论文信息
| 论文名称 | LIRA: Learnable, Imperceptible and Robust Backdoor Attacks |
|---|---|
| 作者 | Khoa Doan(Baidu Research) |
| 会议/出版社 | ICCV 2021 |
| 📄在线pdf | |
| 代码 | 💻pytorch |
| 其他 | 该作者还有一篇攻击的论文,在线pdf |
介绍
本文提出了一种新的攻击框架 LIRA,该框架可以学习一种隐形的后门以及带有该后门的优化器。本文将后门的学习过程视为一个非凸约束优化问题,通过交替优化的方同时训练后门注入函数 T T T 以及带有后门的分类器 f f f。
之前的文章的 backdoor trigger 在视觉上有了改进,但是仍能被检测到。

可以由上图看出,本文方法生成的 trigger 更加隐蔽。
本文的方法不同之处:
- 将攻击问题视为约束优化的问题,并且采用了交替优化的方式去解决。
- 先前的文章是先训练 transformation function T,再训练 f f f ,本文让 T T T 和 f f f 同时训练。这样的优点是,不同图像的 trigger 是不同的,难以被检测。
威胁模型:
- 攻击者可以可以访问数据,模型结构和模型参数
- 返回一个训练好的模型
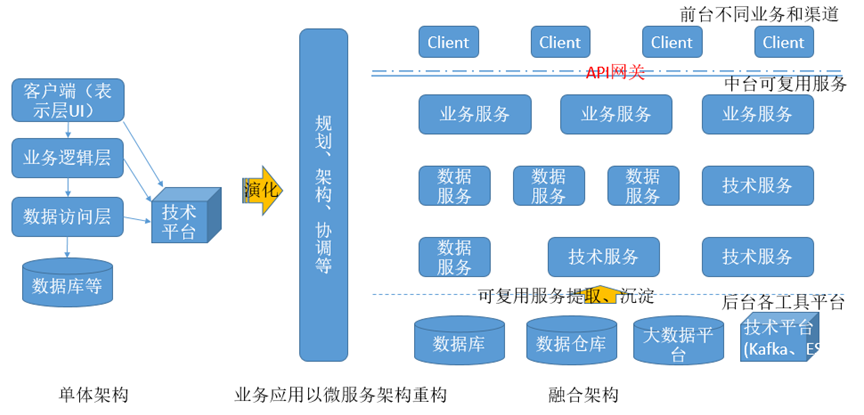
模型
整个模型的训练过程:
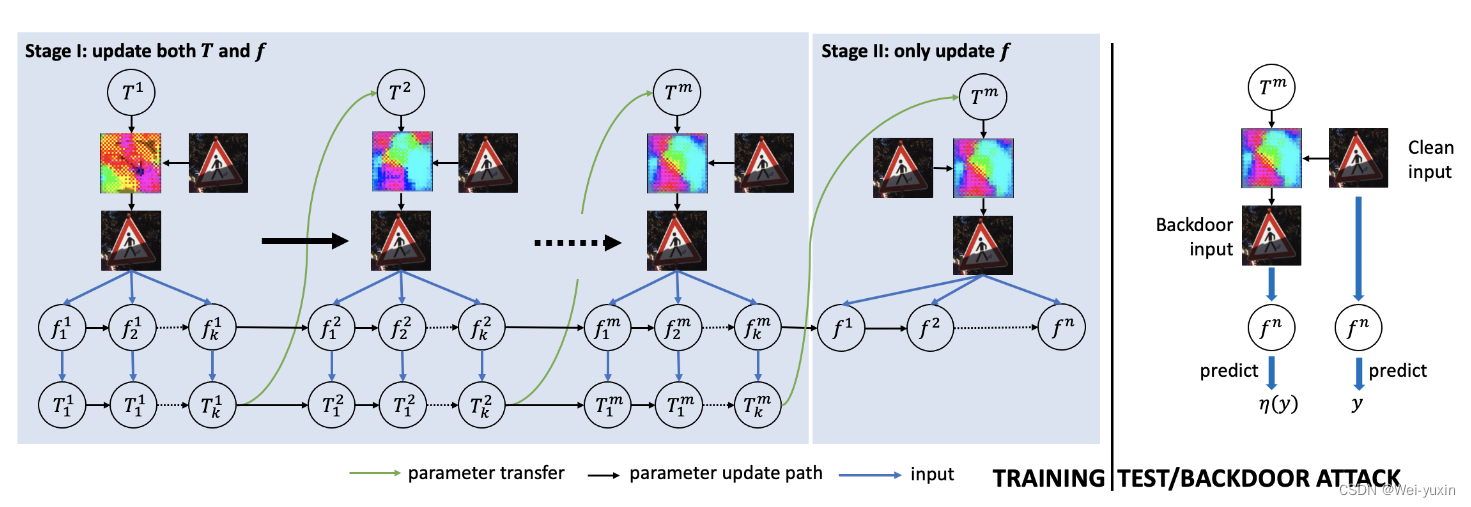
-
optimization problem
min θ ∑ i = 1 N α L ( f θ ( x i ) , y i ) + β L ( f θ ( T ξ ∗ ( θ ) ( x i ) ) , η ( y i ) ) \min _{\theta} \sum_{i=1}^{N} \alpha \mathcal{L}\left(f_{\theta}\left(x_{i}\right), y_{i}\right)+\beta \mathcal{L}\left(f_{\theta}\left(T_{\xi^{*}(\theta)}\left(x_{i}\right)\right), \eta\left(y_{i}\right)\right) minθ∑i=1NαL(fθ(xi),yi)+βL(fθ(Tξ∗(θ)(xi)),η(yi))
s.t. (i) ξ ∗ = arg min ξ ∑ i = 1 N L ( f θ ( T ξ ( x i ) ) , η ( y i ) ) \xi^{*}=\underset{\xi}{\arg \min } \sum_{i=1}^{N} \mathcal{L}\left(f_{\theta}\left(T_{\xi}\left(x_{i}\right)\right), \eta\left(y_{i}\right)\right) ξ∗=ξargmin∑i=1NL(fθ(Tξ(xi)),η(yi))
(ii) d ( T ( x ) , x ) ≤ ϵ d(T(x), x) \leq \epsilon d(T(x),x)≤ϵ- α \alpha α 和 β \beta β 为超参数,文中设置为 0.5,0.5
-
two-stage training
- Stage I:train f and T with the proposed alternating scheme for a fixed number of trials
- Stage II:we fine-tune only the classifier f with both clean and backdoor data generated by the learned transformation T in Stage I.
-
Algorithm
“Algorithm 1 LIRA Backdoor Attack Algorithm” 具体算法可以看文章
实验
-
模型结构
- Generator:U-Net
- classifier:Resnet-18
-
数据集
- MNIST, CIFAR10, GTSRB and Tiny ImageNet (T-ImageNet)
-
实验
- Human Inspection Test:使用人去检测 trigger 的视觉效果
- Attack Experiments:验证了攻击的效果
- Defense Experiments:分别对防御模型,Neural Cleanse,STRIP,GradCam 进行了测试
![T293037 [传智杯 #5 练习赛] 白色旅人](https://img-blog.csdnimg.cn/e8516f1549fc4d12857246f9b3a3e43c.png)


![[附源码]java毕业设计校园淘宝节系统](https://img-blog.csdnimg.cn/9e2cae9a19794641b55093ae7eb6d55e.png)