线程的注意点
学习目标
能够说出线程的注意点
1. 线程的注意点介绍
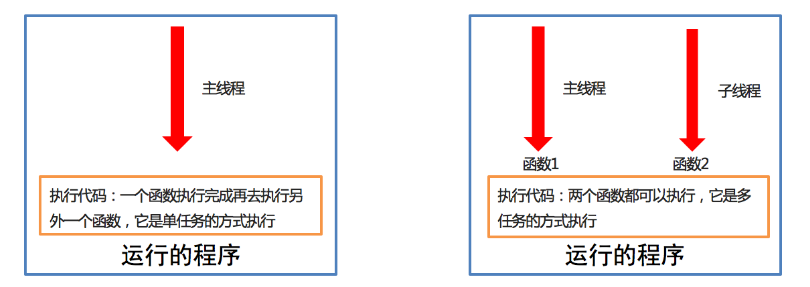
线程之间执行是无序的
主线程会等待所有的子线程执行结束再结束
线程之间共享全局变量
线程之间共享全局变量数据出现错误问题
2. 线程之间执行是无序的
import threading
import time
deftask():
time.sleep(1)
print("当前线程:", threading.current_thread().name)
if __name__ == '__main__':
for _ in range(5):
sub_thread = threading.Thread(target=task)
sub_thread.start()执行结果:
当前线程: Thread-1
当前线程: Thread-2
当前线程: Thread-4
当前线程: Thread-5
当前线程: Thread-3说明:
线程之间执行是无序的,它是由cpu调度决定的 ,cpu调度哪个线程,哪个线程就先执行,没有调度的线程不能执行。
进程之间执行也是无序的,它是由操作系统调度决定的,操作系统调度哪个进程,哪个进程就先执行,没有调度的进程不能执行。
3. 主线程会等待所有的子线程执行结束再结束
假如我们现在创建一个子线程,这个子线程执行完大概需要2.5秒钟,现在让主线程执行1秒钟就退出程序,查看一下执行结果,示例代码如下:
import threading
import time
# 测试主线程是否会等待子线程执行完成以后程序再退出defshow_info():for i in range(5):
print("test:", i)
time.sleep(0.5)
if __name__ == '__main__':
sub_thread = threading.Thread(target=show_info)
sub_thread.start()
# 主线程延时1秒
time.sleep(1)
print("over")执行结果:
test: 0
test: 1
over
test: 2
test: 3
test: 4说明:
通过上面代码的执行结果,我们可以得知: 主线程会等待所有的子线程执行结束再结束
假如我们就让主线程执行1秒钟,子线程就销毁不再执行,那怎么办呢?
我们可以设置守护主线程
守护主线程:
守护主线程就是主线程退出子线程销毁不再执行
设置守护主线程有两种方式:
threading.Thread(target=show_info, daemon=True)
线程对象.setDaemon(True)
设置守护主线程的示例代码:
import threading
import time
# 测试主线程是否会等待子线程执行完成以后程序再退出defshow_info():for i in range(5):
print("test:", i)
time.sleep(0.5)
if __name__ == '__main__':
# 创建子线程守护主线程 # daemon=True 守护主线程# 守护主线程方式1
sub_thread = threading.Thread(target=show_info, daemon=True)
# 设置成为守护主线程,主线程退出后子线程直接销毁不再执行子线程的代码# 守护主线程方式2# sub_thread.setDaemon(True)
sub_thread.start()
# 主线程延时1秒
time.sleep(1)
print("over")执行结果:
test: 0
test: 1
over3. 线程之间共享全局变量
需求:
定义一个列表类型的全局变量
创建两个子线程分别执行向全局变量添加数据的任务和向全局变量读取数据的任务
查看线程之间是否共享全局变量数据
import threading
import time
# 定义全局变量
my_list = list()
# 写入数据任务defwrite_data():for i in range(5):
my_list.append(i)
time.sleep(0.1)
print("write_data:", my_list)
# 读取数据任务defread_data():
print("read_data:", my_list)
if __name__ == '__main__':
# 创建写入数据的线程
write_thread = threading.Thread(target=write_data)
# 创建读取数据的线程
read_thread = threading.Thread(target=read_data)
write_thread.start()
# 延时# time.sleep(1)# 主线程等待写入线程执行完成以后代码在继续往下执行
write_thread.join()
print("开始读取数据啦")
read_thread.start()执行结果:
write_data: [0, 1, 2, 3, 4]
开始读取数据啦
read_data: [0, 1, 2, 3, 4]4. 线程之间共享全局变量数据出现错误问题
需求:
定义两个函数,实现循环100万次,每循环一次给全局变量加1
创建两个子线程执行对应的两个函数,查看计算后的结果
import threading
# 定义全局变量
g_num = 0# 循环一次给全局变量加1defsum_num1():for i in range(1000000):
global g_num
g_num += 1
print("sum1:", g_num)
# 循环一次给全局变量加1defsum_num2():for i in range(1000000):
global g_num
g_num += 1
print("sum2:", g_num)
if __name__ == '__main__':
# 创建两个线程
first_thread = threading.Thread(target=sum_num1)
second_thread = threading.Thread(target=sum_num2)
# 启动线程
first_thread.start()
# 启动线程
second_thread.start()执行结果:
sum1: 1210949
sum2: 1496035注意点:
多线程同时对全局变量操作数据发生了错误
错误分析:
两个线程first_thread和second_thread都要对全局变量g_num(默认是0)进行加1运算,但是由于是多线程同时操作,有可能出现下面情况:
在g_num=0时,first_thread取得g_num=0。此时系统把first_thread调度为”sleeping”状态,把second_thread转换为”running”状态,t2也获得g_num=0
然后second_thread对得到的值进行加1并赋给g_num,使得g_num=1
然后系统又把second_thread调度为”sleeping”,把first_thread转为”running”。线程t1又把它之前得到的0加1后赋值给g_num。
这样导致虽然first_thread和first_thread都对g_num加1,但结果仍然是g_num=1
全局变量数据错误的解决办法:
线程同步: 保证同一时刻只能有一个线程去操作全局变量 同步: 就是协同步调,按预定的先后次序进行运行。如:你说完,我再说, 好比现实生活中的对讲机
线程同步的方式:
线程等待(join)
互斥锁
线程等待的示例代码:
import threading
# 定义全局变量
g_num = 0# 循环1000000次每次给全局变量加1defsum_num1():for i in range(1000000):
global g_num
g_num += 1
print("sum1:", g_num)
# 循环1000000次每次给全局变量加1defsum_num2():for i in range(1000000):
global g_num
g_num += 1
print("sum2:", g_num)
if __name__ == '__main__':
# 创建两个线程
first_thread = threading.Thread(target=sum_num1)
second_thread = threading.Thread(target=sum_num2)
# 启动线程
first_thread.start()
# 主线程等待第一个线程执行完成以后代码再继续执行,让其执行第二个线程# 线程同步: 一个任务执行完成以后另外一个任务才能执行,同一个时刻只有一个任务在执行
first_thread.join()
# 启动线程
second_thread.start()执行结果:
sum1: 1000000
sum2: 20000005. 小结
线程执行执行是无序的
主线程默认会等待所有子线程执行结束再结束,设置守护主线程的目的是主线程退出子线程销毁。
线程之间共享全局变量,好处是可以对全局变量的数据进行共享。
线程之间共享全局变量可能会导致数据出现错误问题,可以使用线程同步方式来解决这个问题。
线程等待(join)