Few-shot object detection的开山之作之一 ~~
特征学习器使用来自具有足够样本的基本类的训练数据来 提取 可推广以检测新对象类的meta features。The reweighting module将新类别中的一些support examples转换为全局向量,该全局向量indicates meta features对于检测相应物体的重要性或相关性。这两个模块与detection prediction 一起,基于an episodic few-shot learning scheme和一个精心设计的损失函数进行端到端的训练。通过大量的实验,我们证明了我们的模型在多个数据集和设置上,在少样本目标检测方面比之前建立良好的基线有很大的优势。
引入
最近,Meta Learning为类似的问题提供了很有希望的解决方案,即少样本分类。 然而,由于目标检测不仅涉及到类别预测,而且涉及到目标的定位,因此现有的少样本分类方法不能直接应用于少样本检测问题。 以匹配网络(Matching networks)和原型网络(Prototypical networks)为例,如何构建用于匹配和定位的对象原型尚不清楚,因为图像内可能存在无关类的分散注意力的对象或根本没有目标对象。(because there may be distracting objects of irrelevant classes within the image or no targeted objects at all.)
我们提出了一种新的检测模型,通过充分利用一些基类的检测训练数据,并根据一些支持实例快速调整检测预测网络来预测新的类,从而提供了few-shot learning能力。 该模型首先从基类中学习元特征(这些元特征可推广到不同对象类的检测)。 然后利用几个支持实例来识别元特征(这些元特征对于检测新的类是重要的和有鉴别性的,并相应地适应于将检测知识从基类转移到新的类。)
因此,我们提出的模型引入了一个新的检测框架,包括两个模块,即元特征学习器和轻量级features reweighting 模块。 给定一个查询图像和几个新类的支持图像,特征学习器从查询图像中提取元特征。 重新加权模块学习捕获支持图像的全局特征,并将其嵌入到重新加权系数中,以调制查询图像元特征。 因此,查询元特征有效地接收支持信息,并适合于新对象检测。 然后,将适应的元特征输入检测预测模块,以预测查询中新对象的类和边界盒(图2)。 特别地,如果有N个新的类要检测,重权模块将接受N个支持实例类,并将它们转换成N个重权向量,每个重权向量负责从相应的类中检测新的对象。 通过这种特定于类的重权向量,可以识别出新类的一些重要的、具有鉴别性的元特征,从而有助于检测决策,整个检测框架可以有效地学习检测新类。
元特征学习器和重权重模块与检测预测模块一起进行端到端的训练。 为了保证few-shot的泛化能力,整个few-shot检测模型采用两阶段学习方案进行训练:首先从基类中学习元特征和良好的重权值模块; 然后微调检测模型以适应新类。 为了解决检测学习中的困难(例如,存在分散注意力的物体),它引入了精心设计的损失函数。
我们提出的few-shot检测器在多个数据集和各种设置下都优于竞争基线方法。 此外,它还显示了从一个数据集到另一个不同的数据集的良好可移植性。 我们的贡献可概括如下:
We design a novel few-shot detection model that 1)learns generalizable meta features; and 2) automatically reweights the features for novel class detection by producing class-specific activating coefficients from a few support samples.
Related work
Few-shot learning
An increasingly popular solution for few-shot learning is meta-learning, which can further be divided into three
categories:
a) Metric learning based. In particular, Matching Networks [39] learn the task of finding the most similar class for the target image among a small set of labeled images. Prototypical Networks [35] extend Matching Networks by producing a linear classifier instead of weighted nearest neighbor for each class. Relation Networks [37] learn a distance metric to compare the target image to a few labeled images.
b) Optimization for fast adaptation. Ravi and Larochelle [28] propose an LSTM meta-learner that is trained to quickly converge a learner classifier in new few-shot tasks. Model-Agnostic Meta-Learning(MAML) [12] optimizes a task-agnostic network so that a few gradient updates on its parameters would lead to good performance on new few-shot tasks.
c) Parameter prediction. Learnet [2] dynamically learns the parameters of factorized weight layers based on a single example of each class to realize one-shot learning.
上面的方法只是为了识别新的图像而开发的,还有一些其他的工作试图学习一个模型can 对基本图像和新图像进行分类
Object detection with limited labels
弱监督方法考虑了训练对象检测器时只使用图像级标记,而不使用bounding box标记(获取代价更高)的问题。 Few example object detection 假设每类只有几个标记的bounding box,但依赖于大量的未标记图像来生成可信的伪标记框用于训练。 zero-shot object detection旨在检测以前看不到的类别,因此通常需要类之间的关系等外部信息。 与这些设置不同的是,我们的few-shot检测器为每个新的类使用非常少的bounding box标记(1-10),而不需要未标记的图像或外部知识。
方法
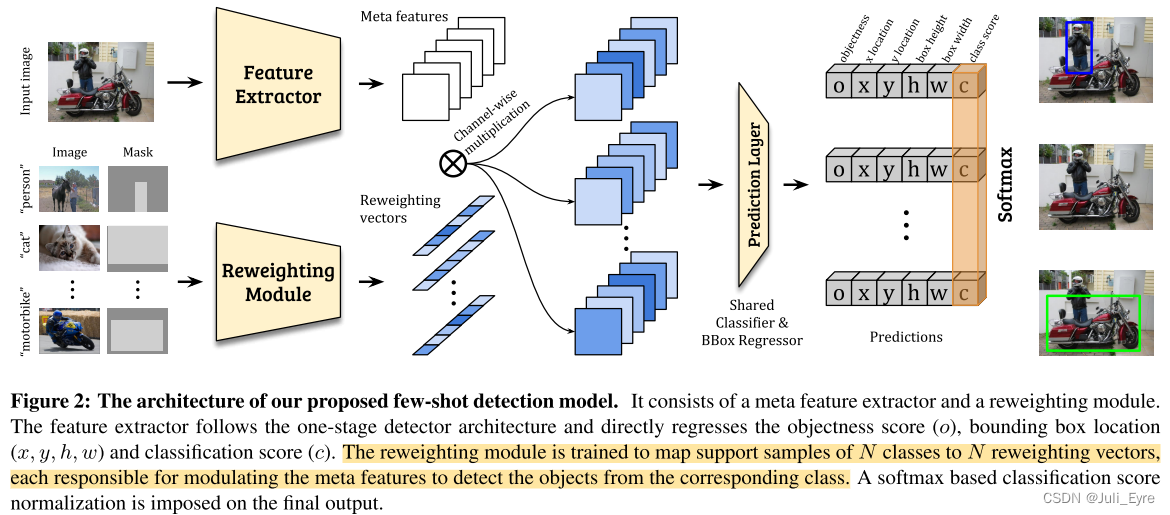
Feature Reweighting for Detection
我们提出的few-shot检测模型在一个阶段检测框架中引入了元特征学习器D和重权重模块M。 在本工作中,我们采用了无提案检测框架YOLOV2。 它 通过检测预测模块P 将每个锚点的特征直接回归得到相关输出(包括分类得分和框坐标)。采用YOLOV2的主干(即DarkNet-19)实现元特征提取器D,并遵循与YOLOV2相同的锚点设置。 对于重权模块M,我们精心设计成一个轻量级的CNN,既提高了效率,又简化了学习。
The meta feature learner
D
D
D 学习如何提取输入查询图像的元特征以检测新类。
Reweighting module
M
M
M 以支持图像为输入,学习将支持信息嵌入到 reweighting vectors 中,并相应地调整查询图像的每个元特征的贡献,以用于后续预测模块
P
P
P。Reweighting module 将激发一些对检测新类有用的元特征,从而辅助检测预测。
I
I
I: an input query image
corresponding meta features
F
=
D
(
I
)
,
F
∈
R
w
×
h
×
m
F=D(I), F ∈ R^{w×h×m}
F=D(I),F∈Rw×h×m, The produced meta feature has m feature maps.
I
i
,
S
i
I_i, S_i
Ii,Si: the support images and their associated bounding box annotation for class
i
i
i
a class-specific representation:
w
i
=
M
(
I
i
,
S
i
)
∈
R
m
w_i =M(I_i,S_i)∈ R^m
wi=M(Ii,Si)∈Rm:
w
i
w_i
wi 负责reweighting元特征,并突出更重要和相关的特征,以从类
i
i
i 中检测目标对象。
更具体地说,在获得class-specific 的reweighting系数
w
i
w_i
wi之后,我们的模型应用它来获得the class-specific feature
F
i
F_i
Fi for
novel class
i
i
i,方法是:
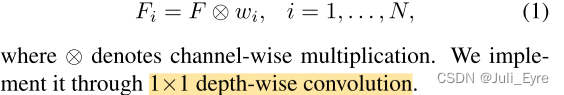
喂入预测模块
P
P
P 得到the objectness score
o
o
o, bounding box location offsets
(
x
,
y
,
h
,
w
)
(x, y, h, w)
(x,y,h,w), and classification score
c
i
c_i
ci for each of a set of predefined anchors
Learning Scheme
从基类中学习一个好的元特征学习器 D D D和重新加权模块 M M M以使它们能够产生可推广的元特征和权重系数是不简单的。 为了保证模型的泛化性能,我们提出了一种新的两阶段学习方案,不同于传统的检测模型训练方案。
第一阶段是base training。 在这一阶段,尽管每个基类都有丰富的标签,但我们仍然联合训练feature learner D D D、预测 P P P和重权值模块 M M M。 这是为了让它们以期望的方式进行协调:模型需要学习 通过参考一个好的reweighting vector来检测感兴趣的对象。 第二阶段是few-shot fine-tuning。 在这个阶段,我们在基类和新类上训练模型。 由于新类只有k个可用,为了平衡基类和新类的样本,我们也为每个基类包含k个 bounding boxs。 训练过程与第一阶段相同,只是模型收敛所需的迭代次数明显减少。
在两个训练阶段中,重新加权系数 depend on 从可用数据中随机采样的输入对(支持图像、bounding box)。 经过少量的微调,我们希望得到一个不需要任何支持输入就可以直接执行检测的检测模型?。 这是通过将目标类的重新加权向量设置为模型预测的平均向量来实现的,然后将K镜头样本作为输入。 在此之后,在推理过程中可以完全移除重新加权模块。 因此,我们的模型在原始探测器上增加了可忽略不计的额外模型参数。
Detection loss function: 为了训练少样本检测模型,我们需要仔细选择损失函数,特别是对于类预测分支,因为样本数很少。 假设预测 is made classwisely,使用二进制交叉熵损失似乎是很自然的,如果对象是目标类,则回归1,否则回归0。 然而,我们发现使用这个损失函数导致 模型容易输出冗余的检测结果(例如,将火车检测为公共汽车和汽车)。 这是由于对于一个特定的感兴趣的区域,N个类别中只有一个是 true positive 的。 然而,二元损失 力求 产生平衡的正负预测。 非最大抑制不能帮助消除这些假阳性,因为它只对每个类内的预测进行操作。
为了解决这个问题,我们提出的模型采用了一个Softmax层来校准分类分数,自适应降低错误类别的检测分数。

其中1(·,i)是当前锚方块是否真的属于I类的指示函数。 引入Softmax后,针对特定锚点的分类得分总和等于1,不太可能的类预测将被抑制。
Reweighting module input: 重新加权模块的输入应该是感兴趣的对象。 然而,在目标检测任务中,一幅图像可能包含来自不同类别的多个目标。 为了让重新加权模块知道目标类是什么,除了三个RGB通道之外,我们还包括一个附加的“掩码”通道(MI),它只有二进制值:在感兴趣对象的边界框内的位置上,值为1,否则为0(参见图2的左下角)。 如果图像上存在多个目标对象,则只使用一个对象。 这个附加的掩码通道使重加权模块知道它应该使用图像的哪一部分信息,以及哪一部分应该被认为是“背景”。 将掩码和图像相结合作为输入,不仅提供了感兴趣对象的类别信息,而且还提供了对检测有用的位置信息(由掩码指示)。 在实验中,我们还研究了其他输入形式。
实验
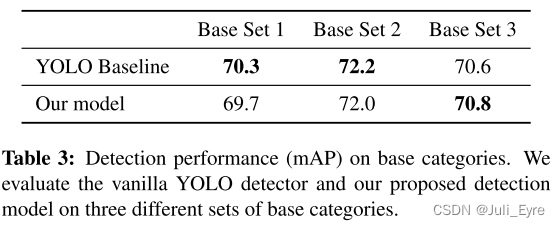
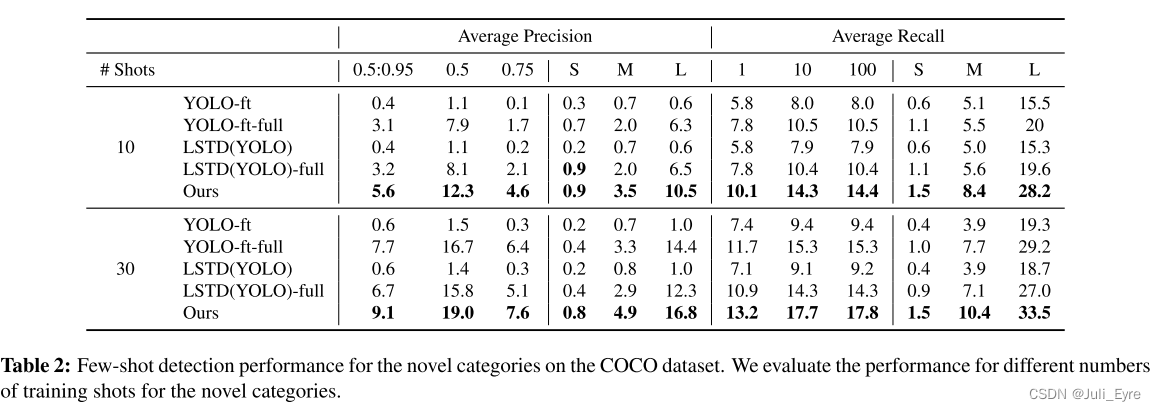
对比方法:第一种方法是在基类和新类的图像上对检测器进行训练。 这样,它就可以从基类中学习到适用于检测新类的良好特征。 我们把这个基线称为 YOLO-joint。 我们用与我们相同的总迭代来训练这个基线模型。 另外两个基于Yolo的基线也使用了我们的两个训练阶段。 特别是,他们用与我们相同的基地训练阶段训练原始Yolov2模型; 对于少量的微调阶段,一个用与我们相同的迭代来微调模型,称为YOLO-ft; 一个训练模型至完全收敛,称为YOLO-ft-full。
最后两个基线来自最近的一种少镜头检测方法,即低镜头转移检测器(LSTD)[4]。 LSTD依靠背景抑制(BD)和转移知识(TK)来获得新类上的少量检测模型。 为了公平比较,我们在YOLOV2的基础上重新实现了BD和TK,对其进行了相同的迭代训练,得到了LSTD(YOLO); 并训练它收敛以获得最后一个基线LSTD(YOLO)-full。
AP
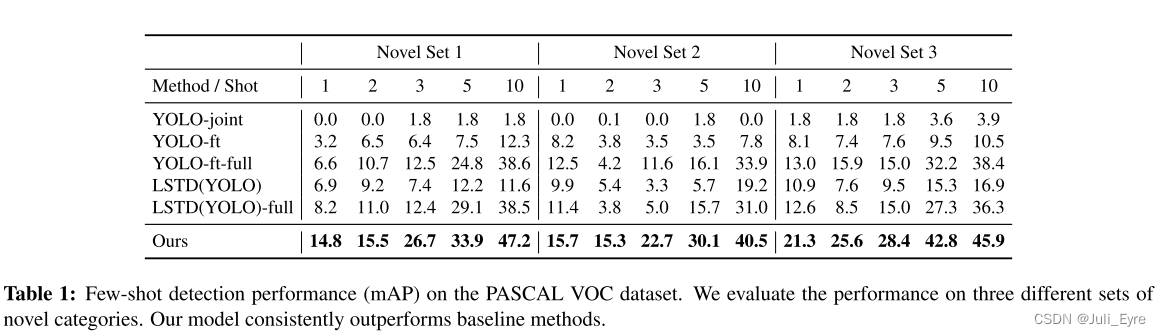
speed
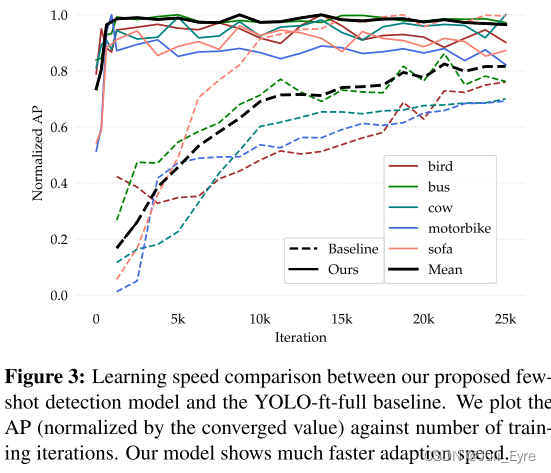
尽管我们的检测器是为少样本场景设计的,但它也具有强大的表示能力,并提供良好的元特征,以达到与原始Yolov2检测器在大量样本上训练的性能相当的性能。 这为解决少样本目标检测问题奠定了基础。