原文链接:https://blog.csdn.net/AnameJL/article/details/124362219,再次主要是为了方便查找,把原文章复制一遍
目录
1. 三者的使用
1.1 cache的讲解与使用
1.2 persist的讲解与使用
1.3checkpoint 的讲解与使用
2. 三者的比较
2.1 优缺点
2.2 使用场景
3.释放内存
在Spark的数据处理过程中我们可以通过cache、persist、checkpoint这三个算子将中间的结果数据进行保存,这里主要就是介绍这三个算子的使用方式和使用场景
1. 三者的使用
1.1 cache的讲解与使用
cache算子可以将spark任务的中间结果数据缓存到内存当中,用以优化数据处理的时效性,这里结合代码进行讲解。
首先这里准备好数据文件
# 通过命令我们可以看到数据文件有4592639 行
[root@lx01 bin]# wc -l /root/log-t.txt
4592639 /root/log-t.txt
# 将数据文件上传至hdfs,并对文件重命名
[root@lx01 ~]# hdfs dfs -put /root/log-t.txt /log/log01
[root@lx01 ~]# hdfs dfs -put /root/log-t.txt /log/log02
[root@lx01 ~]# hdfs dfs -put /root/log-t.txt /log/log03
[root@lx01 ~]# hdfs dfs -put /root/log-t.txt /log/log04
[root@lx01 ~]# hdfs dfs -put /root/log-t.txt /log/log05
[root@lx01 ~]# hdfs dfs -put /root/log-t.txt /log/log06
[root@lx01 ~]# hdfs dfs -put /root/log-t.txt /log/log07

这里可以看到文件的大小是65.7MB
# 这里为了方便直接启动spark-shell对数据进行处理
[root@lx01 bin]# ./spark-shell --master spark://lx01:7077 --executor-memory 4G --total-executor-cores 2
进入spark-shell后,我们对文件简单的做一个行数统计,然后看一下耗时时间
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_231)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val lines = sc.textFile("hdfs://lx01:8020/log")
lines: org.apache.spark.rdd.RDD[String] = hdfs://lx01:8020/log MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.count
res0: Long = 32148480
scala> lines.count
res1: Long = 32148480
scala> lines.count
res2: Long = 32148480
scala> lines.count
res3: Long = 32148480
统计完可以看到是32148480,这里我们看一下时间

通过上图我们可以看到查询这里数据总耗时最快可达到2s,这里我们开始使用cache算子,将数据缓存到内存当中,然后再查询数据的总行数,这里要注意cache算子并非action算子,所以要执行一次action算子cache算子才会生效。
# 这里我们还是使用的action算子还是count
scala> lines.cache
res4: lines.type = hdfs://lx01:8020/log MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.count
res5: Long = 32148480
我们先砍一下将数据存储到内存中,然后在使用count算子计算总行数的耗时时长

通过上图我们可以看到,这次使用cache算子后,比未使用cache算子的耗时时长还要多5s,这是因为我们在执行count时不仅要从hdfs中读取数据计算行数,还要将数据存储到内存中,所以时间更长,下面我们在直接执行一次count并看一下耗时时长
scala> lines.count
res3: Long = 18370560

通过上图我们可以看到,数据存储到内存中后我们再直接使用count时,计算速度提高了几十倍,从这里也说明了一个问题,只有中间结果的数据被重复利用的时候,我们使用cache算子才有意义,如果整个spark程序对同一数据只执行一次action算子,我们将数据存储到内存中不仅没有任何意义,还会降低数据处理的时效性,并且浪费资源,这里为什么说浪费资源,因为cache算子是将数据以java对象的形式存储,作为开发人员我们都清楚以java对象进行存储的方式是很重的,这里我读取的文件每个都是65.7MB,一共读取了7个,我们看一下数据存储到内存中后的大小
通过上图我们可以看到,459.9MB的数据存储到内存中后就变成了2.3GB,从这里就可以看出,cache算子对内存的开销是极大的,如果不对脏数据进行处理,或者进行一些数据筛选,直接将数据存储到内存中,是很浪费资源的,再就是上面提到的,只有一次action不要使用cache算子,其实persist也是一样的。
注意:cache把数据缓存到内存,其实是缓存到每个executor的内存中,cache是以分区为单位进行缓存的,要么整个分区全部被缓存到内存,要么整个分区数据都不被缓存,不会发生缓存某个分区的一部分数据的情况。
1.2 persist的讲解与使用
persist算子相对于cache算子要更加的灵活,persist可以配置中间结果数据存储级别,存储数据的副本数据量等。而且通过翻看源码我们可以看到cache算子底层调用的就是persist算子
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
通过上面的源码我们可以看到cache算子使用的就是persist算子的MEMORY_ONLY,这里我们官网看一下persist的存储级别都有哪些

通过上图我们可以看到persist的存储级别是很丰富的,这里我们可以根据具体的需求选择对应的存储级别。
注意:persist把数据缓存到内存,其实是缓存到每个executor的内存中,内存存储不下,就存储在磁盘,磁盘就是executor所在的机器的磁盘上,不是hdfs
这里我们重新开启一个spark-shell,用以测试persist算子
[root@lx01 bin]# ./spark-shell --master spark://lx01:7077 --executor-memory 4G --total-executor-cores 2
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_231)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
这里我们先测试persist的DISK_ONLY的效率,还是以相同的文件
# 这里还是先测试直接做count的时效
scala> val lines = sc.textFile("hdfs://lx01:8020/log")
lines: org.apache.spark.rdd.RDD[String] = hdfs://lx01:8020/log MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.count
res0: Long = 32148480
scala> lines.count
res1: Long = 32148480
scala> lines.count
res2: Long = 32148480
scala> lines.count
res3: Long = 32148480

可以看到最高时效还是2s
这里我们再将数据以DISK_ONLY的方式进行存储
# 因为这里使用的是spark-shell,我们要先进行导包
scala> import org.apache.spark.storage.StorageLevel
import org.apache.spark.storage.StorageLevel
scala> lines.persist(StorageLevel.DISK_ONLY)
res4: lines.type = hdfs://lx01:8020/log MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.count
res5: Long = 32148480

通过上图我们可以看到,使用persist算子的DISK_ONLY存储耗时为6s,和使用cache算子时的原理是相同的,不仅要从hdfs读取数据做count计算,还要将数据存储到本地磁盘,但是我们可以看到,将数据存储到本地磁盘比存储到内存的总耗时小,我们在使用cache的时候耗时7s,使用persist的DISK_ONLY存储耗时6s,造成这样的原因就是存储到本地磁盘的数据是从hdfs读取的原始数据文件,而存储到内存中的数据是以java对象的形式存储,多了很多附加信息,如下图
每个文件为65.7MB,7个文件正好是459.9MB
这里我们再测试一下,存储到磁盘后的数据计算时效性
scala> lines.count
res3: Long = 18370560

通过上图可以看到,将数据存储到本地磁盘后,在做count计算用时1s,相对于直接做count的计算速度还是翻倍的,但是相对于存储到内存中还是慢了不少,比直接做count快是因为做计算时是从本地磁盘读取的数据,而不从hdfs上读取的数据,而且数据量越大,时效性的差距越明显.
使用本地磁盘的存储方式和内存存储相比,虽然时效性下降,但是可利用的存储资源更多,而且比内存存储更节约资源.
这里我们在测试一下内存和磁盘并用,重复的代码这里就省略了
scala> lines.persist(StorageLevel.MEMORY_AND_DISK)
res0: lines.type = hdfs://lx01:8020/log MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.count
res1: Long = 32148480

这里可以看到将数据做count计算的同时,并将数据存储到内存和本地磁盘中总耗时19s
这里我们在直接执行一次count计算,看一下耗时
scala> lines.count
res2: Long = 32148480

可以看到总耗时为0.1s,和直接将数据存储到内存后再进行计算的速度是相同的,这是因为我们将数据同时存储到内存和本地磁盘中后,再重复利用这些数据时,会优先读取内存中的数据.当内存中的数据丢失时才会读取本地磁盘中存储的数据.
1.3checkpoint 的讲解与使用
checkpoint算子同样是将中间结果数据进行存储,不过它是将数据存储到高可靠,高可用的文件系统HDFS,相对于cache和persist是更加安全的.
# 使用checkpoint的时候注意,一定要先设置checkpoint在hdfs存储数据的路径
scala> sc.setCheckpointDir("hdfs://lx01:8020/check")
scala> val lines = sc.textFile("hdfs://lx01:8020/log")
lines: org.apache.spark.rdd.RDD[String] = hdfs://lx01:8020/log MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.checkpoint
scala> lines.count
res2: Long = 32148480
这里我们先看一下已经配置好的checkpoint的HDFS路径是否有数据
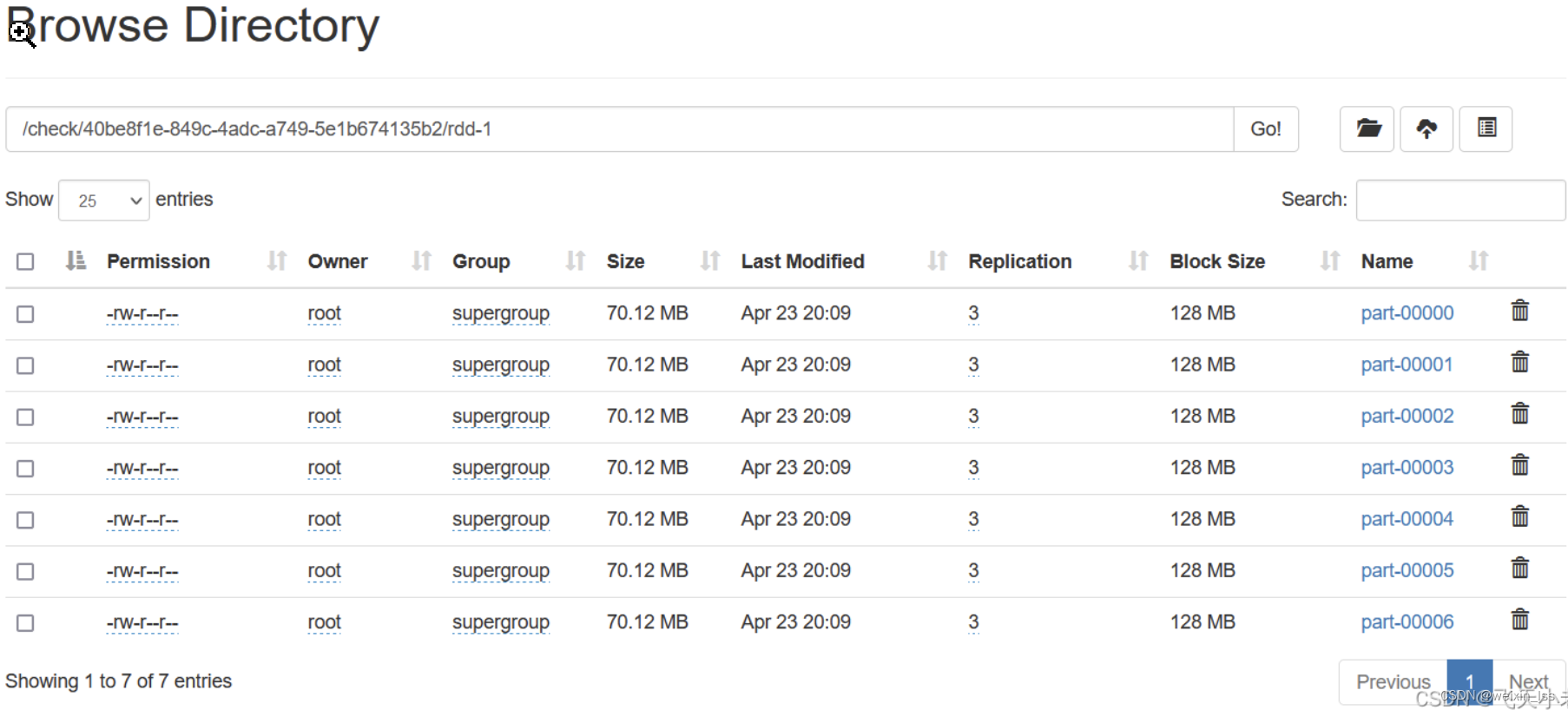
用过上图可以看到在check路径下已经有了7个数据块

这里执行了6s,比直接执行count算子要多出4s,就是因为我们在计算数据的同时也在将数据存储到HDFS上.
2. 三者的比较
2.1 优缺点
cache
优点: 对相同的数据进行处理是,时效性最高,可以大大提高spark程序的时效性能
缺点: 很耗费内存资源,如果数据量较大并不适用cache
persist
优点: 可以进行灵活的配置,如果内存不够大,可以将中间结果数据存储到本地磁盘,同cache相比时效性降低,但是同样比直接从hdfs读取数据做计算要高出几倍的效率,而且如果将数据存储到本地磁盘相对于只将数据存储到内存中要更加安全
缺点: 虽然persist可以将数据存储到内存或者磁盘,但是对单节点的磁盘和内存资源存在一定的限制性
checkpoint
优点: 将中间结果数据存储到HDFS中能更加能确保中间结果数据的安全性
缺点: 重复利用中间结果数据时,还是和HDFS进行交互,时效性相对于内存存储和本地磁盘存储较低
2.2 使用场景
cache
当中间结果数据的数据量较小,并且要求的时效性较高时比较适合使用cache算子
persist
当单一的内存存储无法满足业务需求时,或者中间结果数据给内存造成很大压力时,可以使用persist算子
checkpoint
当中间结果数据极其宝贵,对数据的安全要求较高时,比如使用机器学习可能程序执行几天才的到的模型数据,这一类数据的安全性能要求相对较高,就比较适用于checkpoint算子.
以上就是对cache,persist,checkpoint的介绍,这三者有一个共同点,就是数据的重复利用,如果对相同的中间结果数据只执行一次action算子是没有必要使用这三个算子的,读取中间结果数据的优先级:内存<–磁盘<–hdfs,对于这三者的介绍就结束了,相对来说比较齐浅显,希望对有疑问的朋友有所帮助.
3.释放内存
rdd.unpersist(true) ,即释放内存的方法为同步的,必须将executor中的内存释放完后,Driver的方法才会进行往下执行。