1. 论文信息
| 论文名称 | Imperceptible Backdoor Attack: From Input Space to Feature Representation |
|---|---|
| 作者 | Nan Zhong(Fudan University) |
| 会议/出版社 | IJCAI 2022 |
| 📄在线pdf 本地pdf | |
| 代码 | 💻pytorch |
| 概要 | 文中提出了一种难以察觉的后门。作者将trigger视为多项式分布下的一种特殊噪声。 通过unet网络生成多项式分布,再通过MLP进行采样。 |
2. introduction
本文提出一种难以察觉的攻击方式,相较于之前的做法,只需要改动一小部分像素就能达到攻击的效果。
-
背景
-
先前的隐形 trigger 可以骗过人眼,但是无法骗过检测器
-
在 DNN 中很多休眠神经元,只有 trigger 出现时才被激活
“Dormant neurons are activated when the trigger appears in the feature representation space.”
-
-
文章贡献:
-
本文从两个方面考虑了后门攻击的隐匿性
- input space
- feature representation space
-
-
解决的问题:
- 使用 multinomial distribution 的采样方法减少 trigger 的改动
- 最小化 backdoor 特征和目标类特征的距离来抵抗防御模型
-
threat model:
- 用户将数据上传服务商进行训练,攻击者可以对数据进行处理,但是不能改变模型结构(攻击者知道模型结构)
- 用户将数据上传服务商进行训练,攻击者可以对数据进行处理,但是不能改变模型结构(攻击者知道模型结构)
3. method
-
模型结构:
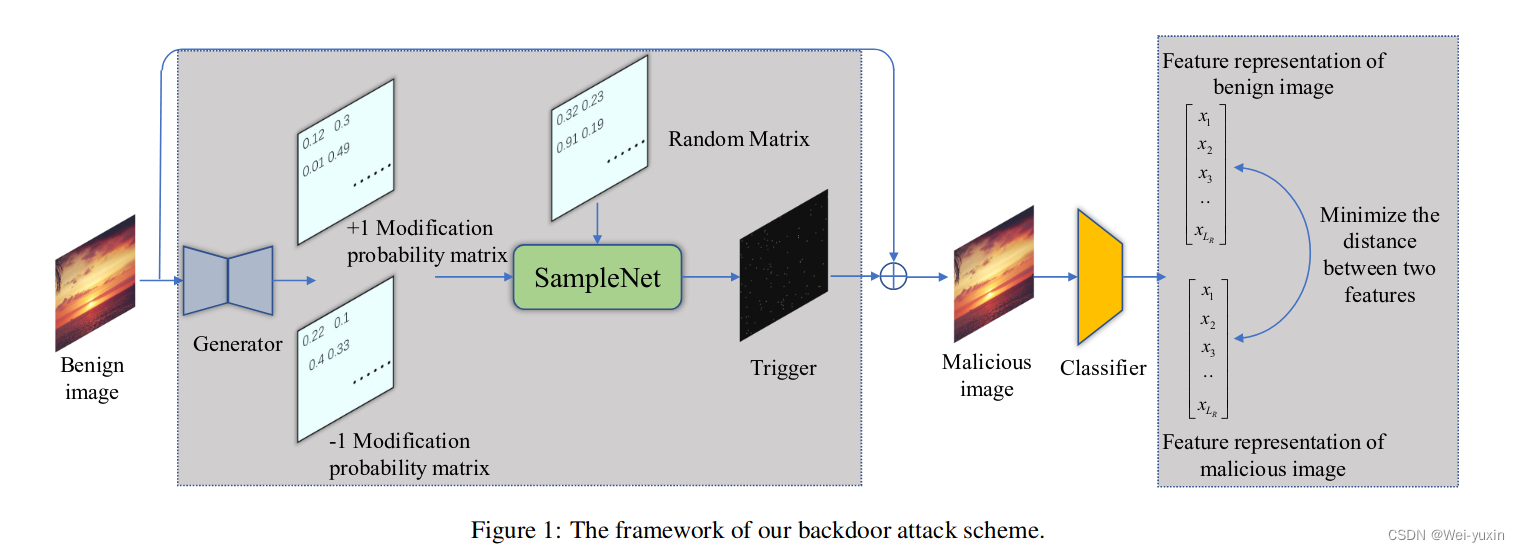
- 使用 u-net 模型生成“a pair of ±1 modification probability matrices” (pdf),also can be named as the parameters of the multinomial distribution
- 使用 samplenet(MLP)采样出 trigger,和原图像拼接产生恶意的图片
- 改变恶意图片的label
-
loss function
-
L cls = L ( f θ ( x benign , y ori ) ) + L ( f θ ( x malicious , y t g t ) ) L_{\text {cls }}=\mathcal{L}\left(f_{\theta}\left(x_{\text {benign }}, y_{\text {ori }}\right)\right)+\mathcal{L}\left(f_{\theta}\left(x_{\text {malicious }}, y_{t g t}\right)\right) Lcls =L(fθ(xbenign ,yori ))+L(fθ(xmalicious ,ytgt))
- x malicious = S ( G ( x benign ) , n ) x_{\text {malicious }}=S\left(G\left(x_{\text {benign }}\right), n\right) xmalicious =S(G(xbenign ),n)
-
L e t g = ( f benign − f malicious ) 2 L_{e t g}=\left(f_{\text {benign }}-f_{\text {malicious }}\right)^{2} Letg=(fbenign −fmalicious )2
-
L n u m = ∑ i = 1 w ∑ j = 1 h ( ∣ trigger i , j ∣ ) L_{n u m}=\sum_{i=1}^{w} \sum_{j=1}^{h}\left(\left|\operatorname{trigger}_{i, j}\right|\right) Lnum=∑i=1w∑j=1h(∣∣triggeri,j∣∣),
-
L t o t = L c l s + α ⋅ L e t g + β ⋅ L n u m L_{t o t}=L_{c l s}+\alpha \cdot L_{e t g}+\beta \cdot L_{n u m} Ltot=Lcls+α⋅Letg+β⋅Lnum
-
4. experiments
4.1 数据集
数据集一
GTSRB: 包含43个类别的交通信号
train:39209,test:12630
数据集二
CelebA:包含40个类别的人脸数据集
train:162084,test:40515
4.2 评价指标
-
BA: 正常情况下的准确率
-
ASR:backdoor 数据的准确率
-
L1-norm: s u m ( a b s ( x b e n i g n − x m a l i c i o u s ) ) / ( c h a n n e l × h e i g h t × w i d t h ) sum(abs(x_{benign} − x_{malicious}))/(channel × height × width) sum(abs(xbenign−xmalicious))/(channel×height×width)
用于统计修改像素的数量
4.3 实验
-
Attack Effectiveness and Visualization
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hasKG1xE-1669022411123)(assets/image-20220525120133-j4mqgi9.png)]](https://img-blog.csdnimg.cn/dc91f214fcd94e2cb32827f91be96d7f.png)
-
证明了这种攻击方法的改动较少,并且能取得不错的准确率
-
-
Defences
- 使用 FTD 进行防御
- 使用 Neural Cleanse 进行防御
- 使用 Network Pruning 进行防御
-
Ablation Studies
- 验证 α \alpha α 和 β \beta β 的作用


![[附源码]java毕业设计校园出入管理系统](https://img-blog.csdnimg.cn/b6d7671ddd0648ea8f8ecb1eaeedb2d8.png)

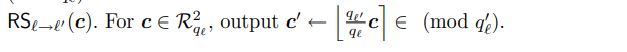



![[go学习笔记.第十六章.TCP编程] 2.项目-海量用户即时通讯系统](https://img-blog.csdnimg.cn/2615930efa4a4fb8b364542977b22152.png)



