前言:
搭建大数据环境集群环境算是比较麻烦的一个事情,并且对硬件要求也比较高其中搭建大数据环境需要准备jdk环境和zk环境,还有hdfs,还有ssh之间的免密操作,还有主机别名访问不通的问题 等。
必然会出现的问题:环境版本,配置问题,内存问题,节点端口通讯等。
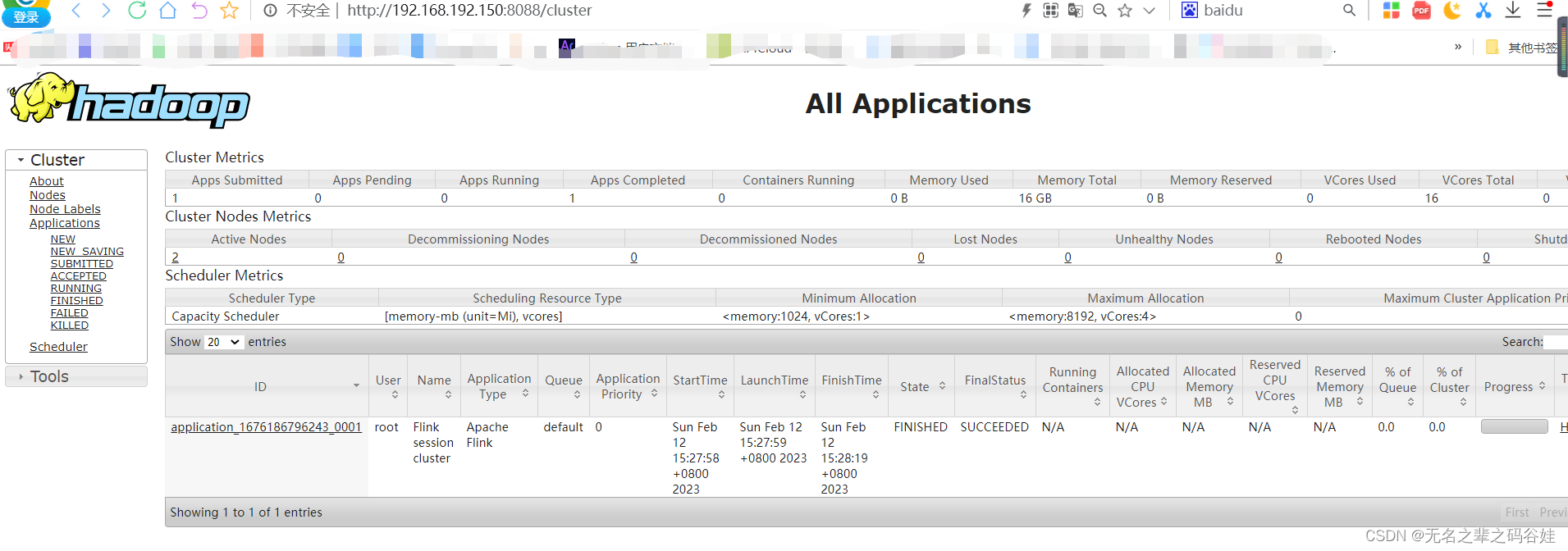
最终效果图:
一 环境准备:
三台服务器:
jdk | jdk1.8 | 环境变量 |
hadoop | hadoop-3.1.3 | 版本 |
flink | flink-1.6.1 | 版本 |
主 | 192.168.192.150 | 免密登录 |
从1 | 192.168.192.151 | 免密登录 |
从2 | 192.168.192.152 | 免密登录 |
三台服务器设置免密登录,且配置当前主机的别名映射:
vim /etc/hosts
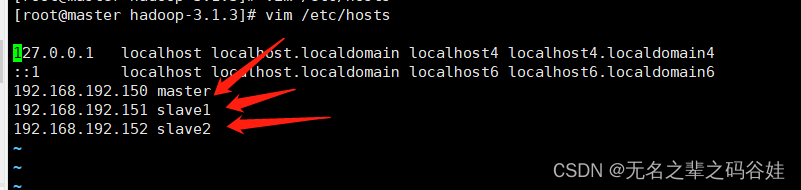
三台服务器的配置信息:
我这里电脑是16G运行内存,也可以看设备管理器(虚拟机设置太大运行内存虚拟机会报错,适量内存配置)
二 配置文件:
2.1 配置hadoop-env.sh文件
vim /opt/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_301
export HADOOP_HOME=/opt/hadoop-3.1.3
2.2 配置core-site.xml文件
vim /opt/hadoop-3.1.3/etc/hadoop/core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.192.150:9000</value>
</property>

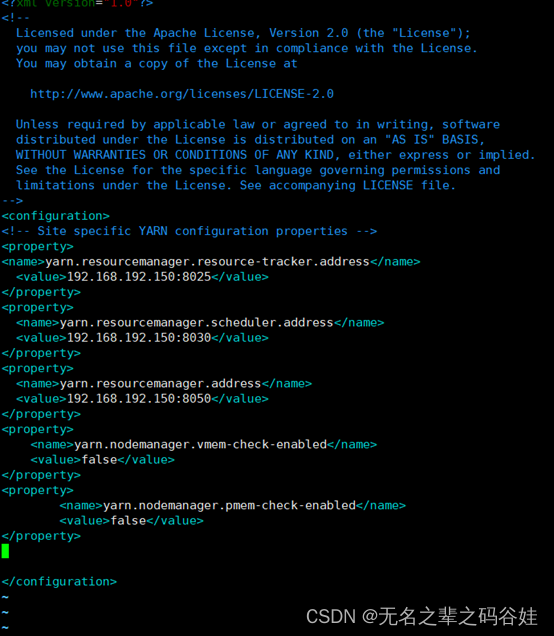
2.3 配置yarn-site.xml文件
vim /opt/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.192.150:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.192.150:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.192.150:8050</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
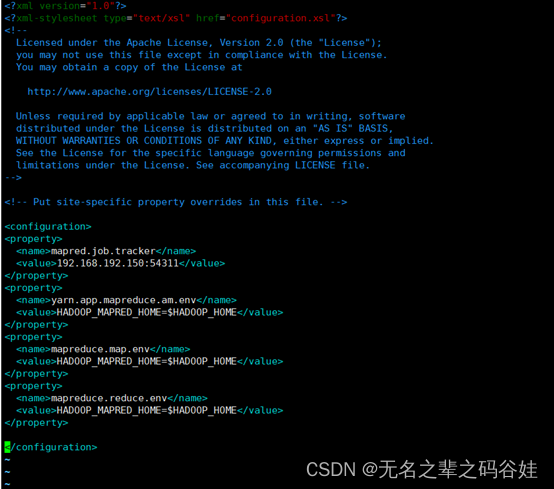
2.4配置mapred-site.xml文件
vim /opt/hadoop-3.1.3/etc/hadoop/mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>192.168.192.150:54311</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
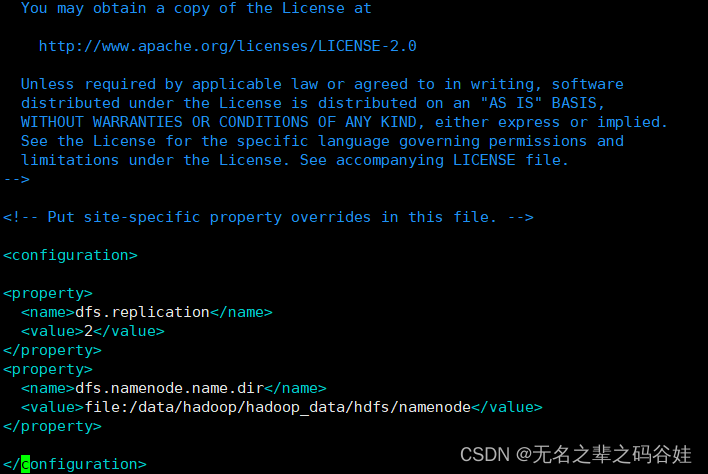
2.5 配置hdfs-site.xml文件
vim /opt/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/hadoop_data/hdfs/namenode</value>
</property>
2.6 配置workers文件
vim /opt/hadoop-3.1.3/etc/hadoop/workers

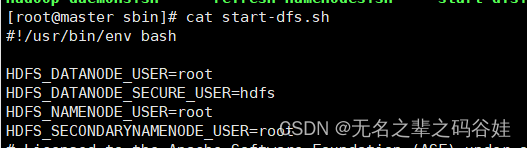
2.7 配置start-dfs.sh和stop-dfs.sh文件
vim /opt/hadoop-3.1.3/sbin/ start-dfs.sh
vim /opt/hadoop-3.1.3/sbin/stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root因为hdfs启动是root用户需要配置root配置,也可以加到/etc/profile 全局环境变量中
2.8 配置start-yarn.sh和stop-yarn.sh文件
vim /opt/hadoop-3.1.3/sbin/start-yarn.sh
vim /opt/hadoop-3.1.3/sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root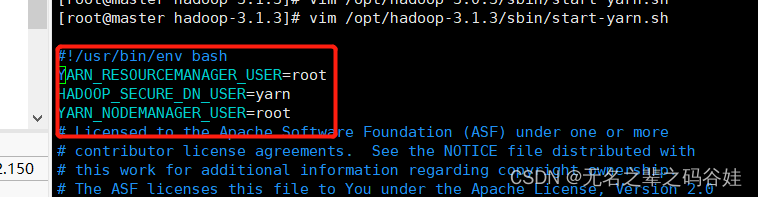
2.9 把配置好的配置复制到其他俩台节点服务器上面,直接复制/opt/hodoop3.1.3
scp -r /opt/hodoop3.1.3 slave1:/opt/
scp -r /opt/hodoop3.1.3 slave2:/opt/
三 启动集群:
3.1 初始化NameNode
/opt/hadoop-3.1.3/bin/hadoop namenode -format
(注意:这里如果jps没有namenode就需要手动启动了)
hadoop-daemon.sh start namenode


3.2 直接执行全部启动的脚本
start-all.sh

四,启动后状态
master->192.168.192.150
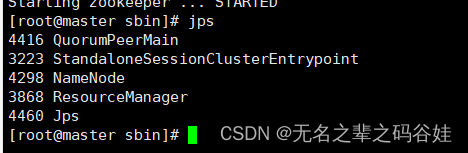
slave1-> 192.168.192.151
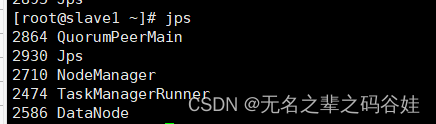
slaev2->192.168.192.152

QuorumPeerMain zookeeper的进程
ResourceManager flink进程
TaskManagerRunner flink进程
NodeManager yarn进程
NameNode HDFS进程
DataNode HDFS进程
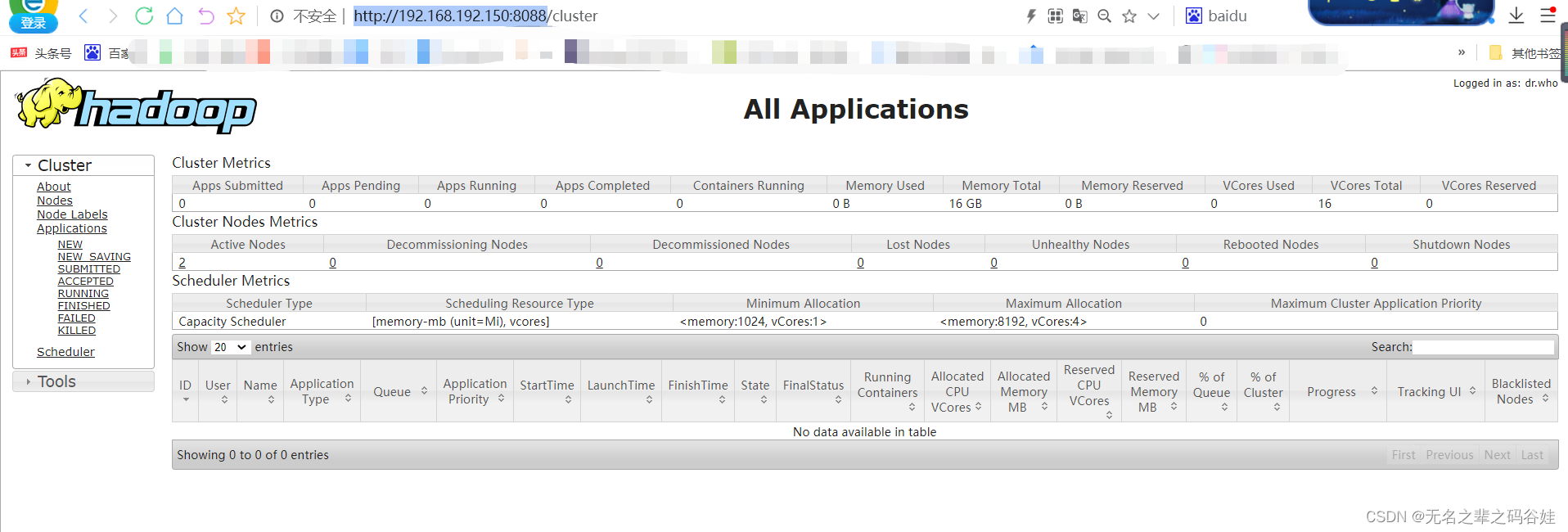
web页面访问:
大数据地址:
http://192.168.192.150:8088
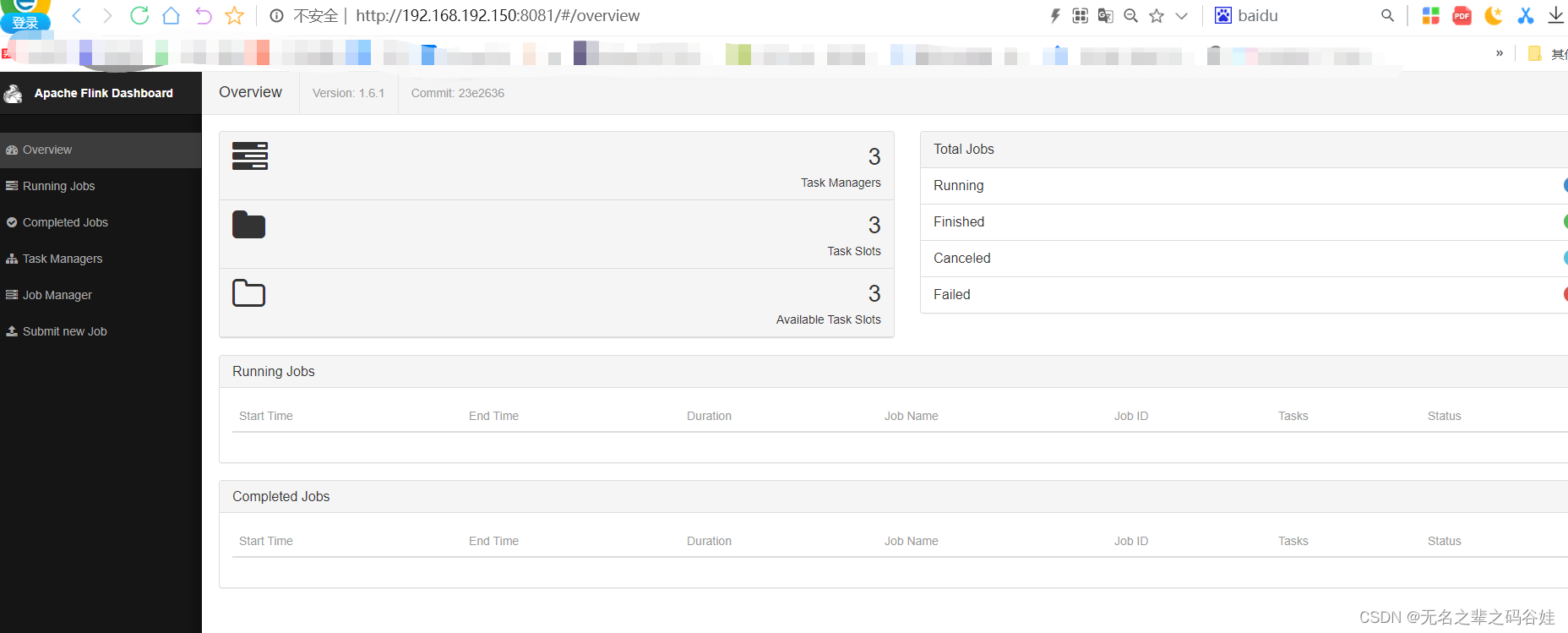
flink访问地址:
http://192.168.192.150:8081
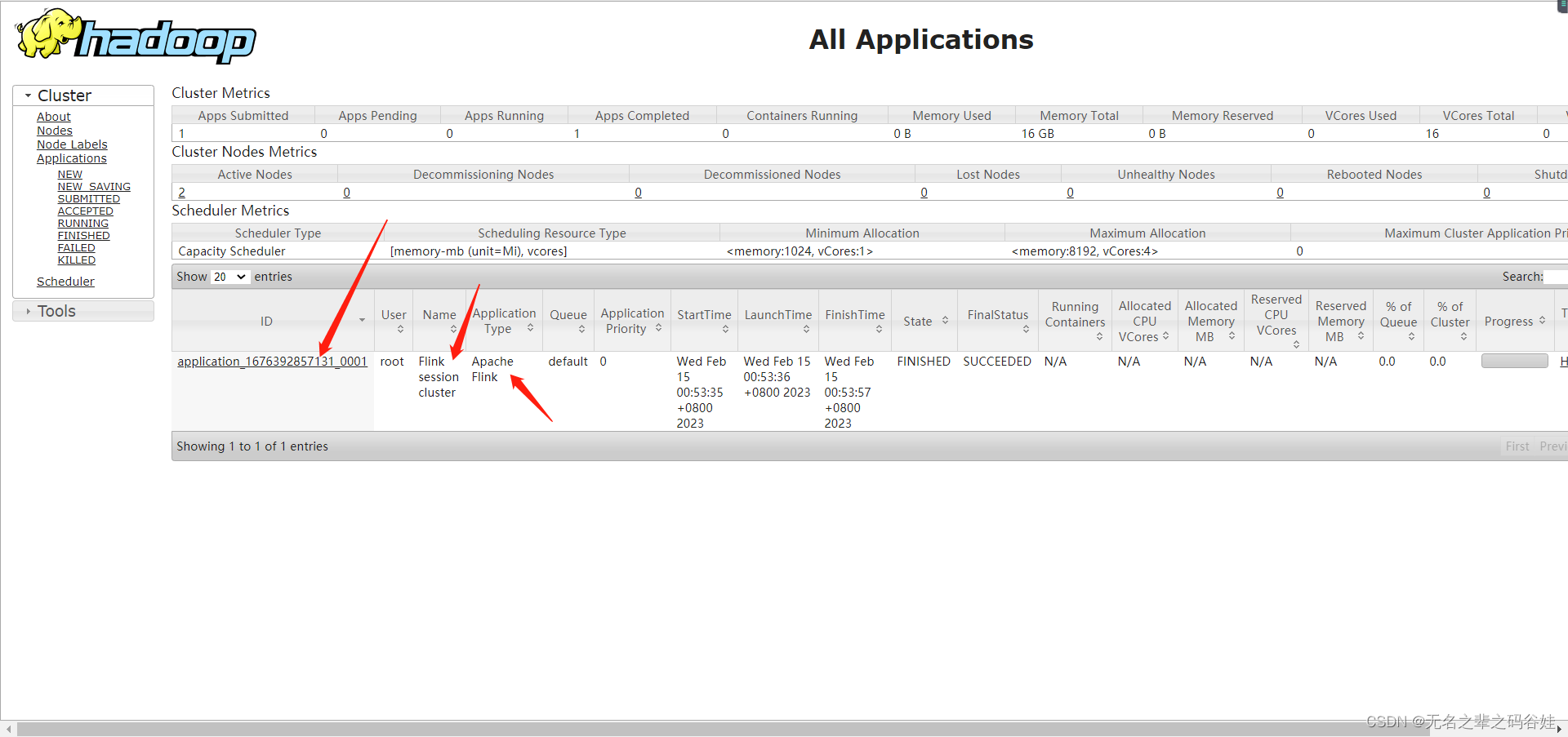
五,采用yarn-session+ flink提交任务执行(这里有很多种任务提交,flink单服务提交,yarn-session提交)
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -c com.xiaoyang.streaming.SocketDemoFullCount ../Flink-1.0-SNAPSHOT.jar

去hadoop界面查看任务执行情况
为啥要采用这种方式部署:
(开辟资源+提交任务)
没次创建新的flink集群任务之间互不影响,任务执行完成后对应集群也会消失。
先开辟资源再提交任务
这种会使用所以任务都会提交到一个资源,任务需要手动停止,不易于拓展和管理
六,问题记录排查和解决
6.1任务启动失败
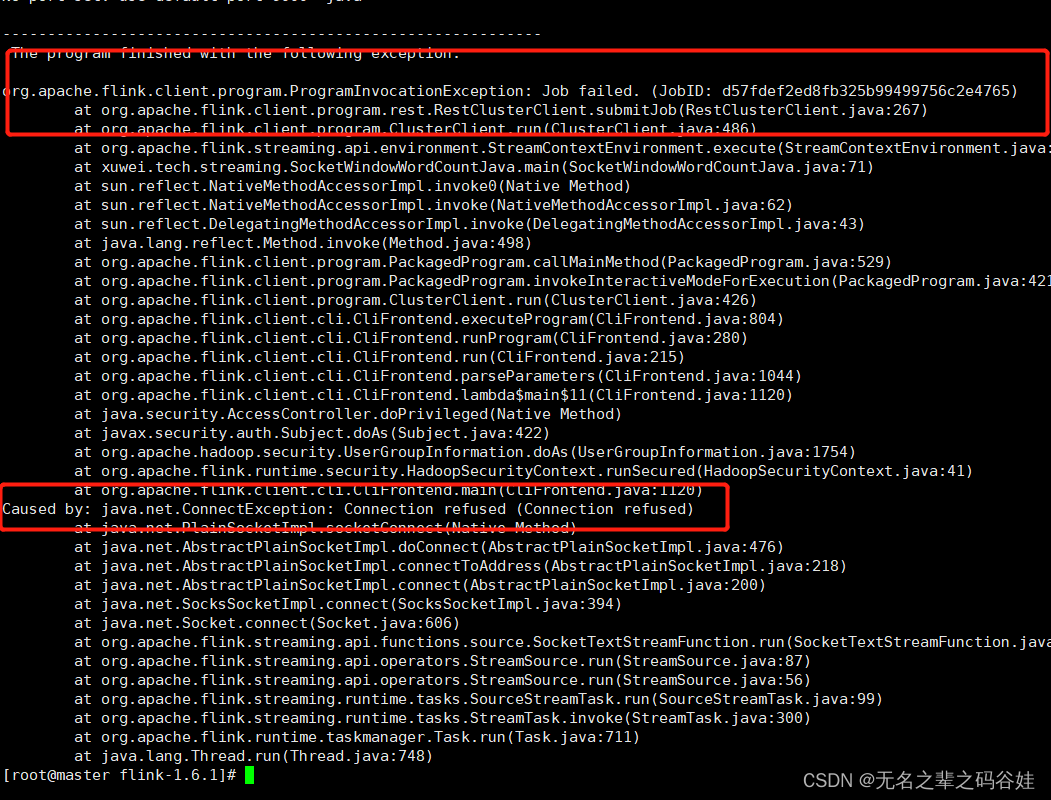
这种问题一看就是脚本问题启动问题
错误脚本:
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ../Flink-1.0-SNAPSHOT.jar -c com.xiaoyang.streaming.SocketDemoFullCount
正确脚本:
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -c com.xiaoyang.streaming.SocketDemoFullCount ../Flink-1.0-SNAPSHOT.jar
6.2 集群配置问题别名
集群里面的配置最好使用ip配置,不要使用别名,这样在通讯的时候不会出现端口问题,这样启动任务的时候会有连接问题。
6.3 权限配置问题
权限配置问题需要配置要么配置到全局变量或者 指定配置里面,不然会报错。
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
6.4 hdfs 节点启动问题
主节点必须要有NameNode ,从节点要有DataNode 不然启动hdfs启动会报错。
6.5 环境变量配置问题,hadoop配置jdk环境,如果不配置启动也会报错。
6.6 配置问题 /opt/hadoop-3.1.3/etc/hadoop/目录下的配置文件
如果配置错误也会导致报错各种问题,所以配置需要仔细检查

6.7 其他问题,这里包括版本包的问题,依赖包的问题,不能太新也不能太旧
总结:
首先部署hadoop集群其实还是比较麻烦的,环境配置,各个配置的依赖,节点信息,当然部署过程难免也会遇到很多问题,但是我们在解决一个困扰很久的问题的时候你不仅在成长还会收获满满的成就感。
————没有与生俱来的天赋,都是后天的努力拼搏(我是小杨,谢谢你的关注和支持)