A hybrid of transformer and CNN for efficient single image super-resolution via multi-level distillation
(基于transform和CNN的多级蒸馏单幅图像超分辨率算法)
近年来,基于卷积神经网络(CNN)的单幅图像超分辨率(SISR)模型取得了显著进展,并逐渐成为主流方法。然而,它们仍然遭受高计算成本、大量存储器消耗和有限的感受域。视觉变换虽然具有更强的建模能力和更大的接收域,但也带来了较高的计算能力消耗和内存占用。为了解决这些问题,提出了一种Transformer和CNN的混合网络,该网络具有级联的特征提取模块,可实现高效的图像超分辨率(TCPDN)。TCPDN既能利用局部信息,又能利用长期交互作用,同时具有足够的灵活性。具体,TCFDN包括级联蒸馏Transformer-CNN功能块(TCFDB)和一个upsampling模块。TCFDB的特征提取流水线可以帮助我们的模型逐步学习具有更好表示能力的精细特征,同时保持轻量级。此外,我们还设计了一个改进的Swin Transformer层(ESTL),将标准Transformer中的多层感知器(MLP)替换为卷积前馈层(CFF),使其更适合于SR任务。然后,嵌入到TCFDB中的增强的空间注意力可以进一步提高SR性能。此外,我们观察到使用更高级的损失函数,即,对比度损失也可以带来0.01dB-0.03dB的公共基准上的PSNR增益。大量实验表明,TCPDN在性能和模型大小之间取得了较好的平衡,优于现有的方法。在公共基准Urban100上的4X SR任务下,我们的TCPDN在PSNR方面比第二好的模型性能好0.37 dB。与其他最先进的方法相比,TCPDN中的参数总数可以减少多达32%,同时保持有竞争力的性能。
介绍
单幅图像超分辨率(SISR)是计算机视觉领域的经典课题之一。它的目标是从低分辨率(LR)图像恢复高分辨率(HR)图像。SR是不适定问题,因为LR图像可以从许多HR图像降级。由于随机共振可以从低质量图像中恢复高频细节和纹理信息,因此在遥感、医学照片、监控图像和旧图像增强等方面有着广泛的应用。
近年来,各种基于卷积神经网络(CNN)的算法被提出并取得了显著的性能。它们不断刷新SR记录,逐渐成为主流方法。为了进一步提高SR模型的性能,设计了许多复杂的结构,例如递归网络、密集连接和剩余连接。但是这些方法导致计算成本和存储器消耗的爆炸性增长,因此将它们应用于边缘设备是不切实际的。此外,基于CNN的模型存在两个固有问题。首先,基于CNN的模型使用相同的卷积核来处理不同的图像区域,这可能不是最佳选择。第二,基于神经网络的模型具有有限的接收域,因此它只依赖于局部信息进行恢复。然而,在恢复当前补丁时,图像的类似补丁可以提供附加细节。
因此,基于变换器的模型被引入到SR任务中,以捕获图像中的长期依赖性。Ashish等人提出在自然语言处理中使用Transformer架构。目前,它已广泛应用于目标检测、语义分割等计算机视觉领域。Transformer设计了一种自我注意机制来捕捉图像上下文之间的长期交互,因此理论上它具有全局感受野。最近,Liu等人在Swin Transformer中引入了移窗和跨窗操作,其优于其他最先进的(SOTA)SR方法。虽然Swin Transformer的收敛速度与CNN模型相近,但仍存在模型规模大、计算量大等问题。
为了解决上述问题,提出了一种基于特征提取的轻量级单幅图像超分辨率的Transformer和CNN混合网络(TCFDN),该网络综合了Transformer和CNN的优点。当嵌入CNN时,基于Transformer的算法可以同时具有大的感受域、更高的模型灵活性和更快的收敛速度。我们还通过添加2D卷积层来增强标准Transformer中的前馈网络,使其更适合图像SR任务。此外,我们还采用SOTA方法中的特征蒸馏**(FD)机制来降低网络复杂度,提高建模效率**。FD可以帮助模型学习具有更好表示能力的精细特征,并且可以减少网络的总参数数。具体来说,给定输入LR图像,我们首先使用3 × 3卷积层来提取浅特征。3 × 3卷积层能很好地处理早期的粗糙特征,并将RGB空间映射到高维特征空间。然后,我们使用Transformer-CNN特征提取块(即,TCFDB)来逐渐细化粗糙特征。级联TCFDB通过多层次特征提取和残差连接,在保持模型小尺寸的同时,学习到更多有区别的特征。最后,上采样模块由3 × 3卷积层和像素混洗层组成。浅特征和提取特征都通过剩余连接馈送到上采样模块。为了进一步提高其性能,我们建议采用对比的损失。大量实验证明TCFDN优于方面的最先进的方法更好的超分辨率的性能和模型的复杂性之间的权衡。
贡献
1)提出了一种基于Transformer和CNN的混合网络实现单幅图像超分辨率。与其他轻量级SOTA方法相比,该方法以较少的参数获得了更好的性能。
2)我们提出了Transformer-CNN特征提取块(即,TCFDB),通过多层次特征提取,逐步获取更具区分性的特征。同时,它可以使我们的模型更加轻量级和灵活。
3)嵌入卷积前馈网络(CFF),设计了更适合SR任务的增强Swin Transformer层(ESTL)。
4)我们观察到,使用Transformer和CNN的混合网络的对比损耗也可以带来公共基准上的PSNR增益。
相关工作
CNN-based models and feature distillation
CNN-based models
在Transformer应用于计算机视觉任务之前,基于神经网络的算法是图像SR任务的主流方法。使用CNN来超级解析图像的最重要的工作是SRCNN。首先,将LR图像内插到高分辨率空间,并使用卷积层进行特征提取。然后,它使用激活层进行非线性映射。虽然SRCNN是轻量级的,但是它依赖于小区域的信息,并且训练过程收敛太慢。VDSR在SRCNN的基础上,加深了网络以扩大感受野,并引入残差网络以防止细节丢失。残差网络有助于缓解消失/爆炸梯度,这是深度学习的一个突破。EDSR 去除了残差网络的批归一化(BN)层以提高SR性能。RDN 引入了基于EDSR的密集连接,以充分利用所有之前的功能。
Feature distillation
由于计算能力和存储空间的高成本,这些复杂的模型无法在边缘设备上实现,从而限制了它们的实际应用。在这种情况下,研究者开始考虑更轻量级的SR模型。Hu等人提出了IDN,其具有轻量级的参数大小和较低的计算复杂度。Hui等人在IDN的基础上引入了通道分裂操作、多级蒸馏操作和对比度通道注意,在视觉质量、推理速度和内存占用之间取得了很好的平衡。RFDN 使用特征提取连接设计了一个更加轻量级的网络。此外,Jie等人提出了浅残差块(SRB)以进一步改善SR性能。我们还采用了特征提取机制来学习代表性特征,保持网络的轻量化。
Transformer-based models
Transformer 首先在自然语言处理(NLP)领域取得了重大突破。最近,基于变换器的模型已经显示出显著的改进,并且在各种度量上优于基于CNN的模型。Transformer的核心是自我注意机制,它被认为具有映射令牌之间长期交互的能力。Vision Transformer通常会将图像分割成不重叠的2D面片,然后将其展平为1D标记。Dosovitskiy等人是第一个在SR中用Transformer结构代替CNN结构的工作,先将图像分割成不重叠的2D面片。然后将每个面片转换为1D令牌并馈送到Transformer。然而,在块之外的边界像素不能用于图像恢复,这可能在每个块周围引入边界伪像。IPT由多个头部和多个尾部组成。不同的头部和尾部可以处理不同的任务,并与主体共享相同的Transformer结构。SwinIR 采用Swin变压器作为主干,并实现SOTA性能。该算法采用由多个残差Swin变换块(residual Swin Transformer block,RSTB)组成的深度特征提取模块来提取深度特征。所提出的Transformer-CNN特征提取模块也充分利用了Swin Transformer层。
方法
Network architecture
如图2所示,我们提出的网络由三部分组成:1)浅层特征提取模块,2)深层特征提取模块,以及3)高分辨率重建模块。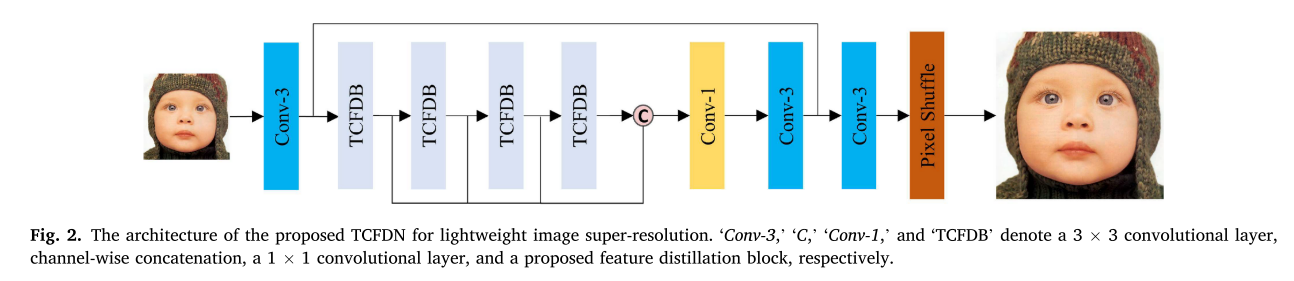
Shallow feature extraction
该模块是提出的网络的头部,主要用于提取粗特征和将RGB空间映射到高维特征空间。给定低分辨率图像ILR ∈
R
H
×
W
×
3
R^{H×W×3}
RH×W×3,H和W分别表示RGB图像的高度和宽度。初始3 × 3卷积层表示为HSF(·),粗糙特征表示为F0 ∈
R
H
×
W
×
C
R^{H×W×C}
RH×W×C,其中C表示特征通道数。因此,浅层特征提取网络可以表示为
Deep feature distillation
深度特征提取模块是模型的核心部分,由一叠Transformer-CNN特征提取模块(TCFDB)组成。此外,我们对前馈网络做了一些改动(即:MLP),并构建了增强型Swin transformer层(ESTL)。TCFDB由ESTL和卷积层组成。每个TCFDB都有两个特征传播路径。一条路径用于特征蒸馏操作,另一条路径用于渐进特征精化操作。然后,使用1 ×1卷积层将两个输出级联。因此,从F0提取的深度特征可以表示为
Super-resolution reconstruction module
它利用浅层特征和深层特征来重建高分辨率图像。超分辨图像ISR被重建为
其中Up(⋅)是上采样重建的函数。浅层特征包含丰富的低频图像信息,而深层特征包含精细的高频图像信息。多层次特征提取机制可以引导网络学习更多有代表性的特征,同时保持网络的轻量化。
Transformer-CNN feature distillation block
提出的特征提取模块(TCFDB)由CNN和增强Swin Transformer 层(ESTL)、卷积层和增强空间注意力的混合网络组成。框架如图3所示。该模块的核心思想是让EST逐步提取代表能力较强的特征。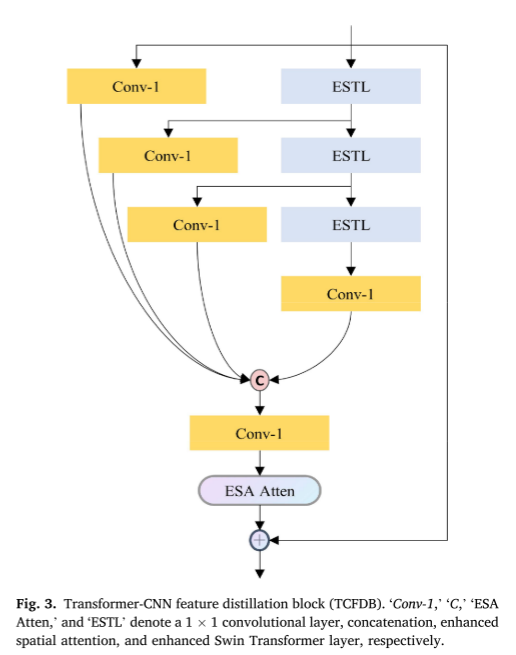
Feature distillation and refinement pipeline
TCFDB包含两条流水线,即:其特征在于蒸馏和精制管道。中间特征被并行地馈送到两个管道中。左边的1 × 1卷积层负责提取特征和减少具有少量参数的通道。右边是级联的EST,它可以关注空间背景,逐渐提炼特征,以获得更具区分力的信息。此外,我们还通过在标准Transformer层的前馈网络中增加卷积层来增强标准Transformer层。给定输入特征Fin,TCFDB可表示为

然后,将不同操作迭代的所有提取特征连接在一起。最后,在TCFDB中增加了1 × 1卷积层和增强的空间注意层。TCFDB的输出公式为
Enhanced Swin Transformer layer (ESTL)
The standard transformer layer.
用于低级视觉任务的标准transformer(例如:视觉transformer)包括层规格化(即,LN),多头自我注意(即,MSA),以及前馈网络(即,FFN)。由于MSA的计算复杂度是图像大小的二次方,因此将标准Transformer直接应用于轻量级SR任务是不切实际的。
Swin transformer layer.
我们采用窗口多头自注意和移动窗口多头自注意(即,W-MSA和SW-MSA)。W-MSA将自我注意力的计算限制在单个窗口。它不仅可以加快运算速度,而且可以减少内存的消耗。然而,W-MSA本身缺乏跨不同窗口的连接,这限制了它的建模能力。如果仅使用W-MSA,则窗口外的边界像素不能用于图像重建,这可能在每个窗口周围引入边界伪影。因此,我们将SW-MSA和W-MSA作为一对,使不同的窗口能够相互交互,以了解长期依赖性,这也有助于消除边界伪影。此外,我们用CFF代替了MLP。其结构如图4所示。
Tensor reshape operation.
输入CNN的特征应保持H × W × C的形状(H × W表示二维空间特征,C表示通道数)。对于Transformer,形状应类似于HW × C(HW表示1D展平特征,即:令牌)。由于Transformer和CNN可以处理的数据形状不同,我们嵌入了张量重排操作来重塑网络中的数据。
给定一个大小为H ×W × C(F0 ∈
R
H
×
W
×
C
R^{H×W×C}
RH×W×C)的输入,ESTL首先将其划分为互不重叠的局部窗口HW/
M
2
M^2
M2 ×
M
2
M^2
M2 × C,其中M为窗口大小,HW/
M
2
M^2
M2为窗口总数。然后,ESTL分别计算每个窗口的标准自我注意,即:它使用Fw ∈
M
2
M^2
M2 × C的标记来计算MSA。
Convolutional feed-forward network (CFF).
在普通 transformer 中,MSA的输出直接馈入前馈网络(FFN),该前馈网络是使用多层感知器(MLP)的全连接层(FC)。FC层捕获2D空间信息的能力有限,而超分辨率任务主要取决于2D图像背景。为了解决这个问题,我们在FFN中加入了卷积层来构造CFF,以提高对SR任务的性能。具体地说,我们首先使用一个完全连通的层来将记号投影到更高的维度,并将1D记号重新塑造成2D(类似于图像)特征地图。然后,使用3 × 3深度方向卷积层来捕获2D特征地图中的局部空间信息。最后,中间特征被展平到1D空间,并且随后的完全连通层将把扩展的令牌投影到其原始大小。ESTL的整个过程可表述为
Enhanced spatial attention block (ESA)
为了进一步提高SR性能,我们在ESTL之后添加了增强空间注意(ESA)模块,它比普通的1 × 1卷积层或3 × 3卷积层更强大。ESA模块在每个TCFDB的后部工作,引导模块聚焦于感兴趣的区域。其结构如图5所示。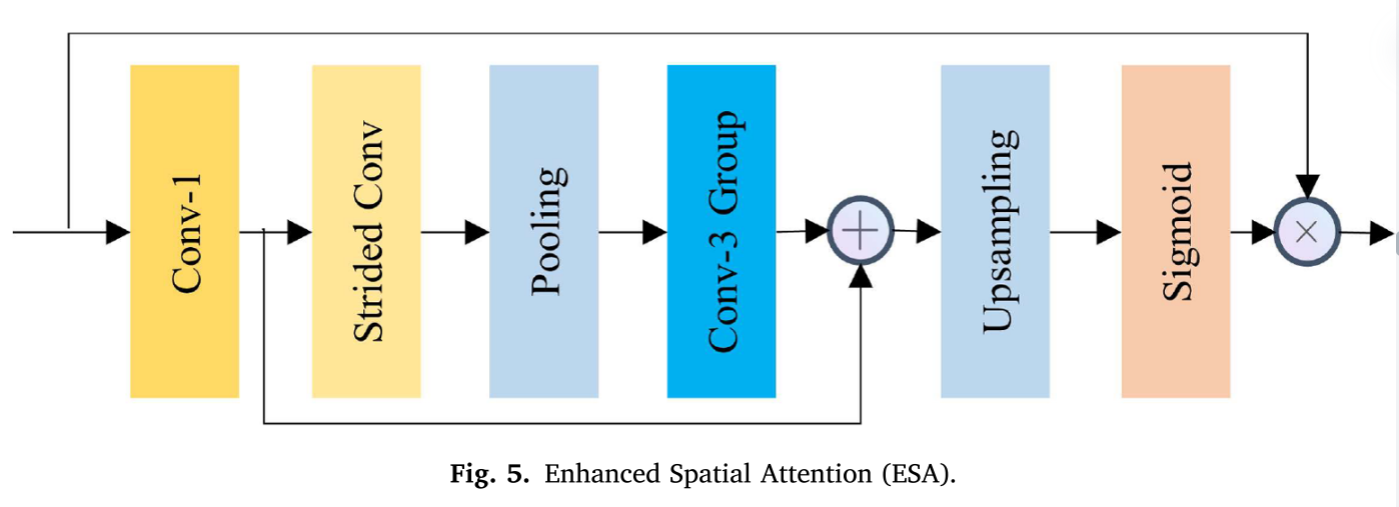
考虑到ESA模块的输入
F
e
s
a
F^{esa}
Fesai,它从1 × 1卷积层开始,以压缩功能和减少通道,使整个模块可以非常轻量级。该过程可表示为

其中
H
e
s
a
H^{esa}
Hesa1×1是初始1 × 1卷积层,
F
e
s
a
F^{esa}
Fesa1是压缩特征映射。然后,它使用一个步长卷积层
H
e
s
a
H^{esa}
Hesasc(⋅),接着是一个最大池层
H
e
s
a
H^{esa}
Hesap(⋅)来扩大感受野。随后的几个3 × 3卷积层
H
e
s
a
H^{esa}
Hesa3×3(⋅)用于进一步提取特征,如下所示:
其中
F
e
s
a
F^{esa}
Fesa2是更深的中间特征图。然后,我们使用插值上采样图层恢复要素地图的空间大小,以匹配输入
F
e
s
a
F^{esa}
Fesai。1 × 1卷积层还用于检索信道维度以匹配输入信道的数目。上采样和检索可以表示为
其中
H
e
s
a
H^{esa}
Hesaup(⋅)表示插值上采样层。最后,我们添加一个Sigmoid层来计算注意力屏蔽。我们还使用了一个残差连接,在空间或通道缩减之前直接将特征添加到块的末尾。每个ESA块
F
e
s
a
F^{esa}
Fesaout的输出可以公式化为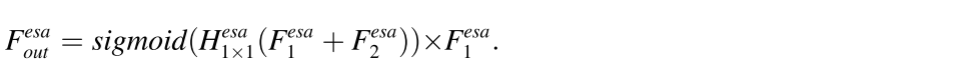
ESA块有助于扩大感受野并分配更合适的权值,这有利于图像SR重建。
Image reconstruction module
将来自先前模块的浅特征和深特征聚集在一起用于重构。这个过程可以表述为
其中Up(□)表示上采样重建,由一个3 × 3卷积层和一个亚像素层组成,ISR表示最终超分辨率图像。在亚像素层中,首先使用卷积层来增加LR特征图的通道。然后,执行整形操作(也称为周期性混洗算子)用于重新排列扩展特征图中的这些像素以获得HR输出。具体地说,给定输入大小H×W× C和缩放因子,首先将通道数扩展为
t
o
s
2
tos^2
tos2 × C,中间特征映射可以表示为H × W×
s
2
s^2
s2C。然后,执行周期性混洗操作以产生大小为H × sW× C的输出。
Loss function
L1 pixel loss
对于图像SR任务,我们通过最小化原始L1像素损失来优化TCPDN的参数。用于重建的像素损失Lrec可以公式表示为
Contrastive loss
我们使用它来提高SR性能在PSNR和SSIM方面。最近的工作提出了一种新的对比度损失,并通过提高重建图像的质量来证明其有效性。高层的想法是在表征空间中将积极(GT)推近锚点(SR),将消极(LR)推离锚点。换句话说,在对比度损失的情况下,在表示空间中超分辨率图像被拉得更靠近GT图像并且被推得远离低分辨率图像。使用结构简单的特征提取器来捕获感知细节并将图像转换到潜在空间。受上述参考文献的启发,我们使用两个3 × 3卷积层作为特征提取器,并且我们提出的网络的对比度损失被公式化为