User-controllable Recommendation Against Filter Bubbles
摘要
推荐系统经常面临过滤气泡的问题:过度推荐基于用户特征以及历史交互的同质化项目。过滤气泡将会随着反馈循环增长,缩小了用户兴趣。现有的工作通常通过纳入诸如多样性和公平性等准确性之外的目标来减少过滤气泡。然而,这种方式会牺牲精确性,损害模型的保真度以及用户体验。甚至用户需要被动地接受推荐策略以及用一种很低效高延迟性的方式来影响系统。
本文提出了一种新的推荐原型,叫做“用户可控推荐系统”(User Controllable Recommender System, UCRS),该系统使得用户可以主动地控制对过滤气泡的减弱。UCRS的目标有以下几点:
- UCRS可以提醒那些深陷过滤气泡的用户,
- UCRS可以支持四种控制命令来帮助用户从不同的粒度上来减弱气泡效应,
- UCRS可以对控制进行响应,并且自由地调整推荐。
调整的关键在于阻塞推荐中过时用户响应的效应,包括与控制命令不一致的历史信息。例如,作者发展了一种因果增强的用户可控推理(User-Controllable Inference, UCI)狂降,可以快速地修正在推理阶段基于用户控制的推荐,使用反事实推理来减弱过时用户表示的效应。在三个数据集上的实验证明了UCI框架可以基于用户控制有效地推荐更多需要的项目,在精确性和多样性上展示出了卓越的效果。
1 简介
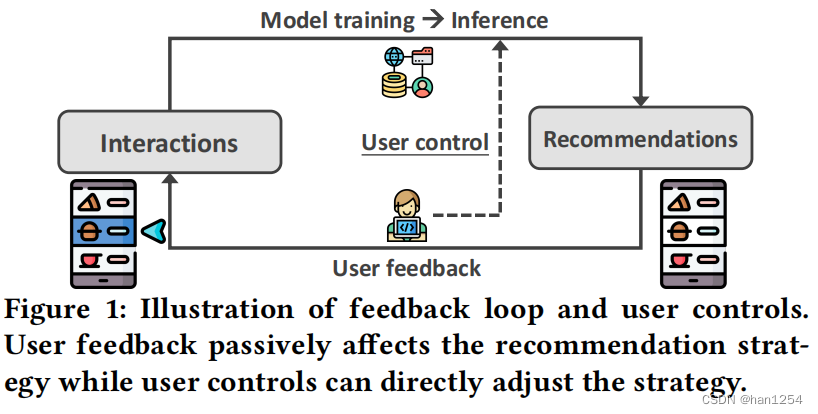
由于仅仅是拟合数据,推荐系统常常面临过滤气泡问题:持续推荐很多同质性的项目,将用户和多样化的内容隔离开。例如,如果用户点击了很多短视频,来学习制作咖啡,系统可能会持续向其推荐不同视频上传者投稿的相似短视频,占据了其他诸如热点新闻等信息丰富的视频。更糟糕的是,因为如图一的反馈循环,过滤气泡可能会逐渐地变得严重。从长远来看,过滤气泡将会减少用户的积极性以及项目的创造性,会损伤整个生态环境。因此,消除过滤气泡是很重要的。
为了实现这一目标,现有的研究提出纳入额外目标的历史交互数据拟合。例如(1)多样性[6]、[58],强制推荐列表覆盖尽可能多的项目类别;(2)公平性[3]、[30],追求在项目类别上的公平曝光机会;(3)标准化[39]、[48],保证了推荐列表在不同项目类别上的显示与用户的交互历史具有相同的分布。然而这些方法只是在不同目标间的权衡,牺牲了精确性甚至是用户体验。此外,在反馈循环中,用户只能通过用户反馈来被动地调整推荐,由于用户需要持续地提供反馈知道系统识别到用户需求,这种方式是低效并且不充分的。
作者认为,用户需要拥有权力来决定是否消除过滤气泡,并且选择减弱哪种气泡。最终,作者基于三个设想提出了UCRS:(1)系统有责任来提醒用户他们是否陷入了过滤气泡中;(2)系统应该提供多样的命令来充分支持用户的控制倾向;(3)系统应该快速地对控制进行响应。
过滤气泡警告
作者定义了一些标准来衡量过滤气泡的强度。这些标准,表现为系统提示,旨在让用户理解过滤气泡的状态,并且决定是否消除气泡。
控制命令
作者建议在用户特征以及项目特征两个层次上进行用户控制。在细粒度层次上,UCRS支持增加特定用户或者项目特征上的项目,例如“更多的被年轻人喜欢的项目”、“更多的某一类别的项目”。注意到用户可能并不会区分目标组别,UCRS也会支持粗粒度级别上的命令,例如“当涉及到我的年龄时,不要存在气泡”、“在项目类别上,不要存在气泡”。
对用户控制的响应
一旦接收到控制命令,UCRS通过将命令结合到推荐系统的推理中来调整推荐。但是这是有一定难度的,因为从历史交互中习得的一些过时用户表示已经将可能导致过滤气泡的偏好信息进行了编码。因此一些用户表示可能导致同质性推荐。
为了克服这些挑战,作者提出了一种因果强化的用户可控推理框架,从因果视角来审视推荐的产生过程,消除过时用户表示的影响。UCI框架设想出一个反事实世界,在这里的过时用户表示被去除,并且将过时表示的效应估计为真实世界以及反事实世界之间的差别。在减除该效应之后,UCI将控制指令结合进推荐系统的推理中。至于用户特征的控制,UCI使用指令中确定的用户特征(例如,将年龄从中年改成青少年)来在细粒度和粗粒度两个层面上产生最终的推理。而项目特征控制,考虑到项目分类,UCI采用了用户可控的排序策略来控制推荐。
2 前期准备
首先对过滤气泡进行直觉上的理解。
实验设置
作者在三个公开数据集(DIGIX-Video、Amazon-Book以及ML-1M)上训练了一个具有代表性的推荐模型FM[35],然后对每个用户选取top-10的推荐项目。然后为了研究过滤气泡的问题,作者根据用户特征以及用户交互这两个因子来将用户分成两个组别。可以通过例如性别和年龄来对用户进行分组。此外,用户经常对不同的项目类别(如:浪漫爱情电影)感兴趣,因此可以根据用户在项目类别上的交互来对用户进行分组。对于每个项目类别,选择那些交互比例比阈值高的用户。然后比较用户的历史交互以及以及FM生成的推荐。
分析
对于DIGIX-Video数据集上的男性和女性用户,作者可视化了他们在top-3项目类别的历史分布,总结在图二(a)中。从图中,可以观察到,男性和女性用户再项目类别上表现出不同的兴趣。例如,与女性相比,男性用户更加偏好动作电影而不是浪漫爱情电影。因此,推荐模型继承了这一偏差分布。如图二(b)和(c)所示,对于男性和女性用户的推荐分布很接近历史分布,表现出用户将会接收到同质化的推荐。更糟糕的是,模型倾向于放大偏差并且曝光出更多的历史多数类别,如图二(b)、(c)所示,这将造成男性和女性用户推荐之间的严重割裂。
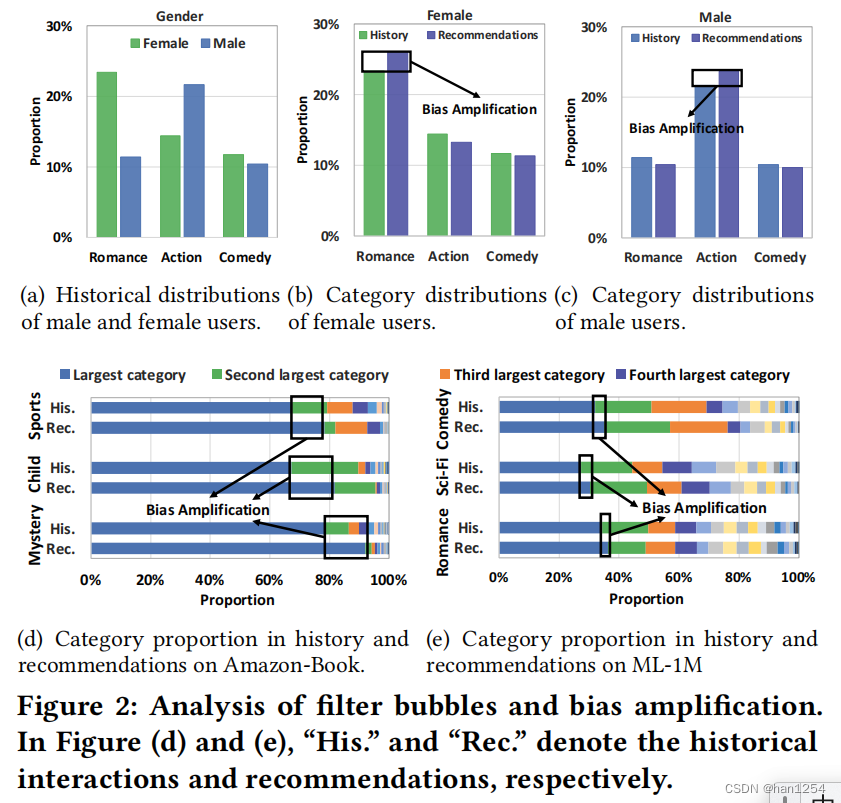
对于被用户交互区分的组别,图二(d)和(e)中作者分别展示了在Amazon-Book和ML-1M上的结果。从图中有以下发现:(1)最大的用户历史交互类别在推荐列表中占据主导地位。此外,与Amazon-Book相比,ML-1M上的分布更加多样化,这是因为在ML-1M中的大部分项目都有多个类别;(2)模型经常会产生偏差放大问题,并且增加推荐多数类别的占比。由于偏差放大,过滤气泡将会逐渐地增强,并且势必会限制了用户的喜好、隔离用户,并且导致组别的分割。
总结
作者发现,过滤气泡存在于用户以及项目特征一侧。涉及到项目特征的气泡是由在项目类别上的偏差交互导致的。作者提出了响应的用户特征控制以及项目特征控制。
3 用户可控推荐
3.1 UCRS的形式化
3.1.1 用户可控推荐系统
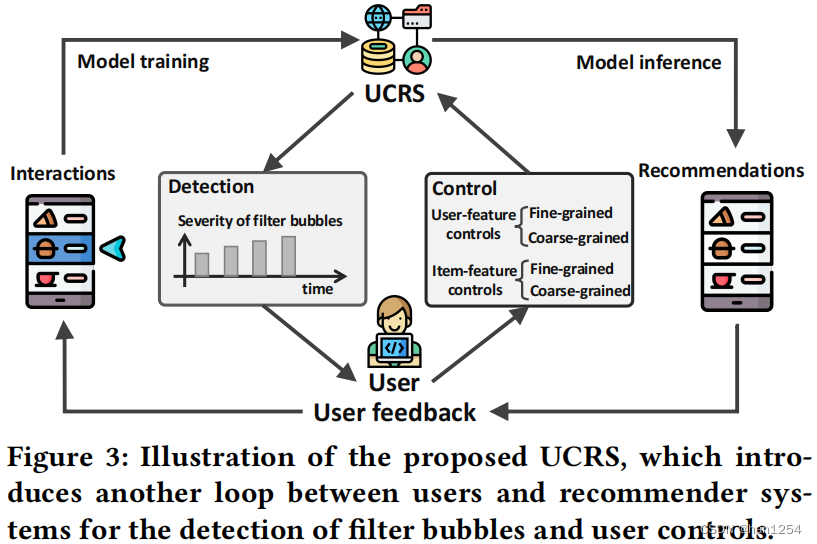
由图三所示,UCRS将“检测”和“控制”模块结合起来,将用户以及推荐系统之间的另一个循环引入。首先,检测模块被用来测量随时间加剧的过滤气泡的严重性,并且警告用户是否陷入过滤气泡中。如果用户想要消除过滤气泡,他们可以使用控制命令并且通过控制模块实时施加调整。
严格来讲,给定用户的历史交互 D D D,传统的推荐系统模型旨在通过 P ( R ∣ D ) P(R|D) P(R∣D)来预测推荐 R R R。相反, U C R S UCRS UCRS额外地考虑到用户控制 C C C以及在用户干预 d o ( C ) do(C) do(C)下估计 P ( R ∣ D , d o ( C ) ) P(R|D,do(C)) P(R∣D,do(C)),从因果的角度将干预形式化为四种控制。通过干预,用户可以快速地调整推荐,明显地降低历史主要类别中的项目,自由地跳出过滤气泡。作者基于用户以及项目特征,在细粒度和粗粒度的层次上将用户控制形式化为四种。
3.1.2 用户特征控制
将用户 u u u的 N N N个特征表示为 x u = [ x u 1 , ⋯ , x u n , ⋯ , x u N ] x_u=[x_u^1,\cdots, x_u^n,\cdots,x_u^N] xu=[xu1,⋯,xun,⋯,xuN],这里的 x u n ∈ { 0 , 1 } x_u^n\in \{0,1\} xun∈{0,1}表示用户 u u u含有特征 x n x^n xn。
细粒度用户特征控制
为了消除用户特征过滤气泡(例如,性别和年龄),作者设计了细粒度的用户特征控制,保证了UCRS推荐更多被其他用户组喜欢的项目。例如,三十岁中年用户可能对青少年喜欢的电影感兴趣。形式化地讲,为了计算用户
u
u
u的
P
(
R
∣
D
,
d
o
(
C
)
)
P(R|D,do(C))
P(R∣D,do(C)),将控制形式化为
d
o
(
C
=
c
u
(
+
x
^
,
α
)
)
do(C=c_u(+\hat{x},\alpha))
do(C=cu(+x^,α)),这里的
c
u
(
+
x
^
,
α
)
c_u(+\hat{x},\alpha)
cu(+x^,α)是暴露更多被其他用户组
x
^
\hat{x}
x^喜欢项目的控制命令,
c
u
(
+
x
^
,
α
)
c_u(+\hat{x},\alpha)
cu(+x^,α)需要用户
u
u
u没有特征
x
^
\hat{x}
x^,即
x
^
u
=
0
\hat{x}_u=0
x^u=0。此外,
α
∈
[
0
,
1
]
\alpha\in [0,1]
α∈[0,1]是调整用户控制强度的系数。
粗粒度用户特征控制
用户可能简单地想要消除过滤气泡,并不喜欢其他用户组喜欢的项目。并且,一些用户可能并不知道哪个用户组更加具有吸引力。因此,作者提出了粗粒度用户特征控制,帮助用户跳出自己组别的过滤气泡。例如,中年用户可能并不希望推荐被严格限制在“年龄=30”上。在 P ( R ∣ D , d o ( C ) ) P(R|D,do(C)) P(R∣D,do(C))中的控制 d o ( C ) do(C) do(C)形式化为 d o ( C = c u ( − x ‾ , α ) ) do(C=c_u(-\overline{x},\alpha)) do(C=cu(−x,α)),这将会减少用户自己组别喜欢的项目 x ‾ \overline{x} x,即 x ‾ u = 1 \overline{x}_u=1 xu=1。
3.1.3 项目特征控制
虽然用户特征控制可以削弱在用户特征上的过滤气泡,但是却忽略了由用户交互造成的过滤气泡。如图二(d)所示,推荐模型常常曝光历史多数类别。因此,为了补充用户特征控制,作者设计了项目特征控制来调整推荐。与用户特征类似,设项目 i i i的 M M M个特征表示为 h i = [ h i 1 , ⋯ , h i m , ⋯ , h i M ] h_i=[h_i^1,\cdots, h_i^m,\cdots, h_i^M] hi=[hi1,⋯,him,⋯,hiM],这里的 h i m ∈ { 0 , 1 } h_i^m\in \{0, 1\} him∈{0,1}表示为项目 i i i拥有特征 h m h^m hm。
细粒度项目特征控制
如果用户有目标项目类别(例如,更多浪漫电影),细粒度项目特征控制可以用来增加对它们的推荐。干预 d o ( C ) do(C) do(C)可以被表示为 d o ( C = c i ( + h ^ , β ) ) do(C=c_i(+\hat{h},\beta)) do(C=ci(+h^,β)),这里的 h ^ \hat{h} h^是目标项目类别, β ∈ [ 0 , 1 ] \beta\in [0,1] β∈[0,1]是用来修改用户控制的强度。
粗粒度项目特征控制
相应的,作者提出粗粒度项目特征控制来减轻用户指定目标项目类别的负担。粗粒度项目特征控制的目标是减少用户历史交互中最大项目类别的推荐。干预可以表示为
d
o
(
C
=
c
i
(
−
h
‾
,
β
)
)
do(C=c_i(-\overline{h},\beta))
do(C=ci(−h,β))。
3.2 UCRS的实现
3.2.1 过滤气泡监测
作者提出了一些度量方法来从不同的角度衡量过滤气泡的严重性,例如多样性以及隔离状态。在不同时间段,可以通过推荐系统设计的启发式规则来计算度量并且获得过滤气泡的严重性程度。然后,严重程度被展示给用户并且让用户决定是否控制过滤气泡。
覆盖性
过滤气泡经常减少推荐项目的多样性,因此可以结合广泛使用的多样性衡量方式:覆盖性(coverage),这种衡量计算推荐列表中的项目类别的数量。
隔离指标
除了基于多样性衡量的方式外,作者还提出了隔离指标(Isolation Index)[20]来衡量不同用户组别之间的隔离。给定两个用户组 a a a和 b b b,可以对推荐的隔离指标进行如下计算:
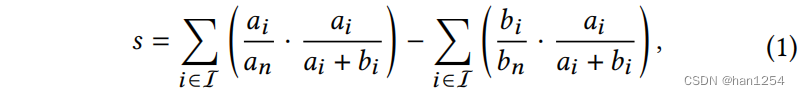
这里的 I \mathcal{I} I是项目集合, a i a_i ai以及 b i b_i bi是接收到推荐项目 i i i的组 a a a和组 b b b中的用户数量。此外, a n = ∑ i ∈ I a i a_n=\sum_{i\in \mathcal{I}}a_i an=∑i∈Iai是组 a a a中受到项目曝光的总频率, b n b_n bn同理。最终, s ∈ [ 0 , 1 ] s\in [0,1] s∈[0,1]等于组别 a a a中的加权平均项目曝光减去组别 b b b的,权重为 a i a i + b i \frac{a_i}{a_i+b_i} ai+biai[20]。直觉上, s s s捕获了两个组别之间的推荐隔离程度,值越高意味着越严重的隔离。如果有多个都别,采取任意两组之间的 s s s值的平均。
多数类别优势(MCD)
隔离指标适合于根据用户特征分组来计算组别隔离。对于项目特征,可以使用MCD来获得历史最大项目类别在推荐列表中的比例。在不同时间段MCD的增加,反映着在项目类别上的过滤气泡逐渐严重。
3.2.2 用户特征控制响应
如果用户旨在削弱过滤气泡,UCRS需要对用户控制实时响应,对于细粒度的用户特征控制 d o ( C = c u ( + x ^ , α ) ) do(C=c_u(+\hat{x},\alpha)) do(C=cu(+x^,α)),用户想要更多的被其他用户组别 x ^ \hat{x} x^喜欢的项目。由此,UCRS事实上需要基于变动的用户特征来生成推荐。例如,年龄从30岁到18岁。从因果的视角,细粒度用户特征控制的目标是回答一个反事实问题:如果用户在一个反事实的组别 x ^ \hat{x} x^,那么用户的推荐将会变成什么样子? 相似地,粗粒度用户特征控制是为了回答如果用户不在真实组别 x ‾ \overline{x} x中,那么推荐将会变成什么样子? 为了回答该反事实问题,UCI框架需要识别在用户特征和推荐之间的因果联系,并且进行反事实推理。
产生推荐的因果视角
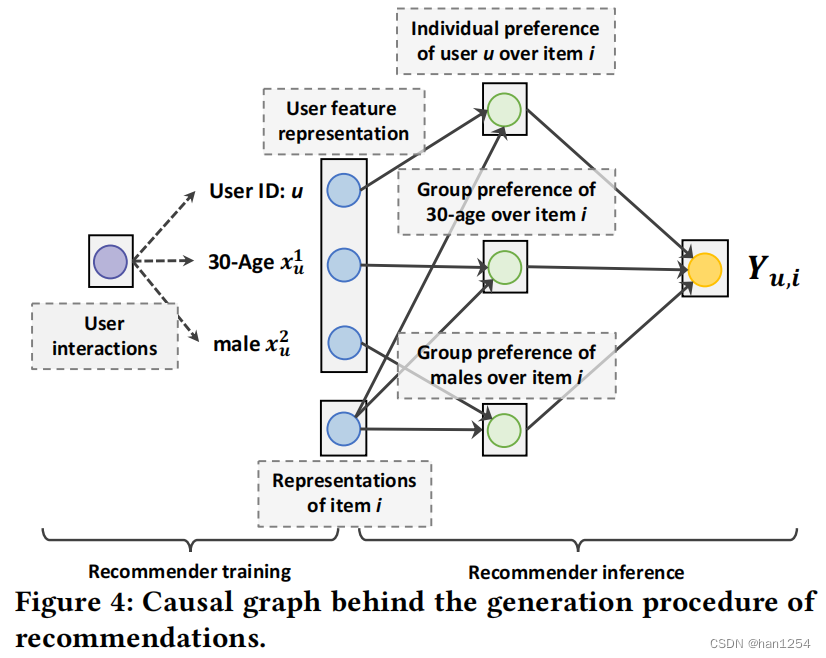
如图四所示,作者通过因果图分析了推荐产生的过程。对于大部分模型,推荐系统通过交互来学习用户表示,包括用户ID、年龄以及性别的表示。因此,对于用户 u u u以及项目 i i i的表示被用来预测用户对项目的偏好概率,即 Y u , i ∈ [ 0 , 1 ] Y_{u,i}\in [0,1] Yu,i∈[0,1]。 Y u , i Y_{u,i} Yu,i是个体ID和多组特征的偏好得分融合,组别偏好被对应用户组别内的用户分享。
为了回答细粒度用户特征控制的反事实问题,一个直觉上的解决方式是改变推荐器推理的用户特征,例如将年龄从30改为18。关于粗粒度用户特征控制,可以直接摒弃推理中的用户特征 x ‾ \overline{x} x。然而,如图四所示,用户交互实际上是混杂因子,在推荐器训练过程中影响用户ID以及其他组别特征的表示。因此,在用户ID和组别特征之间存在联系。虽然组别特征被改变或者丢弃,第三十用户ID表示仍然将原始特征的过时兴趣进行了编码,这与用户控制不一致,并且阻碍了对目标用户组别的推荐。
为了移除混杂效应,流行的选择是混杂平衡[36]、后门调整以及前门调整。然而,混杂平衡和后门调整需要估计混杂因子在表示上的因果效应。这种估计是不可行的,原因如下:(1)用户交互处于一个动态的高纬空间,这里的新的交互持续增加;(2)用户交互对于表示的影响是由推荐器的训练过程决定的,不同的训练方式结果也不同。此外,前门调整需要发掘阻塞所有后门路径的媒介,这对于图四中的因果图并不适用。为了避免这些挑战,作者提出了直接减少在推理过程中用户ID表示对预测 Y u , i Y_{u,i} Yu,i的因果效应,这可以在不知道训练过程的情况下有效地减少过时表示的影响。
实现反事实推理
UCI框架首先使用反事实推理来估计用户ID表示的效应,然后从原始的预测 Y u , i Y_{u,i} Yu,i中扣除该效应。设想在反事实世界中**如果用户 u u u没有ID表示,预测 Y u ^ , i Y_{\hat{u},i} Yu^,i会变成怎样。**这里的 u ^ \hat{u} u^代表没有ID表示的用户表示。通过比较 Y u , i Y_{u,i} Yu,i和 Y u ^ , i Y_{\hat{u},i} Yu^,i,可以通过 Y u , i − Y u ^ , i Y_{u,i} - Y_{\hat{u},i} Yu,i−Yu^,i来衡量用户ID表示的效果。因此,可以在原始预测 Y u , i Y_{u,i} Yu,i中减除该效应,使用系数 α \alpha α来控制减除的力度。
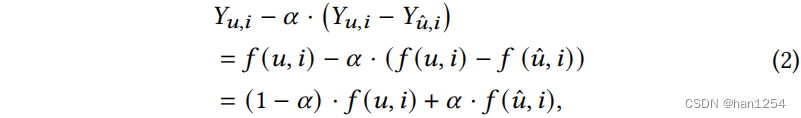
这里的 f ( ⋅ ) f(\cdot) f(⋅)可以是任何使用用户以及项目表示来计算预测 Y Y Y的推荐方法。
UCI总结
UCI框架由两步组成,在推理时回答两个关于用户特征控制的问题:
(1)改变特定用户特征为
x
^
\hat{x}
x^,进行细粒度控制以及丢弃用户特征
x
‾
\overline{x}
x进行粗粒度控制;
(2)使用反事实推理,通过等式(2)来减弱过时用户ID表示的影响。
3.2.3 响应项目特征控制
项目特征控制的细粒度控制旨在增加目标项目类别 h ^ \hat{h} h^,而粗粒度控制为了减少用户历史中最大历史类别 h ‾ \overline{h} h。实际上,在这里询问了两个干预问题:如果用户想要更多目标类别 h ^ \hat{h} h^的项目,推荐会变成怎样?以及用户不想要最大类别 h ‾ \overline{h} h推荐又会变成怎样? 为了回答这些问题,UCI框架使用了一个用户可控的排序策略:
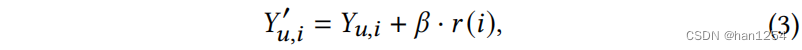
这里的 Y u , i ′ Y_{u,i}' Yu,i′是修正的排序分数, β ∈ [ 0 , 1 ] \beta\in [0,1] β∈[0,1]是调整用户控制强度的系数。 r ( i ) r(i) r(i)表示项目 i i i的正则项,

在细粒度控制下, r ( i ) r(i) r(i)鼓励推荐更多的目标类别 h ^ \hat{h} h^中的项目,如果施加了粗粒度控制,则减少最大类 h ‾ \overline{h} h。
目标类别预测
由于大量的项目类别的存在,用户在细粒度项目特征控制上来选择目标类是一种巨大负担。即使粗粒度控制部分消除了这种负担,但是可以通过对用户预测可能的目标类别来进一步减弱这种负担。如果用户希望减少历史最大类别,可以预测用户可能喜欢历史中的哪个项目类别,然后使用细粒度项目特征控制来改善粗粒度项目特征控制。
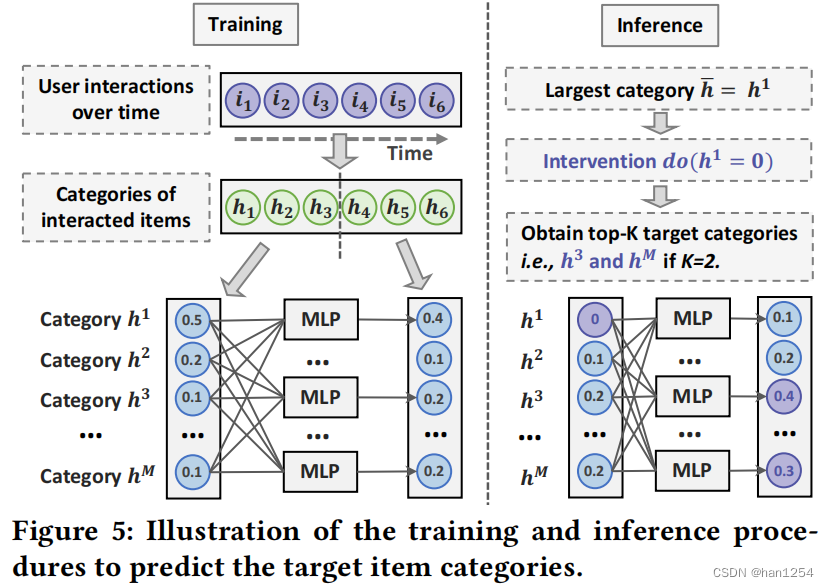
如图五所示,将用户的交互项目按照时间排序,然后将交互序列分成两部分,分别获得项目类别的分布。然后,使用多层感知机,根据第一部分来预测第二部分的分布。在训练过程中,MLPs使用所有用户的类别分布来捕获(1)时间兴趣转移(例如,在一些类别上逐渐增加的偏好),(2)项目类别之间的关系(例如,喜欢动作电影的用户可能也喜欢犯罪电影)。在推理阶段,使用第二部分的分布来预测top-K目标类别。此外,构造干预 d o ( h ‾ = 0 ) do(\overline{h}=0) do(h=0)来指示减少类别 h ‾ \overline{h} h的用户控制。top-K项目类别被视为细粒度控制的目标项目。最终,UCI进一步通过使用目标类别预测来强化粗粒度项目特征控制。
UCI总结
在项目特征控制下,用户ID表示仍然将历史喜好进行编码,这与增加目标类别或者减少历史大部分类别的目标相冲突。因此,(1)UCI首先构建了反事实推理来减弱用户ID表示的因果效应。(2)对于粗粒度项目特征控制,UCI利用目标类别预测来获得top-K目标类别;(3)UCI采用了等式(3)中的排序策略来进行推荐。
4 实验
- RQ1. UCI如何通过四种用户控制来消除过滤气泡,调整推荐?
- RQ2. 用户如何使用系数(即 α \alpha α和 β \beta β)来控制推荐?
- RQ3. 提出的反事实推理如何影响推荐?
4.1 实验设定
- 数据集
作者使用三种真实世界数据集来进行实验:DIGIX-Video、ML-1M以及Amazon-Book。
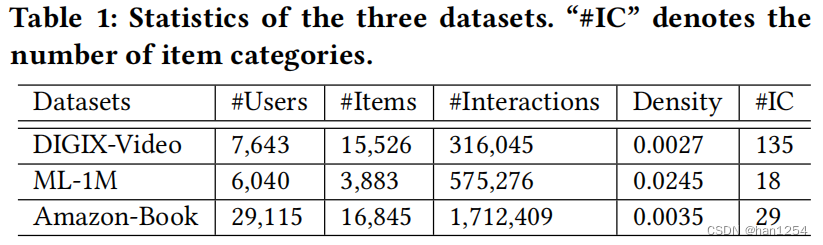
将评分大于等于4的项目作为积极样本。通过时间戳来排序交互,分割成80%、10%以及10%作为训练、验证以及测试集。对于每个交互,随机地采样一个未观测的交互来作为训练的负样本。
- 用户特征控制评估
由于线上测试的代价过大,作者设计了一种离线评估设定:(1)假设一些用户想要消除过滤气泡并且提供了四种控制;(2)根据用户控制,不同的推荐方法生成推荐;(3)在准确性以及消除过滤气泡的测量上进行评估。例如Isolation Index、MCD以及Coverage。
数据集
对于用户特征控制,使用DIGIX-Video来进行评估,因为该数据集拥有丰富的用户特征(例如,性别和年龄)以及视频类别。相反,Amazon-Book只有用户ID特征,ML-1M中的用户被数据集偏差严重地影响,77%的用户最喜欢的电影类别是“戏剧”和“喜剧”,10%的流行电影占据了52%的交互。因此,不同特征的用户表现出了相似的交互分布。因此。Amazon-Book和ML-1M不能很好地适应用户特征上的过滤气泡的评估。本工作中,作者在DIGIX-Video数据集的性别组和年龄组分别测试了细粒度和粗粒度的用户特征控制。用户在细粒度控制下以性别相反的群体为目标,并希望在粗粒度控制下跳出自己的年龄组。这是因为年龄组的数量更大,因此用户更有可能使用粗粒度控制,而不需要指定目标年龄组的负担。
基线
所有的基线以及提出的UCI都是模型无关的,这些模型在FM以及NFM两个代表性推荐模型上来进行比较。
(1)woUF,在没有用户特征的情况下训练模型,这可能会缓解推荐训练过程中不同用户组之间的隔离。
(2)changeUF使用训练好的推荐模型并且只改变用户特征为目标
x
^
\hat{x}
x^来进行推理。例如,将年龄从30变成18。changedUF被用来细粒度用户特征控制。
(3)maskUF摒弃了原始用户特征
x
‾
\overline{x}
x来进行粗粒度用户特征控制推理。
(4)Fairco[30]是一个用户可控的排序算法,追求项目组别之间的公平曝光推荐机会。
(5)Diversity[59]将重排序方法与最小化列表内相似性的多样化推荐结合。
测量
为了测量表现效果,使用全排序原型[49],并且top-10项目被返回作为推荐。采用 Recall \textbf{Recall} Recall和 NDCG \textbf{NDCG} NDCG来衡量精确性。为了确定过滤气泡的严重性,使用 Isolation Index \textbf{Isolation Index} Isolation Index以及 Coverage \textbf{Coverage} Coverage来估计组别隔离程度以及推荐的多样性。此外,对于目标用户组上的细粒度用户特征控制,作者采用了 DIS-EUC \textbf{DIS-EUC} DIS-EUC来比较用户和组别之间推荐的距离。
形式化来说,将 x ‾ \overline{x} x和 x ^ \hat{x} x^分别表示为用户 u u u原始的以及目标的组别; d u ∈ R M d_u \in \mathbb{R}^M du∈RM是用户 u u u的推荐项目类别分布; g ‾ u ∈ R M \overline{g}_u\in \mathbb{R}^M gu∈RM通过平均原始组别 x ‾ \overline{x} x中的用户来表示相同的分布; g ^ ∈ R M \hat{g}\in \mathbb{R}^M g^∈RM表示目标组别 x ^ \hat{x} x^的相同分布。然后对用户 u u u,计算 DIS-EUC = dis ( d u , g ^ u ) − dis ( d u , g ‾ u ) \text{DIS-EUC}=\text{dis}(d_u,\hat{g}_u)-\text{dis}(d_u,\overline{g}_u) DIS-EUC=dis(du,g^u)−dis(du,gu),这里的 dis ( ⋅ ) \text{dis}(\cdot) dis(⋅)使用欧拉距离。DIS-EUC衡量了用户到两个组别的距离差异,这里更大的距离标志着更严重的组别隔离以及过滤气泡。
- 评估项目特征控制
作者在从训练到测试数据集上产生偏好转变的用户上构造实验。对于每个用户,获得在训练以及测试数据集上最大的项目类别,然后根据不同的最大类别选择用户。这模拟了用户想要减弱历史过滤气泡并且想要更多的其他类别项目的场景。在DIGIX-Video、ML-1M以及Amazon-Book上选择的用户数量分别是4320、3806以及5155。
基线
通过下列方法为选择的用户生成推荐:
(1)woIF不适用项目特征训练FM和NFM;
(2)Fairco;
(3)Diversity;
(4)Reranking是一个UCI的变体,在等式(3)中只使用排序测量;
(5)C-UCI表示在粗粒度控制下进行目标类别预测的UCI策略;
(6)F-UCI表示在细粒度控制下的UCI,知道每个用户的目标类别,即测试集中的最大类别。
度量
对于模型表现的比较,作者使用了Recall、NDCG以及Coverage。此外,作者使用了一个新的度量Weighted NDCG(W-NDCG),该度量对目标类别中的正项目、非目标类中的正项目以及负项目分别分配NDCG分数2、1和0分。W-NDCG区分在目标类别和非目标类别中的正项目,并且偏好目标类别中的正项目。此外,作者使用了MCD以及Target Category Domination(TCD)来计分别算历史最大类别的比例以及推荐中用户的目标类别。
- 超参数设定
作者通过[22]中的设定来训练FM和NFM:用户/项目的表示大小为64;batch size为1024,使用Adagrad进行参数优化。学习率在{0.001,0.01,0.05}中进行搜索。NFM以及目标类别预测中的MLP的尺寸在{4,8,16,32}中进行微调,正则化系数在{0,0.1,0.2}中进行搜索。目标类别预测中的K从{1,2,……,5}中选择。此外, c u ( ⋅ ) c_u(\cdot) cu(⋅)和 c i ( ⋅ ) c_i(\cdot) ci(⋅)对照组中的 α \alpha α和 β \beta β分别在{0, 0.1,……,0.5}以及{0,0.01,……,0.1}中进行选择。在验证集中根据Recall值来选择最好的模型。