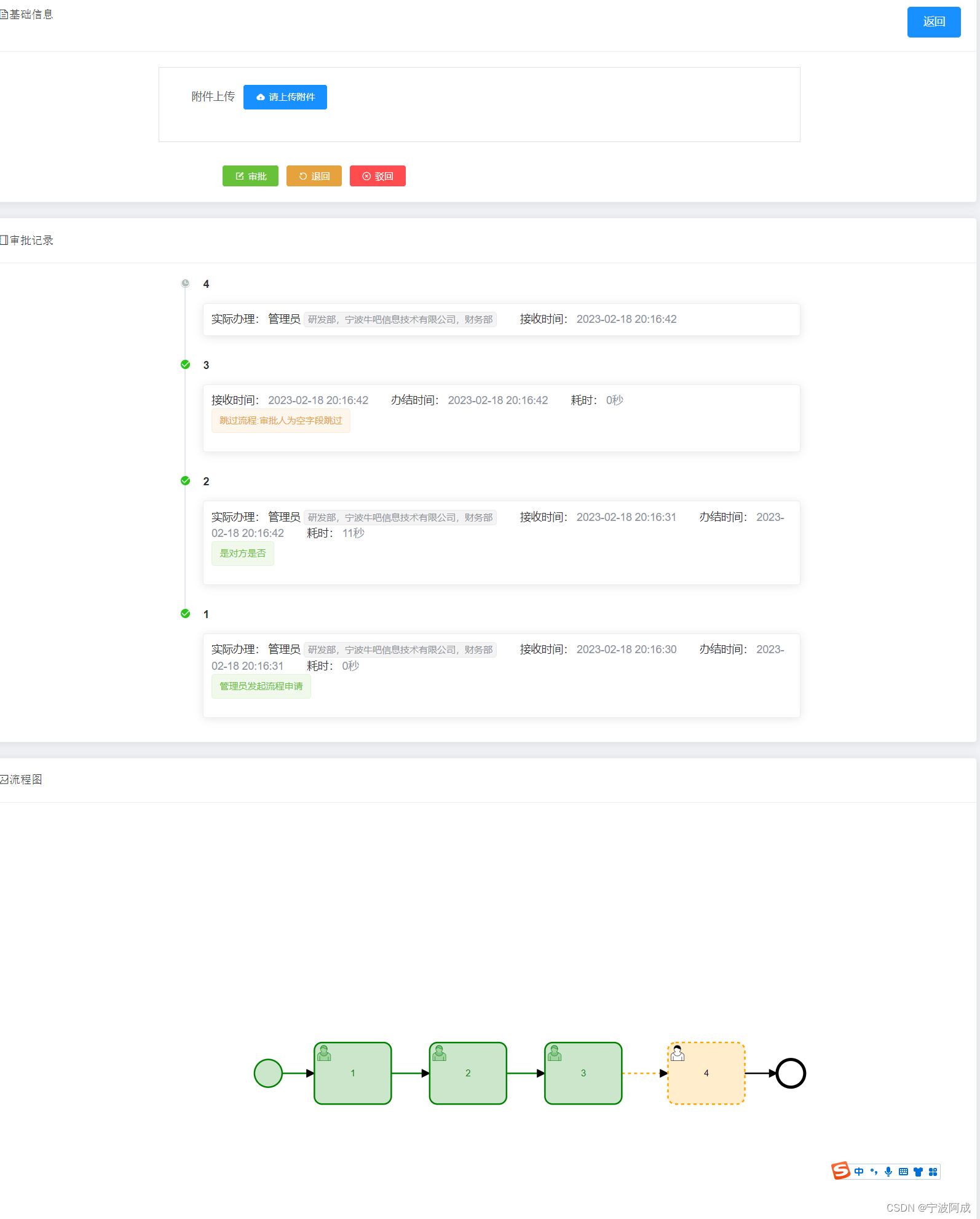
OpenAI-CLIP

官方介绍
-
尽管深度学习已经彻底改变了计算机视觉,但目前的方法存在几个主要问题:典型的视觉数据集是劳动密集型的,创建成本高,同时只教授一组狭窄的视觉概念;标准视觉模型擅长于一项任务且仅擅长于一项任务,并且需要大量的努力来适应新的任务;在基准测试中表现良好的模型在压力测试中的表现令人失望,1234对整个计算机视觉深度学习方法产生了怀疑。
-
我们提出了一个旨在解决这些问题的神经网络:它是在各种各样的图像上训练的,有各种各样的自然语言监督,这些图像在互联网上随处可见。通过设计,可以用自然语言指导网络执行各种各样的分类基准测试,而不直接优化基准测试的性能,类似于GPT-25和GPT-3.6的“零镜头”功能。这是一个关键的变化:通过不直接优化基准测试,我们表明它变得更具代表性:我们的系统在不使用任何原始1.28M标记示例的情况下,在ImageNet零拍上与原始ResNet-507的性能匹配时,将这一“鲁棒性差距”缩小了75%。
CLIP使用示例
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
import cv2
import skimage
import IPython.display
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from glob import glob
from collections import OrderedDict
import torch
import gc
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
安装CLIP库
openai-clip-weights链接
!pip install ../input/openaiclipweights/python-ftfy-master/python-ftfy-master
!pip install ../input/openaiclipweights/clip/CLIP
!cp ../input/openaiclipweights/CLIP-main/CLIP-main/clip/bpe_simple_vocab_16e6.txt /opt/conda/lib/python3.7/site-packages/clip/.
!gzip -k /opt/conda/lib/python3.7/site-packages/clip/bpe_simple_vocab_16e6.txt
!ls /opt/conda/lib/python3.7/site-packages/clip/.
import torch
import clip
from tqdm.notebook import tqdm
from torch.utils.data import DataLoader, Dataset
print("Torch version:", torch.__version__)
- 下载几张图片用于测试
!wget https://farm8.staticflickr.com/6036/6426668771_b5b915e46c_o.jpg
!wget https://c6.staticflickr.com/8/7457/10806045045_02d3dbdcee_o.jpg
!wget https://c1.staticflickr.com/4/3267/2888764405_0a0a608604_o.jpg
!wget https://farm8.staticflickr.com/4028/4294212194_a49663b2b9_o.jpg
!wget https://c5.staticflickr.com/9/8173/8019508216_6540c8686a_o.jpg
!wget https://farm3.staticflickr.com/1146/1357102390_943c5cb999_o.jpg
- 统计图片列表
files = glob('*.jpg')
print(files)
- 列出可用的CLIP预训练模型
clip.available_models()

- 列出可用的CLIP预训练权重
!ls ../input/openaiclipweights/clip/CLIP/models/
- 加载CLIP的基础视觉模型
model, preprocess = clip.load("../input/openaiclipweights/clip/CLIP/models/ViT-B-32.pt")
model.cuda().eval()

重头戏,对每一张图片我们可以提问问题,并且查看CLIP会做出什么样的回答
QUERIES = [
"a dog",
"a cat",
"a elephant",
"a zebra",
"a sleeping dog",
"a sleeping cat",
"a giraffe",
"a poodle",
"animal inside a car",
"animal outside a car",
"a sofa",
"some animals",
"santa claus",
"ipod",
"two mugs",
"three mugs",
"blue sky",
] ```
## 使用CLIP结合问题对图片进行打分
```python
with torch.no_grad():
for file in files:
print(file)
#加载图像数据
img = Image.open(file).convert('RGB')
#图片可视化
plt.imshow(cv2.resize(np.array(img),(256,256)))
plt.show()
#使用clip对图片进行预处理
img = preprocess(img).unsqueeze(0).cuda()
#将图片进行编码
image_embeddings = model.encode_image(img)
image_embeddings/=image_embeddings.norm(dim=-1, keepdim = True)
score = []
#提问问题并且进行打分
for query in QUERIES:
text = clip.tokenize(query)cuda()
#问题文本编码
text_embeddings = model.encode_text(texts)
text_embeddings /= text_embeddings.norm(dim=-1, keepdim=True)
#计算图片和问题之间的匹配分数
sc = float((image_embeddings @ text_embeddings.T).cpu().numpy())
score.append(sc)
print( pd.DataFrame({'query': QUERIES, 'score': score}).sort_values('score', ascending=False) )
print('')
print('-------------------------')
print('')


数据集
petfinder-data
参考文章
OpenAI推出CLIP:连接文本与图像,Cover所有视觉分类任务
openai-CLIP

![[软件工程导论(第六版)]第3章 需求分析(复习笔记)](https://img-blog.csdnimg.cn/d8ef7b8e31654d6ea1cfb6ca521355fa.png)