实习项目用到了 Kafka,系统学习一下
文章目录
- Zookeeper
- 一 概述
- 二 数据结构和监听行为
- 三 功能实现
- 1 统一配置管理
- 2 统一命名管理
- 3 分布式锁
- 4 集群管理
- Kafka
- 一 系统架构
- 1 架构图
- 2 数量关系
- 3 Consumer 重要参数
- 二 工作流程
- 1 消息写入过程
- 2 数据不丢失:ACK、ISR
- 3 数据不重复:幂等性
- 4 偏移量管理
- 5 分区分配和重平衡
- 三 常见问题
- 1 Kafka 高效读写原理
Zookeeper
参考链接
一 概述
- 主要用于管理分布式系统
- 客户端 / 服务器结构,类似 Redis
- 可以实现的功能
- 统一配置管理
- 统一命名服务
- 分布式锁
- 集群管理
二 数据结构和监听行为
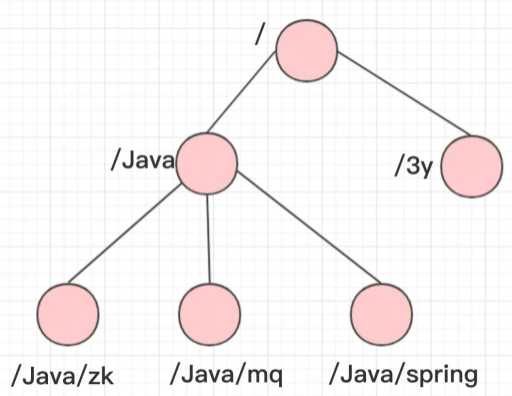
- 类似 Unix 文件系统,呈树形结构
- 每个节点是一个 ZNode,节点携带配置文件,也可以有子节点
- 两种 ZNode 节点类型(每种又可分为带序号、不带序号)
- 短暂 / 临时 Ephemeral:当客户端和服务端断开连接后,节点会自动删除
- 持久 Persistent:当客户端和服务端断开连接后,节点不会删除
- 两种常用监听方式
- 监听节点数据变化
- 监听子节点增减变化
三 功能实现
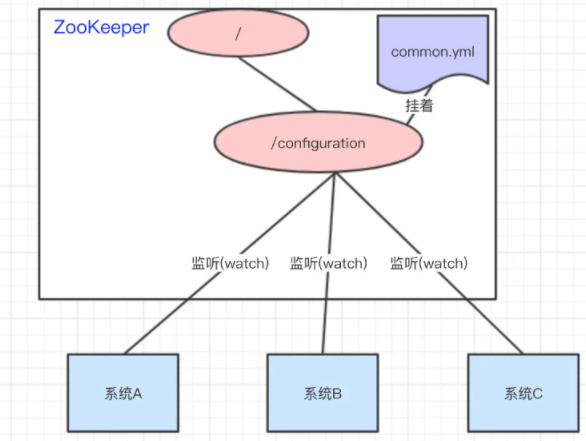
1 统一配置管理
- 将
common.yml放在节点中,系统 A、B、C 监听节点数据有无变更,如变更及时响应
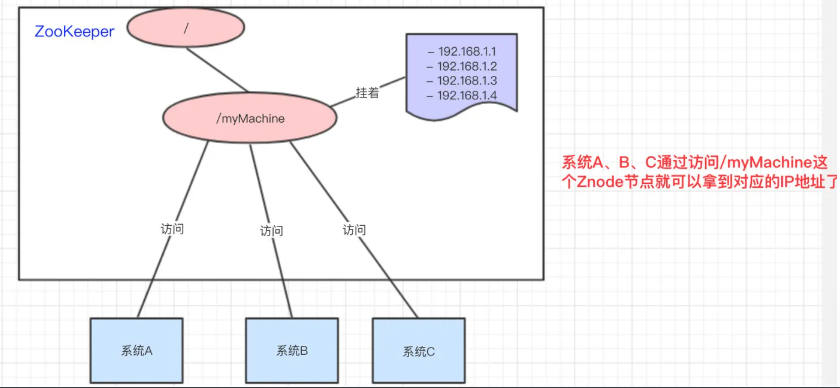
2 统一命名管理
- 类似域名到IP地址的映射,访问节点数据即可获得IP地址
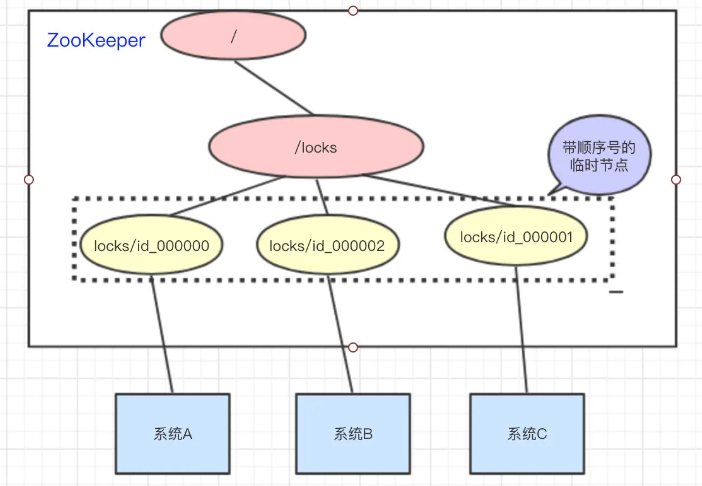
3 分布式锁
- 首先所有系统都尝试访问 /locks 节点,并创建临时的带序号节点
- 如果系统持有编号最小的临时节点时,则认为它获得了锁,否则监听其编号之前的节点状态
- 释放锁时删除临时节点
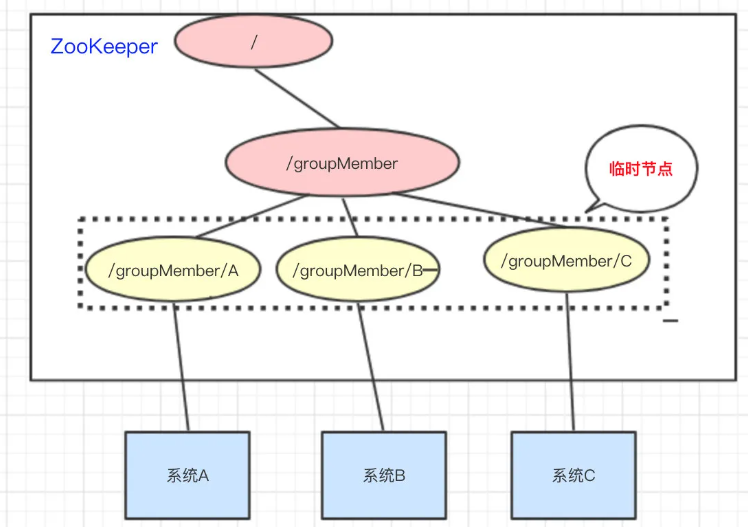
4 集群管理
- 系统启动时在 /groupMember 节点下创建临时节点,通过监听子节点感知系统状态
- 动态选举Master:如果使用带序号的临时节点,将编号最小的系统作为Master
Kafka
一 系统架构
1 架构图
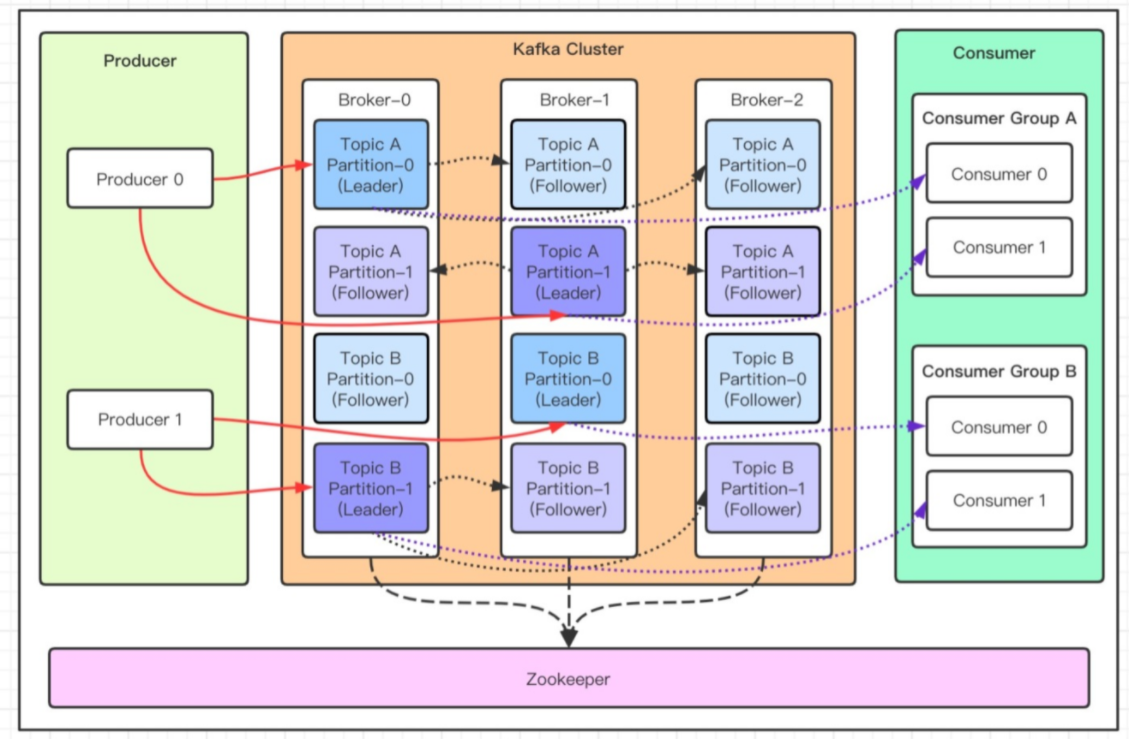
| 组件 | 作用 |
|---|---|
| Producer | 消息生产者 |
| Consumer | 消息消费者 |
| Consumer Group | 消费者组 |
| Broker | Kafka 实例 |
| Topic | 消息主题(逻辑概念) |
| Partition | Topic 分区(物理概念),一个 Topic 可以包含多个分区,单分区内消息有序;每个分区对应一个 Leader 和多个 Follower,仅 Leader 与生产者、消费者交互;Partition 在物理上对应一个文件夹 |
| Segment | Partition 物理上被分成多个 Segment,每个 Segment 对应一个物理文件 |
| Zookeeper | 保存元信息,现已废除 |
2 数量关系
-
同一 Broker 对同一个分区也只能存放一个副本,所以分区副本数不能超过 Broker 数
-
消费者组内的消费者,与分区的关系
- 同一个组的多个 Consumer 可以消费同一个 Topic 下不同分区的数据
- 同一个分区只会被同一组内的某个 Consumer 所消费,防止出现组内消息重复消费的问题
- 一个 Consumer 可以消费同一个 Topic 下的多个分区
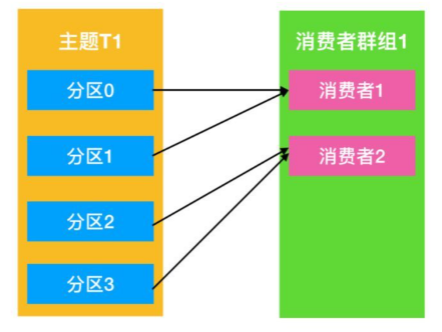
- 不同组的 Consumer,可以消费同一个分区的数据
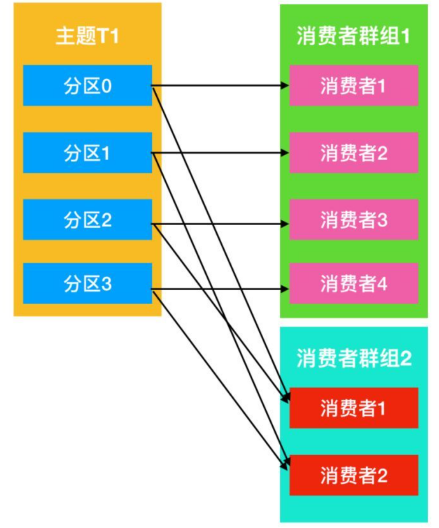
- 通常
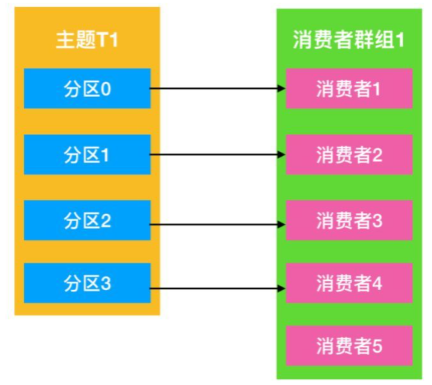
分区数 >= 一组内的Consumer数,以实现系统的可伸缩性,否则有一些 Consumer 是无法消费的
3 Consumer 重要参数
| 属性值 | 值 | 含义 |
|---|---|---|
enable_auto_commit | false | 自动提交偏移量,当一个Group在一个Topic上提交偏移量时,下次再使用该Group读取该Topic的消息时,就会从偏移量的位置开始读取 |
session_timeout_ms | … | 检测Consumer发生崩溃所需的最长时间。超过该时间Consumer未汇报心跳,则认为Consumer失效,将其移出group |
auto_offset_reset | earliest | 决定当Group在某Topic上无偏移时,开始读取的位置。设置为earliest使得每次抽样都从Topic的开始位置进行抽样,如果设置为latest就只能抽样那些正在写入消息的Topic |
max_poll_records | … | 单次poll()的最大消息数 |
group_id | … | Group名 |
max_poll_interval_ms | … | 两次poll()的最大间隔时间,超过该时间则认为Consumer失效,将其移出Group |
heartbeat_interval_ms | … | Consumer向Cooperator汇报心跳的间隔时间 |
二 工作流程
1 消息写入过程
只有完成所有流程的消息才可以被消费
- 选择分区,根据以下策略
- 写入时指定分区
- 没有指定分区但设置了 Key,则根据 HashCode 选择分区
- 没有指定分区和 Key,轮询选择分区
- 获取指定分区 Leader
- 生产者将消息发送给分区 Leader
- Leader 将消息写入本地文件
- 对应的 Follower 从 Leader 拉取消息并写入本地文件
- Follower 向 Leader 发送 ACK
- (ACK策略为-1时)Leader 收到所有 ISR Follower 的 ACK 后,向生产者发送 ACK
2 数据不丢失:ACK、ISR
| acks | 行为 |
|---|---|
| 0 | 生产者发起消息写入请求后,不会等待任何来自 Broker 器的响应(最不安全) |
| 1 | 生产者发起消息写入请求后,分区的 Leader 成功落盘后,Broker 即向生产者返回成功响应 |
| -1 | 生产者发起消息写入请求后,ISR 集合中的所有副本都落盘,Broker 才向生产者返回成功响应(最安全) |
Kafka 副本备份策略——如何保证消息不丢失
AR(Assigned Repllicas):一个分区的所有副本
ISR(In-Sync Replicas):能够和 Leader 保持同步的 Follower + Leader本身 组成的集合
OSR(Out-Sync Relipcas):不能和 Leader 保持同步的 Follower 集合
AR = ISR + OSR
- Kafka 只保证对 ISR 集合中的所有副本保证完全同步
- ISR 集合是动态调整的,如果一些副本**和 Leader 完全同步两次时间差超过阈值
replica.lag.time.max.ms**则被移出 ISR(因为生产者可以批量发送消息,所以不能指定未同步的消息条数作为检测标准)- 要使消息不丢失,需要满足
(acks = -1) && (replication.factor>=2) && (min.insync.replicas>=2)
3 数据不重复:幂等性
- 数据传递语义
- 至少一次 =
(acks = -1) && (replication.factor>=2) && (min.insync.replicas>=2) - 最多一次 =
(acks = 0) - 精确一次 =
(幂等性) && (至少一次)
- 至少一次 =
- 幂等性:生产者发送若干次重复的数据,Broker 都只会持久化一次
- 配置方法 (默认)
enable.idempotence = true - 判断的标准是
<PID, Partition, SeqNumber>,其中 PID 在 Kafka 启动时分配,Partition 代表分区,SeqNumber 自增 - 仅保证单分区单会话内的幂等性
- 配置方法 (默认)
- 生产者事务
- 开启事务的前提是开启幂等性
- 需要给生产者指定全局唯一的事务 ID
- 开启事务后,即使服务器重启,也能继续处理未完成的事务
4 偏移量管理
-
Offset 存放于内置 Topic
__consumer_offsets,由 Coordinator 管理 -
Consumer 的偏移量是按照 组 + Topic + 分区 进行维护的
-
偏移量相关概念
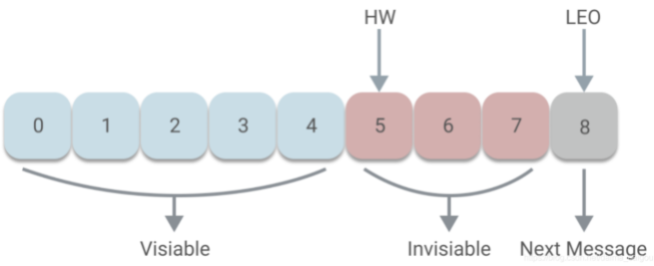
- LEO (Last End Offset):某个分区 Leader 或其 Follower 的下一个 Offset 值
- HW (High Watermark):某个分区 ISR 中,LEO 的最小值,仅 HW 之前的消息是已提交的消息,对于消费者可见
-
偏移量的提交方式
- 自动提交(可能造成重复消费)
- 指定
enable_auto_commit = true和auto_commit_interval_ms设置自动提交间隔
- 指定
- 手动提交(可能造成漏消费)
- 同步提交 :
consumer.commitSync()提交失败的时候一直尝试提交,直到遇到无法重试的情况下才会结束 - 异步提交+回调函数:
consumer.commitAsync()消费者线程不会阻塞,提交失败的时候也不会进行重试,可以配合回调函数记录错误信息 - 组合提交:消费时执行异步提交,停止消费后执行同步提交
- 同步提交 :
- 自动提交(可能造成重复消费)
KafkaConsumer<Integer, String> consumer = new KafkaConsumer<Integer, String>(configs);
consumer.subscribe(Collections.singletonList("topic_0"));
try {
while (true){
ConsumerRecords<Integer, String> records = consumer.poll(3000);
for (ConsumerRecord<Integer, String> record : records) {
System.out.println(record.value());
}
consumer.commitAsync(); // 异步提交
}
} catch (Exception exception){
// ...
} finally {
consumer.commitSync(); // 消费者关闭前,或者异步提交发生异常时,使用同步阻塞式提交
consumer.close();
}
5 分区分配和重平衡
- 分区分配的目的是,给定一个 Topic 和一个消费者组,决定组内哪个消费者消费 Topic 哪个分区的数据的问题
- 分区分配过程
- 同组的所有消费者向 Broker 的 Coordinator 发送 JoinGroup 请求(Broker 和 Coordinator 一一对应,负责管理消费者组)
- Coordinator 选出其中一个消费者作为 Leader,并把 Topic 的情况传递给 Leader
- Leader 根据指定的分区分配策略,决定消费方案,发送给 Coordinator
- Coordinator 将消费方案发送给每个消费者
- 对于同一个 Topic 的分区分配策略
partition_assignment_strategy_config
1.Range:计算每个消费者要消费的分区数,多余的分区分配给前几个消费者(Topic 增加时容易造成消费不均衡)
2.RoundRobin:轮询向消费者分配分区
3.Sticy:尽量均匀地分配分区,根据上次的分配结果尽量减少变动 - 重平衡 Rebalance
- 重平衡是 Kafka 集群的一个保护设定,重新分配每个消费者消费的分区,用于剔除掉无法消费或者过慢的消费者
- 进行重平衡时 Kafka 基本处于不可用状态,应该尽量避免
- 发生重平衡的情况:组内消费者数量变化、订阅 Topic 分区数量变化、组订阅 Topic 变化、Coordinator 宕机
三 常见问题
1 Kafka 高效读写原理
-
页缓存
- Kafka 的数据并不是实时的写入硬盘,当上层有写操作时,操作系统只是将数据写入 PageCache,同时标记为 Dirty
- 当读操作发生时,先从 PageCache 中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据
- 避免在 JVM 内部(堆内存)缓存数据,避免 GC 等机制带来的负面影响;如果进程重启,JVM 内的 Cache 会失效,但 PageCache 仍然可用
- 实际上 PageCache 是把尽可能多的空闲内存都当做了磁盘来使用
-
零拷贝
参考链接-
作用是在数据报从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现 CPU 的零参与
-
网络数据持久化到磁盘 (Producer 到 Broker)
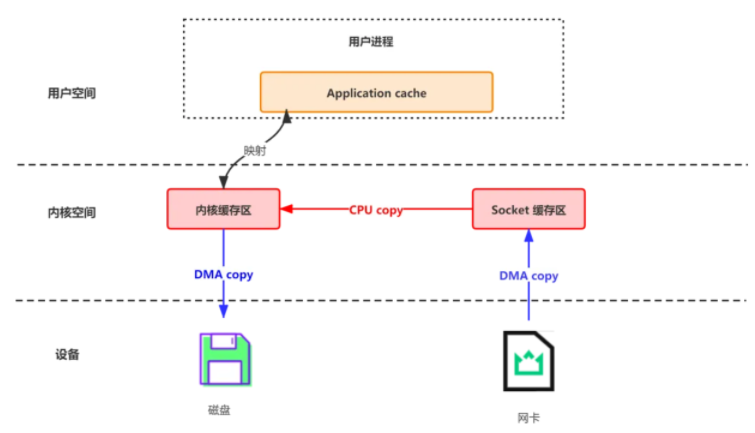
-
磁盘文件通过网络发送 (Broker 到 Consumer)
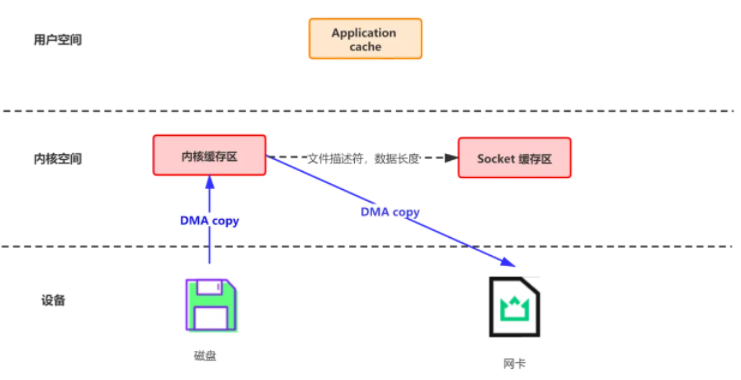
-
-
磁盘顺序写入
- 每条消息都是追加方式写入,不会从中间写入和删除消息,保证了磁盘的顺序访问
-
批量操作
- 在磁盘顺序写入的场景下有助于性能提升
- 更大的数据包有利于在网络 I/O 时提高吞吐量
-
分区并行处理
- 不同 Partition 可位于不同机器,可以充分利用集群优势,实现机器间的并行处理