文章目录
- 前言
- 一. 实验环境
- 二. 安装ubuntu虚拟机
- 2. 1.下载ubuntu镜像
- 2.2 配置虚拟机
- 2.3 安装操作系统
- 三. 安装MindSpore20.0-alpha
- 3.1 下载需要的安装程序脚本
- 3.2 安装MindSpore 2.0.0-alpha和Python 3.7
- 3.3 开始手动安装
- 3.4. 安装gcc
- 3. 5.安装MindSpore
- 3.6. 验证是否成功:
- 四. 实现数据变换 Transforms
- 4.1 compse模块
- 4.2 mindspore.dataset.vision模块
- 4.2.1 Rescale
- 4.2.2 Normalize
- 4.23 HWC2CWH
- 4.3 Text Transforms
- 4.3.1 BasicTokenizer
- 4.3.2 Lookup
- 4.4 Lambda Transforms
- 总结

前言
大家好,我是沐风晓月,本文是对昇思MindSpore社区的产品进行测试,测试的步骤,记录产品的使用体验和学习。
如果文章有什么需要改进的地方还请大佬不吝赐教👏👏。
🏠个人主页:我是沐风晓月
🧑个人简介:大家好,我是沐风晓月,双一流院校计算机专业😉😉
💕 座右铭: 先努力成长自己,再帮助更多的人 ,一起加油进步🍺🍺🍺
💕欢迎大家:这里是CSDN,我总结知识的地方,喜欢的话请三连,有问题请私信😘
如何加入社区? 参加下图:
一. 实验环境
参考下图进行设置:
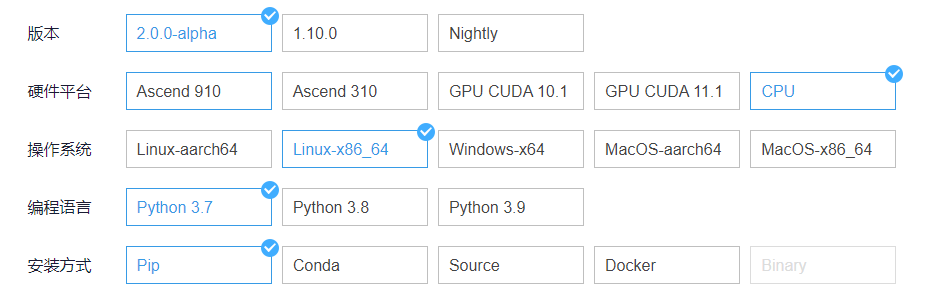
操作系统: ubuntu18.04
编程语言: python3.7版本
安装方式: pip安装
二. 安装ubuntu虚拟机
这里使用的是ubuntu18.4的系统
2. 1.下载ubuntu镜像
-
打开清华大学开源镜像站
下载地址:https://mirrors.tuna.tsinghua.edu.cn/
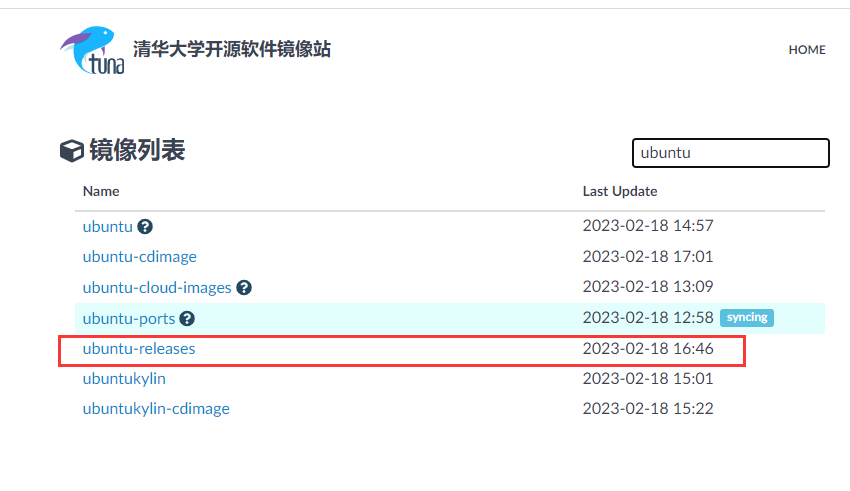
-
选择18.04版本
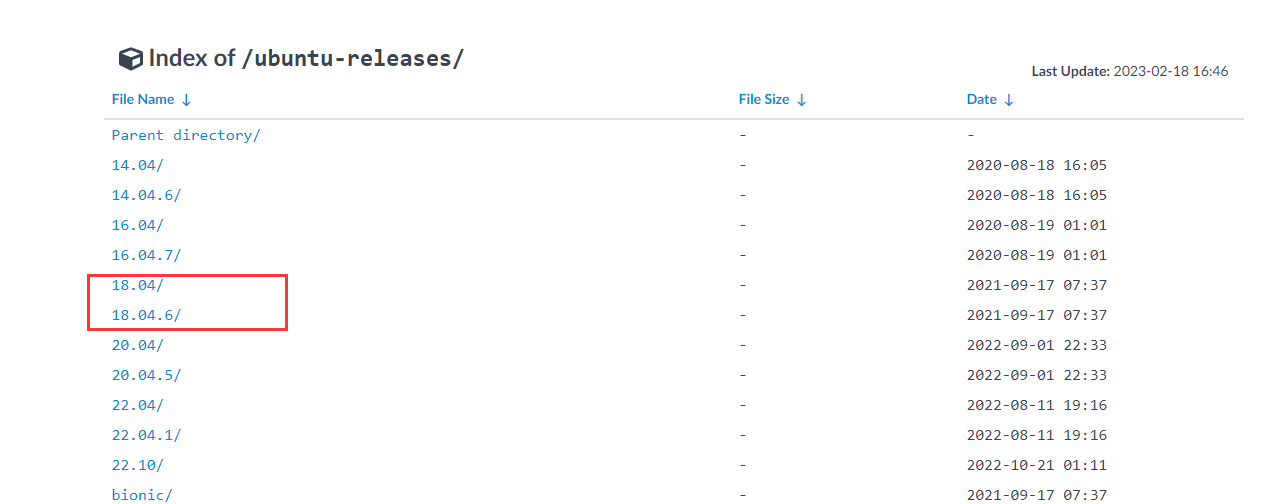
- 下载iso镜像
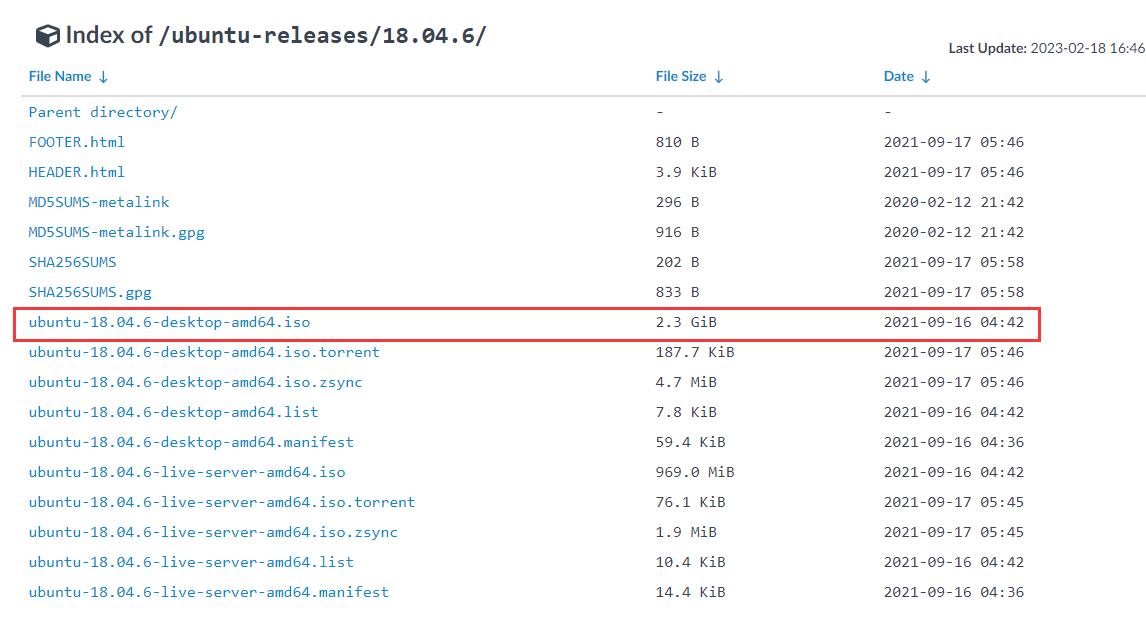
2.2 配置虚拟机
- 打开新建虚拟机,创建虚拟机向导点击下一步
- 选择稍微安装操作系统
- 选择linux操作系统,ubuntu64
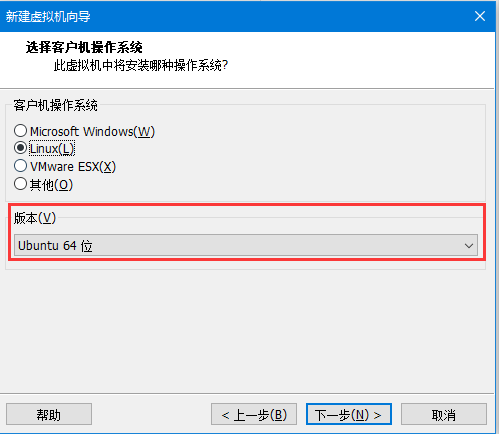
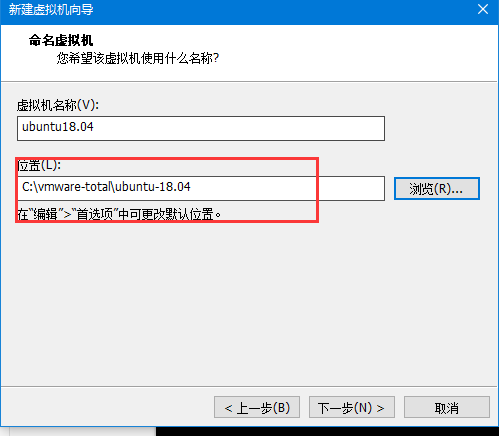
- 命名虚拟机
此处一定要注意,虚拟机的名字见名知意
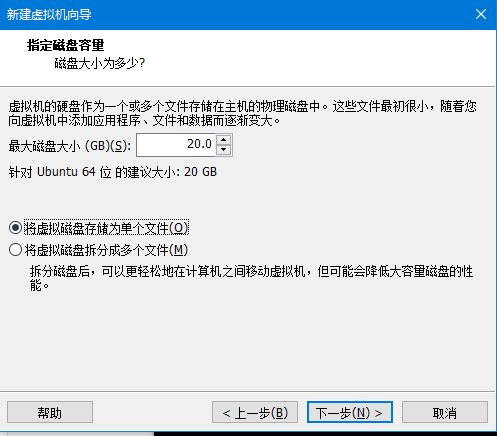
- 指定磁盘容量
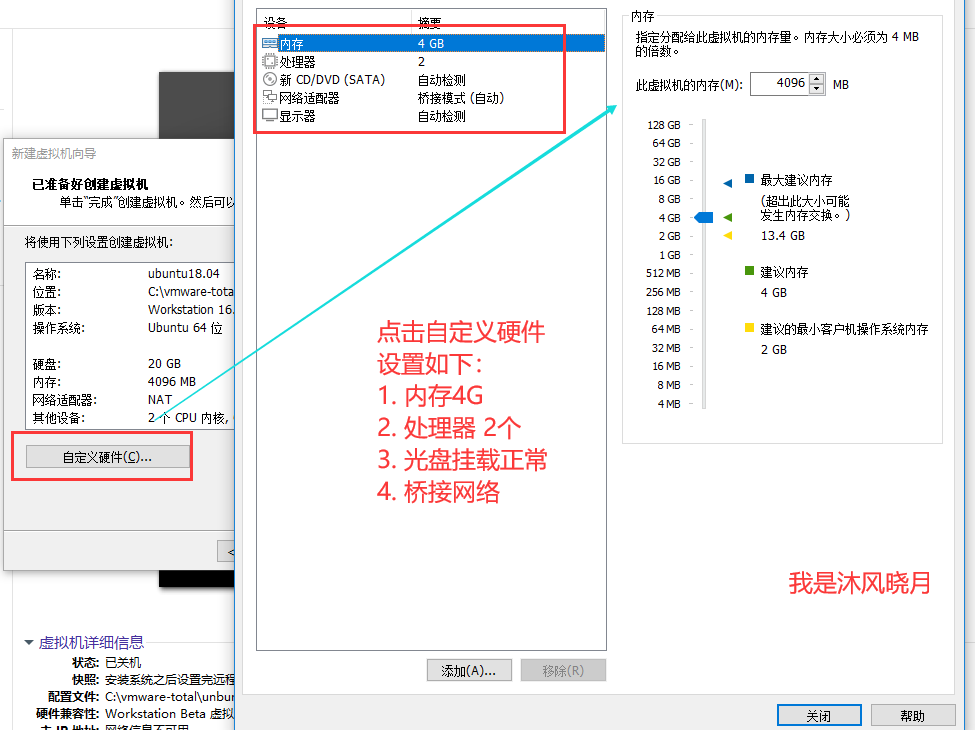
- 设置虚拟机的自定义配置,点击完成
- 完成后效果图如下,然后点击开启
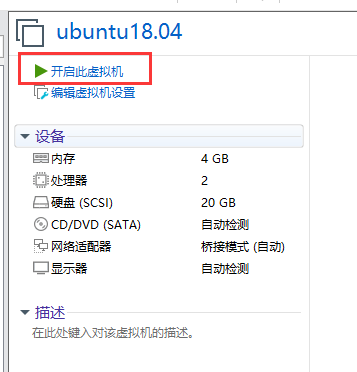
2.3 安装操作系统
为了让大多数人能看懂,我们选择中文版本安装
- 点击开始安装系统:
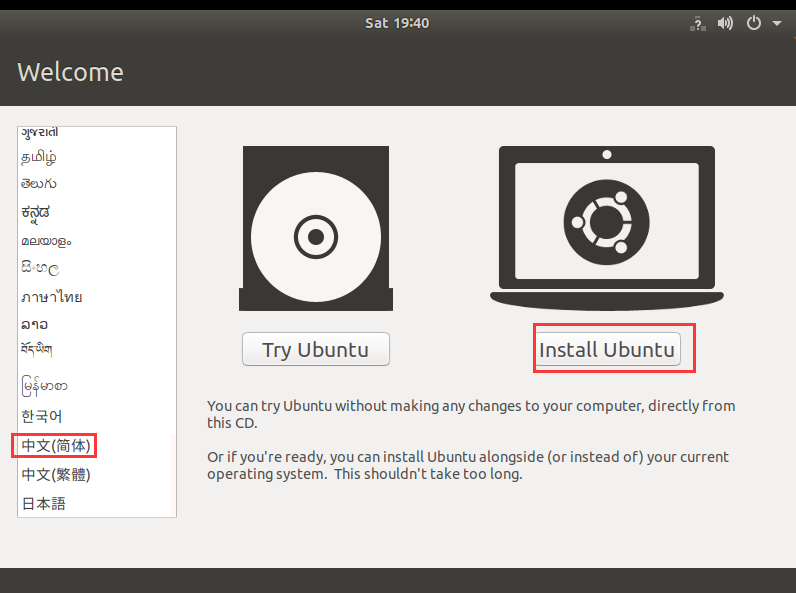
- 键盘布局默认即可
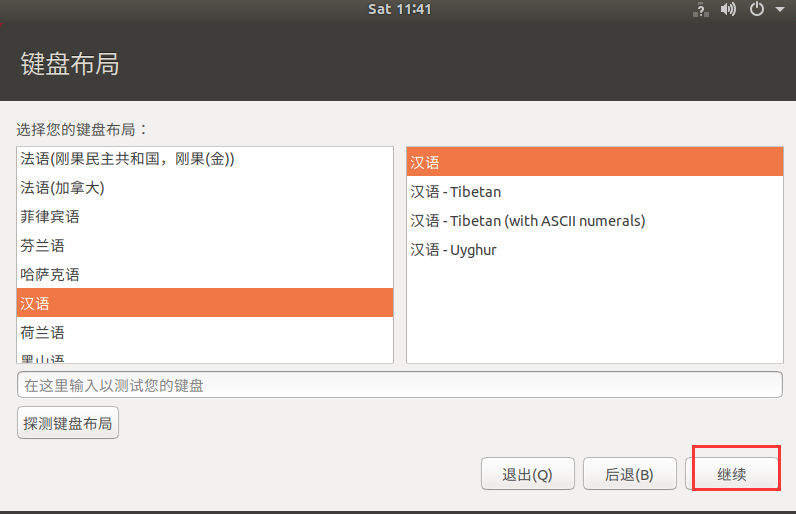
- 更新软件,这里我们选正常安装
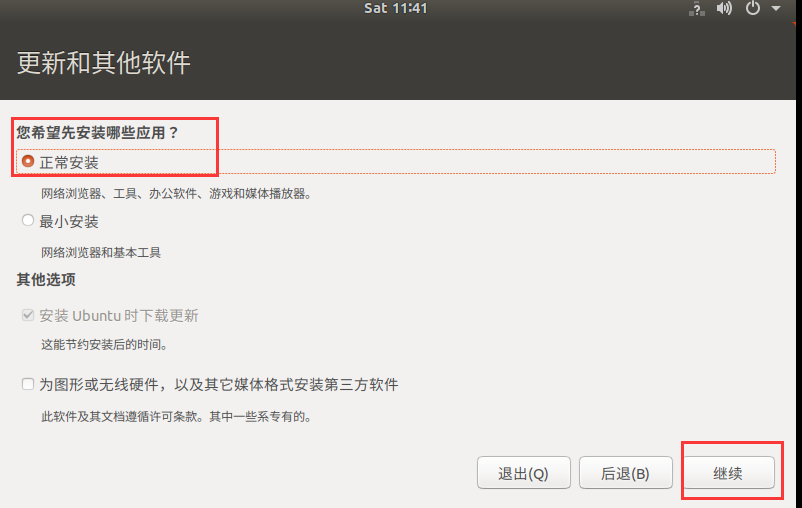
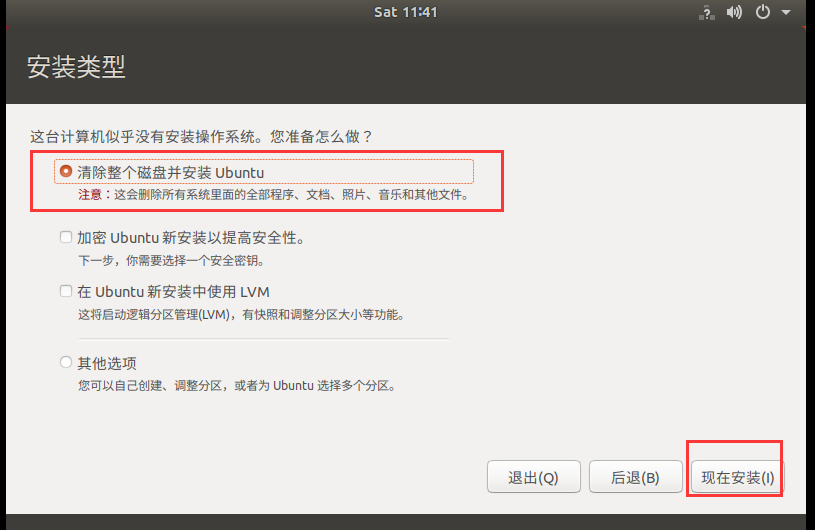
- 这里我们是一块新盘,所以选择整个磁盘安装系统,并点击继续
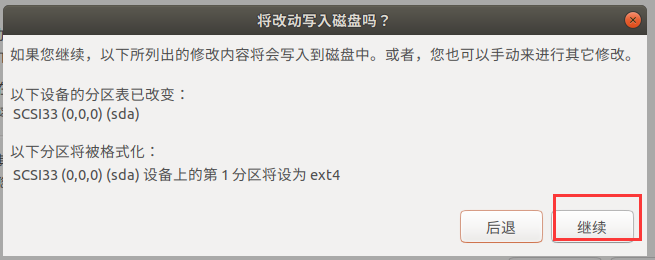
- 选择时区
默认就是上海,这里点击继续即可
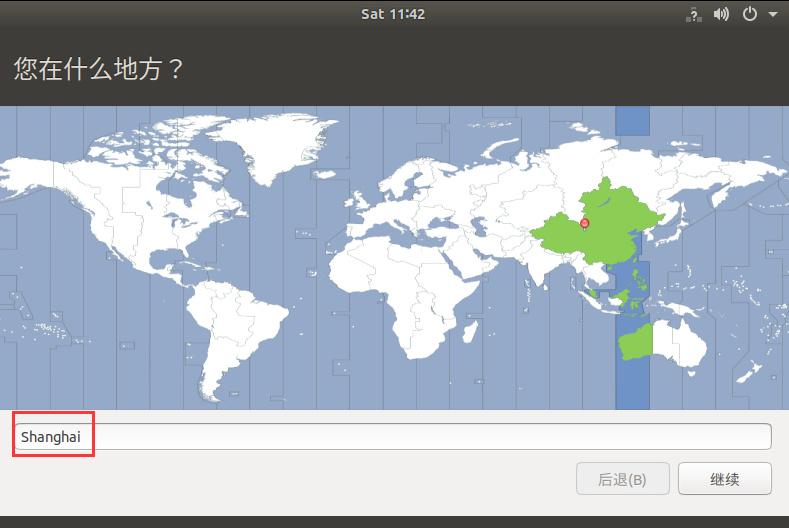
-设置用户名和密码

- 开始安装系统,等待直到完成
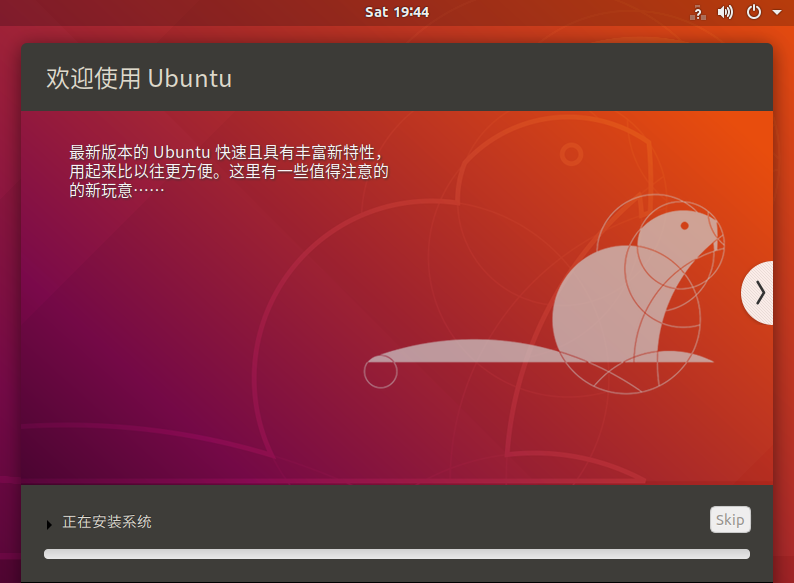
完成后的照片,点起重启
重启后,系统安装成功!
三. 安装MindSpore20.0-alpha
3.1 下载需要的安装程序脚本
root@mufengxiaoyue:~# wget https://gitee.com/mindspore/mindspore/raw/r2.0.0-alpha/scripts/install/ubuntu-cpu-pip.sh
3.2 安装MindSpore 2.0.0-alpha和Python 3.7
这里直接使用自动化安装
MINDSPORE_VERSION=2.0.0a0 bash ./ubuntu-cpu-pip.sh
这一步主要做了以下的事情:
- 更改软件源配置为华为云源。
- 安装MindSpore所需的依赖,如GCC。
- 通过APT安装Python3和pip3,并设为默认。
- 通过pip安装MindSpore CPU版本。
在自动化安装的过程中遇到的问题,应该是提供 网址
(在这里遇到一个问题,应该是提供的网址出现了问题,截图如下:

于是转入手动安装
3.3 开始手动安装
经过测试下,虽然自动化脚本没有一次性安装成功,但自动化脚本已经把python安装好了,python版本如下:
root@mufengxiaoyue:~# python -V
Python 3.7.16
root@mufengxiaoyue:~# python --version
Python 3.7.16
3.4. 安装gcc
直接使用apt-get命令安装即可
#sudo apt-get install gcc-7 -y
3. 5.安装MindSpore
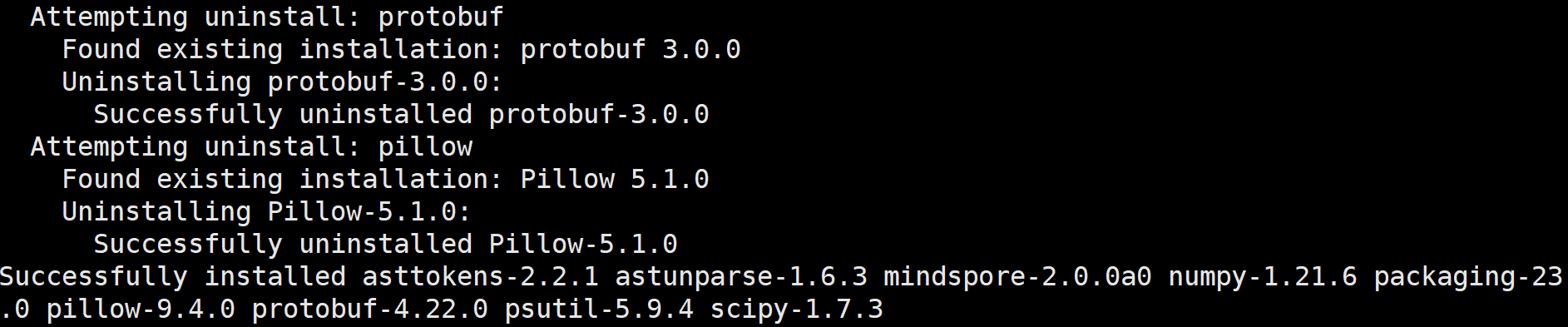
这一步开始安装mindSpore 20.0的版本,直接安装即可,尽量使用普通用户安装,使用root安装会有警告提示,但也不影响使用。
root@mufengxiaoyue:~# export MS_VERSION=2.0.0a0
#pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/${MS_VERSION}/MindSpore/unified/x86_64/mindspore-${MS_VERSION/-/}-cp37-cp37m-linux_x86_64.whl \
--trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
最后执行结果如下:
3.6. 验证是否成功:
root@mufengxiaoyue:~# python -c "import mindspore;mindspore.run_check()"
MindSpore version: 2.0.0a0
The result of multiplication calculation is correct, MindSpore has been installed successfully!
至此MindSpore已经安装成功。
四. 实现数据变换 Transforms
通常情况下,直接加载的原始数据并不能直接送入神经网络进行训练,此时我们需要对其进行数据预处理。
MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
4.1 compse模块
mindspore.dataset.transforms模块支持一系列通用Transforms。这里我们以Compose为例,介绍其使用方式。
Compose接收一个数据增强操作序列,然后将其组合成单个数据增强操作。我们仍基于Mnist数据集呈现Transforms的应用效果
代码如下:
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" "notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
train_dataset = MnistDataset('MNIST_Data/train')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
~
代码运行结果:

代码如下:
1 import numpy as np
2 from PIL import Image
3 from download import download
4 from mindspore.dataset import transforms, vision, text
5 from mindspore.dataset import GeneratorDataset, MnistDataset
6 url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" "notebook/datasets/MNIST_Data.zip"
7 path = download(url, "./", kind="zip", replace=True)
8
9 train_dataset = MnistDataset('MNIST_Data/train')
10 image, label = next(train_dataset.create_tuple_iterator())
11 print(image.shape)
12
13 composed = transforms.Compose(
14 [
15 vision.Rescale(1.0 / 255.0, 0),
16 vision.Normalize(mean=(0.1307,), std=(0.3081,)),
17 vision.HWC2CHW()
18 ]
19 )
20
21
22
23
24 train_dataset = train_dataset.map(composed, 'image')
25 image, label = next(train_dataset.create_tuple_iterator())
26 print(image.shape)
执行结果:
4.2 mindspore.dataset.vision模块
mindspore.dataset.vision模块提供一系列针对图像数据的Transforms。在Mnist数据处理过程中,使用了Rescale、Normalize和HWC2CHW变换
4.2.1 Rescale
Rescale变换用于调整图像像素值的大小,包括两个参数:
-
rescale:缩放因子。
-
shift:平移因子。
图像的每个像素将根据这两个参数进行调整,输出的像素值为outputi=inputi∗rescale+shift。
这里我们先使用numpy随机生成一个像素值在[0, 255]的图像,将其像素值进行缩放。
代码案例:
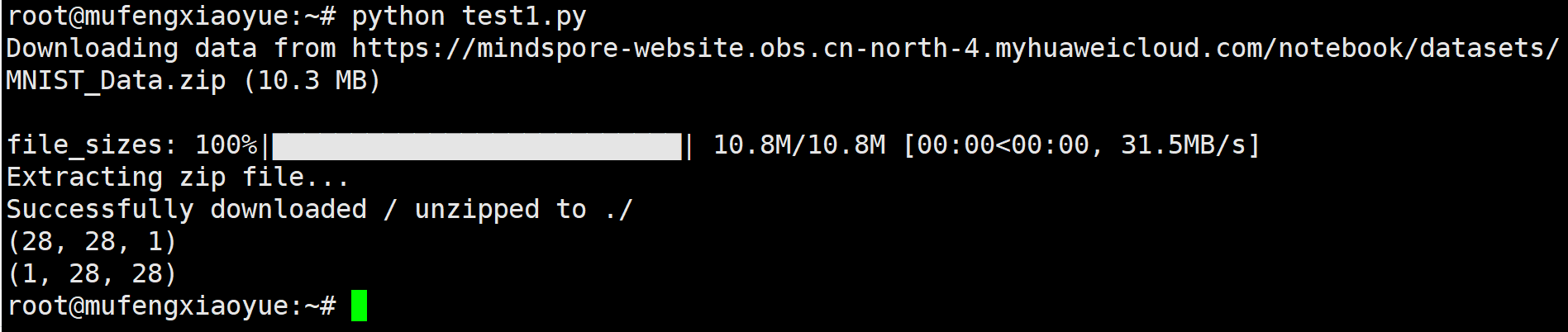
root@mufengxiaoyue:~# cat test1.py
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
print(random_np)
执行结果:
root@mufengxiaoyue:~# python test1.py
[[249 139 103 ... 186 210 138]
[203 81 151 ... 182 34 51]
[190 58 25 ... 242 141 247]
...
[250 193 141 ... 35 35 104]
[164 183 23 ... 125 252 58]
[ 50 106 213 ... 189 72 139]]
为了更直观地呈现Transform前后的数据对比,我们使用Transforms的Eager模式进行演示。首先实例化Transform对象,然后调用对象进行数据处理。
root@mufengxiaoyue:~# cat -n test1.py
1 import numpy as np
2 from PIL import Image
3 from download import download
4 from mindspore.dataset import transforms, vision, text
5 from mindspore.dataset import GeneratorDataset, MnistDataset
6
7
8 random_np = np.random.randint(0, 255, (48, 48), np.uint8)
9 random_image = Image.fromarray(random_np)
10 print(random_np)
11
12
13 rescale = vision.Rescale(1.0 / 255.0, 0)
14 rescaled_image = rescale(random_image)
15 print(rescaled_image)
执行结果:
root@mufengxiaoyue:~# python test1.py
[[192 85 117 ... 145 101 9]
[217 106 87 ... 83 129 209]
[129 12 253 ... 83 15 158]
...
[ 35 95 231 ... 78 93 188]
[ 81 143 206 ... 170 0 4]
[241 157 166 ... 61 28 95]]
[[0.75294125 0.33333334 0.45882356 ... 0.5686275 0.39607847 0.03529412]
[0.85098046 0.4156863 0.34117648 ... 0.3254902 0.5058824 0.8196079 ]
[0.5058824 0.04705883 0.9921569 ... 0.3254902 0.05882353 0.61960787]
...
[0.13725491 0.37254903 0.9058824 ... 0.30588236 0.3647059 0.7372549 ]
[0.31764707 0.56078434 0.8078432 ... 0.6666667 0. 0.01568628]
[0.9450981 0.6156863 0.6509804 ... 0.2392157 0.10980393 0.37254903]]
可以看到使用Rescale后的每个像素值都进行了缩放。
4.2.2 Normalize
Normalize变换用于对输入图像的归一化,包括三个参数:
-
mean:图像每个通道的均值。
-
std:图像每个通道的标准差。
-
is_hwc:输入图像格式为(height, width, channel)还是(channel, height, width)。
图像的每个通道将根据mean和std进行调整:
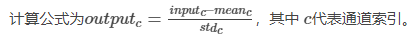
代码案例:
root@mufengxiaoyue:~# cat test1.py
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
#print(random_np)
#
#
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
#print(rescaled_image)
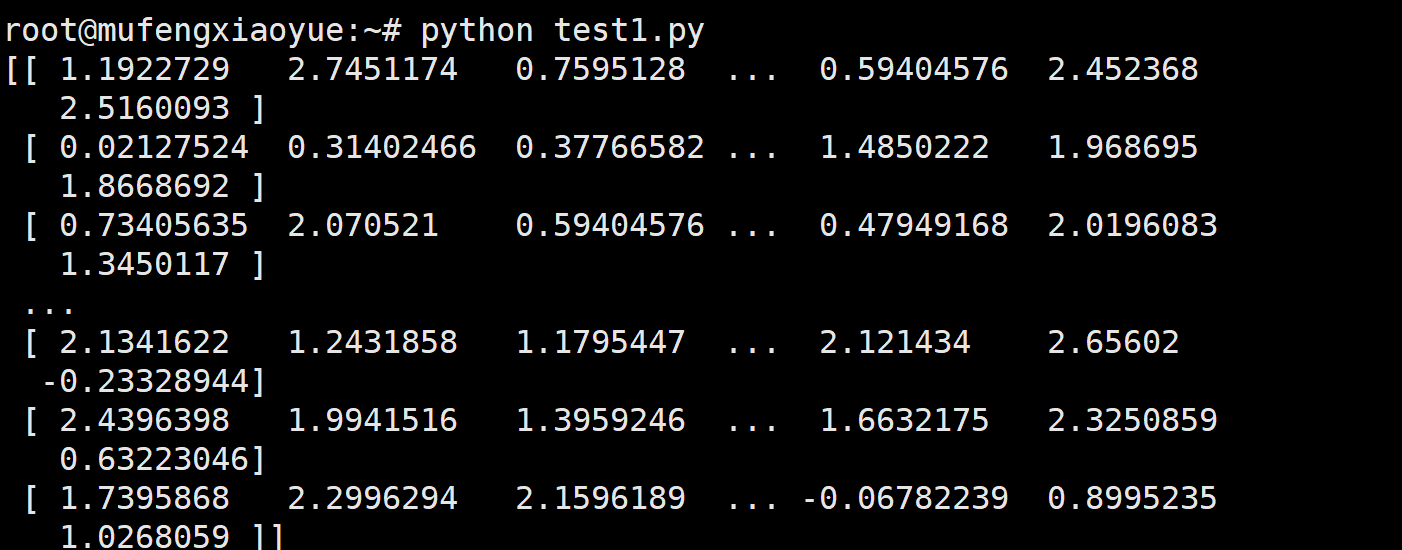
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
print(normalized_image)
执行结果:
4.23 HWC2CWH
HWC2CWH变换用于转换图像格式。在不同的硬件设备中可能会对(height, width, channel)或(channel, height, width)两种不同格式有针对性优化。MindSpore设置HWC为默认图像格式,在有CWH格式需求时,可使用该变换进行处理。
这里我们先将前文中normalized_image处理为HWC格式,然后进行转换。可以看到转换前后的shape发生了变化。
演示代码:
root@mufengxiaoyue:~# cat test1.py
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
#print(random_np)
#
#
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
#print(rescaled_image)
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
#print(normalized_image)
hwc_image = np.expand_dims(normalized_image, -1)
hwc2cwh = vision.HWC2CHW()
chw_image = hwc2cwh(hwc_image)
print(hwc_image.shape, chw_image.shape)
root@mufengxiaoyue:~#
执行结果:
root@mufengxiaoyue:~# python test1.py
(48, 48, 1) (1, 48, 48)
4.3 Text Transforms
mindspore.dataset.text模块提供一系列针对文本数据的Transforms。与图像数据不同,文本数据需要有分词(Tokenize)、构建词表、Token转Index等操作。这里简单介绍其使用方法。
4.3.1 BasicTokenizer
首先我们定义三段文本,作为待处理的数据,并使用GeneratorDataset进行加载。
texts = [
'Welcome to Beijing',
'北京欢迎您!',
'我喜欢China!',
]
test_dataset = GeneratorDataset(texts, 'text')
分词(Tokenize)操作是文本数据的基础处理方法,MindSpore提供多种不同的Tokenizer。这里我们选择基础的BasicTokenizer举例。配合map,将三段文本进行分词,可以看到处理后的数据成功分词。
test_dataset = test_dataset.map(text.BasicTokenizer())
print(next(test_dataset.create_tuple_iterator()))
执行结果

4.3.2 Lookup
Lookup为词表映射变换,用来将Token转换为Index。在使用Lookup前,需要构造词表,一般可以加载已有的词表,或使用Vocab生成词表。这里我们选择使用Vocab.from_dataset方法从数据集中生成词表。
代码案例:
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
texts = [
'Welcome to Beijing',
'北京欢迎您!',
'我喜欢China!',
]
test_dataset = GeneratorDataset(texts, 'text')
test_dataset = test_dataset.map(text.BasicTokenizer())
#print(next(test_dataset.create_tuple_iterator()))
vocab = text.Vocab.from_dataset(test_dataset)
print(vocab.vocab())
执行结果:
root@mufengxiaoyue:~# python test1.py
{'我': 10, '北': 7, '京': 6, '喜': 8, '!': 1, '!': 12, '迎': 11, 'Welcome': 4, '您': 9, '欢': 0, 'China': 3, 'Beijing': 2, 'to': 5}
生成词表后,可以配合map方法进行词表映射变换,将Token转为Index。
vocab = text.Vocab.from_dataset(test_dataset)
test_dataset = test_dataset.map(text.Lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))
执行结果:
root@mufengxiaoyue:~# python test1.py
[Tensor(shape=[3], dtype=Int32, value= [4, 5, 2])]
4.4 Lambda Transforms
Lambda函数是一种不需要名字、由一个单独表达式组成的匿名函数,表达式会在调用时被求值。Lambda Transforms可以加载任意定义的Lambda函数,提供足够的灵活度。在这里,我们首先使用一个简单的Lambda函数,对输入数据乘2:
代码如下:
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print(list(test_dataset.create_tuple_iterator()))
执行结果:
root@mufengxiaoyue:~# python test1.py
[[Tensor(shape=[], dtype=Int64, value= 2)], [Tensor(shape=[], dtype=Int64, value= 4)], [Tensor(shape=[], dtype=Int64, value= 6)]]
可以看到map传入Lambda函数后,迭代获得数据进行了乘2操作。
我们也可以定义较复杂的函数,配合Lambda函数实现复杂数据处理:
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
def func(x):
return x * x + 2
test_dataset = test_dataset.map(lambda x: func(x))
print(list(test_dataset.create_tuple_iterator()))
执行结果:
root@mufengxiaoyue:~# python test1.py
[[Tensor(shape=[], dtype=Int64, value= 3)], [Tensor(shape=[], dtype=Int64, value= 6)], [Tensor(shape=[], dtype=Int64, value= 11)]]
总结
通过这次体验,对MindSpore 20.0 有了新的认识,因为是断断续续做的,大约耗时2个小时。
- 💕 好啦,这就是今天要分享给大家的全部内容了,我们下期再见!
- 💕 博客主页:mufeng.blog.csdn.net
- 💕 本文由沐风晓月原创,首发于CSDN博客
- 💕 每一个你想要学习的念头,都是未来的你像现在的你求救,不辜负未来,全力奔赴