呀他温,博主这次真要红温了,中路一个红温兰博请求对线!!!!!!
莫烦老师的强化学习视频不出SAC,我只能去看看别的程序员讲解SAC算法。结果。。。。
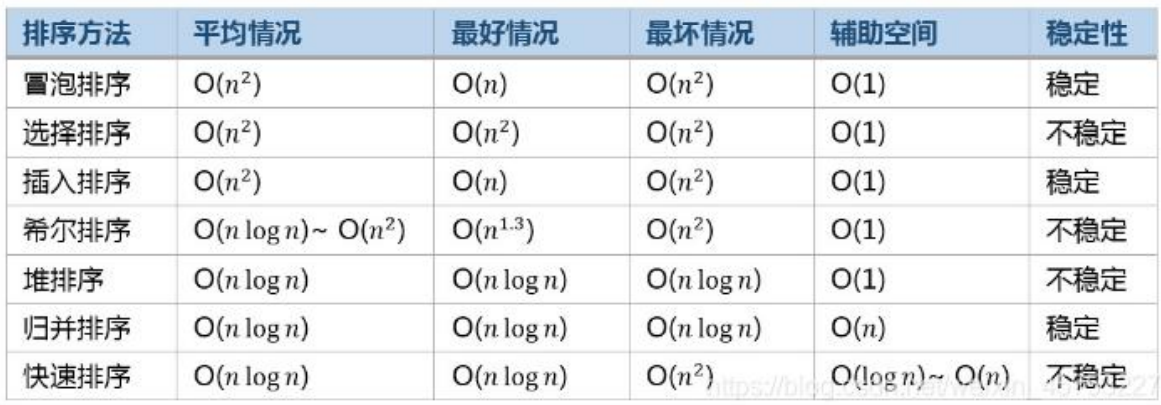
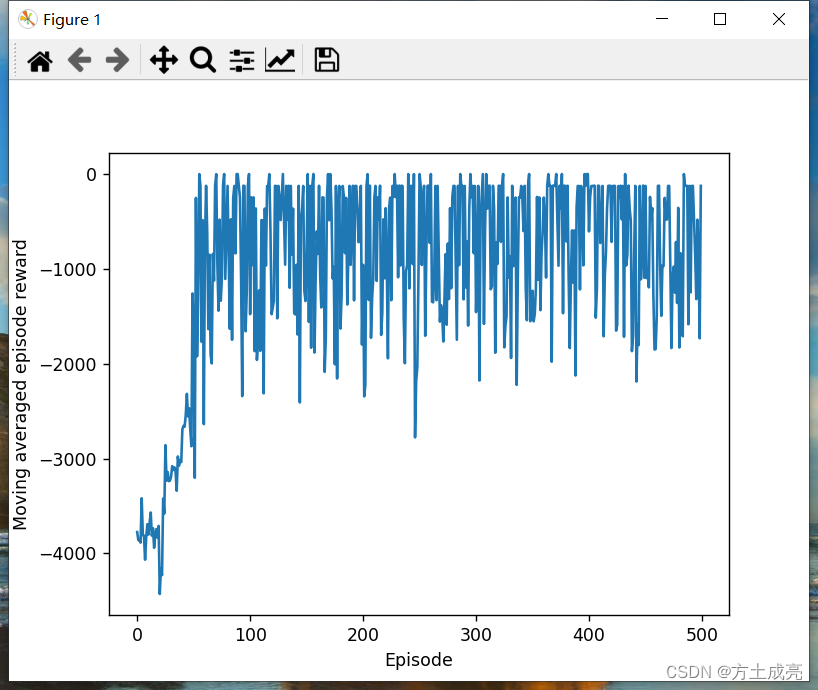
唉,,,别说了,,,,这年头程序员的质量参差不齐,假的SAC代码训练出来的收敛图能有多逆天,请看下图,下图是SAC玩gym的Pendulum-v0游戏环境。SAC训练的效果比DDPG还差,难道写出这SAC代码的作者自己都不觉得奇怪吗?都不怀疑一下为什么这SAC的收敛图比DDPG还要差吗?Pendulum游戏环境总奖励一会-100.1的,一会-2124.5的,跳变的这么厉害,意识不到不对劲吗?
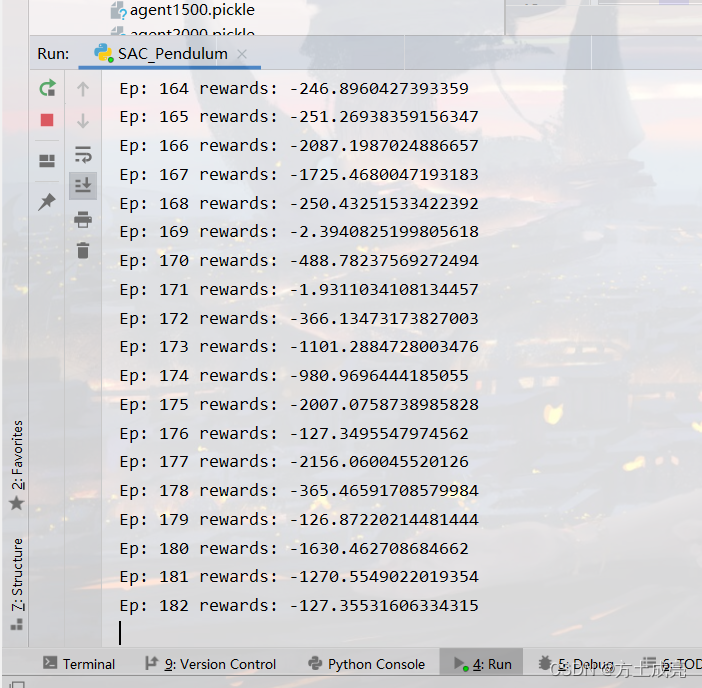
假SAC:
假SAC的代码是我参考这个github代码改来的,假SAC代码如下,我应该没改错吧。。
# -*- coding: utf-8 -*-
#开发者:Bright Fang
#开发时间:2023/2/14 20:10
import torch
import torch.nn as nn
import torch.nn.functional as F
# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
import numpy as np
import gym
from matplotlib import pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
env = gym.make("Pendulum-v0").unwrapped
'''Pendulum环境状态特征是三个,杆子的sin(角度)、cos(角度)、角速度,(状态是无限多个,因为连续),动作值是力矩,限定在[-2,2]之间的任意的小数,所以是连续的(动作也是无限个)'''
state_number=env.observation_space.shape[0]
action_number=env.action_space.shape[0]
max_action = env.action_space.high[0]
min_action = env.action_space.low[0]
RENDER=False
EP_MAX = 500
EP_LEN = 500
GAMMA = 0.9
q_lr = 2e-3
value_lr = 3e-3
policy_lr = 1e-3
BATCH = 128
tau = 1e-2
MemoryCapacity=10000
Switch=0
class ActorNet(nn.Module):
def __init__(self,inp,outp):
super(ActorNet, self).__init__()
self.in_to_y1=nn.Linear(inp,256)
self.in_to_y1.weight.data.normal_(0,0.1)
self.y1_to_y2=nn.Linear(256,256)
self.y1_to_y2.weight.data.normal_(0,0.1)
self.out=nn.Linear(256,outp)
self.out.weight.data.normal_(0,0.1)
self.std_out = nn.Linear(256, outp)
self.std_out.weight.data.normal_(0, 0.1)
def forward(self,inputstate):
inputstate=self.in_to_y1(inputstate)
inputstate=F.relu(inputstate)
inputstate=self.y1_to_y2(inputstate)
inputstate=F.relu(inputstate)
mean=max_action*torch.tanh(self.out(inputstate))#输出概率分布的均值mean
log_std=self.std_out(inputstate)#softplus激活函数的值域>0
log_std=torch.clamp(log_std,-20,2)
std=log_std.exp()
return mean,std
class CriticNet(nn.Module):
def __init__(self,input):
super(CriticNet, self).__init__()
self.in_to_y1=nn.Linear(input,256)
self.in_to_y1.weight.data.normal_(0,0.1)
self.y1_to_y2=nn.Linear(256,256)
self.y1_to_y2.weight.data.normal_(0,0.1)
self.out=nn.Linear(256,1)
self.out.weight.data.normal_(0,0.1)
def forward(self,inputstate):
v=self.in_to_y1(inputstate)
v=F.relu(v)
v=self.y1_to_y2(v)
v=F.relu(v)
v=self.out(v)
return v
class QNet(nn.Module):
def __init__(self,input,output):
super(QNet, self).__init__()
self.in_to_y1=nn.Linear(input+output,256)
self.in_to_y1.weight.data.normal_(0,0.1)
self.y1_to_y2=nn.Linear(256,256)
self.y1_to_y2.weight.data.normal_(0,0.1)
self.out=nn.Linear(256,output)
self.out.weight.data.normal_(0,0.1)
def forward(self,s,a):
inputstate = torch.cat((s, a), dim=1)
q1=self.in_to_y1(inputstate)
q1=F.relu(q1)
q1=self.y1_to_y2(q1)
q1=F.relu(q1)
q1=self.out(q1)
return q1
class Memory():
def __init__(self,capacity,dims):
self.capacity=capacity
self.mem=np.zeros((capacity,dims))
self.memory_counter=0
'''存储记忆'''
def store_transition(self,s,a,r,s_):
tran = np.hstack((s, [a.squeeze(0),r], s_)) # 把s,a,r,s_困在一起,水平拼接
index = self.memory_counter % self.capacity#除余得索引
self.mem[index, :] = tran # 给索引存值,第index行所有列都为其中一次的s,a,r,s_;mem会是一个capacity行,(s+a+r+s_)列的数组
self.memory_counter+=1
'''随机从记忆库里抽取'''
def sample(self,n):
assert self.memory_counter>=self.capacity,'记忆库没有存满记忆'
sample_index = np.random.choice(self.capacity, n)#从capacity个记忆里随机抽取n个为一批,可得到抽样后的索引号
new_mem = self.mem[sample_index, :]#由抽样得到的索引号在所有的capacity个记忆中 得到记忆s,a,r,s_
return new_mem
class Actor():
def __init__(self):
self.action_net=ActorNet(state_number,action_number)#这只是均值mean
self.optimizer=torch.optim.Adam(self.action_net.parameters(),lr=policy_lr)
def choose_action(self,s):
inputstate = torch.FloatTensor(s)
mean,std=self.action_net(inputstate)
dist = torch.distributions.Normal(mean, std)
action=dist.sample()
action=torch.clamp(action,min_action,max_action)
return action.detach().numpy()
def evaluate(self,s):
inputstate = torch.FloatTensor(s)
mean,std=self.action_net(inputstate)
dist = torch.distributions.Normal(mean, std)
noise = torch.distributions.Normal(0, 1)
z = noise.sample()
action=torch.tanh(mean+std*z)
action=torch.clamp(action,min_action,max_action)
action_logprob=dist.log_prob(mean+std*z)-torch.log(1-action.pow(2)+1e-6)
return action,action_logprob,z,mean,std
def learn(self,actor_loss):
loss=actor_loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
class Critic():
def __init__(self):
self.critic_v,self.target_critic_v=CriticNet(state_number),CriticNet(state_number)#改网络输入状态,生成一个Q值
self.optimizer = torch.optim.Adam(self.critic_v.parameters(), lr=value_lr,eps=1e-5)
self.lossfunc = nn.MSELoss()
def soft_update(self):
for target_param, param in zip(self.target_critic_v.parameters(), self.critic_v.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
def get_v(self,s):
return self.critic_v(s)
def learn(self,expected_v,next_v):
loss=self.lossfunc(expected_v,next_v.detach())
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
class Q_Critic():
def __init__(self):
self.q1_net=QNet(state_number,action_number)#改网络输入状态,生成一个Q值
self.q1_optimizer = torch.optim.Adam(self.q1_net.parameters(), lr=q_lr,eps=1e-5)
self.lossfunc = nn.MSELoss()
def get_q(self,s,a):
return self.q1_net(s,a)
def learn(self,br,expected_q,target_v):
next_q = br + GAMMA * target_v
loss=self.lossfunc(expected_q,next_q.detach())
self.q1_optimizer.zero_grad()
loss.backward()
self.q1_optimizer.step()
if Switch==0:
print('SAC训练中...')
actor = Actor()
critic = Critic()
q_critic=Q_Critic()
M = Memory(MemoryCapacity, 2 * state_number + action_number + 1)
all_ep_r = []
for episode in range(EP_MAX):
observation = env.reset() # 环境重置
reward_totle = 0
for timestep in range(EP_LEN):
if RENDER:
env.render()
action = actor.choose_action(observation)
observation_, reward, done, info = env.step(action) # 单步交互
M.store_transition(observation, action, reward, observation_)
# 记忆库存储
# 有的2000个存储数据就开始学习
if M.memory_counter > MemoryCapacity:
b_M = M.sample(BATCH)
b_s = b_M[:, :state_number]
b_a = b_M[:, state_number: state_number + action_number]
b_r = b_M[:, -state_number - 1: -state_number]
b_s_ = b_M[:, -state_number:]
b_s = torch.FloatTensor(b_s)
b_a = torch.FloatTensor(b_a)
b_r = torch.FloatTensor(b_r)
b_s_ = torch.FloatTensor(b_s_)
expected_q=q_critic.get_q(b_s,b_a)
expected_v=critic.get_v(b_s)
new_action, log_prob, z, mean, log_std = actor.evaluate(b_s)
target_v=critic.target_critic_v(b_s_)
q_critic.learn(b_r,expected_q,target_v)
expected_new_q=q_critic.get_q(b_s,new_action)
next_v=expected_new_q-log_prob
critic.learn(expected_v,next_v)
log_prob_target=expected_new_q-expected_v
actor_loss=(log_prob*(log_prob-log_prob_target).detach()).mean()
mean_loss=1e-3*mean.pow(2).mean()
std_loss=1e-3*log_std.pow(2).mean()
actor_loss+=mean_loss+std_loss
actor.learn(actor_loss)
# 软更新
critic.soft_update()
observation = observation_
reward_totle += reward
print("Ep: {} rewards: {}".format(episode, reward_totle))
# if reward_totle > -10: RENDER = True
all_ep_r.append(reward_totle)
if episode % 20 == 0 and episode > 200:#保存神经网络参数
save_data = {'net': actor.action_net.state_dict(), 'opt': actor.optimizer.state_dict(), 'i': episode}
torch.save(save_data, "E:\model_SAC.pth")
env.close()
plt.plot(np.arange(len(all_ep_r)), all_ep_r)
plt.xlabel('Episode')
plt.ylabel('Moving averaged episode reward')
plt.show()
else:
print('SAC测试中...')
aa=Actor()
checkpoint_aa = torch.load("E:\model_SAC.pth")
aa.action_net.load_state_dict(checkpoint_aa['net'])
for j in range(10):
state = env.reset()
total_rewards = 0
for timestep in range(EP_LEN):
env.render()
action = aa.choose_action(state)
new_state, reward, done, info = env.step(action) # 执行动作
total_rewards += reward
state = new_state
print("Score:", total_rewards)
env.close()
所以,这里给出一份经典且标准的SAC代码,用的是pytorch框架,玩的是gym的Pendulum-v0游戏环境,是我翻了一下午从github的这份代码改来的。它的收敛效果图如下:
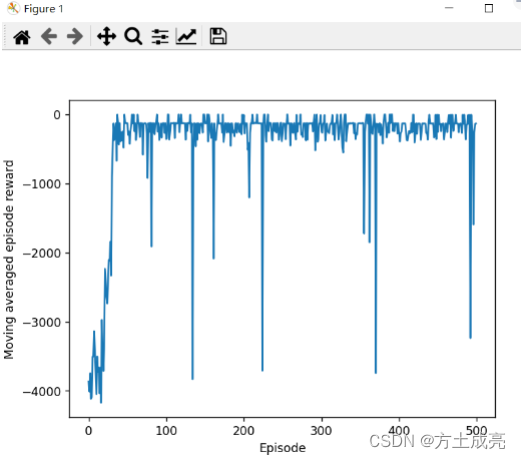
多么漂亮的收敛图啊,这才是我SAC算法应有的实力嘛!!!!不愧是被大家伙吹上天的好算法啊,SAC的能力确实猛!!
至此,代码如下,拿走不谢,复制即用,不行砍我!
# -*- coding: utf-8 -*-
#开发者:Bright Fang
#开发时间:2023/2/14 20:10
import torch
import torch.nn as nn
import torch.nn.functional as F
# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
import numpy as np
import gym
from matplotlib import pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
env = gym.make("Pendulum-v0").unwrapped
'''Pendulum环境状态特征是三个,杆子的sin(角度)、cos(角度)、角速度,(状态是无限多个,因为连续),动作值是力矩,限定在[-2,2]之间的任意的小数,所以是连续的(动作也是无限个)'''
state_number=env.observation_space.shape[0]
action_number=env.action_space.shape[0]
max_action = env.action_space.high[0]
min_action = env.action_space.low[0]
RENDER=False
EP_MAX = 500
EP_LEN = 500
GAMMA = 0.9
q_lr = 3e-4
value_lr = 3e-3
policy_lr = 1e-3
BATCH = 128
tau = 1e-2
MemoryCapacity=10000
Switch=0
class ActorNet(nn.Module):
def __init__(self,inp,outp):
super(ActorNet, self).__init__()
self.in_to_y1=nn.Linear(inp,256)
self.in_to_y1.weight.data.normal_(0,0.1)
self.y1_to_y2=nn.Linear(256,256)
self.y1_to_y2.weight.data.normal_(0,0.1)
self.out=nn.Linear(256,outp)
self.out.weight.data.normal_(0,0.1)
self.std_out = nn.Linear(256, outp)
self.std_out.weight.data.normal_(0, 0.1)
def forward(self,inputstate):
inputstate=self.in_to_y1(inputstate)
inputstate=F.relu(inputstate)
inputstate=self.y1_to_y2(inputstate)
inputstate=F.relu(inputstate)
mean=max_action*torch.tanh(self.out(inputstate))#输出概率分布的均值mean
log_std=self.std_out(inputstate)#softplus激活函数的值域>0
log_std=torch.clamp(log_std,-20,2)
std=log_std.exp()
return mean,std
class CriticNet(nn.Module):
def __init__(self,input,output):
super(CriticNet, self).__init__()
#q1
self.in_to_y1=nn.Linear(input+output,256)
self.in_to_y1.weight.data.normal_(0,0.1)
self.y1_to_y2=nn.Linear(256,256)
self.y1_to_y2.weight.data.normal_(0,0.1)
self.out=nn.Linear(256,1)
self.out.weight.data.normal_(0,0.1)
#q2
self.q2_in_to_y1 = nn.Linear(input+output, 256)
self.q2_in_to_y1.weight.data.normal_(0, 0.1)
self.q2_y1_to_y2 = nn.Linear(256, 256)
self.q2_y1_to_y2.weight.data.normal_(0, 0.1)
self.q2_out = nn.Linear(256, 1)
self.q2_out.weight.data.normal_(0, 0.1)
def forward(self,s,a):
inputstate = torch.cat((s, a), dim=1)
#q1
q1=self.in_to_y1(inputstate)
q1=F.relu(q1)
q1=self.y1_to_y2(q1)
q1=F.relu(q1)
q1=self.out(q1)
#q2
q2 = self.in_to_y1(inputstate)
q2 = F.relu(q2)
q2 = self.y1_to_y2(q2)
q2 = F.relu(q2)
q2 = self.out(q2)
return q1,q2
class Memory():
def __init__(self,capacity,dims):
self.capacity=capacity
self.mem=np.zeros((capacity,dims))
self.memory_counter=0
'''存储记忆'''
def store_transition(self,s,a,r,s_):
tran = np.hstack((s, [a.squeeze(0),r], s_)) # 把s,a,r,s_困在一起,水平拼接
index = self.memory_counter % self.capacity#除余得索引
self.mem[index, :] = tran # 给索引存值,第index行所有列都为其中一次的s,a,r,s_;mem会是一个capacity行,(s+a+r+s_)列的数组
self.memory_counter+=1
'''随机从记忆库里抽取'''
def sample(self,n):
assert self.memory_counter>=self.capacity,'记忆库没有存满记忆'
sample_index = np.random.choice(self.capacity, n)#从capacity个记忆里随机抽取n个为一批,可得到抽样后的索引号
new_mem = self.mem[sample_index, :]#由抽样得到的索引号在所有的capacity个记忆中 得到记忆s,a,r,s_
return new_mem
class Actor():
def __init__(self):
self.action_net=ActorNet(state_number,action_number)#这只是均值mean
self.optimizer=torch.optim.Adam(self.action_net.parameters(),lr=policy_lr)
def choose_action(self,s):
inputstate = torch.FloatTensor(s)
mean,std=self.action_net(inputstate)
dist = torch.distributions.Normal(mean, std)
action=dist.sample()
action=torch.clamp(action,min_action,max_action)
return action.detach().numpy()
def evaluate(self,s):
inputstate = torch.FloatTensor(s)
mean,std=self.action_net(inputstate)
dist = torch.distributions.Normal(mean, std)
noise = torch.distributions.Normal(0, 1)
z = noise.sample()
action=torch.tanh(mean+std*z)
action=torch.clamp(action,min_action,max_action)
action_logprob=dist.log_prob(mean+std*z)-torch.log(1-action.pow(2)+1e-6)
return action,action_logprob,z,mean,std
def learn(self,actor_loss):
loss=actor_loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
class Entroy():
def __init__(self):
self.target_entropy = -action_number
self.log_alpha = torch.zeros(1, requires_grad=True)
self.alpha = self.log_alpha.exp()
self.optimizer = torch.optim.Adam([self.log_alpha], lr=q_lr)
def learn(self,entroy_loss):
loss=entroy_loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
class Critic():
def __init__(self):
self.critic_v,self.target_critic_v=CriticNet(state_number,action_number),CriticNet(state_number,action_number)#改网络输入状态,生成一个Q值
self.optimizer = torch.optim.Adam(self.critic_v.parameters(), lr=value_lr,eps=1e-5)
self.lossfunc = nn.MSELoss()
def soft_update(self):
for target_param, param in zip(self.target_critic_v.parameters(), self.critic_v.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
def get_v(self,s,a):
return self.critic_v(s,a)
def learn(self,current_q1,current_q2,target_q):
loss = self.lossfunc(current_q1, target_q) + self.lossfunc(current_q2, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if Switch==0:
print('SAC训练中...')
actor = Actor()
critic = Critic()
entroy=Entroy()
M = Memory(MemoryCapacity, 2 * state_number + action_number + 1)
all_ep_r = []
for episode in range(EP_MAX):
observation = env.reset() # 环境重置
reward_totle = 0
for timestep in range(EP_LEN):
if RENDER:
env.render()
action = actor.choose_action(observation)
observation_, reward, done, info = env.step(action) # 单步交互
M.store_transition(observation, action, reward, observation_)
# 记忆库存储
# 有的2000个存储数据就开始学习
if M.memory_counter > MemoryCapacity:
b_M = M.sample(BATCH)
b_s = b_M[:, :state_number]
b_a = b_M[:, state_number: state_number + action_number]
b_r = b_M[:, -state_number - 1: -state_number]
b_s_ = b_M[:, -state_number:]
b_s = torch.FloatTensor(b_s)
b_a = torch.FloatTensor(b_a)
b_r = torch.FloatTensor(b_r)
b_s_ = torch.FloatTensor(b_s_)
new_action, log_prob_, z, mean, log_std = actor.evaluate(b_s_)
target_q1,target_q2=critic.get_v(b_s_,new_action)
target_q=b_r+GAMMA*(torch.min(target_q1,target_q2)-entroy.alpha*log_prob_)
current_q1, current_q2 = critic.get_v(b_s, b_a)
critic.learn(current_q1,current_q2,target_q.detach())
a,log_prob,_,_,_=actor.evaluate(b_s)
q1,q2=critic.get_v(b_s,a)
q=torch.min(q1,q2)
actor_loss = (entroy.alpha * log_prob - q).mean()
actor.learn(actor_loss)
alpha_loss = -(entroy.log_alpha.exp() * (log_prob + entroy.target_entropy).detach()).mean()
entroy.learn(alpha_loss)
entroy.alpha=entroy.log_alpha.exp()
# 软更新
critic.soft_update()
observation = observation_
reward_totle += reward
print("Ep: {} rewards: {}".format(episode, reward_totle))
# if reward_totle > -10: RENDER = True
all_ep_r.append(reward_totle)
if episode % 20 == 0 and episode > 200:#保存神经网络参数
save_data = {'net': actor.action_net.state_dict(), 'opt': actor.optimizer.state_dict(), 'i': episode}
torch.save(save_data, "E:\model_SAC.pth")
env.close()
plt.plot(np.arange(len(all_ep_r)), all_ep_r)
plt.xlabel('Episode')
plt.ylabel('Moving averaged episode reward')
plt.show()
else:
print('SAC测试中...')
aa=Actor()
checkpoint_aa = torch.load("E:\model_SAC.pth")
aa.action_net.load_state_dict(checkpoint_aa['net'])
for j in range(10):
state = env.reset()
total_rewards = 0
for timestep in range(EP_LEN):
env.render()
action = aa.choose_action(state)
new_state, reward, done, info = env.step(action) # 执行动作
total_rewards += reward
state = new_state
print("Score:", total_rewards)
env.close()
代码用法:
先把Switch标志位赋为0,先训练,等待训练结束后画出图形。然后,把Switch标志为赋为1进行测试,就可以看到训练的效果了。神经网络的参数被我们保存在了路径:E盘里。所以,别告诉我,你的电脑没有E盘,没有就自己改路径。
remark:
1.神经网络的参数被保存在了电脑E盘里,别告诉我你的电脑没有E盘。没有自己改代码。
2.我感觉版本信息不重要,但还是给一下以供参考。我用的gym版本:0.19.0;我用的pytorch版本:1.10.0+cu113;python版本:3.8