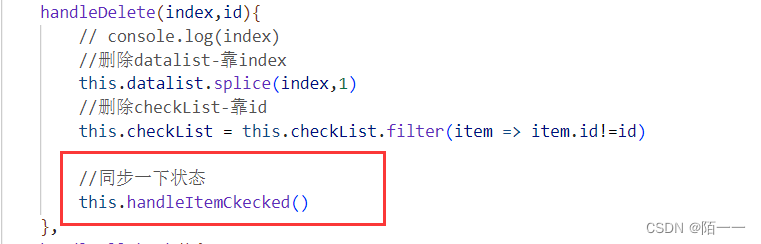
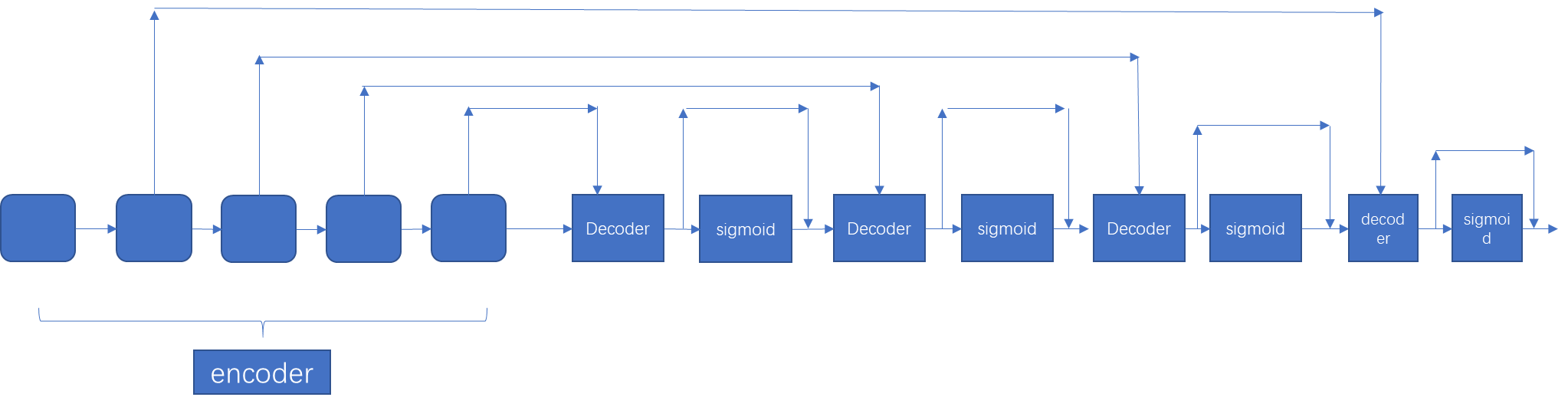
双decoder用于息肉分割。文章的创新点在与使用了双分支的decoder,单encoder的结构。decoder的第二个分支会产生注意力map,在代码中体现为输出通道为1。这个和之前看的confidence map很像。
看一下文章的结构图:
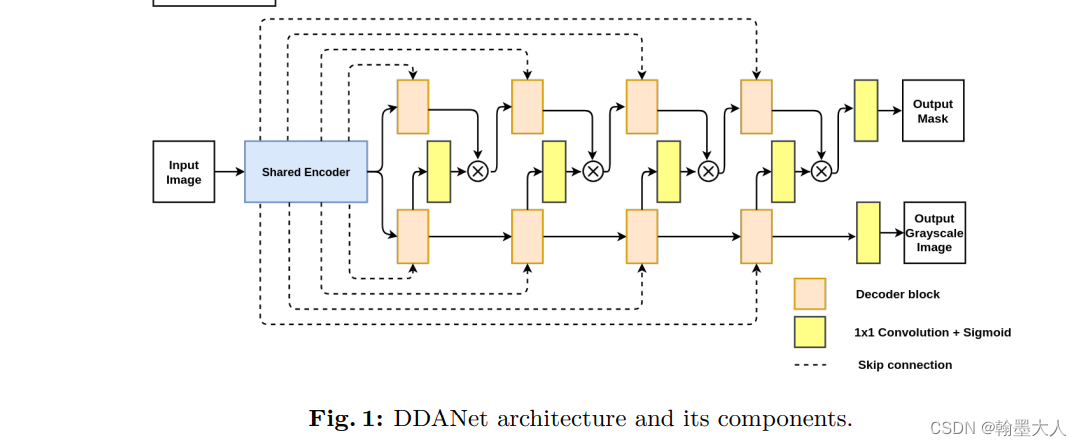
在decoder中,第二个分支生成注意力图,其实shared encoder的跳连接上下两个是一样的,在代码中可以看到,稍后分析。
encoder,decoder的构成:
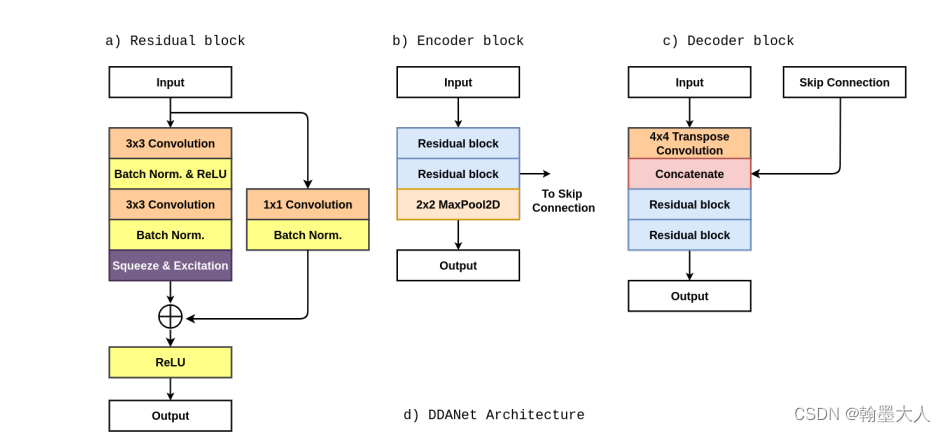
他这里使用的encoder不是原始的resnet,但是使用了resnet的思想,且在两个3x3卷积之后,加入了通道注意力,这个在ESANet中RGB和Depth融合方法中也有用到。
在decoder使用的4倍转置卷积,和encoder的特征进行concat,和RedNet的跳连接结构,和上采样结构都很像。
实验:
医学图像的数据集,不太了解。
------------------------------------------------------分割线-------------------------------------------------------------------------------------------------------------------------
代码:
import torch
import torch.nn as nn
import torchvision.models as models
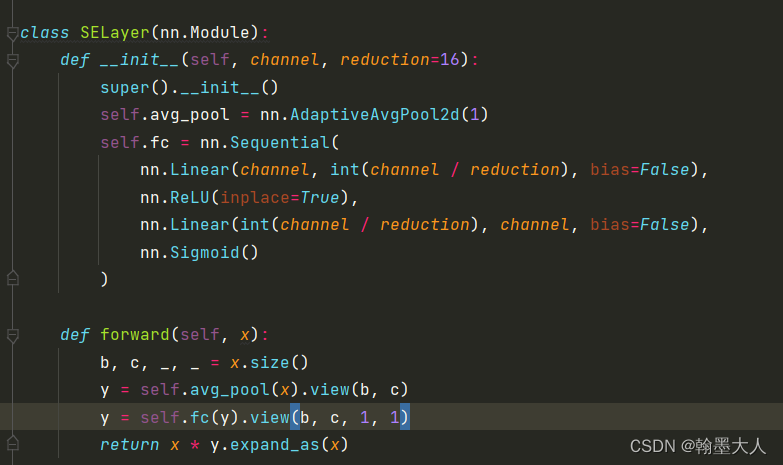
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, int(channel / reduction), bias=False),
nn.ReLU(inplace=True),
nn.Linear(int(channel / reduction), channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class ResidualBlock(nn.Module):
def __init__(self, in_c, out_c):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_c, out_c, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(out_c)
self.conv2 = nn.Conv2d(out_c, out_c, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_c)
self.conv3 = nn.Conv2d(in_c, out_c, kernel_size=1, padding=0)
self.bn3 = nn.BatchNorm2d(out_c)
self.se = SELayer(out_c)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x1 = self.conv1(x)
x1 = self.bn1(x1)
x1 = self.relu(x1)
x2 = self.conv2(x1)
x2 = self.bn2(x2)
x3 = self.conv3(x)
x3 = self.bn3(x3)
x3 = self.se(x3)
x4 = x2 + x3
x4 = self.relu(x4)
return x4
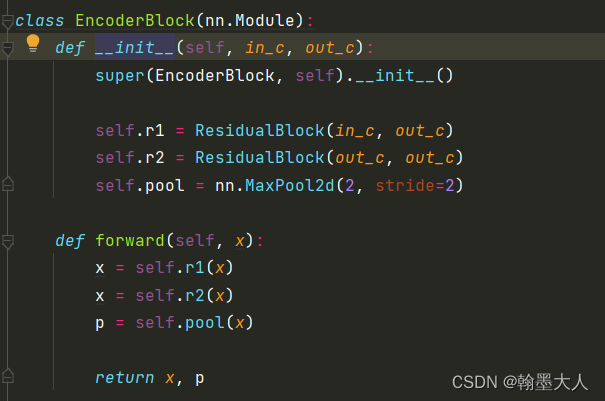
class EncoderBlock(nn.Module):
def __init__(self, in_c, out_c):
super(EncoderBlock, self).__init__()
self.r1 = ResidualBlock(in_c, out_c)
self.r2 = ResidualBlock(out_c, out_c)
self.pool = nn.MaxPool2d(2, stride=2)
def forward(self, x):
x = self.r1(x)
x = self.r2(x)
p = self.pool(x)
return x, p
class DecoderBlock(nn.Module):
def __init__(self, in_c, out_c):
super(DecoderBlock, self).__init__()
self.upsample = nn.ConvTranspose2d(in_c, out_c, kernel_size=4, stride=2, padding=1)
self.r1 = ResidualBlock(in_c+out_c, out_c)
self.r2 = ResidualBlock(out_c, out_c)
def forward(self, x, s):
x = self.upsample(x)
x = torch.cat([x, s], axis=1)
x = self.r1(x)
x = self.r2(x)
return x
class CompNet(nn.Module):
def __init__(self):
super(CompNet, self).__init__()
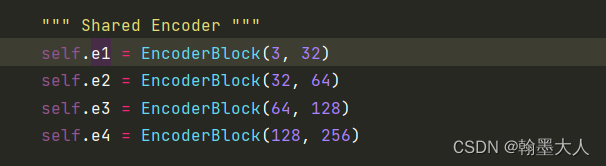
""" Shared Encoder """
self.e1 = EncoderBlock(3, 32)
self.e2 = EncoderBlock(32, 64)
self.e3 = EncoderBlock(64, 128)
self.e4 = EncoderBlock(128, 256)
""" Decoder: Segmentation """
self.s1 = DecoderBlock(256, 128)
self.s2 = DecoderBlock(128, 64)
self.s3 = DecoderBlock(64, 32)
self.s4 = DecoderBlock(32, 16)
""" Decoder: Autoencoder """
self.a1 = DecoderBlock(256, 128)
self.a2 = DecoderBlock(128, 64)
self.a3 = DecoderBlock(64, 32)
self.a4 = DecoderBlock(32, 16)
""" Autoencoder attention map """
self.m1 = nn.Sequential(
nn.Conv2d(128, 1, kernel_size=1, padding=0),
nn.Sigmoid()
)
self.m2 = nn.Sequential(
nn.Conv2d(64, 1, kernel_size=1, padding=0),
nn.Sigmoid()
)
self.m3 = nn.Sequential(
nn.Conv2d(32, 1, kernel_size=1, padding=0),
nn.Sigmoid()
)
self.m4 = nn.Sequential(
nn.Conv2d(16, 1, kernel_size=1, padding=0),
nn.Sigmoid()
)
""" Output """
self.output1 = nn.Conv2d(16, 1, kernel_size=1, padding=0)
self.output2 = nn.Conv2d(16, 1, kernel_size=1, padding=0)
def forward(self, x):
""" Encoder """
x1, p1 = self.e1(x)
x2, p2 = self.e2(p1)
x3, p3 = self.e3(p2)
x4, p4 = self.e4(p3)
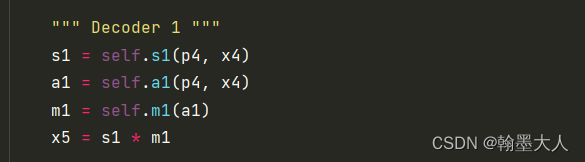
""" Decoder 1 """
s1 = self.s1(p4, x4)
a1 = self.a1(p4, x4)
m1 = self.m1(a1)
x5 = s1 * m1
""" Decoder 2 """
s2 = self.s2(x5, x3)
a2 = self.a2(a1, x3)
m2 = self.m2(a2)
x6 = s2 * m2
""" Decoder 3 """
s3 = self.s3(x6, x2)
a3 = self.a3(a2, x2)
m3 = self.m3(a3)
x7 = s3 * m3
""" Decoder 4 """
s4 = self.s4(x7, x1)
a4 = self.a4(a3, x1)
m4 = self.m4(a4)
x8 = s4 * m4
""" Output """
out1 = self.output1(x8)
out2 = self.output2(a4)
return out1, out2
if __name__ == "__main__":
x = torch.rand((1, 3, 512, 512))
model = CompNet()
y1, y2 = model.forward(x)
我们直接看forward函数:
1:首先就是输入的x经过四个encoder block
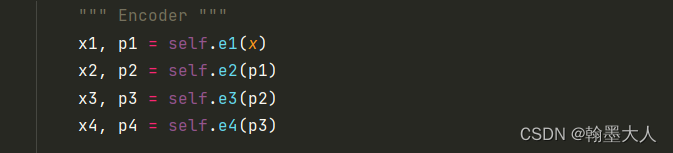
每个block中包含的residual block:
class ResidualBlock(nn.Module):
def __init__(self, in_c, out_c):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_c, out_c, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(out_c)
self.conv2 = nn.Conv2d(out_c, out_c, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_c)
self.conv3 = nn.Conv2d(in_c, out_c, kernel_size=1, padding=0)
self.bn3 = nn.BatchNorm2d(out_c)
self.se = SELayer(out_c)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x1 = self.conv1(x)
x1 = self.bn1(x1)
x1 = self.relu(x1)
x2 = self.conv2(x1)
x2 = self.bn2(x2)
x3 = self.conv3(x)
x3 = self.bn3(x3)
x3 = self.se(x3)
x4 = x2 + x3
x4 = self.relu(x4)
return x4
以第一个为例:输入通道为3,输出通道为32.
经过两个3x3卷积,然后一个1x1卷积的残差连接,注意,这里经过1x1卷积之后才经过SElayer。和图中画的有些不同。
SELayer:和之前看的通道注意力一样,首先经过平均池化,然后经过两个线性层,最后与原始的x相乘得到最终的结果。
每个encoder block包含两个残差块,一个2x2最大池化。注意这里返回的是x,用来跳连接的。 x, p对应于x1, p1 。同理x2为p1。encoder结束后,两个输出分别经过两个decoder分支。

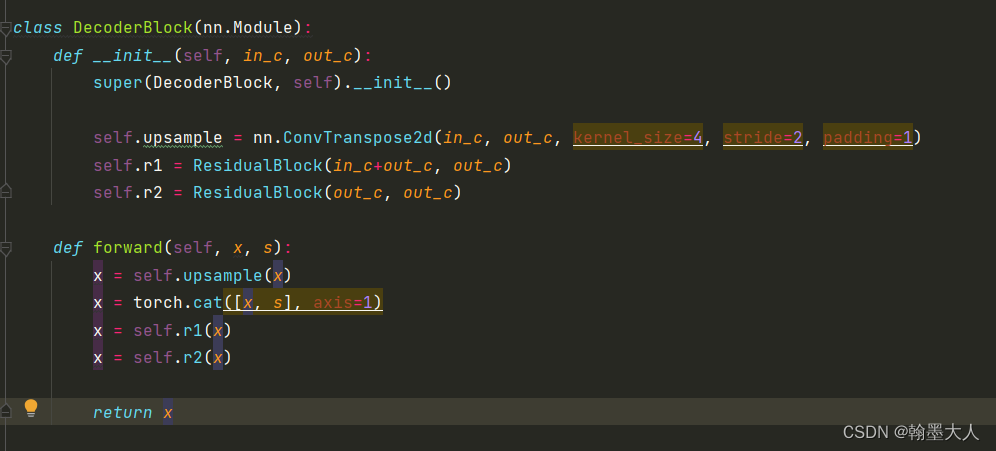
在decoder block中首先通过转置卷积进行上采样四倍,然后和跳连接相concat,再经过两个残差块。而另一条分支的处理和这一条一样的。

不同的是第二条分支产生的结果是一个注意力图。通过一个卷积生成通道为1的attention map,这里医学分割图的最终结果就是单通道,如果是其他的数据集即时多通道,即这里其实相当于之前说的置信度图。
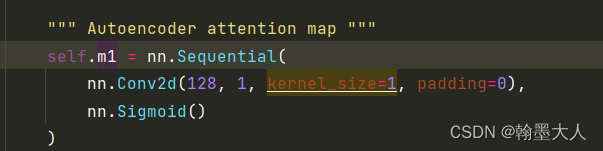
生成的置信度图与第一条分支产生的结果相乘,这样执行四次。
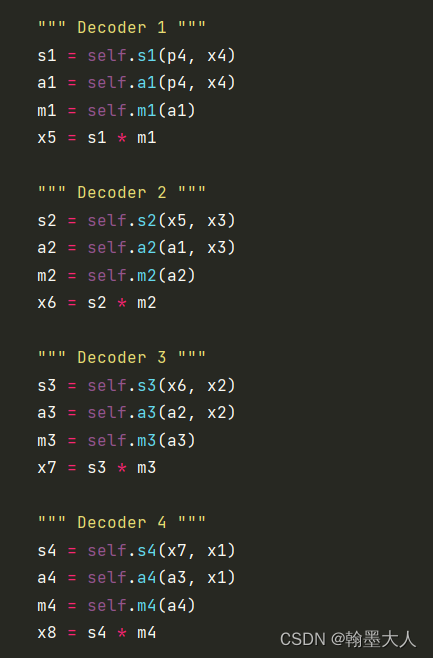
最终的输出经过两个通道为1的卷积,即最终的分割图。
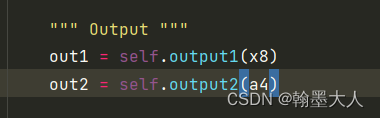
整个网络框架可以简化为:





![[附源码]java毕业设计校园疫情防控管理系统](https://img-blog.csdnimg.cn/ee4aacd7f4d740bfbef7f79c5b28979d.png)