- 1.索引
- 1.2 使用索引
- 2.索引的数据结构【重点】
- 3. 事务
- 3.1 使用
- 3.2 事务的四大特性
1.索引
概念
索引是一种特殊的文件,饱含着对数据表里所有记录的引用指针。可以对表中的一列或者多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的让图书,书籍内容和书籍目录的关系。
- 索引的作用就好比书籍的目录,可以快速 定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助。
- 索引会占用额外的磁盘空间。
- 在数据量较大,且经常会进行列的条件查询,,对于表的插入操作,及对列的修改频率较低的情况下,可以选择创建索引。
- 索引增加了增、删、查的开销,因为每次进行这些操作就需要调整已经创建好的索引目录。
1.2 使用索引
索引才创建好之后,是不需要手动使用的,在查询的时候会自动评估方案成本,自动的选择走不走索引,这是SQL通过数据库的 执行引擎来进行执行的。
- 查看索引
语法
show index from 表面;
案例:查看学生表的索引

-
如果表里有主键(primary/unique/foreign key),有主键这列就会自动创建索引。因为主键是唯一性,所以每次进行插入都需要遍历查询,那么对于查询就会比较频繁,加上索引就会提高性能。
-
创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引。
语法
create index 索引名 on 表名(字段名)
案列:对学生表的name字段创建索引

此时,表里就多了一个针对name这列的索引。
**注意:创建索引最好是创建表时就创建索引,否则,当表中的数据有一定数量时,会吃掉大量的磁盘IO,花很长的时间…这时候创建索引是一个 危险操作 ! **
- 删除索引
语法
drop index 索引名 on 表面;
案例:删除学生表中的name字段的索引
2.索引的数据结构【重点】
记住:索引的主要目的是为了加快查询速度。
- 是哈希表吗?查询时间复杂度O(1)
虽然哈希表是数据结构中最重要的,但是结论并不适合做数据库索引。因为**哈希表只能比较相等,无法比较大于或小于这种范围查询!**而数据库需要频繁的范围查询。
- 是二叉搜索树吗?查询时间复杂度O(N)
二叉搜索树可以范围查询。因为二叉搜索树是有序的,那么比如查一个起点,查一个终点,就可以获得一个范围数据。但是**数据库也没有使用二叉搜索树。**因为二叉搜索树当元素个数多的时候,数的高度就比较高,而数的高度决定了元素的比较次数,也就是查询时间会提高。【数据库进行比较都是需要读硬盘】
- 是N叉搜索树吗?
N叉搜索树:每个节点有N个值,同时有N个分叉。
N叉搜索数相对于二叉搜索树高度就大大降低了。而N叉搜索树中一个典型的实现就是B树。
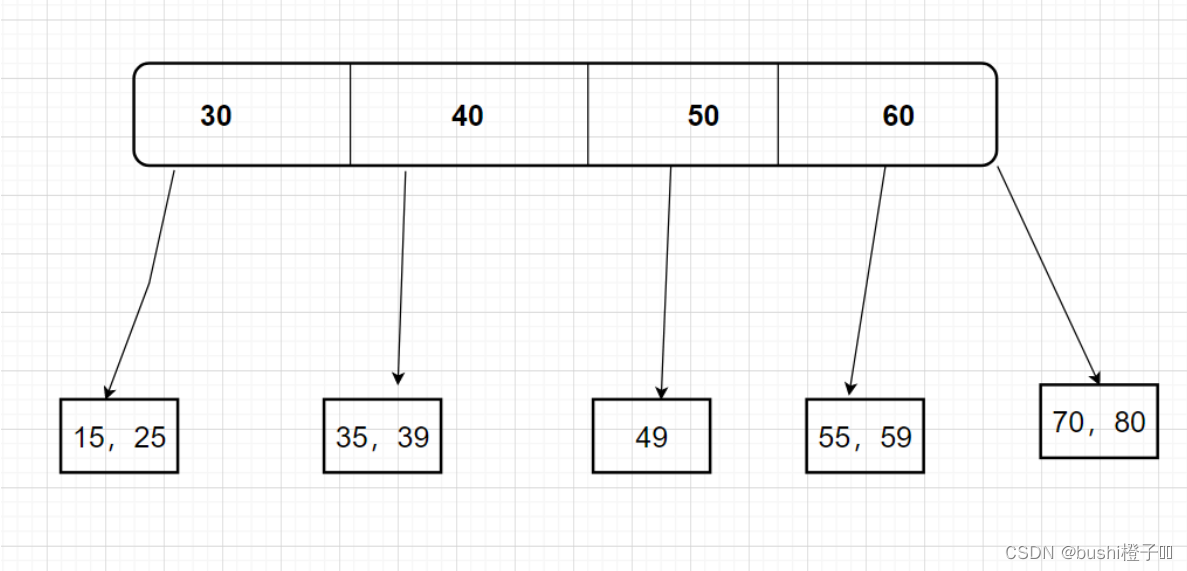
-
比如一个节点包含了4个元素,而这4个元素划分出了5个区间,每个区间内的元素比当前父节点小。
-
可以继续往下分,每个节点可以分为多个分支,每个节点的分支比节点数多一个,以此类推。
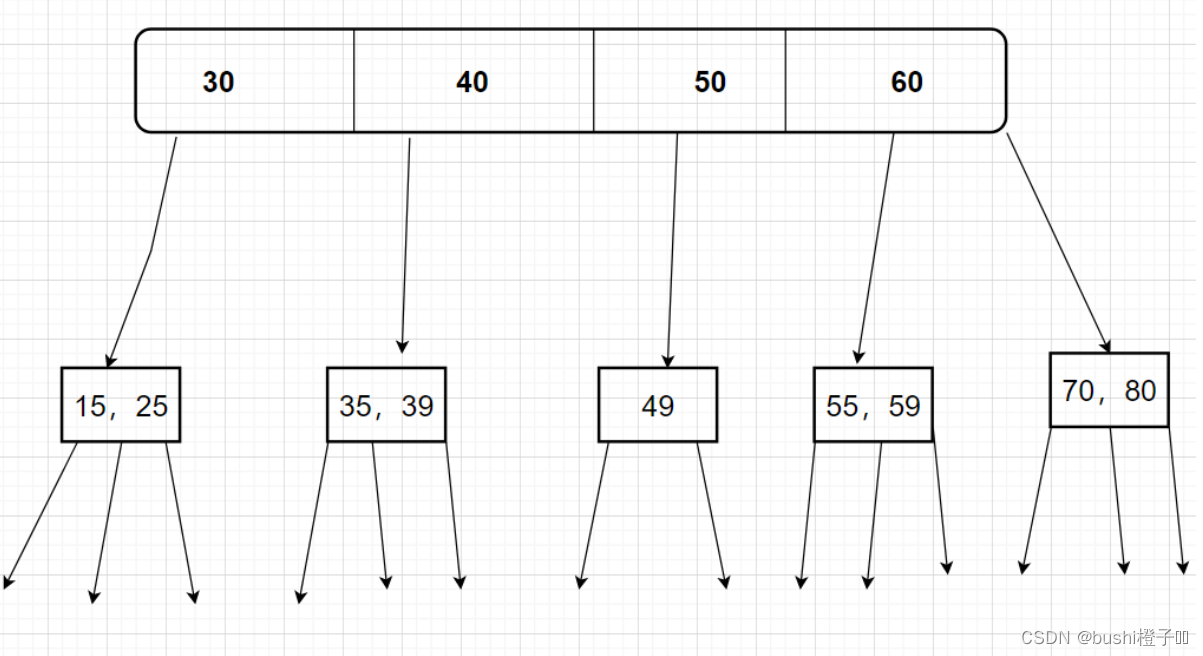
这样的一棵树,很明显树的高度降低的,但是比较次数并没有减少,一个节点依旧需要比较多次,不过读写硬盘的次数减少了(每个节点在硬盘上)。
结论:依旧不合适数据库的索引。于是引入了B+树 ,是对B树的进一步改进,B+树就是为了索引还量身定做的数据结构。
- 答案是B+树
B+树也是一个N叉搜索树,但是有一些新特点:
1.B+树也是B叉树,每个节点上可能包含N个key,N个key划分出N个区间,最后一个key就相当于最大值了。
2.父区间的key会在子区间重复出现,以最大值出现。
**3.**重复出现,叶子区间就包含了所有数据的全集!
4. 叶子节点,用类似链表的方式,进行首尾相连接。
- 比如当前节点上有2个数据时【10,15】,并不是分成3个区间了,而是分成2个区间,左边区间的元素都比10要小,并且10会放在左边区间的最后一个节点里。右区间也是类似的。
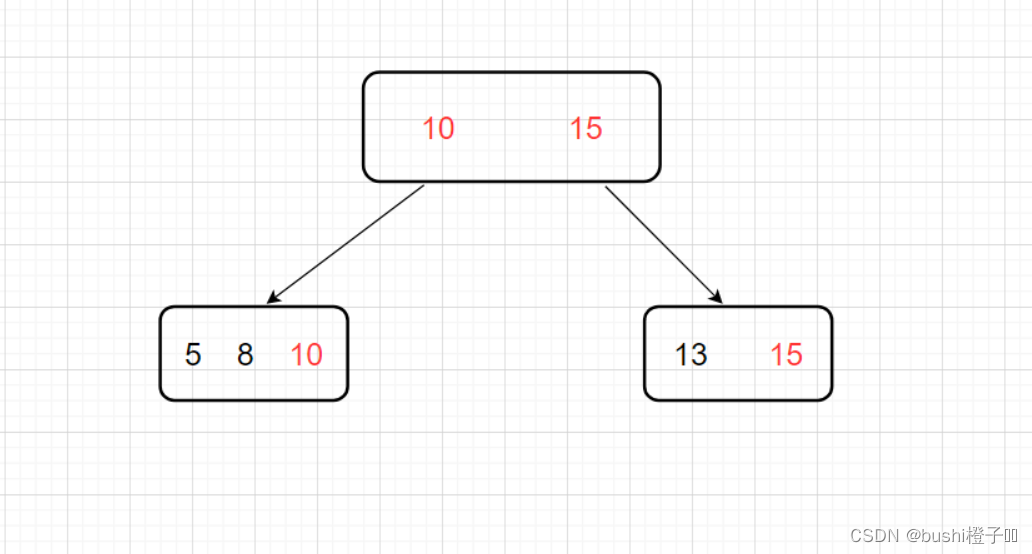
- 再往下分叉,以此类推。
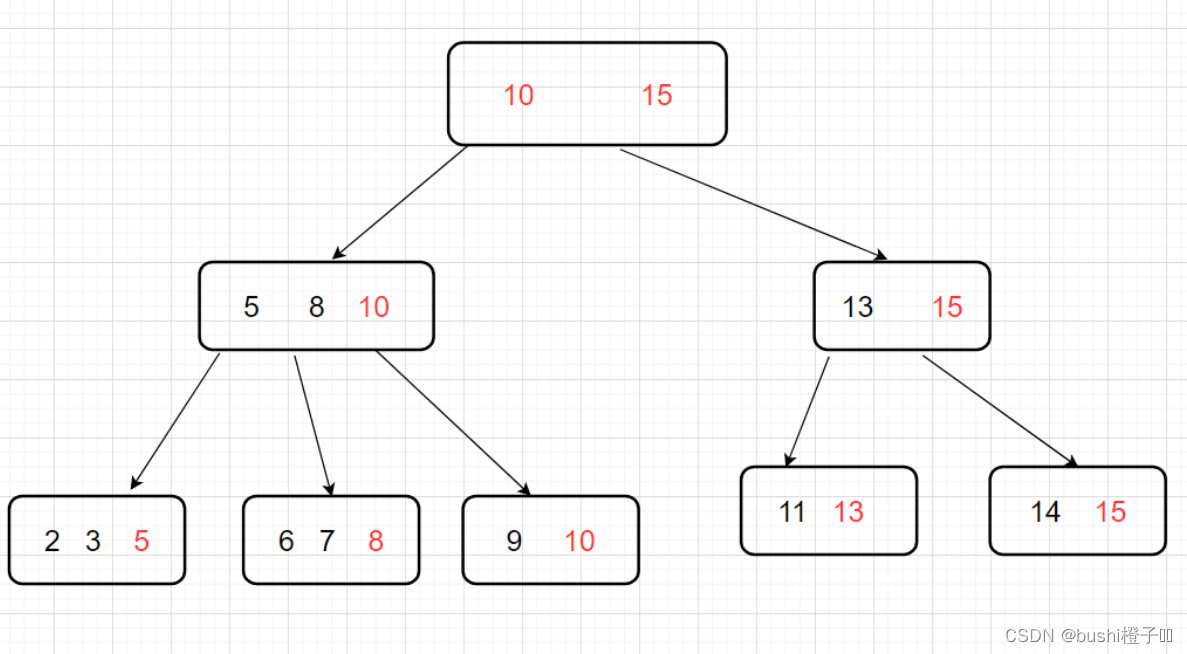
- 最后进行叶子首尾相连接
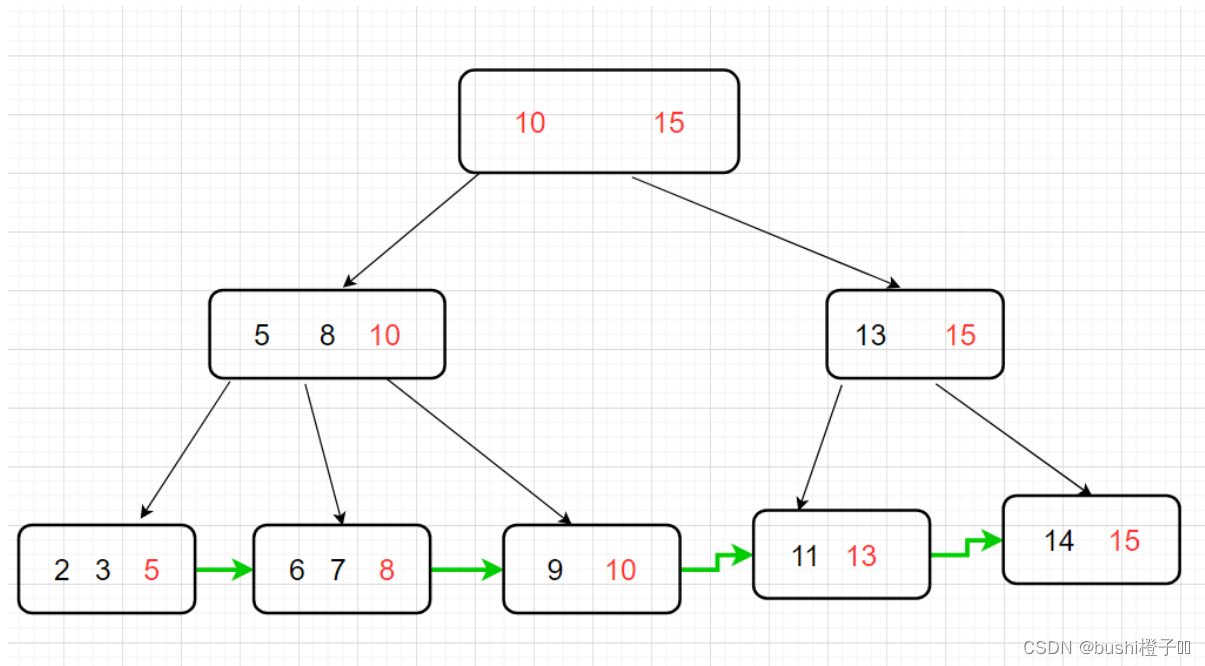
优点:
- 高度降下来了,比较的时候,硬盘IO次数少了。
- 更加适合范围查询。
- 所有的查询,都是在叶子节点完成。无论查询哪个元素,比较次数都是差不多的。相对于B树,查询次数就不平均了。
- 由于所有的key都在叶子节点上,因此非叶子节点,不必存表的真是记录。只需要把所有的数据行放在叶子节点上,非叶子节点只需要存索引列的值。【比如存个id】【存储方式有树形,表型,下面图是树形】
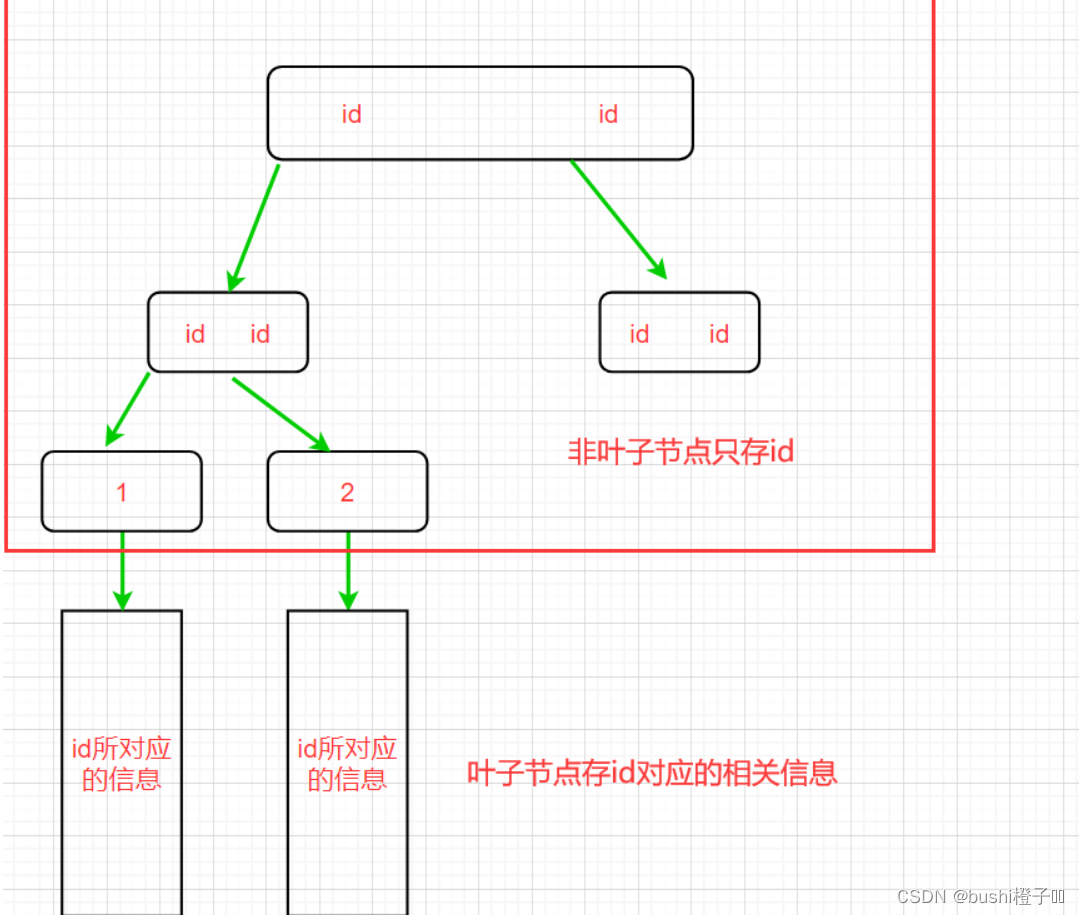
- 由于非叶子节点只存了id,所以导致占用空间就降低了,内存可以放进去了,更进一步降低了硬盘IO。
- 当前B+树是针对MySQL的InnoDB这个数据库引擎。不同引擎的存储结构还可能存在差异。
3. 事务
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
数据库会把每个执行操作记录下来,如果某个操作出错,就会把事务前面的操作进行“回滚”,就像是没有执行过一样。
回滚: 把执行过的操作逆向回复回去。
3.1 使用
- 1)开启事务:start transaction;
- 2)执行多个sql语句;
- 3)回滚或者提交:rollback / commit;
开启事务后,中间这些sql语句不会立即执行,而是积累,等commit再统一执行。(保证了”原子性“)
3.2 事务的四大特性
-
原子性
-
一致性
事务执行前/后,都得是数据合法的状态;比如不能出现数据丢失等情况。
- 持久性
事务产生修改,都是会写入硬盘,即使程序重启/主机重启/断电,事务都可以正常工作,保证修改有效。
- 隔离性【重点】
一个数据库服务器,同时执行多个事务的时候,事务之间的“相互的影响程度”。
a)“相互影响程度”:——“线程安全问题”,当多个事务同时去执行操作同一个表时,容易出现相互影响问题。
b)隔离性越高,意味着事务之间并发程度越 慢,数据准确性越高。
c)隔离性越低,意味着事物之间并发程度越快,数据准确性越低。
- 对于隔离性有不同的需求,MySQL提供了不同的档位:控制隔离性的高低/并发程度的高低/执行效率的高低/数据准确性高低。
隔离级别:
read umcommitted:不做任何限制,事务之间随意并发执行,并发程度高,隔离性最低,会产生脏读、不可重复读、幻读。read committed:对写操作加锁,并发程度降低,隔离性提高,解决脏读,仍存在 不可重复读、幻读。repeatable read:对读写都加锁,并发程度再次降低,隔离性再次提高,解决 脏读、不可重读,可能存在幻读。serializable: 严格串行化,并发程度最低【串行执行】,隔离性最高,解决 脏读、不可重复读、幻读。执行速度最快。
上述总结比较抽象,那就举个栗子吧~:
假如有:事务A在写数据、事务B在读数据,AB读写的是同一份数据【student表】。
- A读完之后就走了,而B把当前student表给删了,那么就称这种情况为**“脏读”** (dirty data)。表示这个数据是一个有问题的数据。【在这情况下是完全并发的,也就是会出现“脏读”】
为了解决“脏读”提供了**“写操作”进行“加锁”**:A在写数据时,B不准读数据。等A写完后并且提交后,才准看。【在这个情况下,也就降低并发程度,提高隔离性、数据准确性】
- 在约定“写加锁”情况下,A写完提交后,B开始读操作时,正在B读的时候,A突然又开始写操作进行修改,重新修改。于是导致了B在读操作时,数据突然就变化了。【这种情况称**“不可重复读”**:在一个事务中连续两次读的数据结果不一致】
为了解决“不可重复读”提供了对**"读操作"进行“加锁”**【隔离性进一步提高,并发再一次降低,执行速度再一次降低,数据准确性再一次提高】
- 在约定"写加锁"和“读加锁”情况下,当B在读的时候,A不能进行操作,那么A可以去执行其他的操作,比如新增删除其他的文件…于是B发现读的数据没变,而文件数量变了。【这种情况称**“幻读”**:在同一事务,两次读的的结果集不同】
重复读”提供了对**"读操作"进行“加锁”**【隔离性进一步提高,并发再一次降低,执行速度再一次降低,数据准确性再一次提高】
- 在约定"写加锁"和“读加锁”情况下,当B在读的时候,A不能进行操作,那么A可以去执行其他的操作,比如新增删除其他的文件…于是B发现读的数据没变,而文件数量变了。【这种情况称**“幻读”**:在同一事务,两次读的的结果集不同】
解决“幻读”:彻底放弃“并发”,进行串行化,只要B在读,A就不准任何操作,只能摸鱼~



![[附源码]java毕业设计学生实习管理系统](https://img-blog.csdnimg.cn/edf3c20609fb469cacbaa9d3dc92af42.png)