敏感词之 DFA 算法
常用算法
遍历匹配
将输入的词语,与词库中的敏感词逐个字符遍历,对比是否包含
优点:思路简单,易于实现(KMP 算法,Brute-Force 算法)
缺点:当词库数目非常大时,单纯只是匹配,其实性能依然非常的低。
正则表达式
优点:匹配能力强,抗变种敏感词
缺点:性能极弱
什么是DFA
DFA(deterministic finite automaton) 确定有限状态自动机或确定有限自动机,其由一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。
可以类比日常中使用的工作流,每个工作的流程都是确定且数目固定的(提交申请->上级审批->得到回复),当前流程的结果是下级流程触发的前提
在实现敏感词过滤的算法中,必须要减少运算,而DFA在DFA算法中几乎没有什么计算,有的只是状态的转换。
例子
诚然,加入在我们的敏感词库中存在如下几个敏感词:日本人、日本鬼子。
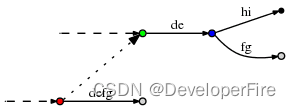
那么我需要构建成一个搜索树
Plain Text
query 日 ---> {本}、query 本 --->{人、鬼子}、query 人 --->{null}、query 鬼 ---> {子}
形如下结构:
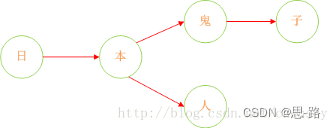
这样我们就将我们的敏感词库构建成了一个类似一颗的树,这样我们判断一个词是否为敏感词时就大大减少了检索的匹配范围。比如我们要判断日本人,根据第一个字我们就可以确认需要检索的是那棵树,然后再在这棵树中进行检索。
具体流程
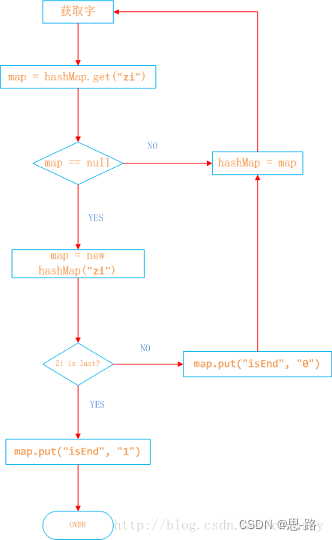
以Java中的HashMap为例来实现DFA算法。
具体过程如下:
日本人,日本鬼子为例
1、在hashMap中查询“日”看其是否在hashMap中存在,如果不存在,则证明已“日”开头的敏感词还不存在,则我们直接构建这样的一棵树。跳至3。
2、如果在hashMap中查找到了,表明存在以“日”开头的敏感词,设置hashMap = hashMap.get(“日”),跳至1,依次匹配“本”、“人”。
3、判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位 isEnd = 1,否则设置标志位 isEnd = 0;
参考
确定有限状态自动机 - 维基百科,自由的百科全书 (wikipedia.org)
java 敏感词之 DFA 算法(Tire Tree 算法)详解
使用DFA实现文字过滤 - 数据结构 - Tech - ITeye论坛