二叉排序树BST
二叉排序树,又称二叉查找树(BST,Binary Search Tree)
二叉排序树是左子树节点值<根节点值<右子树节点值的二叉树
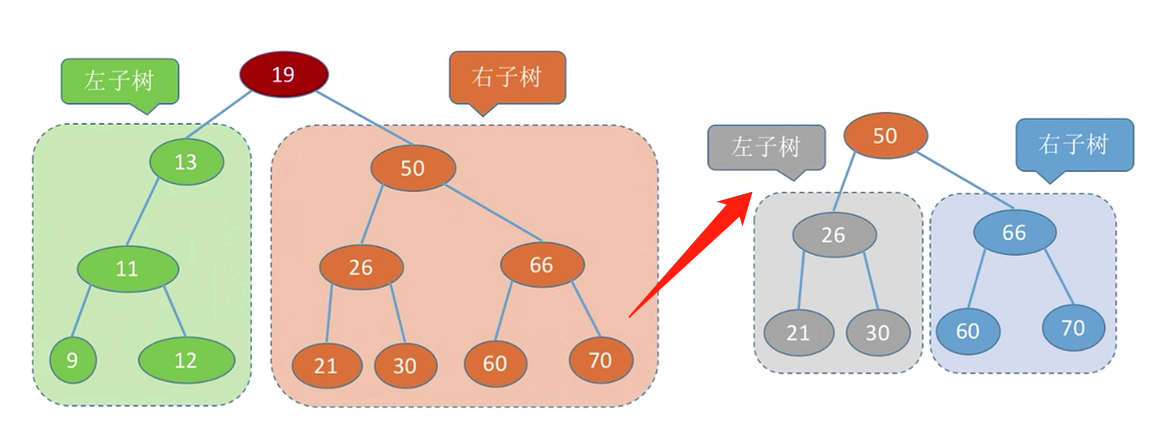
所以对二叉排序树进行中序遍历会得到一个递增的序列(左子树-根-右子树)
1. 二叉排序树的查找
若树非空,目标值与根结点的值比较
- 若相等,则查找成功;
- 若小于根结点,则在左子树上查找
- 若大于根节点在右子树上查找。
查找成功,返回结点指针;查找失败返回NULL,分为递归和非递归两种算法
排序二叉树非递归查找:最坏时间复杂度O(1)-nice
//在二叉排序树中查找值为key 的结点
BSTNode* BST_Search(BSTNode* T, BSTDataType key) {
BSTNode* cur = T;
while (cur != NULL) {//指针空则结束循环
if (key == cur->data) return cur;
else if (key < cur->data)cur = cur->left;//小于查找左子树
else cur = cur->right;//大于查找右子树
}
return cur;//此时cur就是NULL
}
排序二叉树递归查找:比根节点大,就到右子树查找。比根节点小,就到左子树查找。排序二叉树的递归查找最坏时间复杂度为O(n),最坏情况就是递归到排序二叉树的最大深度
//在二叉排序树中查找值为key 的结点
BSTNode* BST_Search(BSTNode* root, BSTDataType key) {
if (!root)return NULL;
else if (key == root->data)return root;
else if (key < root->data) return BST_Search(root->left,key);
else return BST_Search(root->right, key);
}
2. 二叉排序树的插入
若原二叉排序树为空,则直接插入结点;否则,若关键字k小于根结点值,则插入到左子树,若关键字k大于根结点值,则插入到右子树
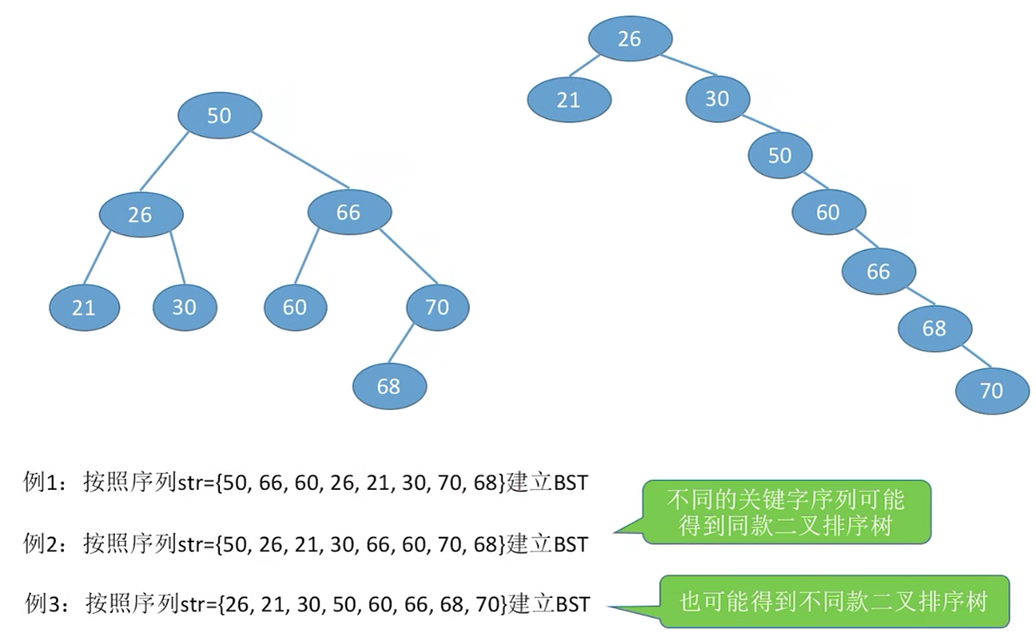
可以发现插入的位置一定是叶子节点的下方!二叉排序树的插入就是二叉排序树不断向下延申的过程,不会出现中间插入的情况。同一组节点可以形成不同的二叉排序树的结构,但其中序遍历一定都是递增数列。
二叉排序树的插入算法有递归和非递归。
二叉排序树递归插入算法:最坏空间复杂度为O(n)
//插入节点
bool insert(BSTNode*& root, BSTDataType data) {
if (root == NULL) {
root = (BSTNode*)malloc(sizeof(BSTNode));
root->data = data;
root->left = NULL;
root->right = NULL;
return true;
}
else if (data == root->data) {
return false;//树中存在下个相同关键字结点,插入失败
}
else if (data < root->data) {
insert(root->left, data);
}
else {
insert(root->right, data);
}
}
二叉排序树非递归插入算法:
//插入节点
bool insert(BSTNode*& root, BSTDataType data) {
//空树直接填充
if (!root) {
root = (BSTNode*)malloc(sizeof(BSTNode));
root->left = NULL;
root->right = NULL;
root->data = data;
return true;
}
//非空二叉排序树需要找到,需要插入位置的根结点!
BSTNode* cur = root;
while (true) {
if (data < cur->data) {
if (cur->left == NULL) {
BSTNode* temp = (BSTNode*)malloc(sizeof(BSTNode));
temp->left = NULL;
temp->right = NULL;
temp->data = data;
cur->left = temp;
return true;
}
else cur = cur->left;
}
else if (data > cur->data) {
if (cur->right == NULL) {
BSTNode* temp = (BSTNode*)malloc(sizeof(BSTNode));
temp->left = NULL;
temp->right = NULL;
temp->data = data;
cur->right = temp;
return true;
}
else cur = cur->right;
}
else {
return false;//树中存在相等的结点,插入失败
}
}
}
3. 二叉排序树的构造
实际上就是根据数值,不断进行二叉树插入操作的过程。所以这里需要引用上面二叉排序树的插入函数
参考代码如下:
void creatBSTree(BSTNode*& root,int* array,int arrayLength){
root=NULL;
for(int i=0;i<arrayLength;i++){
insert(root,array[i]);
}
}
值得注意,不同的序列构建的二叉排序树可能一样,也可能不一样。但这些二叉排序树的中序遍历一定都是一样的。
4. 二叉排序树的删除
先搜索找到目标结点-(前面右谈过二叉排序树的查找函数)
插入的宗旨就是不会破坏二叉排序树的性质(左子树节点值<根节点值<右子树节点值)
-
若被删除结点z是叶结点,则直接删除,不会破坏二叉排序树的性质。
-
若结点z只有左子树或只有右子树,则让z的子树成为z父结点的子树,替代z的位置。
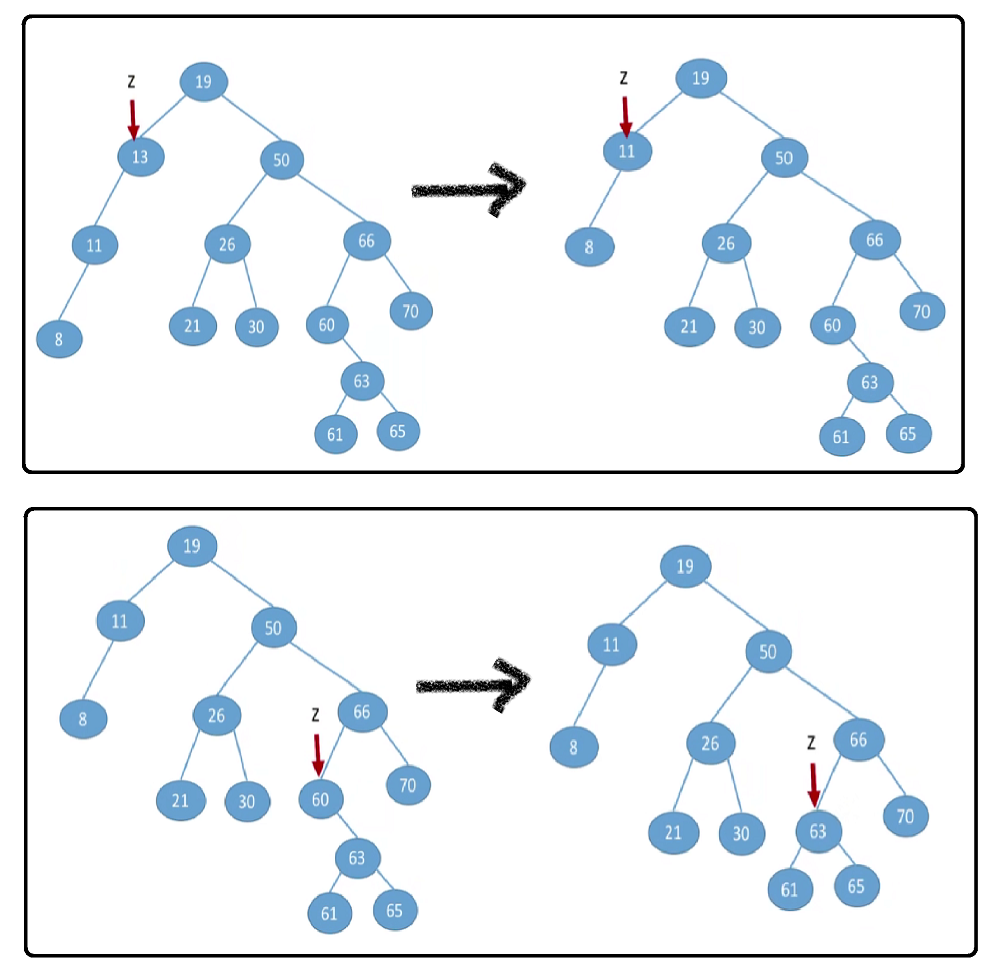
-
若结点z有左、右两棵子树,则令结点z的直接后继(或直接前驱)替代结点z,然后从二叉排序树中删去这个直接后继(或直接前驱),这样就转换成了第一或第二种情况。
- 令结点z的直接后继(或直接前驱)替代z结点?实际上就是让右子树中最小的值(直接后继)覆盖结点z或者左子树中最大值(直接前驱)覆盖结点z任然满足二叉排序树的特性。
- 因为结点z的直接后继或直接前驱,分别是右子树中最左下的元素,和左子树中最右下元素。不可能同时又左右子树,所以就能回归前两种情况了。
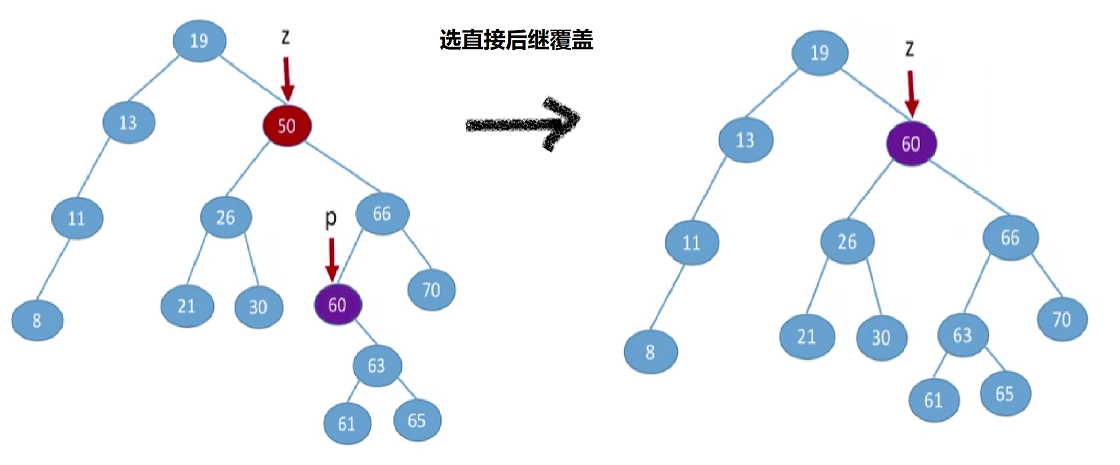
5. 查找效率分析
查找长度――在查找运算中,需要对比关键字的次数称为查找长度,反映了查找操作时间复杂度
5.1 查找成功的平均查找长度ASL (Average Search Length)
每一个结点的查找长度之和除以结点总数=ASL
对于n个节点的二叉树,二叉树的最小高度是⌊log2n⌋+1,最大高度为n,当二叉排序树高度接近于⌊log2n⌋+1,该二叉排序树查找成功的查找效率最高。
5.2 查找失败的平均查找长度ASL (Average Search Length)
对于查找失败就是指针最后停留在了空指针域,计算停留在每一个空指针域的查找长度之和除以空指针域总数(3 * 7+4 * 2)/9=3.22:
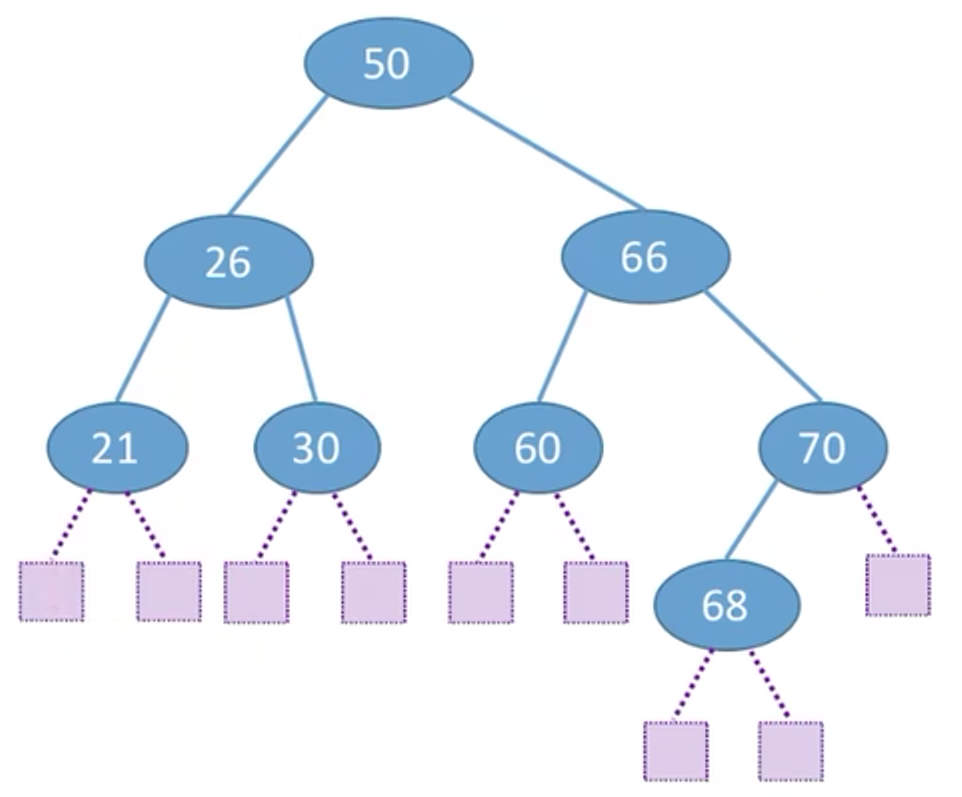
对于n个节点的二叉树,二叉树的最小高度是⌊log2n⌋+1,最大高度为n,当二叉排序树高度接近于⌊log2n⌋+1,该二叉排序树查找失败的查找效率最高。
高度接近⌊log2n⌋+1的二叉排序树查找成功和查找失败的查找效率都是最高的,也就是平衡二叉树
平衡二叉树AVL
平衡二叉树(Balanced Binary Tree),简称平衡树(AVL树)――树上任一结点的左子树和右子树的高度之差不超过1。(AVL是科学家命名)
结点的平衡因子=左子树高度-右子树高度。平衡二叉树的平衡因子值为0,-1,1。只要任意结点的平衡因子大于1,就不是平衡二叉树。
参考代码:
struct AVLNode{
int key;
int balance;
AVLNode *left,*right;
}AVLNode,*AVLTree;
当二叉排序树达到平衡时,查找效率最高。对于n个节点的排序二叉树其高度最小为⌊log2n⌋+1,所以对应的AVL二叉树的查找效率为log2n,那么二叉排序树插入新节点如何保持平衡?
1. 二叉树的插入
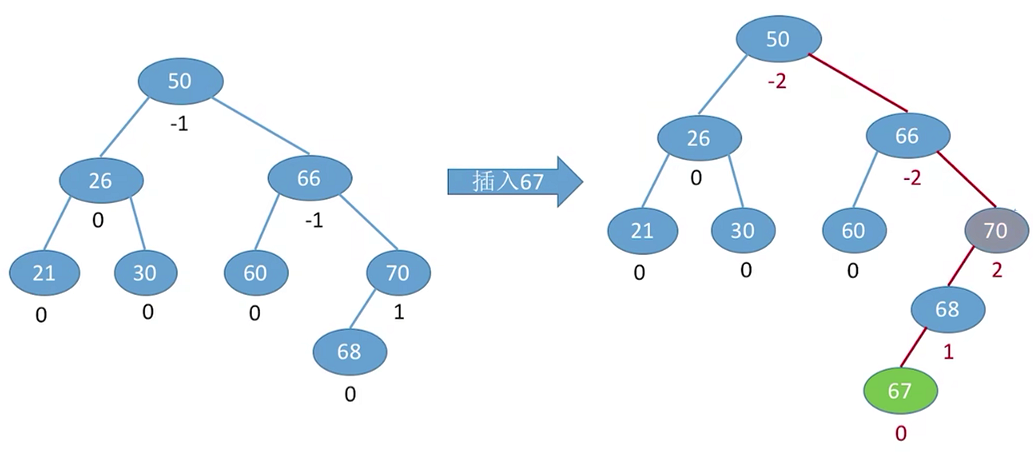
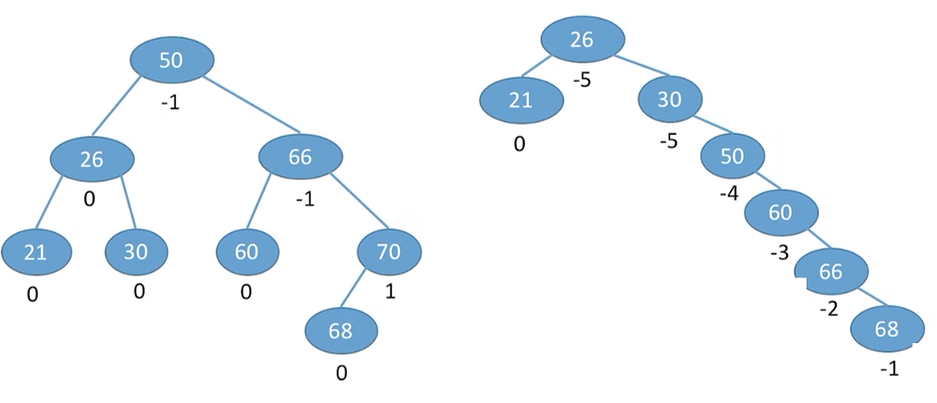
可以看到每插入一个新节点,查找路径上所有结点的平衡因子都可能受到影响。对此我们的策略是调整最小不平衡子树。所谓的最小不平衡子树就是从插入点往回找到第一个不平衡的结点,以该节点构成的子树就是最小不平衡子树。对上述二叉树的调整如下:
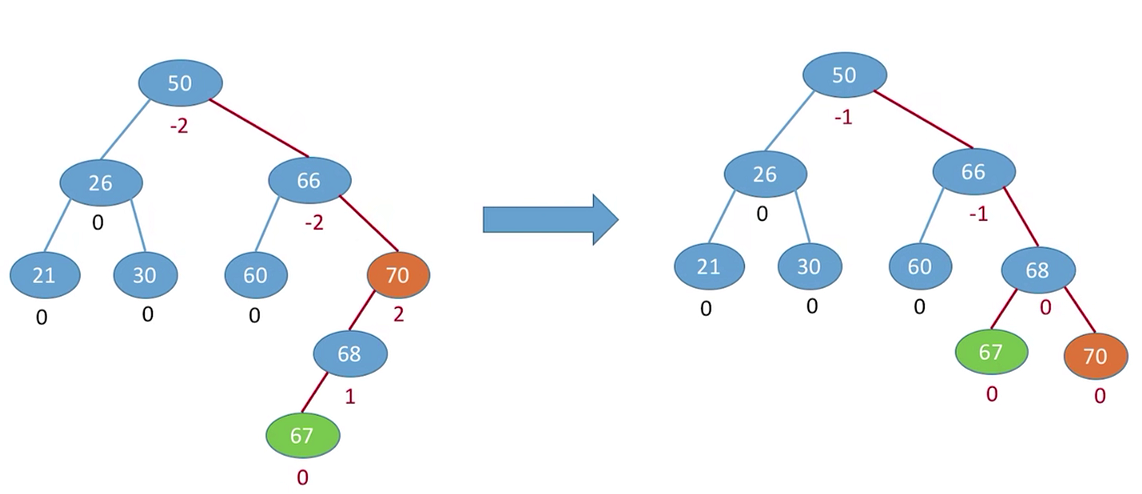
可以发现调整完最小不平衡二叉树,其余所有节点都平衡
2. 调整最小不平衡子树
只要将最小不平衡子树调整平衡,那么其他祖先结点都将恢复平衡。那么为什么?
对于一颗平衡二叉树,如果插入一个结点破坏了平衡。是因为最小平衡二叉树对比插入前高度增加了一!导致其祖先结点对应的子树全部增加一,使得平衡因子异常,我们所做的调整就是==回复最小不平衡子树的高度==,这样祖先结点相应子树高度也就回复了,排序树重新平衡!
我们先抽象出来最小平衡二叉树的模型:平衡二叉树的左右子树高度相差小于等于1,但对于高度差等于零平衡二叉树插入结点不会破坏平衡。我们考虑的是插入结点后能破坏平衡的模型,所以就得到了左右子树高度差相差1的最小平衡树,当我们进行LL的方式插入,可以看到平衡性收到破坏。
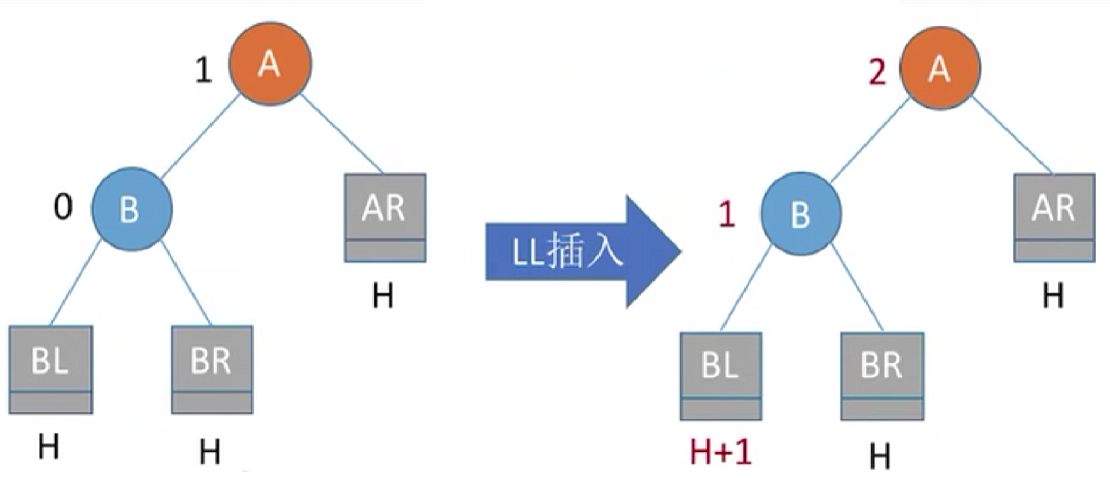
我们要做的就是通过调整,让树恢复平衡并且保持排序二叉树的特点。
二叉排序树的特性:左子树结点值<根结点值<右子树结点值
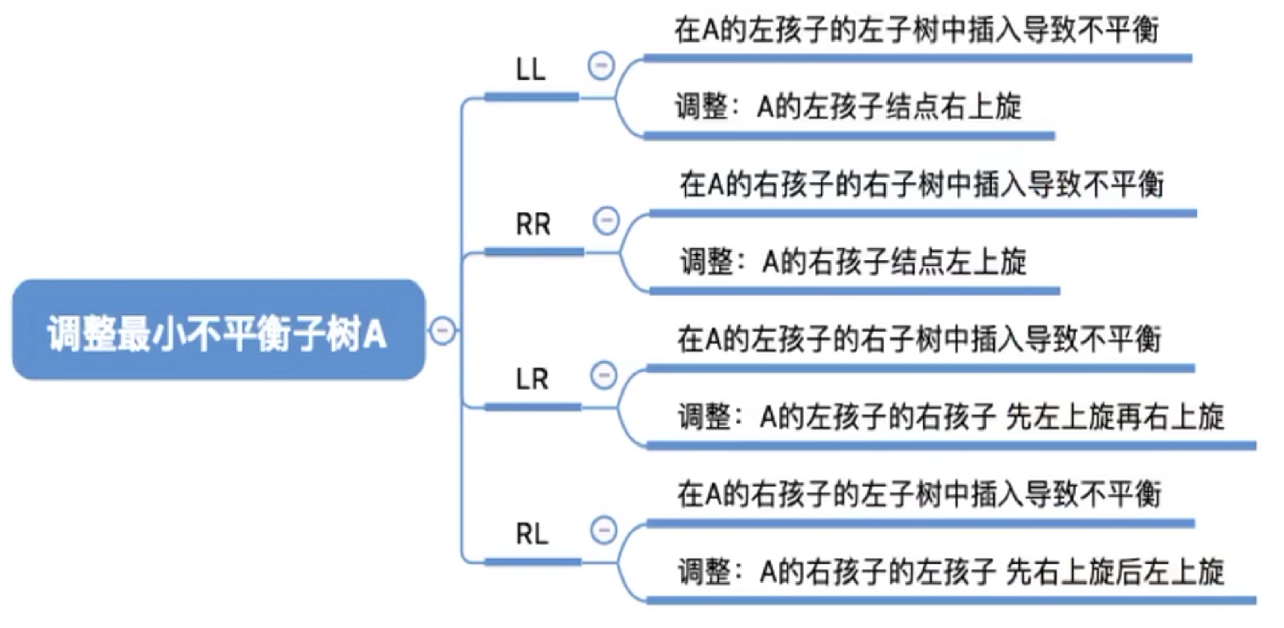
对于可能导致平衡二叉树被破坏的插入操作有四种:
下面我们来分别讨论这四种情况
2.1 LL左孩子的左孩子
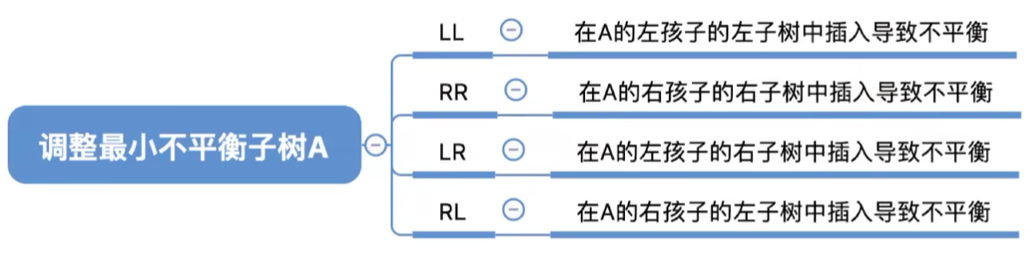
LL平衡旋转(右单旋转)。由于在结点A的左孩子的左子树上插入了新结点,A的平衡因子由1增至2,导致以A为根的子树失去平衡。
调整方式为:左孩子右上旋。将A的左孩子B向右上旋转代替A成为根结点,将A结点向右下旋转成为B的右子树的根结点,而B的原右子树则作为A结点的左子树。
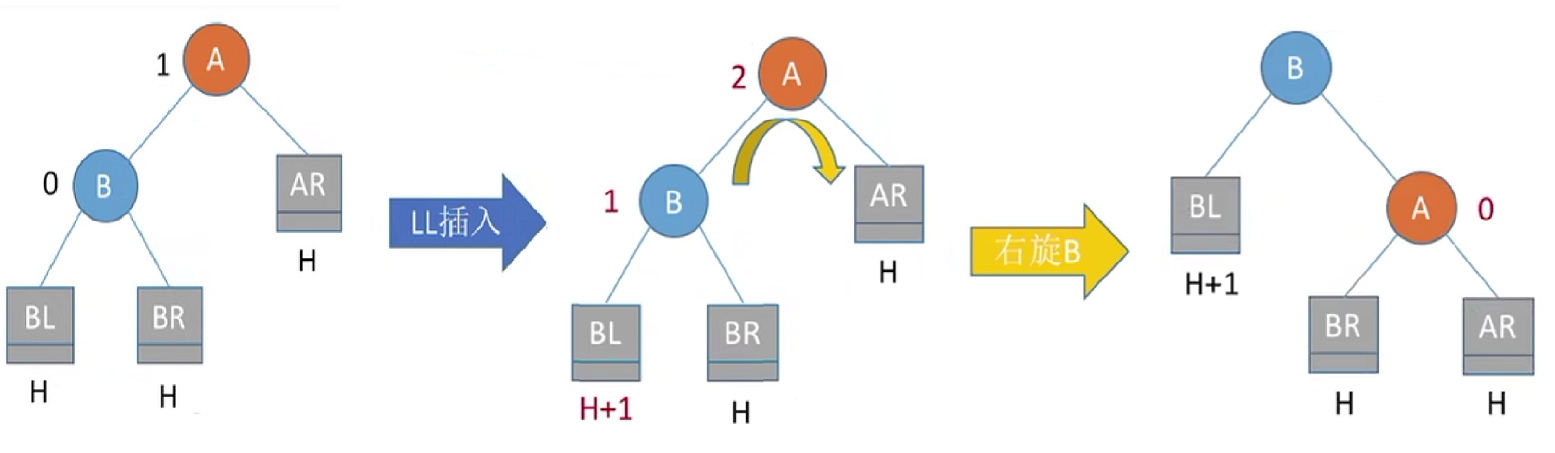
代码实现其实就是调整了三个指针,LL插入平衡调整如下:
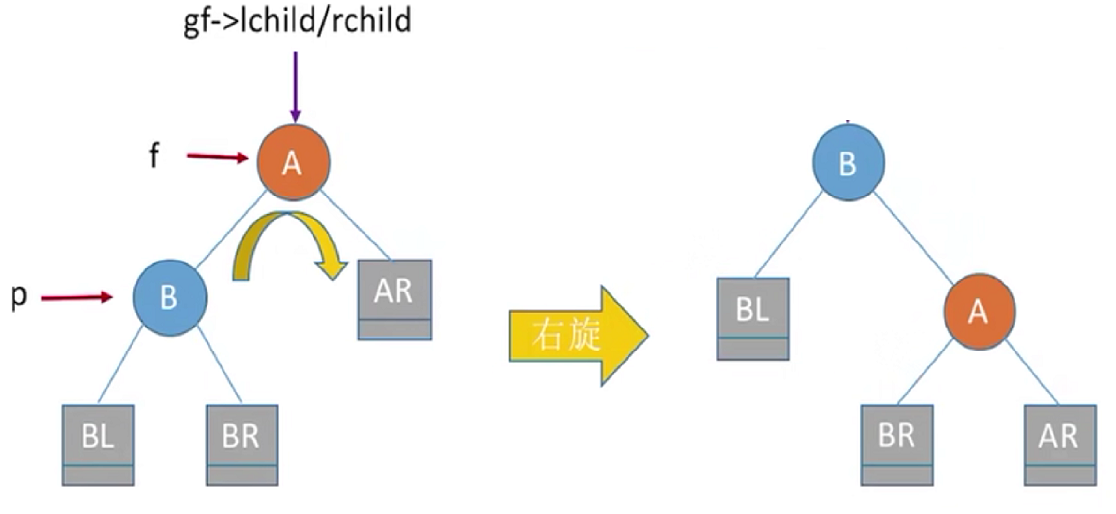
实现右下旋操作,f指向根结点,p指向左孩子,gf指向根节点的双亲结点
修改三个指针,注意顺序:
f->lchild=p->rchild;
gf->lchild=p;//或者gf->rchild=p;
p->rchild=f;
2.2 RR右孩子的右孩子
RR平衡旋转(左单旋转)。由于在结点A的右孩子的右子树上插入了新结点,A的平衡因子由-1减至-2,导致以A为根的子树失去平衡。
调整方式为:右孩子左上旋。将A的右孩子B向左上旋转代替A成为根结点,将A结点向左下旋转成为B的左子树的根结点,而B的原左子树则作为A结点的右子树
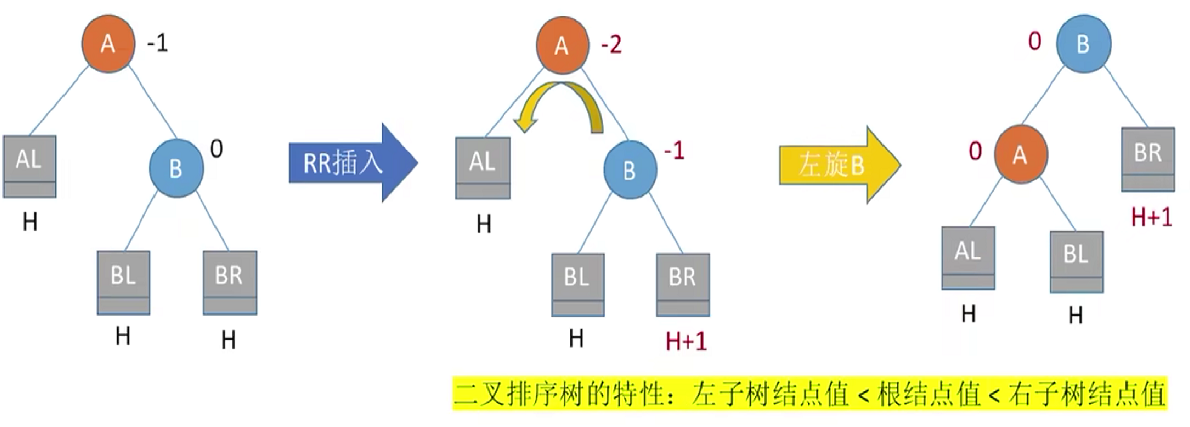
代码实现其实就是调整了三个指针,RR插入平衡调整如下:
实现右下旋操作,f指向根结点,p指向右孩子,gf指向根节点的双亲结点
修改三个指针,注意顺序:
f->rchild=p->lchild;
p->lchild=f;
gf->lchild=p;//gf->rchild=p;
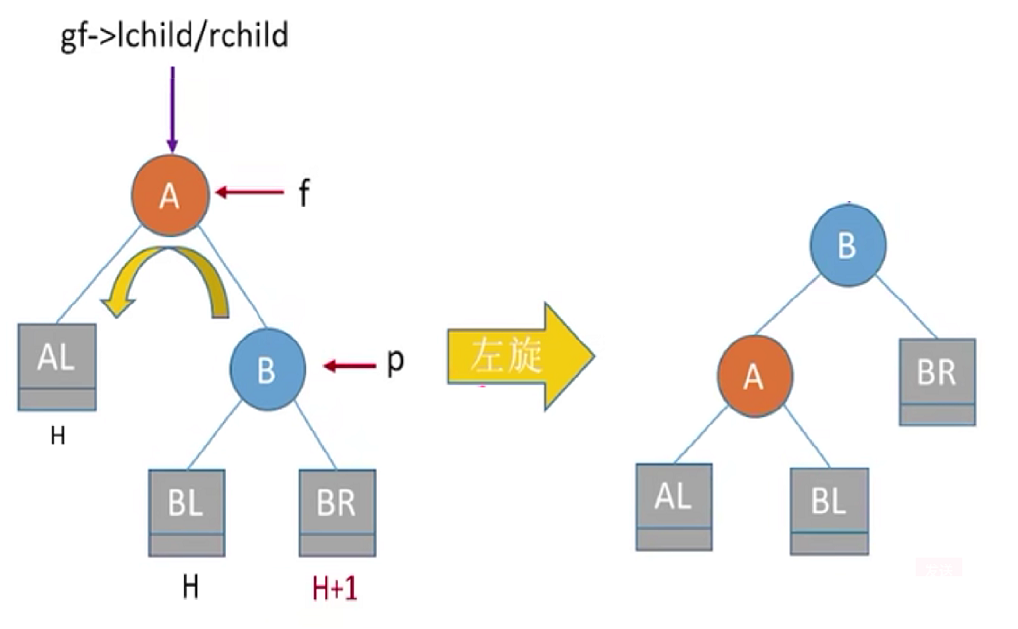
2.3 LR左孩子的右孩子
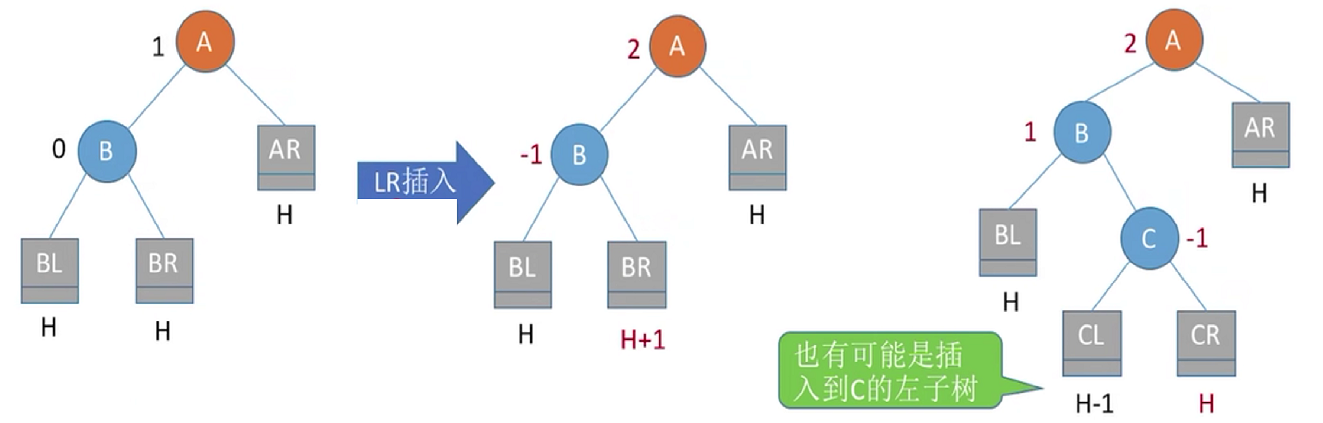
LR平衡旋转(先左后右双旋转)。由于在A的左孩子的右子树上插入新结点,A的平衡因子由1增至2,导致以A为根的子树失去平衡
调整犯法如下:左孩子的右孩子,先左上旋后右上旋。先将A结点的左孩子B的右子树的根结点C向左上旋转提升到B结点的位置,然后再把该C结点向右上旋转提升到A结点的位置。
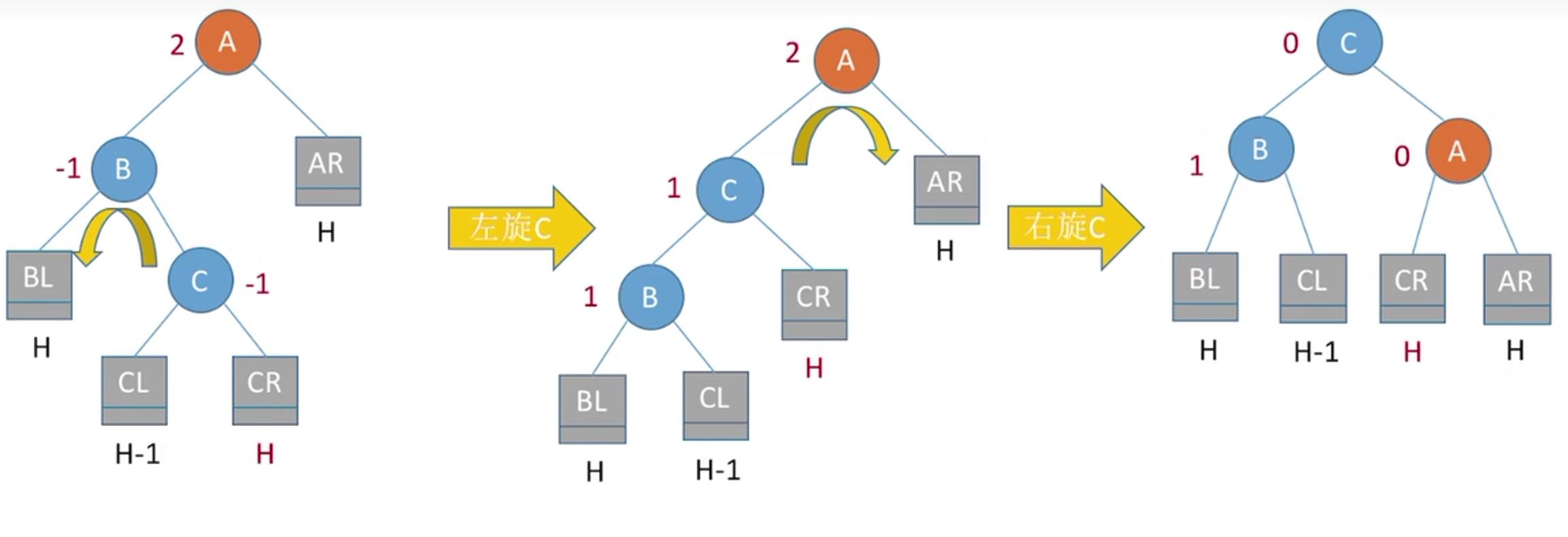
代码实现就是左旋和右旋,上面讲过了,可以封装一个方法,分别用于左旋右旋,参数传的是根结点的双亲。上面讲解的是插入左孩子的右子树的右子树,对于插入左孩子的右子树的左子树的处理方式也是一样的。就是下面的这种情况:
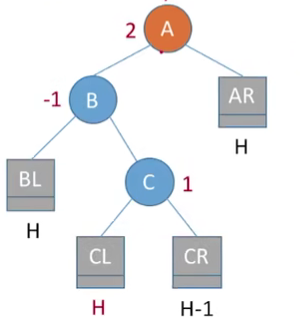
2.4 RL右孩子的左孩子
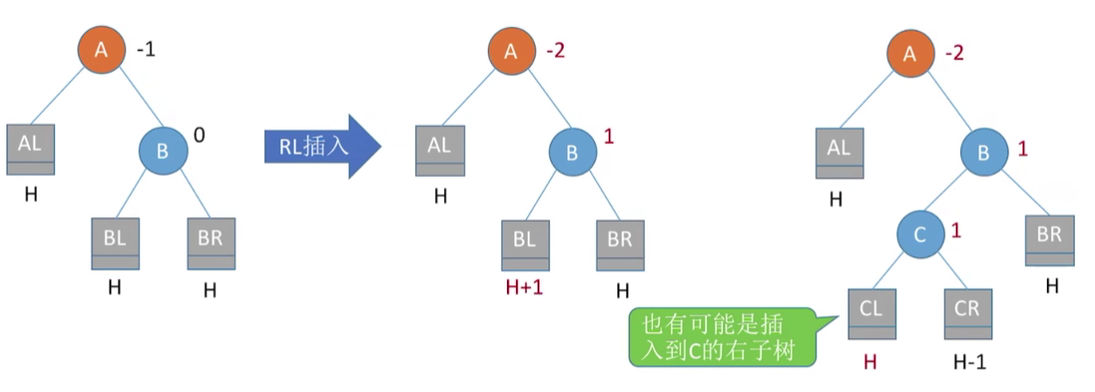
RL平衡旋转(先右后左双旋转)。由于在A的右孩子的左子树上插入新结点,A的平衡因子由-1减至-2,导致以A为根的子树失去平衡.
调整的方式是:右孩子的左孩子,先右上旋转后左上旋转。先将A结点的右孩子B的左子树的根结点c向右上旋转提升到B结点的位置,然后再把该c结点向左上旋转提升到A结点的位置
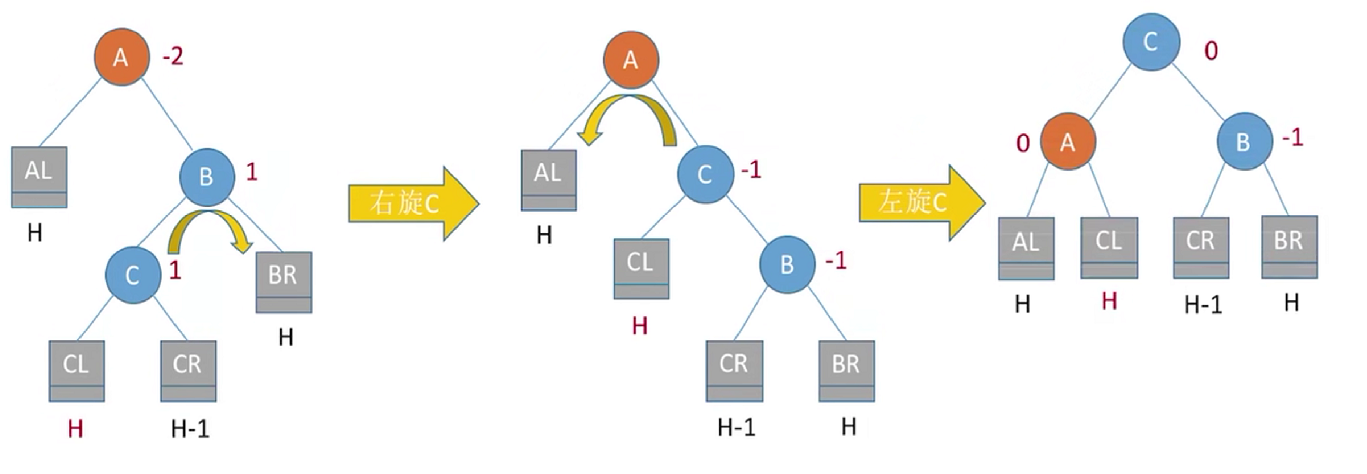
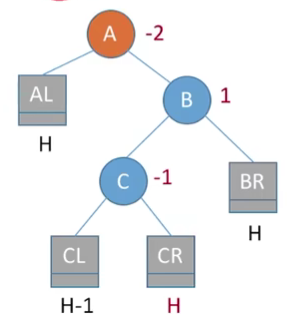
代码实现就是右孩子右上旋,自己左上旋。上面讲的是插入右孩子的左子树的左子树,至于插入右孩子左子树的右子树处理也是一样的,就是下面的这种情况:
2.5 总结
只有左孩子才能右旋,只有右孩子才能左旋。而具体左旋右旋操作固定:

对于调整策略
2.6 案例
实际问题我们应该如何寻找最小不平衡子树呢?首先排序树插入征程插入就行,然后沿着二叉排序树查找路径寻找,最后一个平衡因子异常的就是对应的最小不平衡子树的根结点
例1
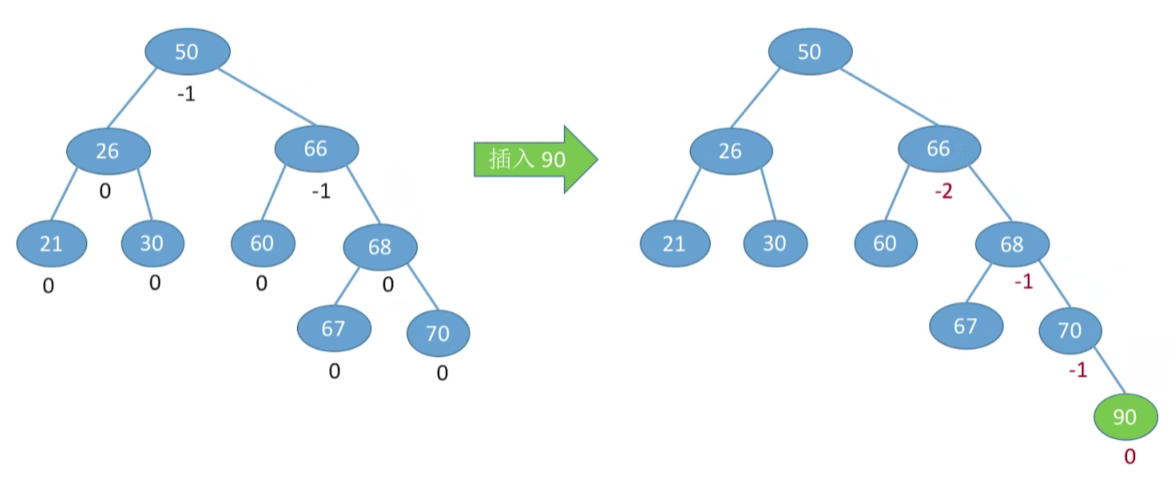
RR型,就是右孩子的右孩子插入调整问题,方法就是右孩子左上旋(此类左孩子右孩子都是相对于最小不平衡二叉树的根节点来说的。孩子变爹,爹变孩子)
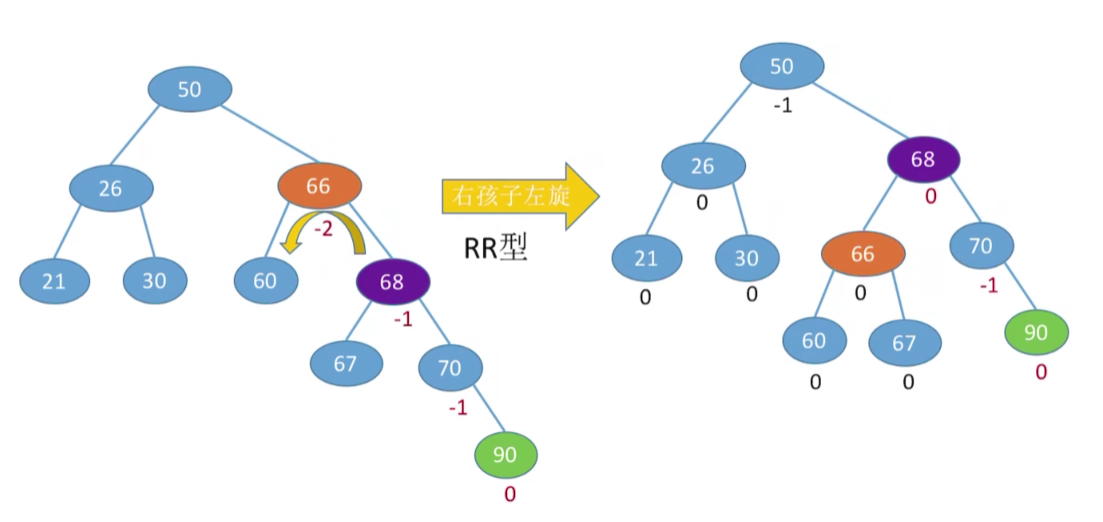
例二
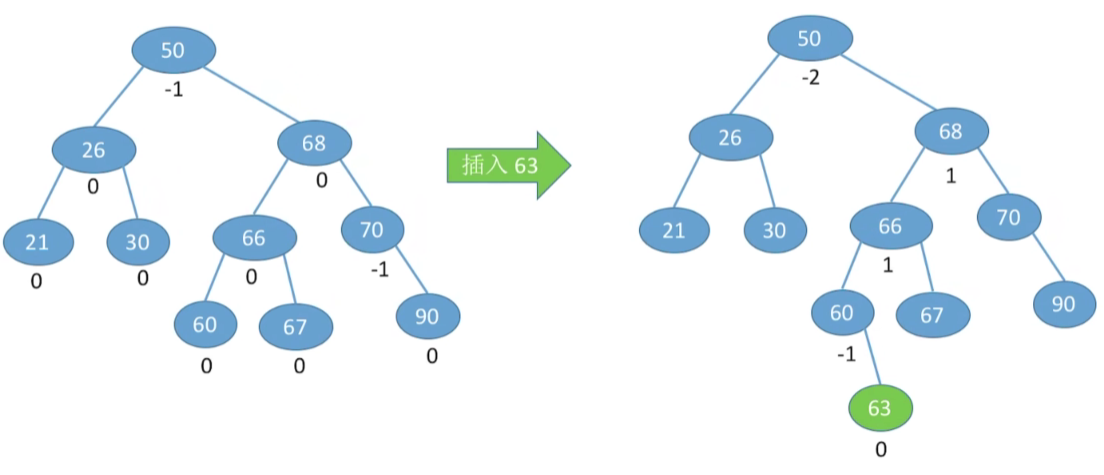
RL型,右孩子的左孩子,先右上旋再左上,对应为:
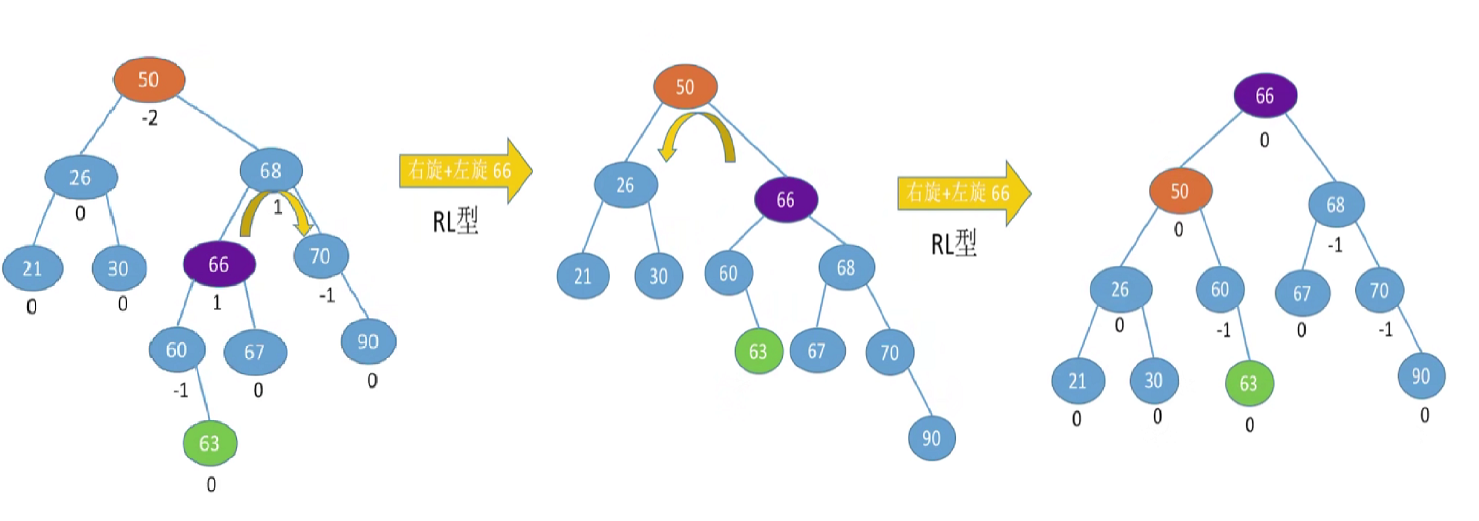
例三

LR型,左孩子的右孩子,先左上旋再右上旋
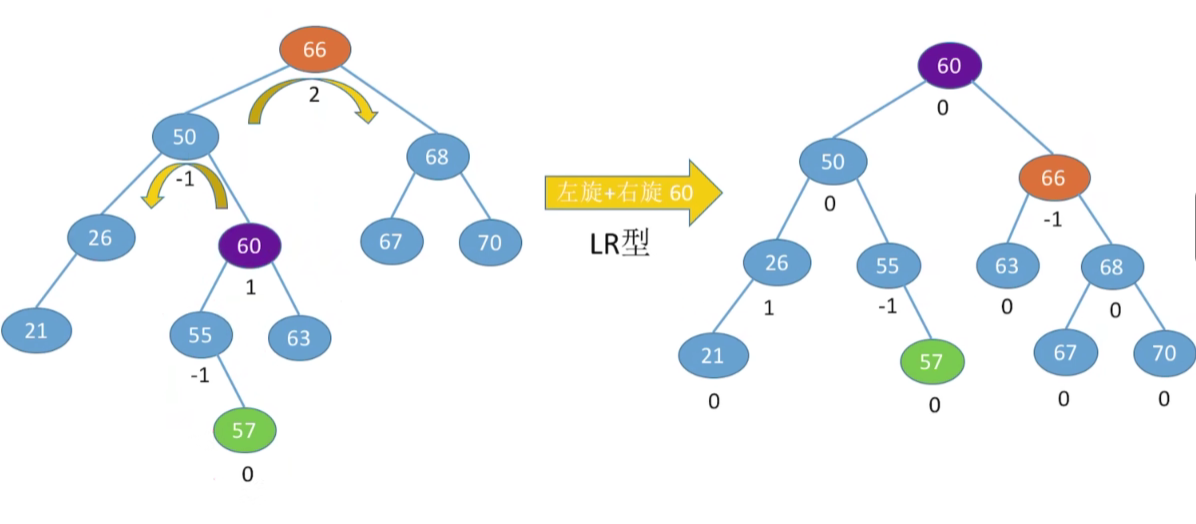
3. 查找效率分析
深度为h的平衡二叉树中含有最少的结点数假设为nh表示
当h=0,n0=0;
当h=1,n1=1;
当h=2,n2=2;
递归:nh=nh-1+nh-2+1
(高度为h的平衡二叉树对应的最少结点数为根结点数加左子树节点数和右子树的节点数)
所以相应的n3=1+n2+n1=4,n4=1+n3+n2=7、、、、有点类似斐波那契数列~
对于高度的h的排序树,查找一个结点最多只需要查找h次。所以9个结点的平衡二叉树高度为4,所以查找长度最大为4
对于n个结点,最大平衡二叉树的数量级为log2n,所以节点数为n的平衡二叉树的查找效率为O(log2n)




![[附源码]java毕业设计校园疫情防控管理系统](https://img-blog.csdnimg.cn/ee4aacd7f4d740bfbef7f79c5b28979d.png)