接下来我们要来学习下自定义渲染管线中的合批,这一节主要学习SRP Batcher
每一次的Draw Call都需要CPU和GPU之间的通信,如果有大量的数据需要从CPU发送到GPU中,那GPU就可能因为等待数据而浪费时间,而CPU会因为忙于发送数据导致无法做其他的事情,所以这两个问题都会导致帧率的降低。在目前我们的做法有点粗暴,一个物体一个Draw Call,这是非常浪费时间的,只是目前我们发送的整体数据量较少,所以还感受不出问题。
我们可以用示例数字来说明这个问题。
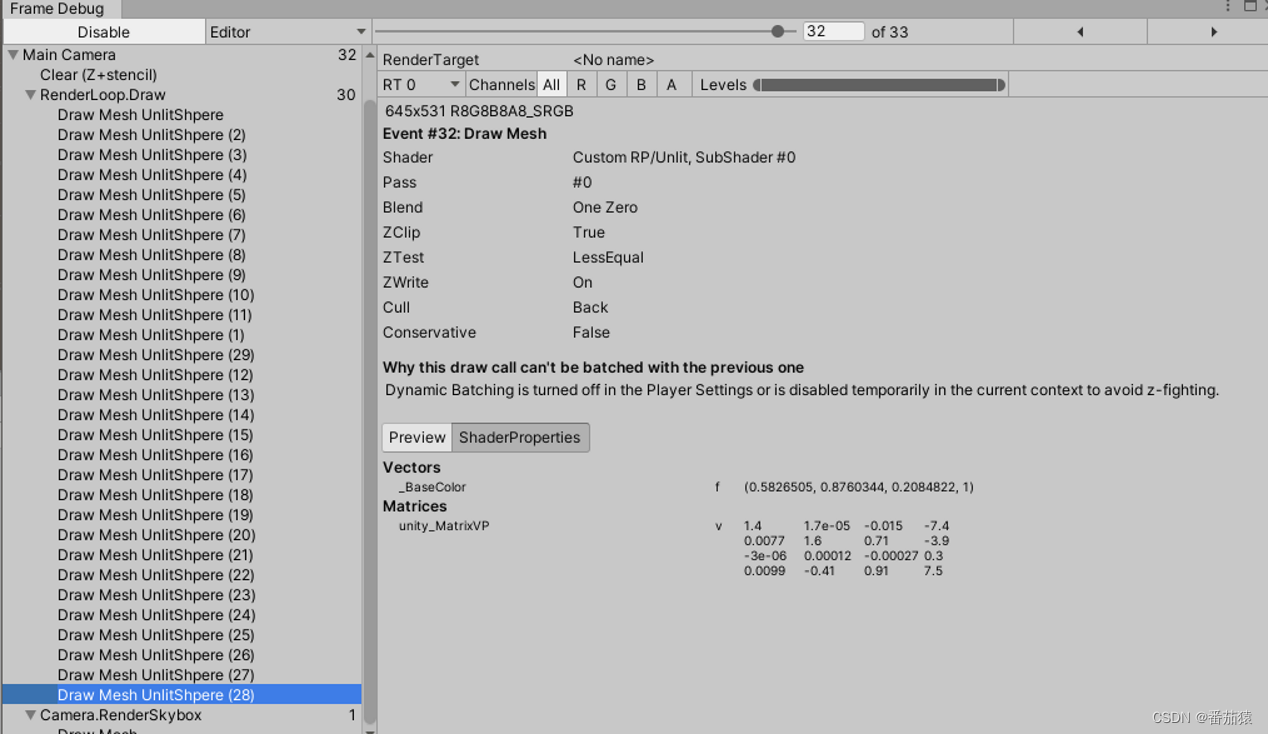
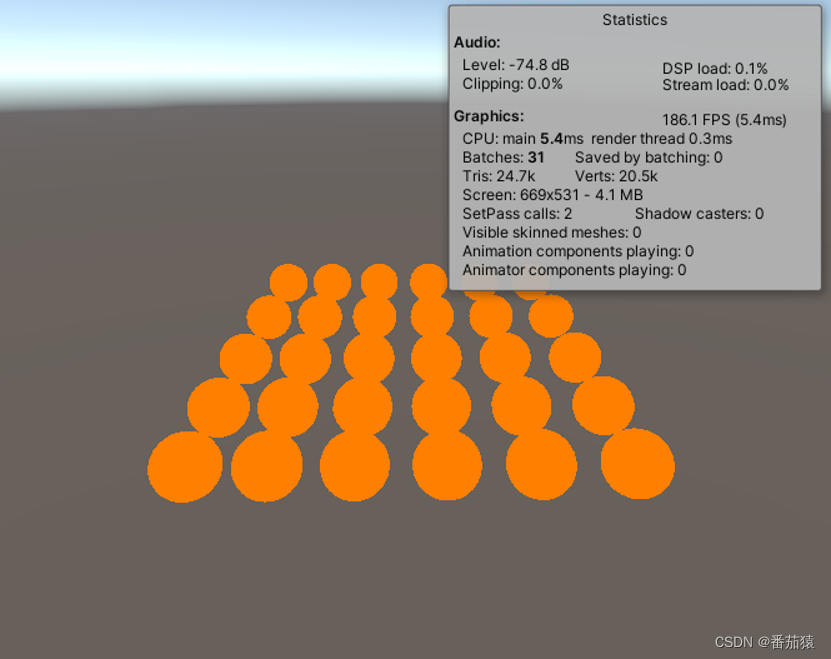
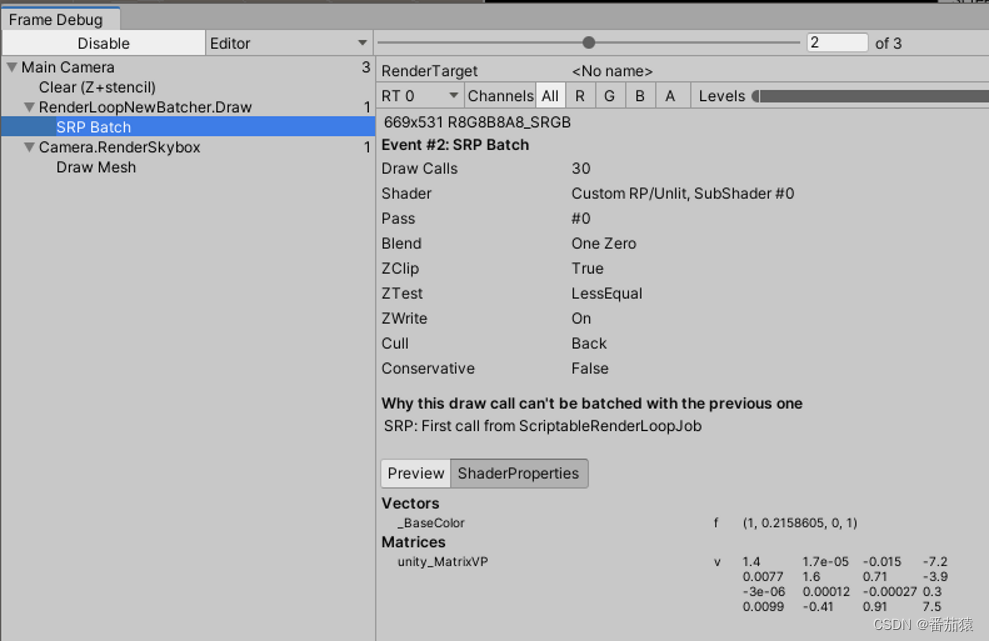
整三十个球,同样颜色,按以前的Unity肯定是能合批的,可是现在需要31个Draw Call,通过合批减少的DrawCall数量(Saved by batching)为0,其实就是天空盒一个,剩下的就是30个球的了。
(为什么Clear的DrawCall没了?哈哈,这就是我们之前做ClearRenderTarget的小优化,对于Skybox的Flag不用进行清理也是可以的,具体可以查看《自定义渲染管线基础学习》-”相机的ClearFlags“这一小节)
自定义渲染管线的合批
合批是合并Draw Call的过程,减少CPU和GPU之间的通信量。
在自定义管线中最简单的实现方法就是直接开启SRP Batcher,SRP Batcher实际上并不是直接减少Draw Call的数量,而是简化了流程,它将材质属性存储在GPU,所以不用每一次Draw Call都发送数据,这样子既能减少CPU和GPU之间的通信,也能减少CPU每一次Draw Call所要做的数据准备工作。这样也相当于减少了Draw Call的数量。
但是想要SRP Batcher生效,我们的Shader编写必须按照规范的统一结构来。
我们查看Shader的面板可以查看SRP Batcher的使用情况,发现有无法使用的提示,”属性没有定义在叫【UnityPerDraw】的cbuffer中“。cbuffer(constant buffer)。
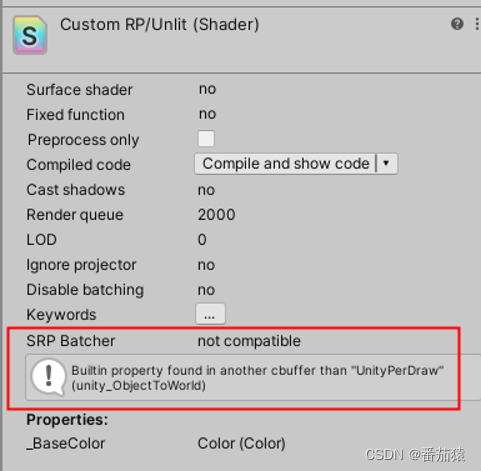
想要SRP Batcher生效,我们Shader中的所有材质属性不能像之前那样直接定义,必须放在固定的内存缓存中。
之前SRP Batcher不生效的写法
float4 _BaseColor;
我们查看Unlit的Shader,在上面可以看到提示SRP合批不适用的原因

标准写法
(但是在一些平台上无法支持cbuffer,比如OpenGL ES 2.0)
//使用cbuffer UnityPerMaterial 包起来才能使SRP Batcher生效
//但是在一些平台上无法支持cbuffer,比如OpenGL ES 2.0
cbuffer UnityPerMaterial
{
float4 _BaseColor; //用于Shader中定义颜色属性,名称需相同
};
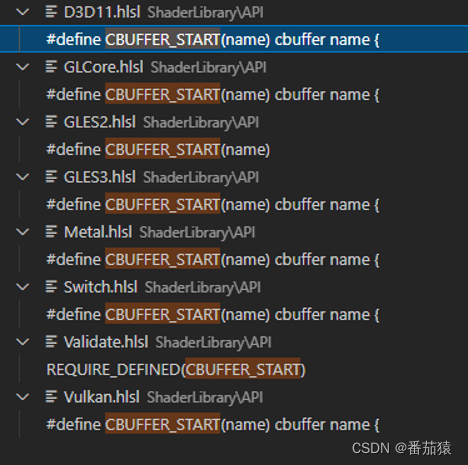
由于一些平台无法直接支持cbuffer
Core RP Library中通过CBUFFER_START和CBUFFER_END对此做了处理,因此我们可以使用这个来解决问题
使用需要include Common.hlsl
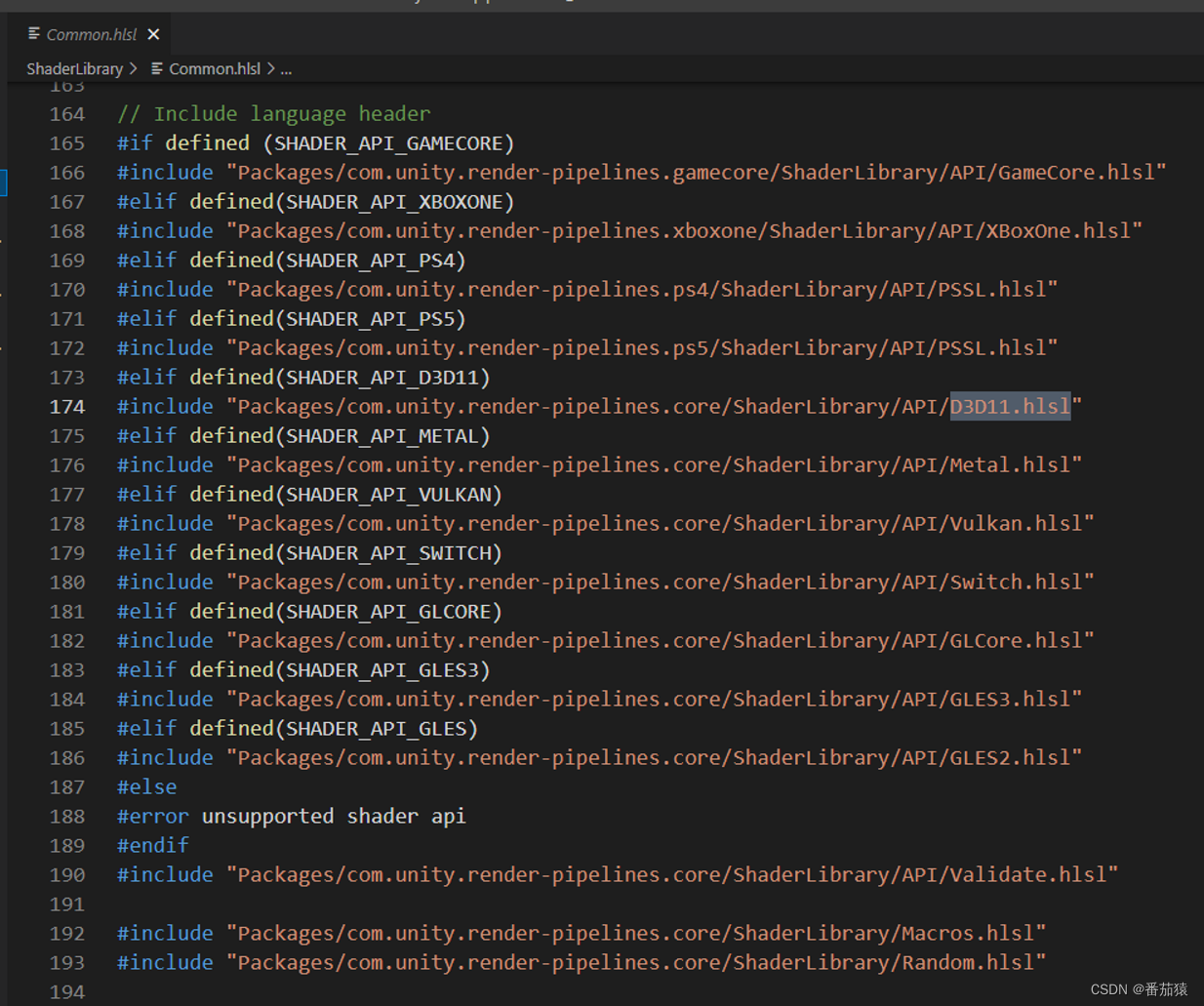
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/Common.hlsl"
最终写法
//CBUFFER_START和CBUFFER_END是CORE RP Library中对cbuffer做的处理,解决部分平台无法支持的问题
CBUFFER_START(UnityPerMaterial)
float4 _BaseColor;
CBUFFER_END
但仍然还有问题

我们还需要把别的变量也加到这里
CBUFFER_START(UnityPerDraw)
float4x4 unity_ObjectToWorld; //每一次绘制GPU设置这个值,然后在一次绘制中的顶点片元函数使用期间值不变
float4x4 unity_WorldToObject;
float4 unity_LODFade;
real4 unity_WorldTransformParams;
CBUFFER_END
然后CustomRenderPipeline.cs中开启SRP合批
public CustomRenderPipeline()
{
GraphicsSettings.useScriptableRenderPipelineBatching = true; //开启SRP合批
}
终于适用了

但不知道为什么我的面板还是没有变化

但是FrameDebuger里面已经可以看到效果了
我们可以看到SRP Batch
但我们可以看到上面显示着,Draw Calls 30,所以实际上SRP Batch并不是真正的合批,仍然会有30次Draw Calls,是减少了发送到GPU的数据量
到了这里我自己有点懵了
没用SRP之前的有合批么?
除了要勾静态的静态合批外,原来的动态合批是怎么回事?
动态合批需要在PlayerSetting中勾选Dynamic Batch功能,然后也有许多限制
但是它的合批是真的合批
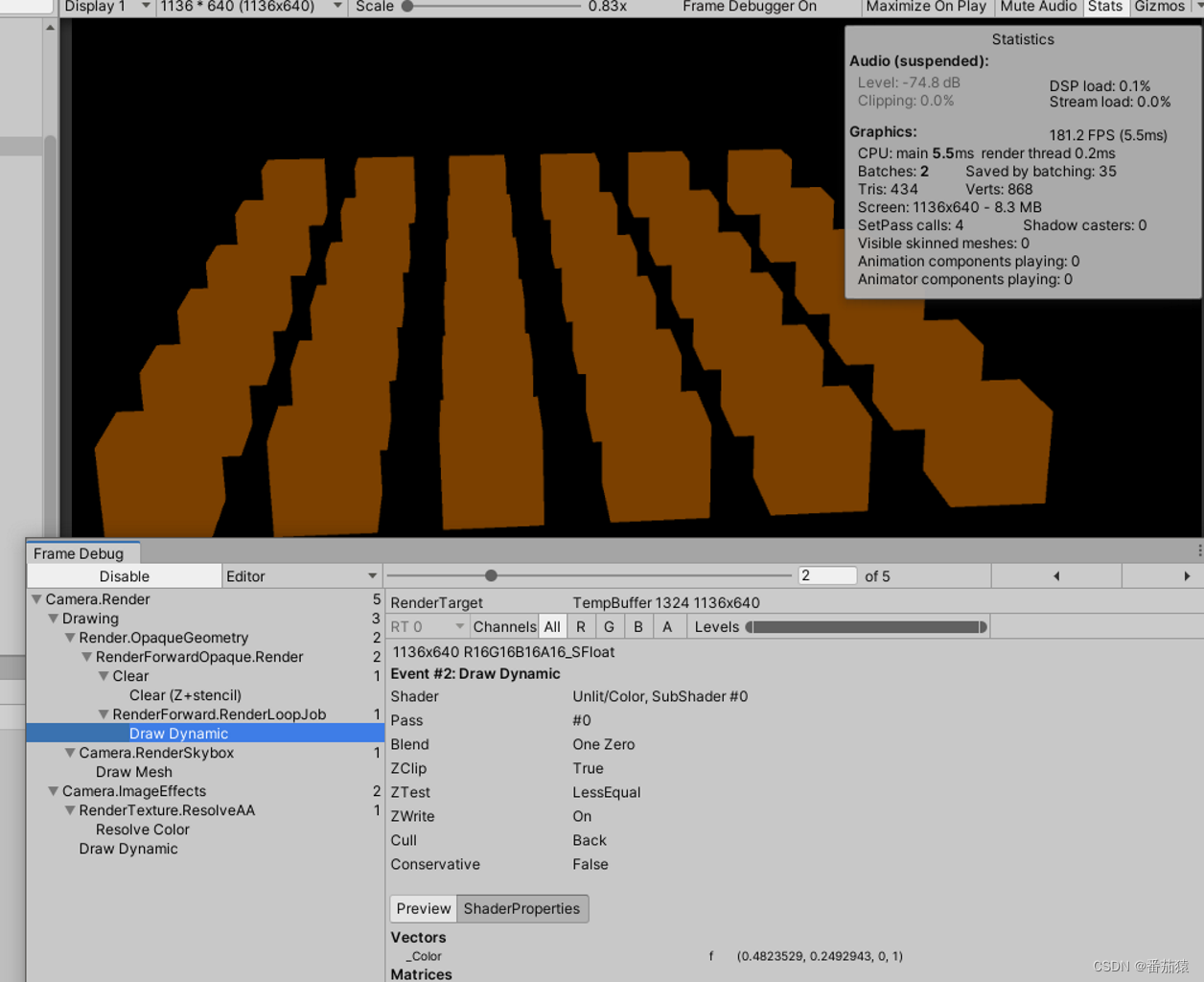
多种颜色的合批
我们增加不同颜色的材质赋予这些球,但是我们发现实际上SRP的Batch并不会增加,因为数据缓存在了GPU上,每一次DrawCall只需要包含内存位置的偏移数据就好了。
对于SRP的使用有一个限制是每个材质的memory layout(内存布局?)必须是一样的,因此在这里所有的球我们都使用了同一个Shader,而这些材质都只包含了一个颜色属性。Unity不会去详细的比较的材质的memory layout,而是简单的根据相同的Shader变体去合并Draw Calls。

在上面的例子中,为了有5种颜色,我们创建了5个材质球,但如果要十几种颜色或者更多,我们总不能去创建那么多的材质球。如果我们能直接设置每个对象的颜色,那就会方便很多。
我们通过MaterialPropertyBlock实现这个功能。
using UnityEngine;
[DisallowMultipleComponent]
public class PerObjectMaterialProperties : MonoBehaviour
{
static int baseColorId = Shader.PropertyToID("_BaseColor"); //使用Id的方式去设置属性会更高效
static MaterialPropertyBlock block;
[SerializeField]
Color baseColor = Color.white;
void Awake()
{
OnValidate(); //OnValidate只在编辑器下会被调用,打包后我们得自己调用
}
//OnValidate在编辑器下,在组件加载和组件修改时会被调用
void OnValidate()
{
if (block == null)
{
block = new MaterialPropertyBlock();
}
block.SetColor(baseColorId, baseColor);
GetComponent<Renderer>().SetPropertyBlock(block);
}
}
我们可以看到虽然我们对这些球只使用了一个材质球,但是颜色却是不一样的,是通过组件修改单个对象的颜色
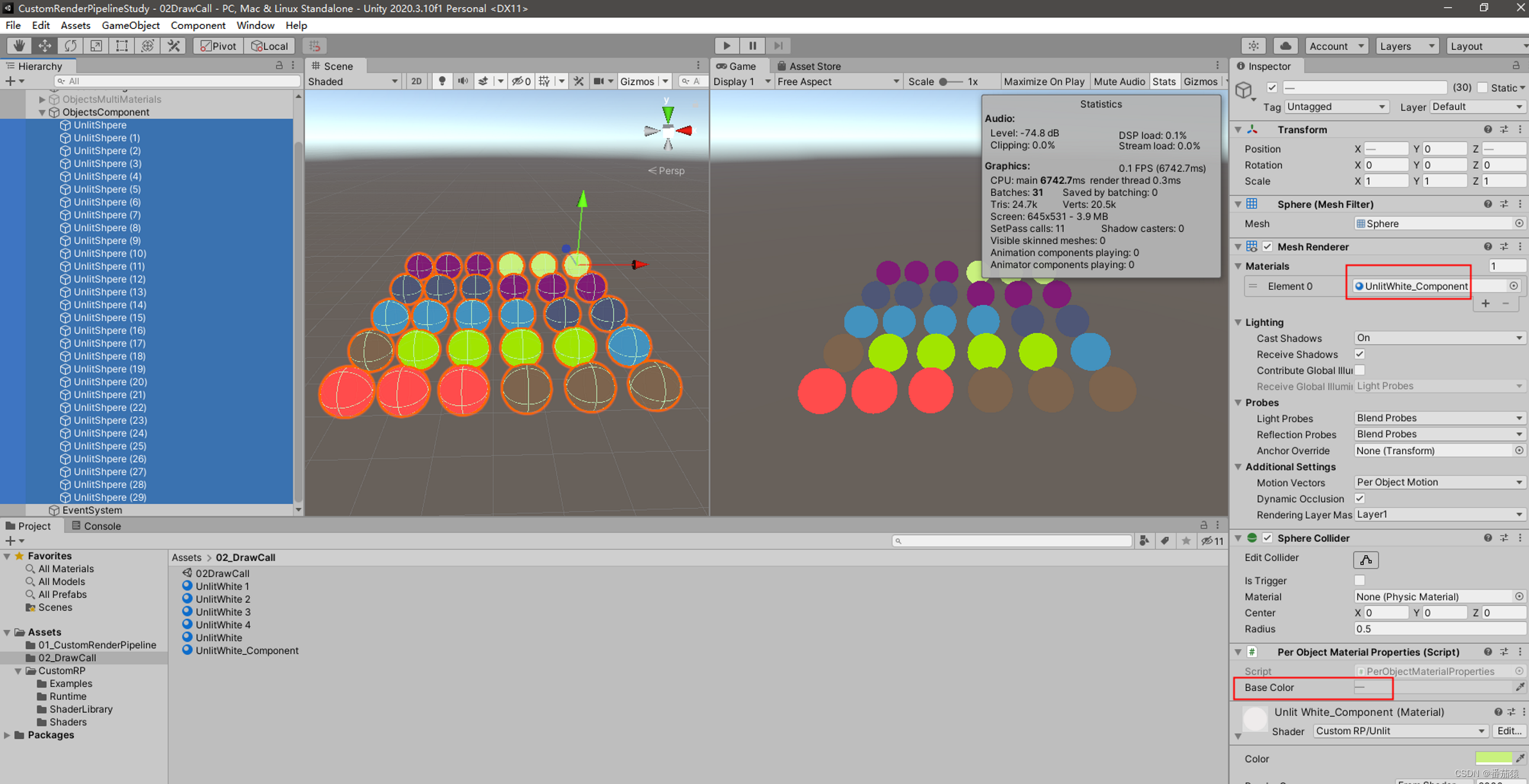
但是,我们看到SRP Batcher不生效了,这样子虽然方便了,但是性能不行了