直接看效果对比
tesseract-ocr
该识别引擎最新版本tesseract4添加了支持神经网络(LSTM)的,该引擎专注于线条识别, 同时也保留了Tesseract OCR 引擎,该引擎通过识别字符模式来工作。
我们需求端的后台语言是go,因此我选择了tesseract-ocr/tesseract 的go语言版本------gosseract 来体验识别效果,我是直接下载了web版本来部署:https://github.com/otiai10/ocrserver, 部署后的识别效果如下图。
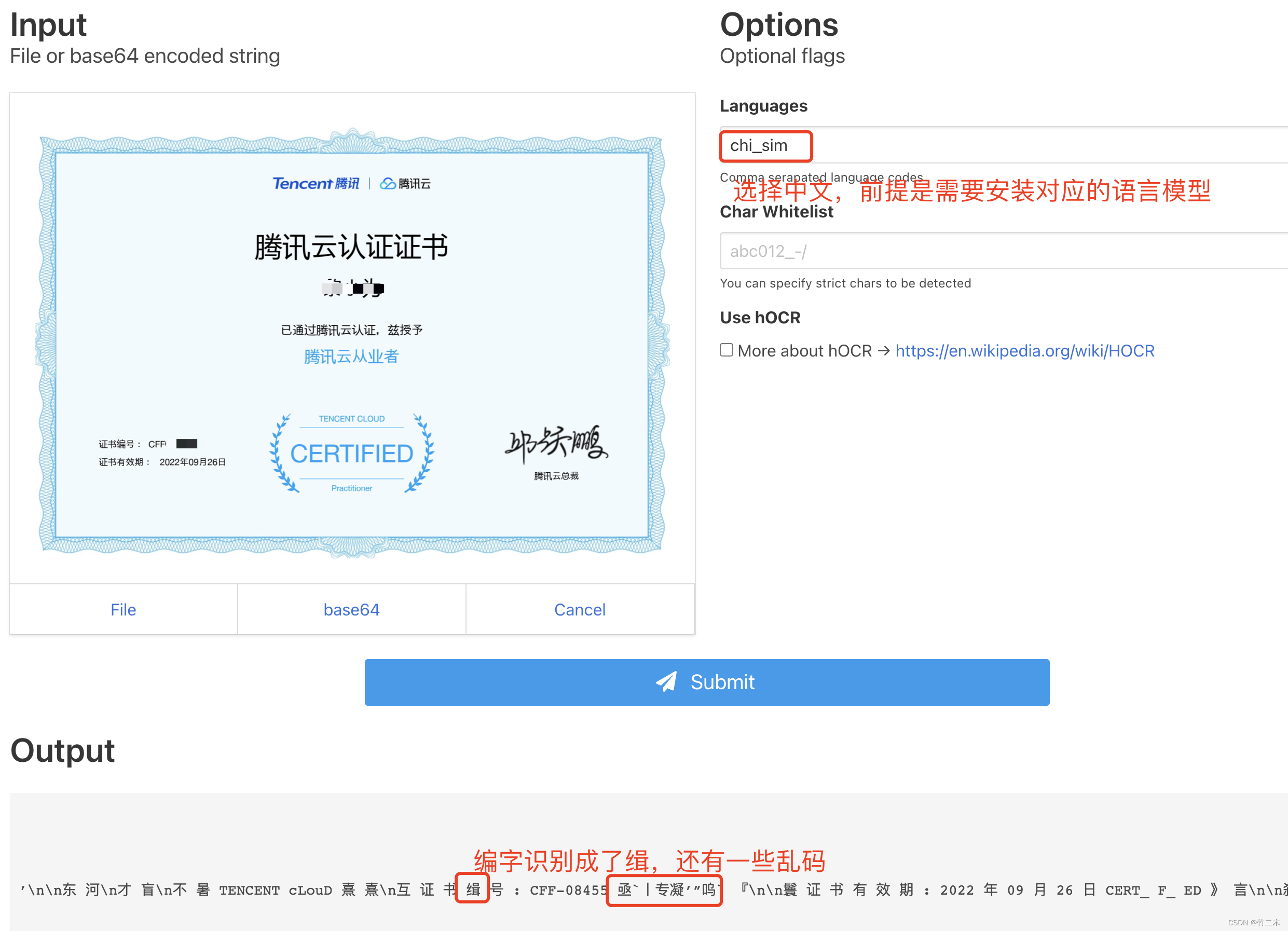
可以看到中文的识别能力一般,很多地方非常方正的中文也识别错了。
注意
- 要能识别中文的话需要安装中文训练模型,下载地址
https://github.com/tesseract-ocr/tessdata
中文语言不支持命令行安装
apt-get install apt-get install -y tesseract-ocr-chi-sim
因此需要手动下载,下载后修改Dockerfile文件,将中文预料模型安装到指定位置
FROM debian:bullseye-slim
LABEL maintainer="otiai10 <otiai10@gmail.com>"
#ARG LOAD_LANG=chi_sim
RUN apt update \
&& apt install -y \
ca-certificates \
libtesseract-dev=4.1.1-2.1 \
tesseract-ocr=4.1.1-2.1 \
golang=2:1.15~1
ENV GO111MODULE=on
ENV GOPATH=${HOME}/go
ENV PATH=${PATH}:${GOPATH}/bin
## 将模型copy到指定的路径下
ENV TESSDATA_PREFIX=/usr/share/tesseract-ocr/4.00/tessdata/
COPY ./tessdata/chi_sim.traineddata ${TESSDATA_PREFIX}chi_sim.traineddata
ADD . $GOPATH/src/github.com/otiai10/ocrserver
WORKDIR $GOPATH/src/github.com/otiai10/ocrserver
RUN go get -v ./... && go install .
# Load languages
RUN if [ -n "${LOAD_LANG}" ]; then apt-get install -y tesseract-ocr-${LOAD_LANG}; fi
ENV PORT=8080
CMD ["ocrserver"]
TrWebOCR
这是一款国内作者开源的专门用于中文识别,clone下来后安装依赖包后就可以直接跑起来了。
我的是centOS 8.x系统,安装python依赖后运行出现了一下错误:
ImportError: libSM.so.6: cannot open shared object file: No such file or directory
缺少依赖包,安装sudo yum install libXext libSM libXrender 后解决,其他系统可以参考,这个回答:
https://stackoverflow.com/questions/47113029/importerror-libsm-so-6-cannot-open-shared-object-file-no-such-file-or-directo
运行后的效果如下图:
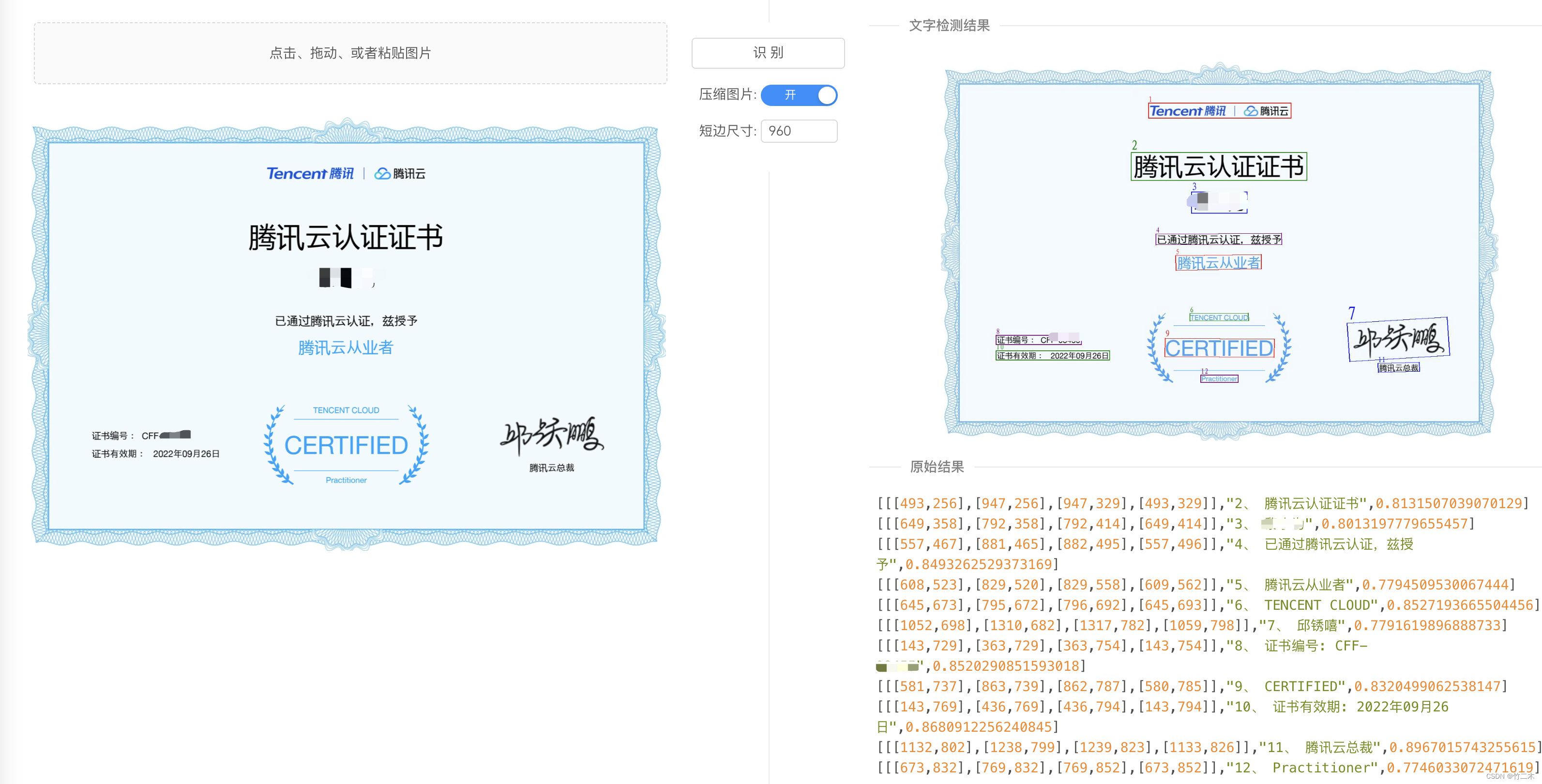
对比之前tesseract-ocr效果有比较明显的进步,特别是中文识别的效果好很多,tesseract-ocr识别错的地方,例如我的名字,还有编字这边都没有问题。
腾讯云OCR识别
体验demo入口:https://cloud.tencent.com/act/event/ocrdemo, 腾讯云OCR识别能力和TrWebOCR比感觉更好点,特别是签名的文字除了姓其他2个字都对了,而TrWebOCR就差别有点大,英文的识别腾讯云的OCR效果也更好些,上面👆的Tencent就识别成了Tencenf, 而腾讯云都是正确的。
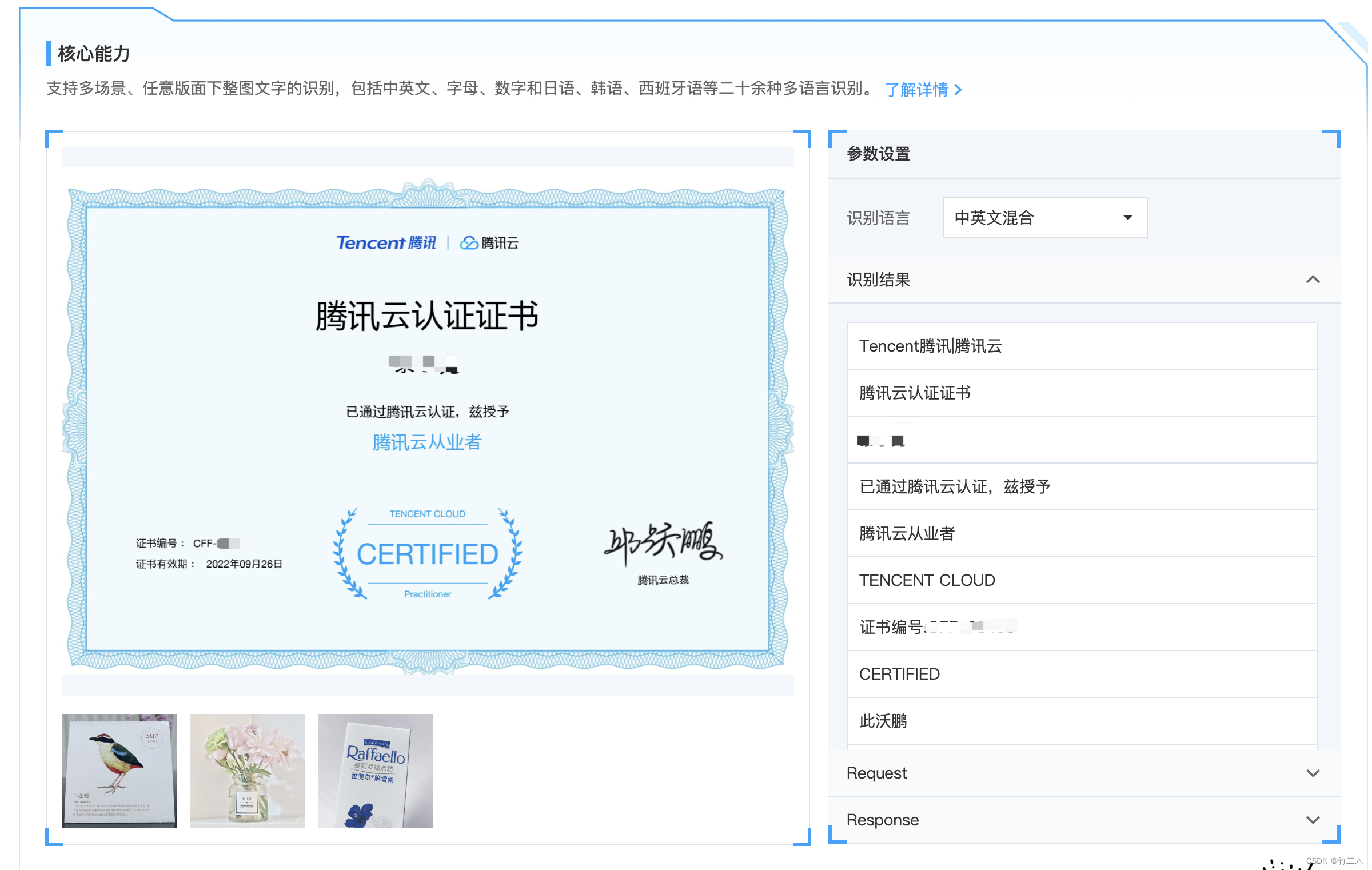
效果总结
- tesseract-ocr 的优点是支持的语言特别多,多达100多种语言支持,缺点是对中文的支持不太友好。
- TrWebOCR 的优点是对中文的识别非常友好,缺点是对英文的识别不太够
- 腾讯云OCR 腾讯云的识别效果中英文都比较好,缺点是要付费,不顾腾讯云也有免费包,小量识别请求可以免费。