文章目录
- 一、随机函数
- 1. numpy.random.rand(d0,d1,…,dn)
- 2. numpy.random.randn(d0,d1,…,dn)
- 3. numpy.random.normal()
- 4. numpy.random.randint()
- 5. numpy.random.sample
- 6. 随机种子np.random.seed()
- 7. 正态分布 numpy.random.normal
- 二、数组的其他函数
- 1. numpy.resize()
- 2. numpy.append()
- 3. numpy.insert()
- 4. numpy.delete()
- 5. numpy.argwhere()
- 6. numpy.unique()
- 7. numpy.sort()
- 8. numpy.argsort()
- 最开始,我们先导入 numpy 库。
import numpy as np
一、随机函数
- NumPy 中也有自己的随机函数,包含在 random 模块中。它能产生特定分布的随机数,如正态分布等。
- 接下来介绍一些常用的随机数。
| 函数名 | 功能 | 参数使用(int a,b,c,d) |
|---|---|---|
| rand(int1,[int2,[int3,]]) | 生成(0,1)均匀分布随机数 | (a),(a,b),(a,b,c) |
| randn(int1,[int2,[int3,]]) | 生成标准正态分布随机数 | (a),(a,b),(a,b,c) |
| randint(low[,hight,size,dtype]) | 生成随机整数 | (a,b),(a,b,c),(a,b,(c,d)) |
| sample(size) | 生成[0,1)随机数 | (a),((a,b)),((a,b,c)) |
1. numpy.random.rand(d0,d1,…,dn)
- rand 函数根据给定维度生成 [0,1) 之间的数据,包含 0,不包含 1。
- dn 表示每个维度。
- 返回值为指定维度的 array。
- 我们可以创建 4 行 2 列的随机数据。
np.random.rand(4,2)
#array([[0.02533197, 0.80477348],
# [0.85778508, 0.01261245],
# [0.04261013, 0.26928786],
# [0.81136377, 0.34618951]])
- 我们也可以创建 2 块 2 行 3 列的随机数据。
np.random.rand(2,2,3)
#array([[[0.01820147, 0.5591452 , 0.05975028],
# [0.09208771, 0.96067587, 0.87031724]],
#
# [[0.32644706, 0.9580549 , 0.94756885],
# [0.57613453, 0.59642938, 0.62449385]]])
2. numpy.random.randn(d0,d1,…,dn)
- randn 函数返回一个或一组样本,具有标准正态分布。
- dn 表示每个维度。
- 返回值为指定维度的 array。
- 标准正态分布又称为 u 分布,是以 0 为均值、以 1 为标准差的正态分布,记为 N(0,1)。
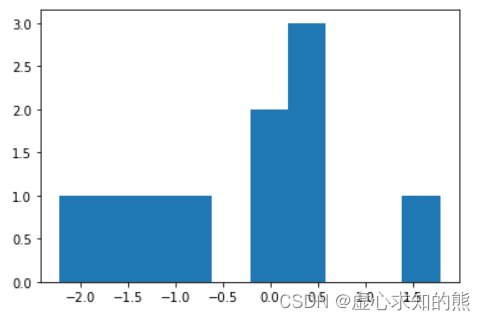
- 我们随机生成满足标准正态分布的 10 个数据,并使用 matplotlib 绘图工具将其绘制出来。
from matplotlib import pyplot as plt
a = np.random.randn(10)
print(a)
plt.hist(a)
#[ 0.42646668 -1.40306793 -0.05431918 0.03763756 1.7889215 0.25540288
# -1.60619811 -2.21199667 -0.92209721 0.47669523]
#(array([1., 1., 1., 1., 0., 2., 3., 0., 0., 1.]),
# array([-2.21199667, -1.81190485, -1.41181303, -1.01172122, -0.6116294 ,
# -0.21153758, 0.18855423, 0.58864605, 0.98873787, 1.38882969,
# 1.7889215 ]),
3. numpy.random.normal()
numpy.random.normal(loc=0.0, scale=1.0, size=None)
- numpy.random.normal 返回一个由 size 指定形状的数组,数组中的值服从 μ=loc,σ=scale 的正态分布。
4. numpy.random.randint()
numpy.random.randint(low, high=None, size=None, dtype=’l’)
- 返回随机整数,范围区间为 [low,high),包含 low,不包含 high。
- 其参数含义为,low 表示最小值,high 表示最大值,size 表示数组维度大小,dtype 表示数据类型,默认的数据类型是 np.int。
- 当 high 没有填写时,默认生成随机数的范围是 [0,low)。
- 例如,我们可以返回 [0,1) 之间的整数,所以只有 0,由于默认数据类型是 int,因此,我们不需要填写数据类型参数。
np.random.randint(1,size=5)
#array([0, 0, 0, 0, 0])
- 同理,我们也可以返回 [2,10) 之间的整数。
np.random.randint(2,10,size=5)
#array([7, 6, 7, 8, 3])
- 我们可以在返回 [2,10) 之间整数的基础上,将返回的维度设置为二维。
np.random.randint(2,10,size=(2,5))
#array([[7, 7, 2, 7, 4],
# [5, 8, 6, 9, 7]])
- 当我们不设置维度参数时,就是默认返回一行一列。例如,我们返回 1 个 [1,5) 之间的随机整数。
np.random.randint(1,5)
#2
- np.random.randint 随机函数对负数也同样生效。例如,我们返回 -5 到 5 之间不包含 5 的 2 行 2 列数据。
np.random.randint(-5,5,size=(2,2))
#array([[-4, -5],
# [ 1, 3]])
5. numpy.random.sample
numpy.random.sample(size=None)
- 返回半开区间内的随机浮点数 [0.0,1.0]。
np.random.sample((2,3))
np.random.sample((2,2,3))
#array([[[0.7686855 , 0.70071112, 0.24265062],
# [0.63907407, 0.76102216, 0.66424632]],
#
# [[0.40679315, 0.73614372, 0.64102261],
# [0.97843216, 0.52552309, 0.44970841]]])
Type Markdown and LaTeX: α2
6. 随机种子np.random.seed()
- 使用相同的 seed() 值,则每次生成的随机数都相同,使得随机数可以预测。
- 但是,只在调用的时候 seed() 一下子并不能使生成的随机数相同,需要每次都调用一下 seed(),表示种子相同,从而生成的随机数相同。
- 如下例子,当我们设置两个随机数种子,就会返回两个不一样的数组。
np.random.seed(2)
L1 = np.random.randn(3, 3)
L2 = np.random.randn(3, 3)
print(L1)
print("-"*10)
print(L2)
#[[-0.41675785 -0.05626683 -2.1361961 ]
# [ 1.64027081 -1.79343559 -0.84174737]
# [ 0.50288142 -1.24528809 -1.05795222]]
----------
#[[-0.90900761 0.55145404 2.29220801]
# [ 0.04153939 -1.11792545 0.53905832]
# [-0.5961597 -0.0191305 1.17500122]]
- 但是,当我们只生产一个随机数种子时,那么,返回的两个数组就会产生一模一样的数据。
np.random.seed(1)
L1 = np.random.randn(3, 3)
np.random.seed(1)
L2 = np.random.randn(3, 3)
print(L1)
print("-"*10)
print(L2)
#[[ 1.62434536 -0.61175641 -0.52817175]
# [-1.07296862 0.86540763 -2.3015387 ]
# [ 1.74481176 -0.7612069 0.3190391 ]]
#----------
#[[ 1.62434536 -0.61175641 -0.52817175]
# [-1.07296862 0.86540763 -2.3015387 ]
# [ 1.74481176 -0.7612069 0.3190391 ]]
7. 正态分布 numpy.random.normal
numpy.random.normal(loc=0.0, scale=1.0, size=None)
- 它的作用是返回一个由 size 指定形状的数组,数组中的值服从 μ=loc,σ=scale 的正态分布。
- 其参数含义如下所示:
- loc : float 型或者 float 型的类数组对象,指定均值 μ。
- scale : float 型或者 float 型的类数组对象,指定标准差 σ。
- size : int 型或者 int 型的元组,指定了数组的形状。如果不提供 size,且 loc 和 scale 为标量(不是类数组对象),则返回一个服从该分布的随机数。
- 例如,我们返回两个正态分布的数组,均为 3 行 2 列,但是他们的均值和标准差不同,第一个返回数组的均值是 0,标准差是 1;第二个返回数组的均值是 1,标准差是 3。
a = np.random.normal(0, 1, (3, 2))
print(a)
print('-'*20)
b = np.random.normal(1, 3, (3, 2))
print(b)
#[[-0.26905696 2.23136679]
# [-2.43476758 0.1127265 ]
# [ 0.37044454 1.35963386]]
#--------------------
#[[ 2.50557162 -1.53264111]
# [ 1.00002928 2.62705772]
# [ 0.05947541 3.31303521]]
二、数组的其他函数
- 主要有以下方法:
| 函数名称 | 描述说明 |
|---|---|
| resize | 返回指定形状的新数组。 |
| append | 将元素值添加到数组的末尾。 |
| insert | 沿规定的轴将元素值插入到指定的元素前。 |
| delete | 删掉某个轴上的子数组,并返回删除后的新数组。 |
| argwhere | 返回数组内符合条件的元素的索引值。 |
| unique | 用于删除数组中重复的元素,并按元素值由大到小返回一个新数组。 |
| sort() | 对输入数组执行排序,并返回一个数组副本 |
| argsort | 沿着指定的轴,对输入数组的元素值进行排序,并返回排序后的元素索引数组 |
1. numpy.resize()
numpy.resize(arr, shape)
- numpy.resize() 可以返回指定形状的新数组。
- 这里我们需要注意的是,numpy.resize(arr,shape) 和 ndarray.resize(shape, refcheck=False) 的区别:
- (1) numpy.resize(arr,shape),有返回值,返回复制内容。如果维度不够,会使用原数组数据补齐。
- (2) ndarray.resize(shape, refcheck=False),修改原数组,不会返回数据。如果维度不够,会使用 0 补齐。
- 具体可见如下示例:
- 首先,我们生成一个指定元素的数组,并输出该数组和数组的形状。
a = np.array([[1,2,3],[4,5,6]])
print('a数组:',a)
print('a数组形状:',a.shape)
#3a数组: [[1 2 3]
# [4 5 6]]
#a数组形状: (2, 3)
- 然后,我们使用 numpy.resize 将 a 数组改变成 3 行 3 列的数组(如果维度不够,会使用原数组数据补齐)。
b = np.resize(a,(3,3))
b
#array([[1, 2, 3],
# [4, 5, 6],
# [1, 2, 3]])
- 此时,我们再次输出 a 数组。
a
#array([[1, 2, 3],
# [4, 5, 6]])
- 然后,我们使用 ndarray.resize(a.resize)将 a 数组改变成 3 行 3 列的数组(如果维度不够,会使用 0 补齐)。
a.resize((3,3),refcheck=False)
a
#array([[1, 2, 3],
# [4, 5, 6],
# [0, 0, 0]])
- 此时,a 数组的原本数据已经进行了修改,在此便不进行演示。
2. numpy.append()
- 它的作用是在数组的末尾添加值,默认返回一个一维数组。
numpy.append(arr, values, axis=None)
- 其参数具有如下含义:
- arr:输入的数组。
- values:向 arr 数组中添加的值,需要和 arr 数组的形状保持一致。
- axis:默认为 None,返回的是一维数组;当 axis=0 时,追加的值会被添加到行,而列数保持不变,若 axis=1 则与其恰好相反。
- 具体可见如下示例:
- 首先,我们生成一个指定元素的数组,并向该数组添加元素。
a = np.array([[1,2,3],[4,5,6]])
print (np.append(a, [7,8,9]))
#[1 2 3 4 5 6 7 8 9]
- 我们可以沿轴 0 添加元素。
print (np.append(a, [[7,8,9]],axis = 0))
#[[1 2 3]
# [4 5 6]
# [7 8 9]]
- 我们也可以沿轴 1 添加元素。
print (np.append(a, [[5,5,5],[7,8,9]],axis = 1))
#[[1 2 3 5 5 5]
# [4 5 6 7 8 9]]
3. numpy.insert()
- 该函数表示沿指定的轴,在给定索引值的前一个位置插入相应的值,如果没有提供轴,则输入数组被展开为一维数组。
numpy.insert(arr, obj, values, axis)
- 其参数具有如下含义:
- arr:要输入的数组。
- obj:表示索引值,在该索引值之前插入 values 值。
- values:要插入的值。
- axis:指定的轴,如果未提供,则输入数组会被展开为一维数组。
- 具体可见如下示例:
- 我们生成一个指定元素的数组,并不提供axis的情况。
a = np.array([[1,2],[3,4],[5,6]])
print (np.insert(a,3,[11,12]))
#[ 1 2 3 11 12 4 5 6]
- 我们可以沿轴 0 将元素插入到行。
print (np.insert(a,1,[11],axis = 0))
#[[ 1 2]
# [11 11]
# [ 3 4]
# [ 5 6]]
- 我们也可以沿轴 1 将元素插入到列。
print (np.insert(a,1,11,axis = 1))
#[[ 1 11 2]
# [ 3 11 4]
# [ 5 11 6]]
4. numpy.delete()
- numpy.delete() 表示从输入数组中删除指定的子数组,并返回一个新数组。
- 它与 insert() 函数相似,若不提供 axis 参数,则输入数组被展开为一维数组。
numpy.delete(arr, obj, axis)
- 其参数具有如下含义:
- arr:要输入的数组;
- obj:整数或者整数数组,表示要被删除数组元素或者子数组;
- axis:沿着哪条轴删除子数组。
- 具体可见如下示例:
- 我们生成一个指定元素的数组,并不提供axis的情况,是删除指定数组元素。
a = np.arange(12).reshape(3,4)
print(a)
print(np.delete(a,5))
#[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
#[ 0 1 2 3 4 6 7 8 9 10 11]
- 我们可以删除第二列,但注意需要将 axis 参数设置为 1,表示沿列方向进行删除。
- 我们也可以将 axis 参数设置为 0,沿行方向进行多行元素删除操作。
- 这里需要注意的是,不可以使用切片的形式。
print(np.delete(a,1,axis = 1))
print(a)
print(np.delete(a,[1,2],axis = 0))
#[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
#[[0 1 2 3]]
5. numpy.argwhere()
- numpy.argwhere()返回数组中非 0 元素的索引,若是多维数组则返回行、列索引组成的索引坐标。
- 具体可见如下示例:
- 我们生成一个指定元素的数组,并将其输出。
x = np.arange(6).reshape(2,3)
x
#array([[0, 1, 2],
# [3, 4, 5]])
- 然后,返回所有大于 1 的元素索引。
print(x)
y=np.argwhere(x>1)
print("-"*10)
print(y,y.shape)
#[[0 1 2]
# [3 4 5]]
#----------
#[[0 2]
# [1 0]
# [1 1]
# [1 2]] (4, 2)
6. numpy.unique()
- numpy.unique() 用于删除数组中重复的元素。
numpy.unique(arr, return_index, return_inverse, return_counts)
- 其参数具有如下含义:
- arr:输入数组,若是多维数组则以一维数组形式展开。
- return_index:如果为 True,则返回新数组元素在原数组中的位置(索引)。
- return_inverse:如果为 True,则返回原数组元素在新数组中的位置(索引)。
- return_counts:如果为 True,则返回去重后的数组元素在原数组中出现的次数。
- 具体可见如下示例:
- 我们先生成一个指定元素的数组,并将其输出。
- 然后,使用 numpy.unique() 对其进行去重操作,并将其输出,便于比对观察。
a = np.array([5,2,6,2,7,5,6,8,2,9])
print (a)
uq = np.unique(a)
print(uq)
#[5 2 6 2 7 5 6 8 2 9]
#[2 5 6 7 8 9]
- 我们可以获取数组去重后的索引数组,并打印去重后数组的索引。
print("a:",a)
u,indices = np.unique(a, return_index = True)
print(u)
print('-'*20)
print(indices)
#a: [5 2 6 2 7 5 6 8 2 9]
#[2 5 6 7 8 9]
#--------------------
#[1 0 2 4 7 9]
- 我们也可以获取去重数组的下标,并打印其下标。
ui,indices = np.unique(a,return_inverse = True)
print (ui)
print('-'*20)
print (indices)
print("a:",a)
#[2 5 6 7 8 9]
#--------------------
#[1 0 2 0 3 1 2 4 0 5]
- 我们可以知道去重元素的重复数量,也就是该去重元素的出现次数。
uc,indices = np.unique(a,return_counts = True)
print (uc)
print (indices)
#a: [5 2 6 2 7 5 6 8 2 9]
#[2 5 6 7 8 9]
#[3 2 2 1 1 1]
7. numpy.sort()
- numpy.sort() 表示对输入数组执行排序,并返回一个数组副本。
numpy.sort(a, axis, kind, order)
- 其参数具有如下含义:
- a:要排序的数组。
- axis:沿着指定轴进行排序,如果没有指定 axis,默认在最后一个轴上排序,若 axis=0 表示按列排序,axis=1 表示按行排序。
- kind:默认为 quicksort(快速排序)。
- order:若数组设置了字段,则 order 表示要排序的字段。
- 具体可见如下示例:
- 我们先生成一个指定元素的数组,并将其输出,然后调用 sort() 函数对其进行排序并输出排序后的数组。
- 最后,输出原数组,发现并没有发生改变,说明 sort() 函数不会对原数组内的元素进行修改。
a = np.array([[3,7,5],[6,1,4]])
print('a数组是:', a)
print('排序后的内容:',np.sort(a))
a
#a数组是: [[3 7 5]
# [6 1 4]]
#排序后的内容: [[3 5 7]
# [1 4 6]]
#array([[3, 7, 5],
# [6, 1, 4]])
- 我们可以以行为参照,列上面的数据排序:
print(np.sort(a, axis = 0))
#[[3 1 4]
# [6 7 5]]
- 我们也可以以列为参照,行上面的数据排序:
print(np.sort(a, axis = 1))
#[[3 5 7]
# [1 4 6]]
- 我们还可以在 sort 函数中设置排序字段,按我们指定的方式进行排序。
- 首先,我们指定数据类型为名字(字符串)和年龄(整型),按指定好的的数据类型定义数组的元素,并将其元素输出。
- 然后,我们将指定排序方式定义为名字,并输出排序后的数组,与前面输出的原数组数据进行比较。
dt = np.dtype([('name', 'S10'),('age', int)])
a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt)
print(a)
print('--'*10)
print(np.sort(a, order = 'name'))
#[(b'raju', 21) (b'anil', 25) (b'ravi', 17) (b'amar', 27)]
#--------------------
#[(b'amar', 27) (b'anil', 25) (b'raju', 21) (b'ravi', 17)]
8. numpy.argsort()
- argsort() 表示沿着指定的轴,对输入数组的元素值进行排序,并返回排序后的元素索引数组。
- 具体可见如下示例:
- 我们先生成一个指定元素的数组,并将其输出。
a = np.array([90, 29, 89, 12])
print("原数组:",a)
#原数组: [90 29 89 12]
- 然后,使用 numpy.argsort() 对 a 数组进行排序,并将排序后的元素索引数组输出。
sort_ind = np.argsort(a)
print("打印排序元素索引值:",sort_ind)
#打印排序元素索引值: [3 1 2 0]
- 随后,我们可以使用索引数组对原数组进行排序。
sort_a = a[sort_ind]
print("打印排序数组")
for i in sort_ind:
print(a[i],end = " ")
a[sort_ind]
#打印排序数组
#12 29 89 90
#array([12, 29, 89, 90])