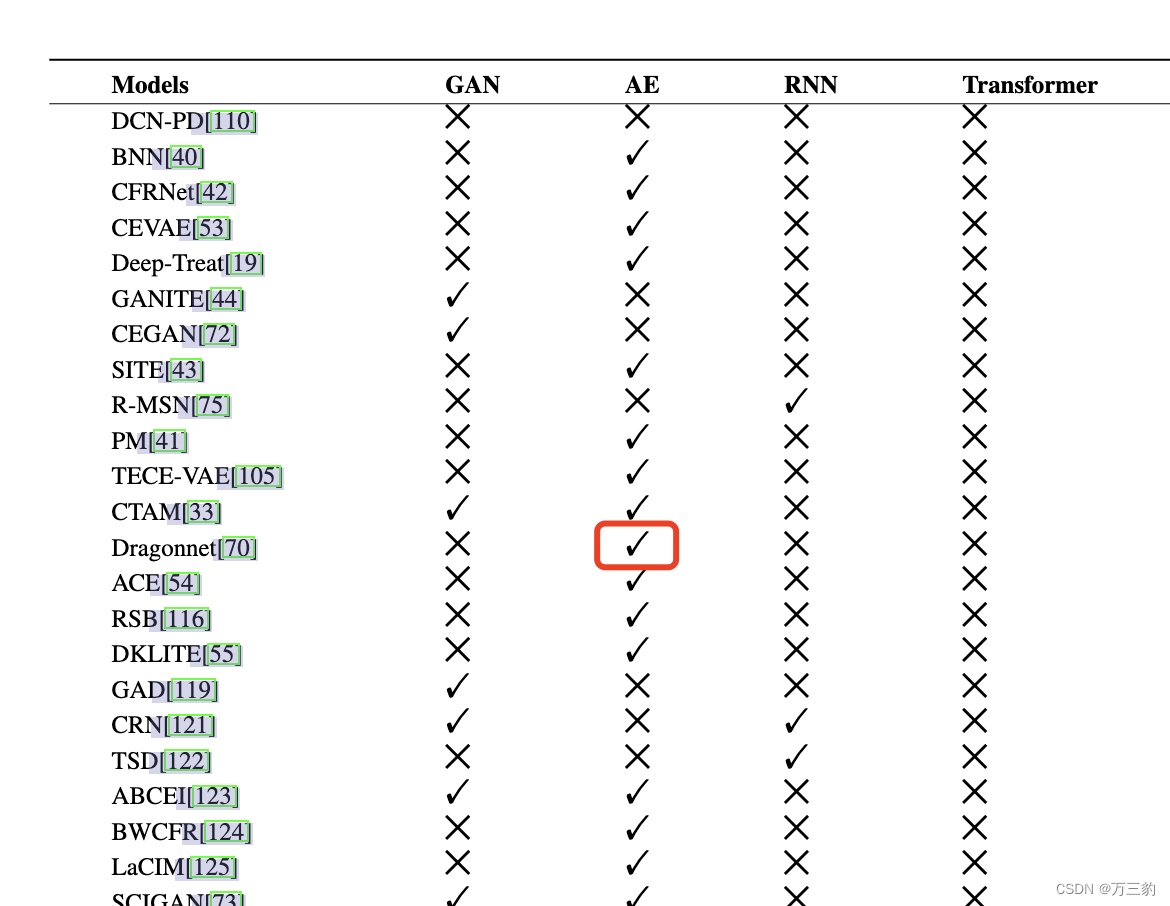
5典型的深层因果模型
随着医疗、教育、经济等领域越来越多的数据积累,深度学习越来越多地被用于从反事实数据中推断因果关系。与现有的深层因果模型(通常将协变量映射到表示空间)相反,目标函数可以实现对反事实数据的无偏估计。不同于从深层因果模型的不同研究角度分类的各种经典模型的简要概述,表2总结了那些典型的深层因果模型应用的经典网络架构。此外,在接下来对典型的基于深度学习的因果模型的详细描述中,也讨论了这些模型面临的问题和挑战。
6实验指南
在深入描述深度因果建模方法之后,本节将提供详细的实验指南,包括对数据集、源代码和实验的综合结论和分析。
6.1数据集
6.2code
 通过结合相关方法、数据集和源代码,我们可以更容易地识别每个模型的创新点。同时,也有利于在绩效考核中进行更加公平的比较。此外,毫无疑问,这些源代码也将极大地促进因果推断研究界的发展。以Dragonnet[70]模型为例,结合DeR-CFR[69]模型,将协变量分解应用于Dragonnet[70]模型,进一步进行模型优化。将TransTEE[77]注意机制应用于VCNet[57]或DRNet[56]的表示平衡部分,可以更准确地拟合连续剂量估计曲线。这也意味着因果分析的最新进展也受益于或受到了以前一些有代表性的作品的启发。
通过结合相关方法、数据集和源代码,我们可以更容易地识别每个模型的创新点。同时,也有利于在绩效考核中进行更加公平的比较。此外,毫无疑问,这些源代码也将极大地促进因果推断研究界的发展。以Dragonnet[70]模型为例,结合DeR-CFR[69]模型,将协变量分解应用于Dragonnet[70]模型,进一步进行模型优化。将TransTEE[77]注意机制应用于VCNet[57]或DRNet[56]的表示平衡部分,可以更准确地拟合连续剂量估计曲线。这也意味着因果分析的最新进展也受益于或受到了以前一些有代表性的作品的启发。
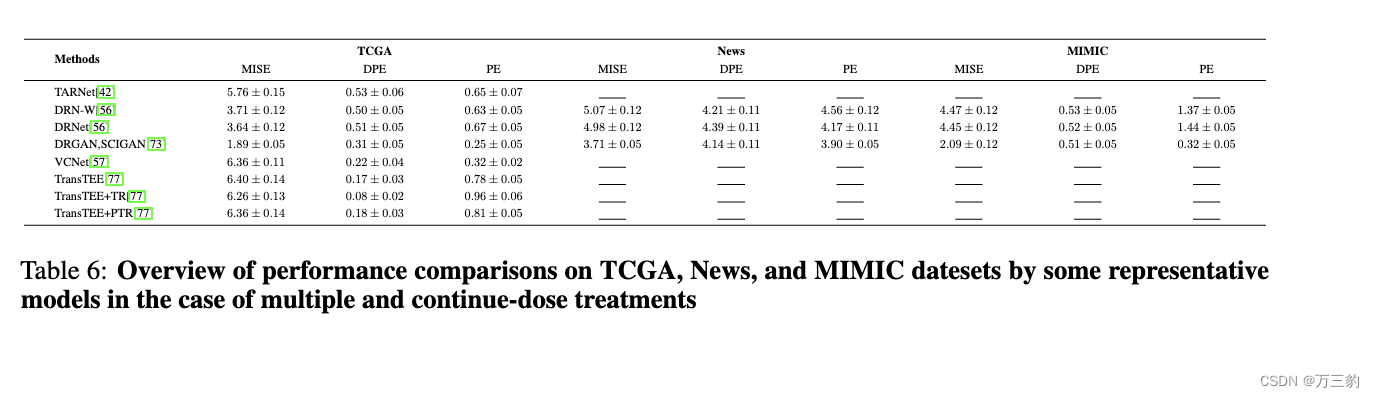
6.3实验
7结论
由于因果推理和深度学习的发展,深度因果模型已经成为一个越来越受欢迎的研究课题。将深度网络模型应用于因果推断,可以提高因果效应估计的准确性和无偏性。此外,利用因果推理中的深层理论可以对深层网络进行优化和改进。这项调查展示了深层因果模型的发展和各种方法的演变。首先,学习了因果推理领域的基本知识。然后,我们提出了经典的处理和指标。此外,我们还从时间发展的角度对深层因果模型进行了全面分析。接下来,我们将深层因果建模方法分为五类,并进行概述和分析。此外,我们对因果推理在工业中的应用作了全面的总结。最后,我们总结了相关的基准测试数据集、开放源代码和性能结果作为实验指南。
自2016年以来,因果推断首次在二元处理案例中与深度学习模型相结合,用于估计反事实结果。到目前为止,深度因果模型已用于时间序列、多变量治疗和连续剂量治疗情况。这离不开深度学习领域研究人员提出的AE、GAN、RNN、Transformer等深度网络模型,离不开统计学领域研究人员对IHDP、Twins、Jobs、News、TCGA等数据集的生成和模拟,离不开行业研究人员在潜在结果框架理论指导下对ATE、PEHE、MISE、DPE的探索。我们相信,在因果学习社区中每个人的共同努力下,深层因果模型将为社会带来好处,和人性。该调查的总结材料可以在GitHub - alwaysmodest/A-Survey-of-Deep-Causal-Models-and-Their-Industrial-Applications上找到。
学习归纳:
深度因果模型将协变量的特征映射到表示空间,然后设计各种目标函数来无偏估计反事实数据
参考
- 因果推断3- 深度学习与因果 - 知乎
- 大白话谈因果系列文章(四)估计uplift--深度学习方法 - 知乎
- 稳态学习 —— 结合因果推断的深度模型 - 知乎
- 深度学习和因果如何结合?北交最新《深度因果模型》综述论文,31页pdf涵盖216篇文献详述41个深度因果模型..._人工智能学家的博客-CSDN博客
- 多角度回顾因果推断的模型方法
- 动态因果模型 DCM - 知乎
- 因果推断入门(6)怎么处理可观测混杂因素 - 知乎
- [因果推断] 7 不可观测混杂 - 知乎
- 因果推断入门(3)因果的定义 - 知乎
- AE和VAE,CVAE_lingboboo的博客-CSDN博客
- 主流的25个深度学习模型 - 知乎
编码
自编码器(autoencoder, AE)是一类在半监督学习和非监督学习中使用的人工神经网络(Artificial Neural Networks,ANNs),属于深度学习领域的范畴,其功能是通过将输入信息作为学习目标,对输入信息进行表征学习。通常用于压缩降维,风格迁移和离群值检测等等。对于图像而言,图像的数据分布信息可以高效表示为编码,但是其维度和数据信息一般远小于输入数据,可作为强大的特征提取器,适用于深度神经网络的预训练,此外它还可以随机生成与训练数据类似的数据,以此来高效率的表达原数据的重要信息,因此通常被看作是生成模型。
自编码器在深度学习的发展过程中出现了很多变体,比如演化出去噪自编码器再到变分自编码器(Denoising Autoencoder,DAE),再到变分自编码器(Variational auto-encoder,VAE),最后到去耦变分自编码,随着时代的发展,往后会出现更多优秀的模型,但它的原理从数学角度都是从输入空间和特征空间开始,自编码器求解两者的映射的相似性误差,通过以下公式使其最小化.
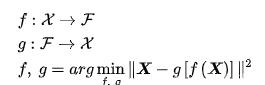
求解完成之后,自编码器输出计算后的特征h,即编码特征,但在自编码运算过程中,容易混入一些随机性,在公式中标识为高斯噪声,然后将编码器的输出作为下一道解码器的输入特征,最终得到一个生成后的数据分布信息。
简单的架构如下所示,以变分自编码器(Variational auto-encoder,VAE)为例。
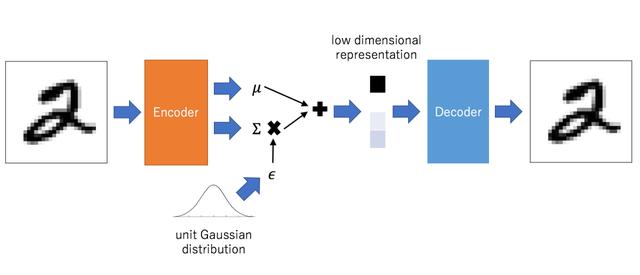
接下来,按照条理逻辑分别介绍。
1.自编码器(AE):
自编码器分成两个部分,第一个部分是encoder,一般是多层网络,将输入的数据压缩成为一个向量,变成低维度,而该向量就称之为瓶颈。第二个部分是decoder,灌之以瓶颈,输出数据,我们称之为重建输入数据。我们的目的是要让重建数据和原数据一样,以达到压缩还原的作用。损失函数就是让重建数据和原数据距离最小即可。损失函数参考图3。
下图是一次训练一个浅层自编码器
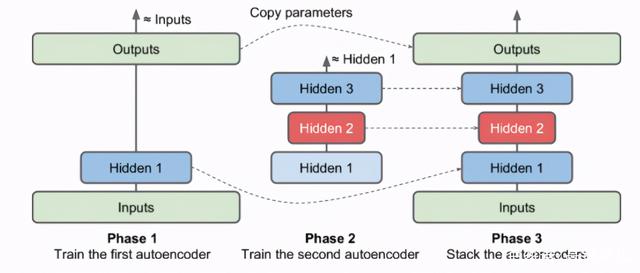
首先,第一个自编码器学习去重建输入。然后,第二个自编码器学习去重建第一个自编码器隐层的输出。最后,这两个自编码器被整合到一起。缺点:低维度的瓶颈显然丢失了很多有用的信息,重建的数据效果并不好。
2.去噪自编码器(DAE)
这里要讲的是,我们拿到一张干净的图片,想象一下比如是干净的原始minst数据集,此时我们给原来干净的图片集加上很多噪声,灌给编码器,我们希望可以还原成干净的是图片集,以和AE相同的方式去训练,得到的网络模型便是DAE.
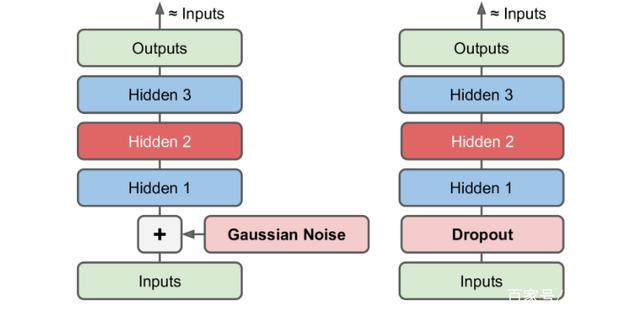
如上图,去噪编码器一般对最初输入增加噪声,通过训练之后得到无噪声的输出。这防止了自编码器简单的将输入复制到输出,从而提取出数据中有用的模式。增加噪声方式可以通过图6左侧增加高斯噪声,或者通过图6右侧的droupout,直接丢弃掉一层特征。
3.变分自编码器VAE
VAE和AE,DAE不同的是,原先编码器是映射成一个向量,现在是映射成两个向量,一个向量表示分布的平均值,另外一个表示分布的标准差,两个向量都是相同的正太分布。现在从两个向量分别采样,采样的数据灌给解码器。于是我们得到了损失函数:

损失函数的前部分和其他自编码器函数一样是重建loss损失,后部分是KL散度。KL散度是衡量两个不同分布的差异,有个重要的性质是总是非负的。仅当两个分布式完全相同的时候才是0。所以后部分的作用就是控制瓶颈处的两个向量处于正态分布。(均值为0,标准差为1)。这里有一个问题,从两个分布采样数据,BP时候怎么做?所以有一个技巧叫做参数重现(Reparameterization Trick),前向传播的时候,我们是通过以上公式得到z,BP的时候是让神经网络去拟合μ和σ,一般我们很难求的参数都丢给神经网络就好,就像Batch Normonization的γ和β一样。缺点效果还是比较模糊。
4.去耦变分自编码
我们希望瓶颈处的向量,即低维度的向量把编码过程中有用的维度保留下来,把没有用的维度用正态分布的噪声替代,可以理解为学习不同维度的特征,只是这些特征有好坏之分而已。我们仅需在loss function中加上一个β即可达到目的。

最后实验表明,VAE在重建图片时候对图片的<长度,宽度,大小,角度>四个值时候是混乱的,而去耦变分自编码器是能比较清晰的展示,最后生成的图片效果也更锐利清楚。至此,非常简单明了的介绍完了自编码到去噪自编码器到变分自编码器到去耦变分自编码。