Title:APAUNet: Axis Projection Attention UNet for Small Target in 3D Medical Segmentation
摘要:
在医学分割中,小目标分割对于诊断至关重要。在本文提出了轴向投影注意力网络,用于三维医学图像分割,特别是小目标。考虑到背景在三维特征空间中所占比例较大。本文引入了一种投影策略,将三维特征投影到三个正交的2D平面当中,以捕捉来自不同视角的上下文注意力,这样我们就可以过滤掉冗余的特征信息,并减轻3D扫描中小病灶的关键信息损失。然后利用了一种维度混合策略来融合来自不同轴的关注度的3D特征,并通过加权求和来合并他们,以自适应的学习不同视角的重要性。
最后在APA解码器中,我们在2D投影过程连接高分辨率和低分辨特征,从而获得更精确的多尺度信息。
Introduction:
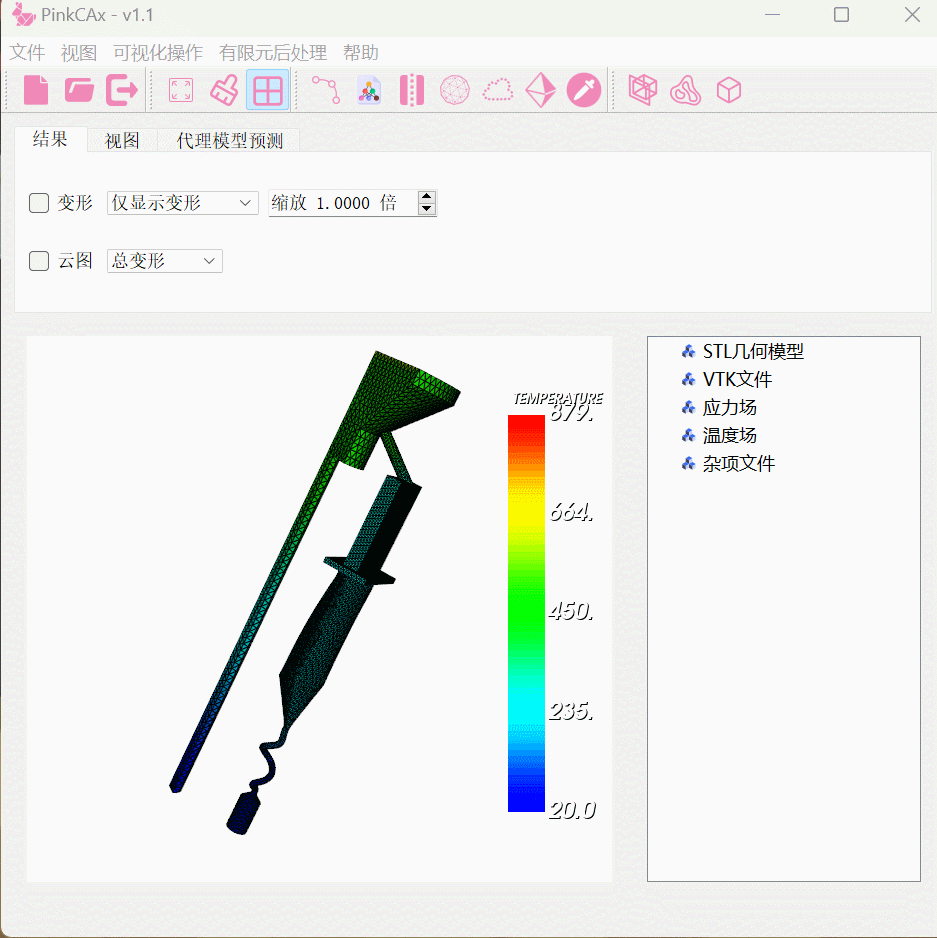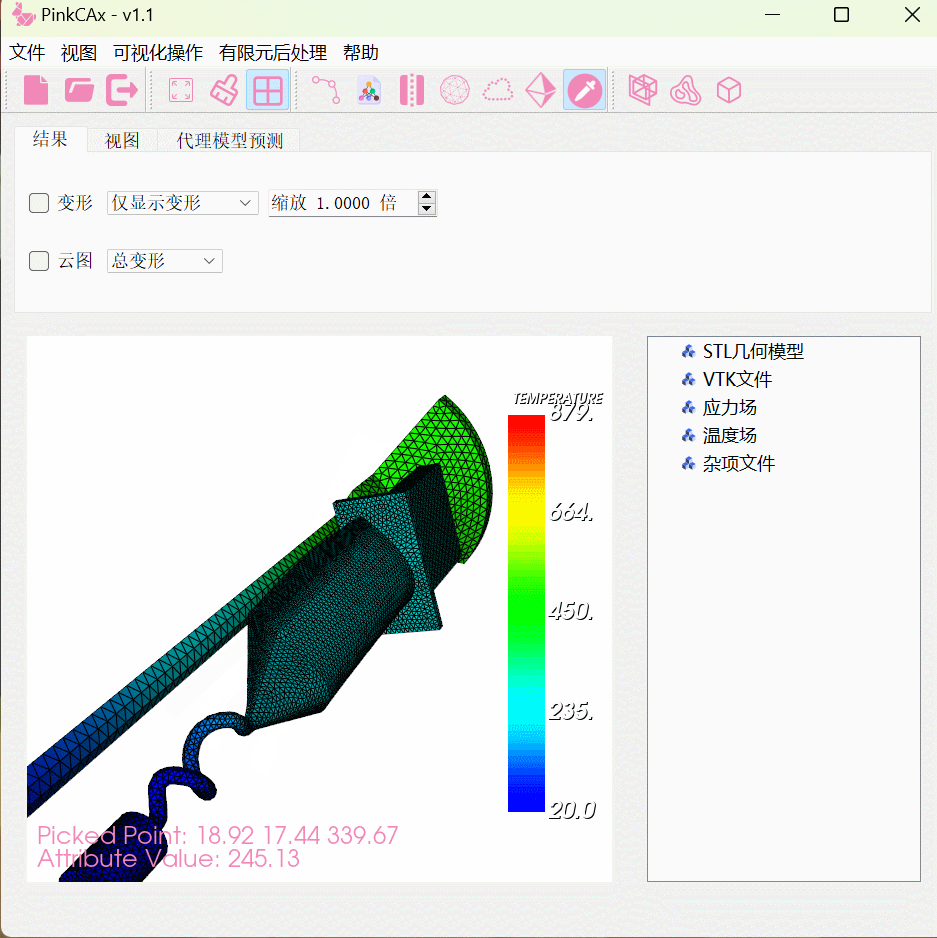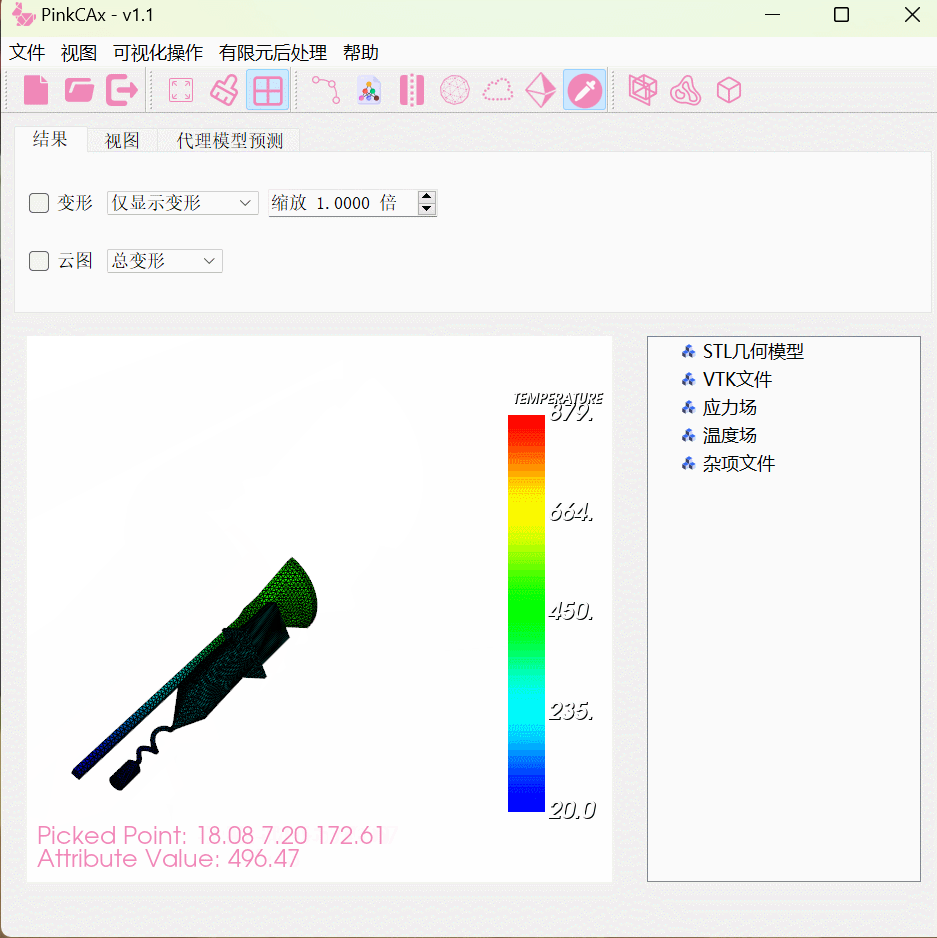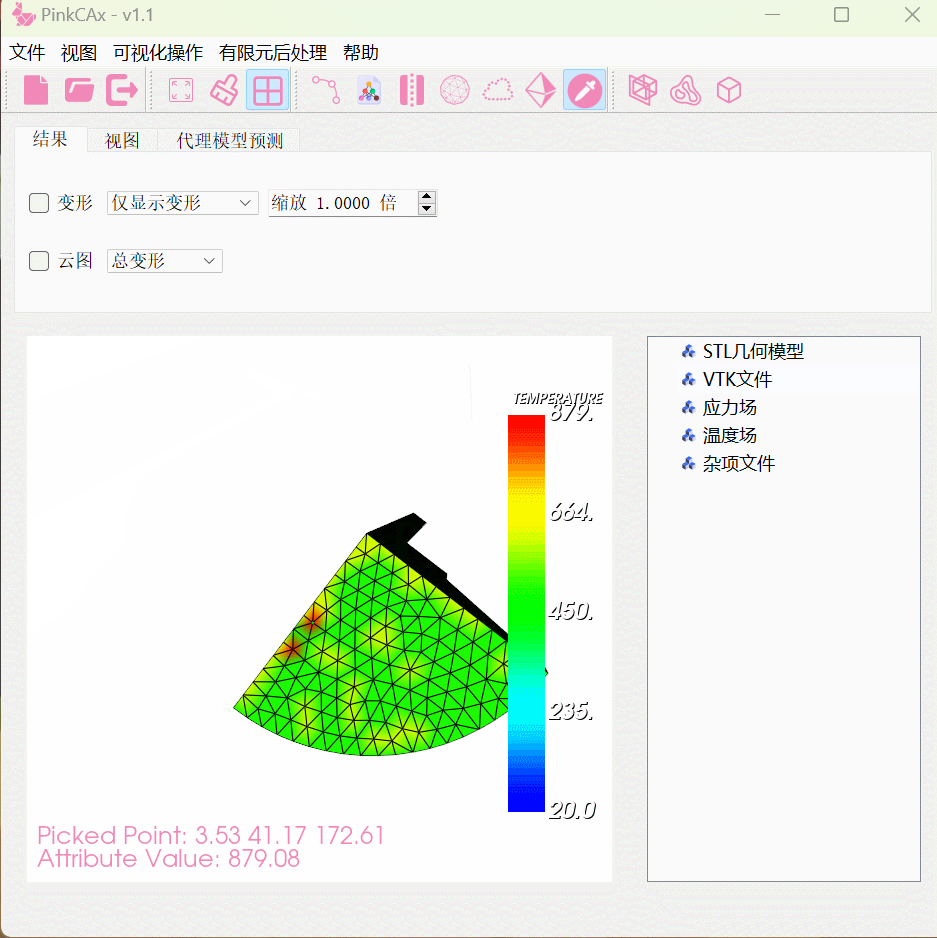
我们提出了一个轴投影注意(APA) UNet,命名为APAUNet,它利用正交投影策略和维度杂交策略来克服上述挑战。具体来说,我们的APAUNet遵循3D-UNet的既定设计。但用我们的APA编码器/解码器模块替换了主要的功能组件,即基于3D卷积的编码器/解码器层。在APA编码器中,初始3D特征图被投影到三个正交的2D平面,即矢状、轴向和冠状视图。这种投影操作可以减轻3D扫描中小病灶的关键信息的损失。然后,我们沿着投影特征提取局部上下文2D注意,以执行不对称特征提取并将其与原始3D特征融合。最终,三个轴的融合特征通过三个可学习因子相加作为最终输出,如下图所示:

相应地,我们的APA解码器遵循与APA编码器相同的原理,但从两个分辨率级别获取输入特征。这样,解码器可以有效地利用多尺度特征的上下文信息。
综上所述,本文的贡献有3点:1)本文提出了Axis Projection Attention UNet。APAUNet利用正交投影策略来增强不对称投影注意和特征提取2)引入了一种新的维度混合策略来融合2D和3D注意图,以在编码器和解码器中获得更好的上下文表示
注意力机制在医学图像分割上的应用
注意力机制已经广泛应用于分割网络,分割网络可以分为两个分支。第一个分支是Hard attention,它通过使用由粗到细的框架来完成分割任务。利用两个并行的fcn首先检测输入特征的ROI,然后对这些裁剪后的ROI块进行细粒度分割,用于体医学图像分割。第二个分支是采用自注意力机制。
方法
下图说明了网络的整体架构

我们的APAUNet由几个具有五个分辨率步长的轴投影注意力(APA)编码器/解码器模块组成。
轴投影注意编码器和解码器
APA编码器旨在从不同视角提取多个分辨率级别的上下文信息,APA编码器的结构如图左边所示。在实践中给定3D医学图像![]() ,APA编码器提取不同分辨率尺度
,APA编码器提取不同分辨率尺度![]() , 对于第I级,输入特征Xi被并行地馈送到三个内部编码器(IE)块,以从三个不同的角度捕捉上下文注意力。为了更有效的捕获小目标特征,原始的3D特征将被投影到三个正交的2D平面,以提取2D空间注意力。然后,将学习到的2D注意力和3D特征图聚合以增强特征表示。在获得三个轴的融合特征之后,我们使用三个可学习的参数βi,a来获得增强特征的加权和:
, 对于第I级,输入特征Xi被并行地馈送到三个内部编码器(IE)块,以从三个不同的角度捕捉上下文注意力。为了更有效的捕获小目标特征,原始的3D特征将被投影到三个正交的2D平面,以提取2D空间注意力。然后,将学习到的2D注意力和3D特征图聚合以增强特征表示。在获得三个轴的融合特征之后,我们使用三个可学习的参数βi,a来获得增强特征的加权和:

其中IE()是IE块的操作,a表示三个正交轴。
这种聚集函数可以进一步帮助网络自适应地学习不同投影方向的重要性,以实现非对称信息提取。然后,应用另一个1 × 1 × 1卷积和2 × 2 × 2平均池来执行下采样操作,以获得下一级的输入特征Xi+1。
类似的,APA解码器模块用于提取和融合多分辨率特征以生成分割结果。详细设计如图3所示(右部)。APA解码器模块具有与APA编码器模块相似的结构,但是采用两个具有不同分辨率的特征作为输入。具体来说低和高分辨率的特征被同时送到APA解码器模块当中。其中低分辨率的特征映射来自第i+1级![]() ,高分辨率特征为
,高分辨率特征为![]() 之后内部编码器ID模块聚合高分辨特征和低分辨特征,以根据这三个特征生成2D上下文注意。然后将3D特征图与2D注意融合,以获得3D上下文化特征,类似于APA编码器中的特征。为此,小尺度前景信息被更好地保留,避免丢失至关重要的特征。最后,我们将三个3D上下文化特征的加权和作为下一级的输出特征。
之后内部编码器ID模块聚合高分辨特征和低分辨特征,以根据这三个特征生成2D上下文注意。然后将3D特征图与2D注意融合,以获得3D上下文化特征,类似于APA编码器中的特征。为此,小尺度前景信息被更好地保留,避免丢失至关重要的特征。最后,我们将三个3D上下文化特征的加权和作为下一级的输出特征。
内部编码器和解码器模块
内部编码器和解码器结构如下图所示:

正交投影策略。在内部编码器模块。为了更好地过滤不相关的背景并放大小病灶的关键信息,我们首先将输入的3D特征投影到三个2D平面。特别地,3D输入特征X ∈ RH×W ×D×C被投影到笛卡尔坐标系的矢状面、轴面和冠状面,以生成关键字(K)和查询(Q),而值(V)保持3D形状。以矢状面视图为例,将输入X投影到2D得到键和查询:K,Q ∈ RC×W ×D,而V ∈ RC×H×W ×D是通过单次1 × 1 × 1卷积得到的。这里,我们采用沿着期望轴(在这种情况下为H)的全局平均汇集(GAP)和全局最大汇集(GMP)的总和作为投影算子:

维度混合策略:
在正交投影之后,在K上使用组大小为4的3×3组卷积来提取局部注意力L ∈ RC×W ×D,其包含与相邻键相关的局部空间表示。然后,我们将局部注意力L与Q连接起来,通过两个连续的1×1 2D卷积和维数扩展进一步得到注意力矩阵G ∈ RC×1×W ×D
 。
。
接下来基于全局注意力图G,计算混合注意力图![]() ,
,
最后,通过选择性注意[24]将获得的混合注意图与输入特征X融合,以获得输出特征Y
多分辨率融合解码器
为了更好的从多分辨率的特征中获取多尺度上下文特征,本文将上采样操作集成到注意力提取过程中。
ID(内部解码器)类似于上述的IE(内部编码器块),但是采用不同分辨率级别的两个输入,其中采用来自编码器的高分辨率特征![]() 来产生q,采用来自先前解码器的低分辨特征
来产生q,采用来自先前解码器的低分辨特征![]() 产生Key值和上采样的值,然后,应用3×3×3转置卷积对键进行上采样以获得局部注意力l。因此,解码器可以从各种尺度完全捕捉混合注意力。随后的上下文提取操作类似于IE块。最后,我们将混合注意力图与高分辨率特征X0融合以生成输出特征Y。
产生Key值和上采样的值,然后,应用3×3×3转置卷积对键进行上采样以获得局部注意力l。因此,解码器可以从各种尺度完全捕捉混合注意力。随后的上下文提取操作类似于IE块。最后,我们将混合注意力图与高分辨率特征X0融合以生成输出特征Y。
损失函数
使用DiceLoss和交叉熵损失函数,具体的损失函数公式为:
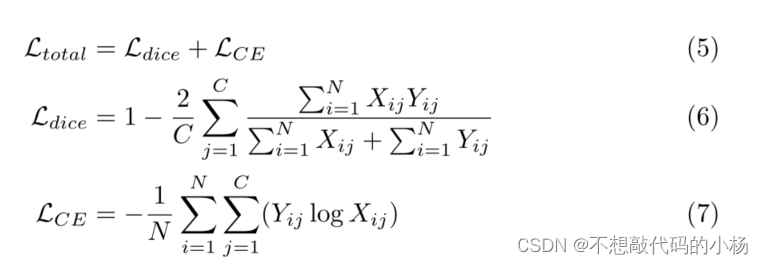
总结:
在本文中,我们提出了一个强大的网络三维医学分割任务,称为轴投影注意网络(APAUNet)。为了处理高度不平衡的目标和背景,我们利用正交投影策略和维度杂交策略来建立我们的APAUNet。