在《kubernetes Device Plugin原理与源码分析》一文中,我们从源码层面了解了kubelet侧关于device plugin逻辑的实现逻辑,本文以nvidia管理GPU的开源github项目k8s-device-plugin为例,来看看设备插件侧的实现示例。
一、Kubernetes Device Plugin
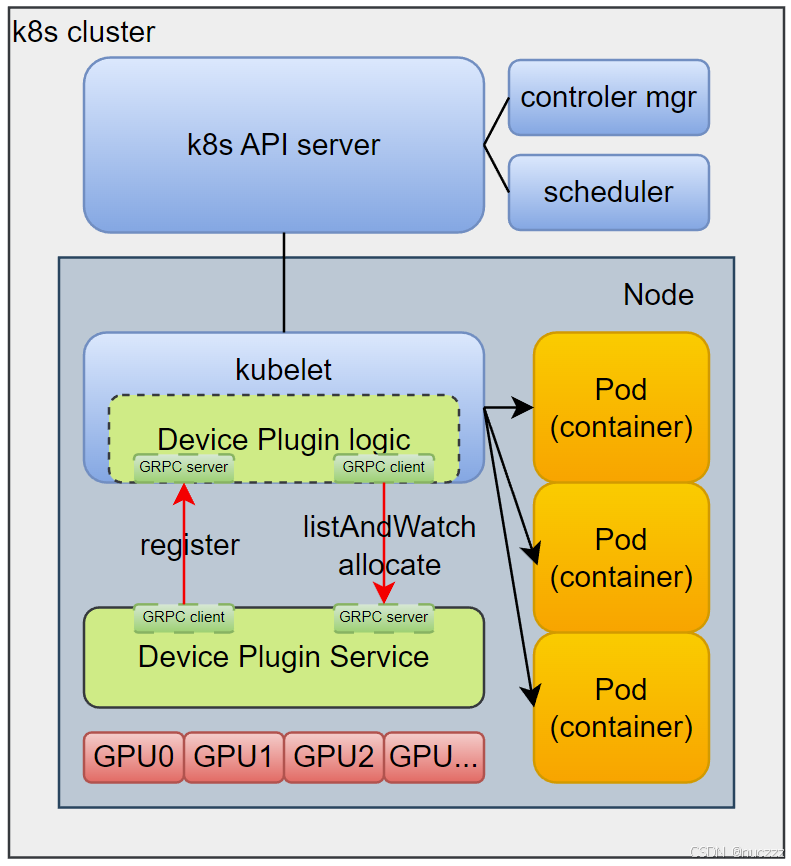
回顾上文kubelet侧的实现逻辑可知,设备插件侧应该实现如下逻辑:
- 启动一个GRPC service,该service需实现以下方法(v1beta1):
// DevicePlugin is the service advertised by Device Plugins
service DevicePlugin {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// GetPreferredAllocation returns a preferred set of devices to allocate
// from a list of available ones. The resulting preferred allocation is not
// guaranteed to be the allocation ultimately performed by the
// devicemanager. It is only designed to help the devicemanager make a more
// informed allocation decision when possible.
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// PreStartContainer is called, if indicated by Device Plugin during registeration phase,
// before each container start. Device plugin can run device specific operations
// such as resetting the device before making devices available to the container
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
最主要的是ListAndWatch和Allocate两个方法,其中ListAndWatch方法负责上报设备上GPU的状态数据给kubelet,Allocate方法则是kubelet创建带有GPU资源的pod容器真正分配资源的方法。
- 启动上述GRPC service后调用kubelet的Register方法,把自己注册到k8s中
二、k8s-device-plugin源码解读
以下内容基于github.com/NVIDIA/k8s-device-plugin@v0.16.2
2.1 main
由于k8s-device-plugin代码量和逻辑并不算复杂,我们直接从main函数开始:
// k8s-device-plugin/cmd/nvidia-device-plugin/main.go
func main() {
...
c.Action = func(ctx *cli.Context) error {
return start(ctx, c.Flags)
}
...
}
// k8s-device-plugin/cmd/nvidia-device-plugin/main.go
func start(c *cli.Context, flags []cli.Flag) error {
...
klog.Info("Starting FS watcher.")
// pluginapi.DevicePluginPath = /var/lib/kubelet/device-plugins/
watcher, err := watch.Files(pluginapi.DevicePluginPath)
if err != nil {
return fmt.Errorf("failed to create FS watcher for %s: %v", pluginapi.DevicePluginPath, err)
}
defer watcher.Close()
...
plugins, restartPlugins, err := startPlugins(c, flags)
...
for {
select {
...
case event := <-watcher.Events:
// pluginapi.KubeletSocket = /var/lib/kubelet/device-plugins/kubelet.sock
if event.Name == pluginapi.KubeletSocket && event.Op&fsnotify.Create == fsnotify.Create {
klog.Infof("inotify: %s created, restarting.", pluginapi.KubeletSocket)
goto restart
}
...
}
}
...
}
这里注意一个逻辑:k8s-device-plugin在启动的时候会监听/var/lib/kubelet/device-plugins/kubelet.sock文件,当创建这个文件后,k8s-device-plugin会重启(goto restart)。之所以有这个逻辑,是因为kubelet重启会重新创建这个文件,而kubelet重启会清除其它设备插件放在这个目录下的socket文件,而且由于kubelet和设备插件之间通过ListAndWatch方法建立了长连接,这个长连接需要设备插件调用kubelet的Register方法触发,断连后k8s-device-plugin goto restart才能重新建立连接。
2.2 startPlugins
startPlugins主要代码逻辑如下:
// k8s-device-plugin/cmd/nvidia-device-plugin/main.go
func startPlugins(c *cli.Context, flags []cli.Flag) ([]plugin.Interface, bool, error) {
...
driverRoot := root(*config.Flags.Plugin.ContainerDriverRoot)
// We construct an NVML library specifying the path to libnvidia-ml.so.1
// explicitly so that we don't have to rely on the library path.
nvmllib := nvml.New(
nvml.WithLibraryPath(driverRoot.tryResolveLibrary("libnvidia-ml.so.1")),
)
devicelib := device.New(nvmllib)
infolib := nvinfo.New(
nvinfo.WithNvmlLib(nvmllib),
nvinfo.WithDeviceLib(devicelib),
)
...
pluginManager, err := NewPluginManager(infolib, nvmllib, devicelib, config)
if err != nil {
return nil, false, fmt.Errorf("error creating plugin manager: %v", err)
}
plugins, err := pluginManager.GetPlugins()
if err != nil {
return nil, false, fmt.Errorf("error getting plugins: %v", err)
}
...
for _, p := range plugins {
// Just continue if there are no devices to serve for plugin p.
if len(p.Devices()) == 0 {
continue
}
// Start the gRPC server for plugin p and connect it with the kubelet.
if err := p.Start(); err != nil {
klog.Errorf("Failed to start plugin: %v", err)
return plugins, true, nil
}
started++
}
...
}
在startPlugins函数中,有以下几个逻辑本文会深入解读下:
2.2.1 初始化nvmllib对象
driverRoot := root(*config.Flags.Plugin.ContainerDriverRoot)
// We construct an NVML library specifying the path to libnvidia-ml.so.1
// explicitly so that we don't have to rely on the library path.
nvmllib := nvml.New(
nvml.WithLibraryPath(driverRoot.tryResolveLibrary("libnvidia-ml.so.1")),
)
调用nvml.New方法基于动态库libnvidia-ml.so.1初始化好一个nvmllib对象,nvml是NVIDIA Management Library的简写,nvmllib对象显然就是对接nvml库的一个对象,而查找libnvidia-ml.so.1动态库则会按顺序在(默认)/driver-root子目录/usr/lib64、/usr/lib/x86_64-linux-gnu、/usr/lib/aarch64-linux-gnu、/lib64、/lib/x86_64-linux-gnu、/lib/aarch64-linux-gnu目录下查找,知道找到第一个符合条件的库文件。
func (r root) tryResolveLibrary(libraryName string) string {
if r == "" || r == "/" {
return libraryName
}
librarySearchPaths := []string{
"/usr/lib64",
"/usr/lib/x86_64-linux-gnu",
"/usr/lib/aarch64-linux-gnu",
"/lib64",
"/lib/x86_64-linux-gnu",
"/lib/aarch64-linux-gnu",
}
for _, d := range librarySearchPaths {
l := r.join(d, libraryName)
resolved, err := resolveLink(l)
if err != nil {
continue
}
return resolved
}
return libraryName
}
2.2.2 初始化devicelib对象
调用device.New方法基于nvmllib初始化一个用于设备管理的对象,初始化时WithSkippedDevices初始化好后续会跳过的设备"DGX Display"、“NVIDIA DGX Display”。
// New creates a new instance of the 'device' interface.
func New(nvmllib nvml.Interface, opts ...Option) Interface {
d := &devicelib{
nvmllib: nvmllib,
}
for _, opt := range opts {
opt(d)
}
if d.verifySymbols == nil {
verify := true
d.verifySymbols = &verify
}
if d.skippedDevices == nil {
WithSkippedDevices(
"DGX Display",
"NVIDIA DGX Display",
)(d)
}
return d
}
2.2.3 初始化infolib对象
调用nvinfo.New方法基于nvmllib和devicelib初始化一个nvidia设备汇总信息的对象:
// New creates a new instance of the 'info' interface.
func New(opts ...Option) Interface {
o := &options{}
for _, opt := range opts {
opt(o)
}
if o.logger == nil {
o.logger = &nullLogger{}
}
if o.root == "" {
o.root = "/"
}
if o.nvmllib == nil {
o.nvmllib = nvml.New(
nvml.WithLibraryPath(o.root.tryResolveLibrary("libnvidia-ml.so.1")),
)
}
if o.devicelib == nil {
o.devicelib = device.New(o.nvmllib)
}
if o.platform == "" {
o.platform = PlatformAuto
}
if o.propertyExtractor == nil {
o.propertyExtractor = &propertyExtractor{
root: o.root,
nvmllib: o.nvmllib,
devicelib: o.devicelib,
}
}
return &infolib{
PlatformResolver: &platformResolver{
logger: o.logger,
platform: o.platform,
propertyExtractor: o.propertyExtractor,
},
PropertyExtractor: o.propertyExtractor,
}
}
2.2.4 初始化pluginManager对象并获取plugin列表
先调用NewPluginManager方法得到pluginManager设备管理对象,再调用该对象的GetPlugins方法获取插件列表。先思考这里的plugins指什么呢?这里的plugins其实指的是一组具体管理某种特定类型GPU资源的插件实例,这些实例会根据GPU硬件配置和用户策略动态生成,每个插件负责一种特定资源类型的上报和分配。
常见的GPU“类型”有:
1)基础GPU设备:
// 节点有2块未启用MIG的T4 GPU
plugins = [
&NvidiaDevicePlugin{
resourceName: "nvidia.com/gpu",
devices: [GPU0, GPU1] // 管理所有基础GPU设备
}
]
资源类型:nvidia.com/gpu
调度表现:
$ kubectl describe node
Capacity:
nvidia.com/gpu: 2
2)启用MIG的A100
// A100 GPU被切分为4个1g.10gb实例
plugins = [
&NvidiaDevicePlugin{
resourceName: "nvidia.com/mig-1g.10gb",
devices: [MIG0, MIG1, MIG2, MIG3]
}
]
资源类型:nvidia.com/mig-1g.10gb
调度表现:
$ kubectl describe node
Capacity:
nvidia.com/mig-1g.10gb: 4
3)时间切片配置
# values.yaml配置
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4
// 生成虚拟设备
plugins = [
&NvidiaDevicePlugin{
resourceName: "nvidia.com/gpu",
devices: [GPU0-0, GPU0-1, GPU0-2, GPU0-3] // 单卡虚拟为4个设备
}
]
资源类型:nvidia.com/gpu(虚拟化后)
调度表现:
$ kubectl describe node
Capacity:
nvidia.com/gpu: 4 # 物理卡数*replicas
当一台机器上同时存在基础GPU和MIG设备时:
plugins = [
&NvidiaDevicePlugin{ // 管理非MIG设备
resourceName: "nvidia.com/gpu",
devices: [GPU0]
},
&NvidiaDevicePlugin{ // 管理MIG切片
resourceName: "nvidia.com/mig-2g.20gb",
devices: [MIG0, MIG1]
}
]
此时k8s-device-plugin将同时上报两种资源:
$ kubectl describe node
Capacity:
nvidia.com/gpu: 1
nvidia.com/mig-2g.20gb: 2
k8s-device-plugin这么设计的意义:
1)架构灵活性:支持混合部署不同GPU类型
2)资源隔离性:不同插件管理独立资源池
3)策略扩展性:新增策略只需实现新的Plugin生成逻辑
通过这种设计,k8s-device-plugin可以同时支持裸金属GPU、MIG切片、时间切片等多种资源管理模式,而无需修改核心分配逻辑。
再来看看NewPluginManager和pluginManager.GetPlugins的实现。先是NewPluginManager:判断MigStrategy,有三种选项:none、single、mixed。之后用cdi.New方法初始化一个cdiHandler,这里的cdi是Container Device Interface的简写,CDI也是社区设备管理的一个方向。
// NewPluginManager creates an NVML-based plugin manager
func NewPluginManager(infolib info.Interface, nvmllib nvml.Interface, devicelib device.Interface, config *spec.Config) (manager.Interface, error) {
var err error
switch *config.Flags.MigStrategy {
case spec.MigStrategyNone:
case spec.MigStrategySingle:
case spec.MigStrategyMixed:
default:
return nil, fmt.Errorf("unknown strategy: %v", *config.Flags.MigStrategy)
}
// TODO: We could consider passing this as an argument since it should already be used to construct nvmllib.
driverRoot := root(*config.Flags.Plugin.ContainerDriverRoot)
deviceListStrategies, err := spec.NewDeviceListStrategies(*config.Flags.Plugin.DeviceListStrategy)
if err != nil {
return nil, fmt.Errorf("invalid device list strategy: %v", err)
}
cdiHandler, err := cdi.New(infolib, nvmllib, devicelib,
cdi.WithDeviceListStrategies(deviceListStrategies),
cdi.WithDriverRoot(string(driverRoot)),
cdi.WithDevRoot(driverRoot.getDevRoot()),
cdi.WithTargetDriverRoot(*config.Flags.NvidiaDriverRoot),
cdi.WithTargetDevRoot(*config.Flags.NvidiaDevRoot),
cdi.WithNvidiaCTKPath(*config.Flags.Plugin.NvidiaCTKPath),
cdi.WithDeviceIDStrategy(*config.Flags.Plugin.DeviceIDStrategy),
cdi.WithVendor("k8s.device-plugin.nvidia.com"),
cdi.WithGdsEnabled(*config.Flags.GDSEnabled),
cdi.WithMofedEnabled(*config.Flags.MOFEDEnabled),
)
if err != nil {
return nil, fmt.Errorf("unable to create cdi handler: %v", err)
}
m, err := manager.New(infolib, nvmllib, devicelib,
manager.WithCDIHandler(cdiHandler),
manager.WithConfig(config),
manager.WithFailOnInitError(*config.Flags.FailOnInitError),
manager.WithMigStrategy(*config.Flags.MigStrategy),
)
if err != nil {
return nil, fmt.Errorf("unable to create plugin manager: %v", err)
}
if err := m.CreateCDISpecFile(); err != nil {
return nil, fmt.Errorf("unable to create cdi spec file: %v", err)
}
return m, nil
}
pluginManager.GetPlugins则是借助nvml对象获取机器上的设备信息:
// GetPlugins returns the plugins associated with the NVML resources available on the node
func (m *nvmlmanager) GetPlugins() ([]plugin.Interface, error) {
rms, err := rm.NewNVMLResourceManagers(m.infolib, m.nvmllib, m.devicelib, m.config)
if err != nil {
return nil, fmt.Errorf("failed to construct NVML resource managers: %v", err)
}
var plugins []plugin.Interface
for _, r := range rms {
plugin, err := plugin.NewNvidiaDevicePlugin(m.config, r, m.cdiHandler)
if err != nil {
return nil, fmt.Errorf("failed to create plugin: %w", err)
}
plugins = append(plugins, plugin)
}
return plugins, nil
}
2.3 plugin.Start
// k8s-device-plugin/internal/plugin/server.go
func (plugin *NvidiaDevicePlugin) Start() error {
...
// 启动gRPC服务
err := plugin.Serve()
...
// 向kubelet注册插件
err = plugin.Register()
...
// 启动一个协程对设备
go func() {
// TODO: add MPS health check
err := plugin.rm.CheckHealth(plugin.stop, plugin.health)
if err != nil {
klog.Infof("Failed to start health check: %v; continuing with health checks disabled", err)
}
}()
return nil
}
在plugin.Start函数中主要做了三件事:
1)plugin.Serve启动一个gRPC服务,该服务实现如下方法
// DevicePlugin is the service advertised by Device Plugins
service DevicePlugin {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// GetPreferredAllocation returns a preferred set of devices to allocate
// from a list of available ones. The resulting preferred allocation is not
// guaranteed to be the allocation ultimately performed by the
// devicemanager. It is only designed to help the devicemanager make a more
// informed allocation decision when possible.
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// PreStartContainer is called, if indicated by Device Plugin during registeration phase,
// before each container start. Device plugin can run device specific operations
// such as resetting the device before making devices available to the container
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
2)plugin.Register向kubelet注册自己
3)plugin.rm.CheckHealth启动一个协程对相关设备做健康检查
2.4 plugin.rm.CheckHealth
当前版本实现了nvml和tegra(always ok)的健康检查,以nvml为例,CheckHealth的实现方式如下,其实就是一个for循环调用nvml对设备进行检查:
// k8s-device-plugin/internal/rm/nvml_manager.go
// CheckHealth performs health checks on a set of devices, writing to the 'unhealthy' channel with any unhealthy devices
func (r *nvmlResourceManager) CheckHealth(stop <-chan interface{}, unhealthy chan<- *Device) error {
return r.checkHealth(stop, r.devices, unhealthy)
}
// k8s-device-plugin/internal/rm/health.go
func (r *nvmlResourceManager) checkHealth(stop <-chan interface{}, devices Devices, unhealthy chan<- *Device) error {
...
eventSet, ret := r.nvml.EventSetCreate()
...
for {
select {
case <-stop:
return nil
default:
}
e, ret := eventSet.Wait(5000)
if ret == nvml.ERROR_TIMEOUT {
continue
}
if ret != nvml.SUCCESS {
klog.Infof("Error waiting for event: %v; Marking all devices as unhealthy", ret)
for _, d := range devices {
unhealthy <- d
}
continue
}
if e.EventType != nvml.EventTypeXidCriticalError {
klog.Infof("Skipping non-nvmlEventTypeXidCriticalError event: %+v", e)
continue
}
if skippedXids[e.EventData] {
klog.Infof("Skipping event %+v", e)
continue
}
klog.Infof("Processing event %+v", e)
eventUUID, ret := e.Device.GetUUID()
if ret != nvml.SUCCESS {
// If we cannot reliably determine the device UUID, we mark all devices as unhealthy.
klog.Infof("Failed to determine uuid for event %v: %v; Marking all devices as unhealthy.", e, ret)
for _, d := range devices {
unhealthy <- d
}
continue
}
d, exists := parentToDeviceMap[eventUUID]
if !exists {
klog.Infof("Ignoring event for unexpected device: %v", eventUUID)
continue
}
if d.IsMigDevice() && e.GpuInstanceId != 0xFFFFFFFF && e.ComputeInstanceId != 0xFFFFFFFF {
gi := deviceIDToGiMap[d.ID]
ci := deviceIDToCiMap[d.ID]
if !(uint32(gi) == e.GpuInstanceId && uint32(ci) == e.ComputeInstanceId) {
continue
}
klog.Infof("Event for mig device %v (gi=%v, ci=%v)", d.ID, gi, ci)
}
klog.Infof("XidCriticalError: Xid=%d on Device=%s; marking device as unhealthy.", e.EventData, d.ID)
unhealthy <- d
}
}
2.5 ListAndWatch
ListAndWatch负责向kubelet上报设备健康状态的方法,实现逻辑如下,逻辑比较简单:先调用s.Send通过gRPC长连接向kubelet上报当前插件类型所有设备信息,之后监听plugin.health,而plugin.health来源于前文的健康检查。当从plugin.health收到有设备异常的消息后,会立刻调用s.Send向kubelet上报该信息。
// k8s-device-plugin/internal/plugin/server.go
// ListAndWatch lists devices and update that list according to the health status
func (plugin *NvidiaDevicePlugin) ListAndWatch(e *pluginapi.Empty, s pluginapi.DevicePlugin_ListAndWatchServer) error {
if err := s.Send(&pluginapi.ListAndWatchResponse{Devices: plugin.apiDevices()}); err != nil {
return err
}
for {
select {
case <-plugin.stop:
return nil
case d := <-plugin.health:
// FIXME: there is no way to recover from the Unhealthy state.
d.Health = pluginapi.Unhealthy
klog.Infof("'%s' device marked unhealthy: %s", plugin.rm.Resource(), d.ID)
if err := s.Send(&pluginapi.ListAndWatchResponse{Devices: plugin.apiDevices()}); err != nil {
return nil
}
}
}
}
2.6 Allocate
Allocate作为kubelet创建pod容器时分配设备资源调用的方法,实现逻辑如下:
// k8s-device-plugin/internal/plugin/server.go
// Allocate which return list of devices.
func (plugin *NvidiaDevicePlugin) Allocate(ctx context.Context, reqs *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
responses := pluginapi.AllocateResponse{}
for _, req := range reqs.ContainerRequests {
if err := plugin.rm.ValidateRequest(req.DevicesIDs); err != nil {
return nil, fmt.Errorf("invalid allocation request for %q: %w", plugin.rm.Resource(), err)
}
response, err := plugin.getAllocateResponse(req.DevicesIDs)
if err != nil {
return nil, fmt.Errorf("failed to get allocate response: %v", err)
}
responses.ContainerResponses = append(responses.ContainerResponses, response)
}
return &responses, nil
}
// k8s-device-plugin/internal/plugin/server.go
func (plugin *NvidiaDevicePlugin) getAllocateResponse(requestIds []string) (*pluginapi.ContainerAllocateResponse, error) {
deviceIDs := plugin.deviceIDsFromAnnotatedDeviceIDs(requestIds)
// Create an empty response that will be updated as required below.
response := &pluginapi.ContainerAllocateResponse{
Envs: make(map[string]string),
}
if plugin.deviceListStrategies.AnyCDIEnabled() {
responseID := uuid.New().String()
if err := plugin.updateResponseForCDI(response, responseID, deviceIDs...); err != nil {
return nil, fmt.Errorf("failed to get allocate response for CDI: %v", err)
}
}
if plugin.config.Sharing.SharingStrategy() == spec.SharingStrategyMPS {
plugin.updateResponseForMPS(response)
}
// The following modifications are only made if at least one non-CDI device
// list strategy is selected.
if plugin.deviceListStrategies.AllCDIEnabled() {
return response, nil
}
if plugin.deviceListStrategies.Includes(spec.DeviceListStrategyEnvvar) {
plugin.updateResponseForDeviceListEnvvar(response, deviceIDs...)
}
if plugin.deviceListStrategies.Includes(spec.DeviceListStrategyVolumeMounts) {
plugin.updateResponseForDeviceMounts(response, deviceIDs...)
}
if *plugin.config.Flags.Plugin.PassDeviceSpecs {
response.Devices = append(response.Devices, plugin.apiDeviceSpecs(*plugin.config.Flags.NvidiaDevRoot, requestIds)...)
}
if *plugin.config.Flags.GDSEnabled {
response.Envs["NVIDIA_GDS"] = "enabled"
}
if *plugin.config.Flags.MOFEDEnabled {
response.Envs["NVIDIA_MOFED"] = "enabled"
}
return response, nil
}
getAllocateResponse是nvidia k8s-device-plugin的核心函数,它负责根据Pod的GPU资源请求生成容器级别的设备分配响应。其核心作用是将GPU设备的物理资源映射到容器的运行时环境中,确保容器能正确访问分配的GPU。代码逐段解析:
1)设备 ID 转换
deviceIDs := plugin.deviceIDsFromAnnotatedDeviceIDs(requestIds)
作用:将Kubernetes传递的抽象设备请求ID(如GPU-fef8089b)转换为实际的物理设备ID(如0表示第0号GPU)
输入:requestIds来自Kubelet的AllocateRequest
输出:物理设备ID列表(例如 [“0”, “1”])
2)响应体初始化
response := &pluginapi.ContainerAllocateResponse{
Envs: make(map[string]string),
}
作用:创建空的响应对象,后续逐步填充环境变量、设备挂载等信息
3)CDI(Container Device Interface)处理
if plugin.deviceListStrategies.AnyCDIEnabled() {
responseID := uuid.New().String()
plugin.updateResponseForCDI(response, responseID, deviceIDs...)
}
CDI是什么:新一代容器设备接口标准,替代传统的环境变量/Volume挂载方式
关键行为:生成唯一响应ID(用于审计追踪);将设备信息按CDI规范注入响应(生成cdi.k8s.io/<device>=<cdi-device-name>注解);
4)MPS(Multi-Process Service)支持
if plugin.config.Sharing.SharingStrategy() == spec.SharingStrategyMPS {
plugin.updateResponseForMPS(response)
}
MPS作用:允许多个进程共享同一GPU的算力
注入内容:设置NVIDIA_MPS_ENABLED=1;挂载MPS控制目录(如/var/run/nvidia/mps)
5)传统设备列表策略处理
// 环境变量模式(默认启用)
if plugin.deviceListStrategies.Includes(spec.DeviceListStrategyEnvvar) {
response.Envs["NVIDIA_VISIBLE_DEVICES"] = strings.Join(deviceIDs, ",")
}
// Volume 挂载模式(已废弃)
if plugin.deviceListStrategies.Includes(spec.DeviceListStrategyVolumeMounts) {
response.Mounts = append(response.Mounts, &pluginapi.Mount{
ContainerPath: "/var/run/nvidia-container-devices",
HostPath: plugin.deviceListAsVolumeMounts(deviceIDs),
})
}
环境变量模式:设置NVIDIA_VISIBLE_DEVICES=0,1,由nvidia-container-runtime根据该变量挂载设备
Volume挂载模式:旧版本兼容方式,通过文件传递设备列表(现已被CDI取代)
6)设备规格透传
if *plugin.config.Flags.Plugin.PassDeviceSpecs {
response.Devices = append(response.Devices, plugin.apiDeviceSpecs(...))
}
作用:将GPU设备文件(如/dev/nvidia0)直接暴露给容器
典型场景:需要直接访问GPU设备文件的特殊应用
7)高级功能标记
// GPU 直接存储(GDS)
if *plugin.config.Flags.GDSEnabled {
response.Envs["NVIDIA_GDS"] = "enabled"
}
// Mellanox 网络加速(MOFED)
if *plugin.config.Flags.MOFEDEnabled {
response.Envs["NVIDIA_MOFED"] = "enabled"
}
GDS:启用GPU直接访问存储的能力(需硬件支持)
MOFED:集成Mellanox网络加速库(用于RDMA场景)
总结起来该函数实现了GPU资源的多维度适配:
- 兼容性:同时支持CDI 新标准和传统环境变量模式
- 灵活性:通过策略开关支持不同共享策略(MPS/Time-Slicing)
- 扩展性:可扩展注入GDS/MOFED等高级功能
- 安全性:通过设备ID转换实现物理资源到逻辑资源的映射隔离
三、部署实践
3.1 环境配置
在安装部署前先介绍下我本地环境:
- 运行环境
windows WSL ubuntu22.04
$ uname -a
Linux DESKTOP-72RD6OV 5.15.167.4-microsoft-standard-WSL2 #1 SMP Tue Nov 5 00:21:55 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux
- k8s信息
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.7", GitCommit:"b56e432f2191419647a6a13b9f5867801850f969", GitTreeState:"clean", BuildDate:"2022-02-16T11:50:27Z", GoVersion:"go1.16.14", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.7", GitCommit:"b56e432f2191419647a6a13b9f5867801850f969", GitTreeState:"clean", BuildDate:"2022-02-16T11:43:55Z", GoVersion:"go1.16.14", Compiler:"gc", Platform:"linux/amd64"}
$ kubectl get node
NAME STATUS ROLES AGE VERSION
desktop-72rd6ov Ready control-plane,master 333d v1.22.7
$ kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-bpxfq 1/1 Running 41 (133m ago) 333d
kube-system coredns-7f6cbbb7b8-lqfrh 1/1 Running 39 (132m ago) 333d
kube-system coredns-7f6cbbb7b8-n4snt 1/1 Running 39 (132m ago) 333d
kube-system etcd-desktop-72rd6ov 1/1 Running 41 (133m ago) 333d
kube-system kube-apiserver-desktop-72rd6ov 1/1 Running 41 (132m ago) 333d
kube-system kube-controller-manager-desktop-72rd6ov 1/1 Running 40 (133m ago) 333d
kube-system kube-proxy-rtjfm 1/1 Running 38 (133m ago) 333d
kube-system kube-scheduler-desktop-72rd6ov 1/1 Running 42 (132m ago) 333d
- 容器运行时
$ kubectl describe node desktop-72rd6ov | grep 'Container Runtime Version'
Container Runtime Version: docker://26.0.0
- GPU设备与cuda
GPU:NVIDIA GeForce RTX4060Ti,16G显存
cuda:12.6
$ nvidia-smi
Sat Mar 8 10:20:00 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.02 Driver Version: 560.94 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 Ti On | 00000000:01:00.0 On | N/A |
| 0% 32C P8 8W / 165W | 954MiB / 16380MiB | 9% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 33 G /Xwayland N/A |
+-----------------------------------------------------------------------------------------+
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Tue_Oct_29_23:50:19_PDT_2024
Cuda compilation tools, release 12.6, V12.6.85
Build cuda_12.6.r12.6/compiler.35059454_0
3.2 安装部署
3.2.1 安装nvidia-container-toolkit
nvidia-container-toolkit官网:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/index.html
官方安装流程:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
国内可使用国内镜像源安装,也是本文的安装方法:
- 下载中国科技大学(USTC)镜像gpgkey
curl -fsSL https://mirrors.ustc.edu.cn/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
- 配置中国科技大学(USTC)镜像APT源
curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://nvidia.github.io#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://mirrors.ustc.edu.cn#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
- 更新APT包列表
sudo apt-get update
- 安装NVIDIA Container Toolkit
sudo apt-get install -y nvidia-container-toolkit
- 验证安装
$ nvidia-container-cli --version
cli-version: 1.17.4
lib-version: 1.17.4
build date: 2025-01-23T10:53+00:00
build revision: f23e5e55ea27b3680aef363436d4bcf7659e0bfc
build compiler: x86_64-linux-gnu-gcc-7 7.5.0
build platform: x86_64
build flags: -D_GNU_SOURCE -D_FORTIFY_SOURCE=2 -DNDEBUG -std=gnu11 -O2 -g -fdata-sections -ffunction-sections -fplan9-extensions -fstack-protector -fno-strict-aliasing -fvisibility=hidden -Wall -Wextra -Wcast-align -Wpointer-arith -Wmissing-prototypes -Wnonnull -Wwrite-strings -Wlogical-op -Wformat=2 -Wmissing-format-attribute -Winit-self -Wshadow -Wstrict-prototypes -Wunreachable-code -Wconversion -Wsign-conversion -Wno-unknown-warning-option -Wno-format-extra-args -Wno-gnu-alignof-expression -Wl,-zrelro -Wl,-znow -Wl,-zdefs -Wl,--gc-sections
// 输入后按tab键
$ nvidia-
nvidia-cdi-hook nvidia-container-cli nvidia-container-runtime nvidia-container-runtime-hook nvidia-container-toolkit nvidia-ctk nvidia-pcc.exe nvidia-smi nvidia-smi.exe
$ whereis nvidia-container-runtime
nvidia-container-runtime: /usr/bin/nvidia-container-runtime /etc/nvidia-container-runtime
- 修改docker配置
新版本执行以下命令配置/etc/docker/daemon.json使用nvidia的runtime:
$ sudo nvidia-ctk runtime configure --runtime=docker
INFO[0000] Loading config from /etc/docker/daemon.json
INFO[0000] Wrote updated config to /etc/docker/daemon.json
INFO[0000] It is recommended that docker daemon be restarted.
$ cat /etc/docker/daemon.json
{
"default-runtime": "nvidia", # 注意一定要有这一行
"registry-mirrors": [
"https://hub-mirror.c.163.com",
"https://ustc-edu-cn.mirror.aliyuncs.com",
"https://ghcr.io",
"https://mirror.baidubce.com"
],
"runtimes": { # 注意一定要有这一个配置
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
}
- 重启docker
$ sudo systemctl restart docker
$ docker info | grep -i runtime
Runtimes: nvidia runc io.containerd.runc.v2
Default Runtime: runc
$ docker info | grep -i runtime
Runtimes: io.containerd.runc.v2 nvidia runc
Default Runtime: nvidia
- 验证
$ docker run --rm --gpus all nvcr.io/nvidia/cuda:12.2.0-runtime-ubuntu22.04 nvidia-smi
==========
== CUDA ==
==========
CUDA Version 12.2.0
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Sat Mar 8 06:26:38 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.02 Driver Version: 560.94 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 Ti On | 00000000:01:00.0 On | N/A |
| 0% 34C P8 8W / 165W | 1162MiB / 16380MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 33 G /Xwayland N/A |
+-----------------------------------------------------------------------------------------+
3.2.2 安装nvidia k8s-device-plugin
执行以下命令安装k8s-device-plugin@v0.16.2(官网yaml:https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.16.2/deployments/static/nvidia-device-plugin.yml):
$ kubectl apply -f - <<EOF
# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
name: nvidia-device-plugin-ds
spec:
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- effect: NoSchedule # 由于我只有一个master节点,该节点打了污点,因此需要加上这个容忍,否则无法调度pod
key: node-role.kubernetes.io/master
operator: Exists
# Mark this pod as a critical add-on; when enabled, the critical add-on
# scheduler reserves resources for critical add-on pods so that they can
# be rescheduled after a failure.
# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/
priorityClassName: "system-node-critical"
containers:
- image: nvcr.io/nvidia/k8s-device-plugin:v0.16.2
name: nvidia-device-plugin-ctr
env:
- name: FAIL_ON_INIT_ERROR
value: "false"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
EOF
检查daemonset:
$ kubectl -n kube-system get ds nvidia-device-plugin-daemonset
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
nvidia-device-plugin-daemonset 1 1 0 1 0 <none> 38m
$ kubectl -n kube-system get pod nvidia-device-plugin-daemonset-jl6nc -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nvidia-device-plugin-daemonset-jl6nc 1/1 Running 0 78s 10.244.0.80 desktop-72rd6ov <none> <none>
$ kubectl -n kube-system logs nvidia-device-plugin-daemonset-jl6nc
I0310 11:30:39.696659 1 main.go:199] Starting FS watcher.
I0310 11:30:39.696723 1 main.go:206] Starting OS watcher.
I0310 11:30:39.697075 1 main.go:221] Starting Plugins.
I0310 11:30:39.697092 1 main.go:278] Loading configuration.
I0310 11:30:39.699210 1 main.go:303] Updating config with default resource matching patterns.
I0310 11:30:39.699332 1 main.go:314]
Running with config:
{
"version": "v1",
"flags": {
"migStrategy": "none",
"failOnInitError": false,
"mpsRoot": "",
"nvidiaDriverRoot": "/",
"nvidiaDevRoot": "/",
"gdsEnabled": false,
"mofedEnabled": false,
"useNodeFeatureAPI": null,
"deviceDiscoveryStrategy": "auto",
"plugin": {
"passDeviceSpecs": false,
"deviceListStrategy": [
"envvar"
],
"deviceIDStrategy": "uuid",
"cdiAnnotationPrefix": "cdi.k8s.io/",
"nvidiaCTKPath": "/usr/bin/nvidia-ctk",
"containerDriverRoot": "/driver-root"
}
},
"resources": {
"gpus": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
]
},
"sharing": {
"timeSlicing": {}
}
}
I0310 11:30:39.699348 1 main.go:317] Retrieving plugins.
I0310 11:30:39.729583 1 server.go:216] Starting GRPC server for 'nvidia.com/gpu'
I0310 11:30:39.729982 1 server.go:147] Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
I0310 11:30:39.730798 1 server.go:154] Registered device plugin for 'nvidia.com/gpu' with Kubelet
到这里其实就部署成功了,查看节点信息验证一下:
$ kubectl get node
NAME STATUS ROLES AGE VERSION
desktop-72rd6ov Ready control-plane,master 334d v1.22.7
$ kubectl get node desktop-72rd6ov -oyaml
...
status:
...
allocatable:
cpu: "16"
ephemeral-storage: "972991057538"
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 16146768Ki
nvidia.com/gpu: "1" # 上报上来的GPU数据
pods: "110"
capacity:
cpu: "16"
ephemeral-storage: 1055762868Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 16249168Ki
nvidia.com/gpu: "1" # 上报上来的GPU数据
pods: "110"
3.3 k8s调度GPU功能验证
准备如下pod:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/cuda:12.2.0-runtime-ubuntu22.04
imagePullPolicy: IfNotPresent
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
securityContext:
capabilities:
add: ["SYS_ADMIN"]
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- effect: NoSchedule # 由于我只有一个master节点,该节点打了污点,因此需要加上这个容忍,否则无法调度pod
key: node-role.kubernetes.io/master
operator: Exists
apply该yaml并查看pod日志:
$ kubectl apply -f pod.yaml
pod/gpu-pod created
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gpu-pod 0/1 Completed 0 5s 10.244.0.127 desktop-72rd6ov <none> <none>
$ kubectl logs gpu-pod
Mon Mar 10 11:35:13 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.02 Driver Version: 560.94 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 Ti On | 00000000:01:00.0 On | N/A |
| 0% 38C P8 7W / 165W | 1058MiB / 16380MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 33 G /Xwayland N/A |
+-----------------------------------------------------------------------------------------+