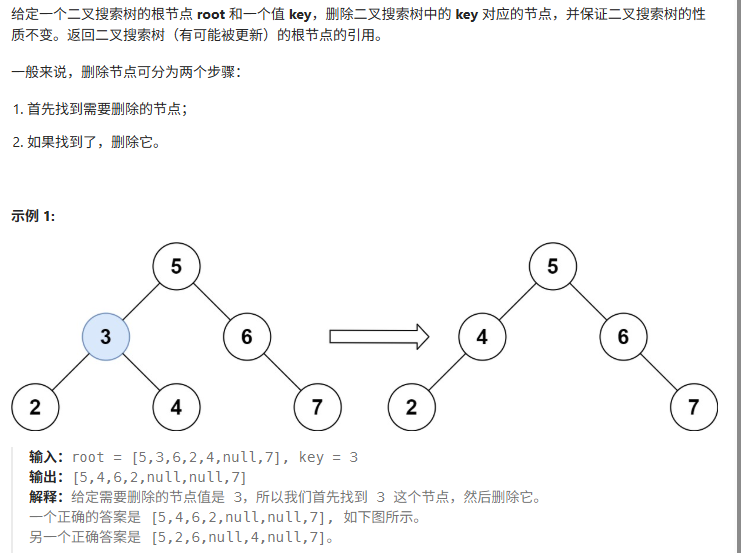
最近换了个工作,刚入职就接了个活--优化公司自营app的接口性能,提升用户体验。
刚开始还以为是1s优化到500ms这种,或者500ms优化到200ms的接口,感觉还挺有挑战的。下好app体验了一下。好家伙,那个慢已经超过了我的忍耐力,瞬间就不想用这个app了,挺佩服那些坚持使用该app的用户。
生产环境其实还好,因为服务器配置好,RT保持在3~4s左右,测试环境就不行了,8s起步。测试同学每次为了测一个下单的小功能,就要先进行搜索,详情,订单确认等接口,累计都快30s的前置操作。我更好奇测试同学这几年是怎么坚持下来的。
还要说下公司的项目,微信小程序起步,最开始是找了个外包团队,用了一套很古老的代码完成的,只能保证功能正常进行,但是代码性能就从没考虑过(想必接过外包活的朋友应该深有体会)。去年开始研发了app,重心逐步向app靠拢了。但是过慢的响应严重影响了公司的推广,于是就把这个活交给了我。
出于篇幅和隐私原因,本文不太会涉及具体业务代码和SQL,部分SQL也会换成通用的表来说明,只是会说一下整个优化的思路。
好了,闲话不多说,马上进入正题。
宏观优化
第一步:sql优化
在做性能优化的第一步,一定是先看有没有慢查,因为这个是不需要做任何分析就能拿到的结果。先找公司运维同事拉了一份慢查清单,真的是让我大开眼界。
10张表的关联查询,无处不在的or语句,like '%%'语句等等,甚至有些sql由于是mybatis-plus生成的sql语句,都找不到从哪调用的。没办法,一步一步来吧。
首先是表关联查询,10张表的sql我实在优化不动,看了下对应的接口QPS,不太高,最先放弃了,这个只能是等以后系统重构再考虑了。
or语句也改的简单粗暴,直接用union all改造,相同的sql结果,RT直降90%。改法如下:
--原sql
select * from user_info where user_id ='' or user_name like '%%' ;
--新sql
select * from user_info where user_id ='' union all select * from user_info where user_name like '%%' ;原理说明:or语句会破坏索引,改为union all以后,每条sql都会走各自的索引(先忽略那个like语句不走索引的问题),这样会大幅提升sql性能
like语句确实在当前技术层面下无法解决,要么改es,要么改需求(明确前缀匹配,或者强制带一个命中索引的条件)。
还要说一个点,也是我们经常容易犯的问题,就是索引缺失。在最开始的需求时,只用user_id这个字段查询,所以对它加了索引,过了一两年以后,需求变更,现在要对user_name也要进行查询了,写代码的时候就会忘记给user_name增加索引。又或者在数据量很低的情况下,没有命中索引也不慢,察觉不到,过了一两年数据累积多了,没有索引的问题就显露了。这种情况很好发现也很好解决,拿着慢查sql执行一下explain,就能发现问题,增加索引即可。
当然有时加索引并不是100%能解决问题,有可能提交的索引会被DBA打回,这就需要结合业务进行判断了,具体不赘述。
最后呢,我再补充个索引失效的案例。
select * from user_info where user_id in (select user_id from order where create_time>='')这条sql非常慢,explain显示user_info表没有走索引,但是user_id是有索引的。进一步探究发现,子查询的结果最多也就10条数据,当我拿着查到的10条数据改为如下sql时,又显示走了user_id索引,非常神奇
select * from user_info where user_id in (1,2,3,4,5,6,7,8,9,10)查询了一些资料得知,当in语句明确数量时,sql解析器是可以走索引的(除非in的数量过大);但是当in是子查询的时候,解析器在选择索引时,由于不太清楚in的数量,并且user_info表的数量也不算太多(大概100万左右吧),它会选择主键索引去关联,这样就导致了user_id索引失效。
知道原因了就很好改了,稍微改一下代码,改成exist语句或者把子查询改成两段分别查询的代码即可。
第二步:串行调用改为并行调用
以详情页为例,这个接口调用了接近20个服务(RPC或查DB)来组装详情页信息,每一个查询又都是线性执行的,假设平均一个接口在100毫秒左右,光这些接口调用就用了2s+的时间,详情页不慢才怪。
这里的改动目标就很明确了,梳理一下这20个服务的层级关系,然后改为并行调用。
-
把没有相互数据依赖的接口放在一个CompletableFuture中并行调用。
-
有相互依赖的,可以用thenAcceptAsync调用,也可以放在另一个CompletableFuture中并行调用。这个选择方式,我会在第六步中详细说明一下。
这一步没什么可细说的,按照标准的并行开发方式改造即可,做好并发编程的一些基本防护,比如用独立的线程池,做好线程超时,线程报错等措施。
宏观层面的改造基本就算完成了。为什么要说是“宏观”呢,因为这两步改造不仅在慢的问题发现上很容易,在改造完成后的体验上也有质的飞跃。我在做完这两步以后,生产RT降到了1s左右,测试RT降到了2s左右。
微观优化
宏观层面的改造,发现容易,改造快,见效明显。如果我们的代码都是按规范实现的,那基本上宏观的改造完成后,接口的优化也就差不多了。如果还要提高接口性能,就要进行非常细致的接口梳理、分析,在拿到整个接口流程后,才能制定更详细的优化方案,这一步我称之为微观优化。
第三步:重复调用
重复调用是一个常见问题,通常发生在一个经过多年,多人,多需求迭代后的接口中。一般来说,重复调用分为两种类型,三个场景:
-
同一个接口反复调用
-
一个接口中反复调用。通常来说,比较大众化的接口,如用户信息,商品信息等,后来的开发者会有意识的去查看整个接口的前置步骤有没有调用过,有的话就直接复用出参了。但如果是一个非常小众的接口,仅在特定的场景下调用,开发者可能就不会很仔细的阅读前置代码,直接在自己的子方法中调用了,而实际上该接口很有可能会在上面某个子方法中被调用过了。
-
上下游接口中反复调用。这个是微服务中经常遇到的,尤其是大众化接口,比如查商品信息,有可能整个链路中,80%的服务都会重新查询一次商品服务。这个的优化需要考虑的点非常多,由于不属于我们今天所讨论的范畴,所以本文就忽略该场景了。
-
-
同一个下游服务类似接口反复调用。比如当前查询了用户接口,获取用户基本信息;过一段时间,需要获取用户积分,你期望在原接口上增加积分出参,但用户系统的同事会说,那个接口调用量太大,不建议增加出参增大RT,推荐给你一个专门查积分的接口;又过了一段时间,类似的情况查询用户会员等级。。。这样不断的累积下,导致你的服务RT越来越高。
我在本次的梳理中,这两个类型都遇到了,并且公司项目并没有分团队,所有代码都可以改。针对类型1,在梳理完流程后,把重复调用的方法从子方法抽到主方法中,作为参数传递;针对类型2,针对当前业务,重新写一个新接口,一次性把用户基本信息,积分,等级等信息拿到。
如果下游服务(如上文所述用户)并不归属你部分所管辖,也可以说服对应的同事帮你提供一个新的接口,比如我在前司就写过很多getxxxForOrder,getxxxForProduct等专用接口,因为这类合并查询的接口,可以显著降低下游服务的QPS,他们也会有动力去优化的。
第四步:循环中查db/远程服务
这是编程中的一个大忌,如果下游不愿意提供批量接口,或者是异步操作,又或者循环数量在可预见的未来,也不会超过2~3个,这么搞是可以的。但如果数量很大的情况下,这么写代码就不推荐了。
我在改造中遇到的非常夸张的点,是查询一个列表页接口,先根据主表分页查询到数据后,循环获取页面上需要的其他数据,比如订单表可能只有订单号,商品id,用户id等,拿到以后,循环调用商品接口,用户接口获取对应的商品名称、用户信息等。
这里的改造就是先拿到当前页需要展示商品id和用户id,调用批量接口拿到所有的商品信息和用户信息,再将这些数据转成map(重点),在循环中用map.get(userId)或者map.getOrDefault(userId,"xxx")的方式拿到对应数据。
//注意,最后的(v1,v2)->v1一定要加上,即使你确定不会出现重复数据,养成这个习惯还是非常好的
Map<Long, String> map = productList.stream().collect(Collectors.toMap(
o -> o.getProductId(), ProductInfo::getProductName,(v1,v2)->v1));查db的也类似,不过有一点会让很多人困惑,感觉只能循环中查询,即:一对多或者多对多的表中,每次的查询条件都不一样。其实这种情况下,只需要将所有的数据全部in查询即可,然后转map的时候,将key进行拼接。
如下所述:
--比如一个活动(a)对应多个商品(p),一个商品也可能对应多个活动
--a1->p1,p2;a2->p3,p4;
--p1->a1,a3,p2->a1,a4;
--通常情况,循环中挨个查询的sql为:
select * from activity_product_rel where product_id='p1' and activity_id in('a1','a3'); select * from activity_product_rel where product_id='p2' and activity_id in('a1','a4');
--不妨改为如下SQL
select * from activity_product_rel where product_id in('p1','p2','p3') and activity_id in('a1','a2','a3','a4');
Map<String, Object> map = activityProductList.stream().collect(Collectors.toMap
(o -> o.getActivityId() +"_"+ o.getProduct() , Function.identity(),(v1,v2)->v1));
//或者是下面的方式,根据实际情况选择
Map<String, List<Object>> map =activityProductList.stream().collect(
Collectors.groupingBy(o -> o.getActivityId() +"_"+ o.getProduct() ));
//循环中用如下方式获取数据
map.get(activityId+"_"+productId)要说的一点是,sql的提前查询也要考虑实际情况,不能滥用,如果真IN出来成百上千的数据,那还不如循环查询呢,总之,要结合db性能,索引命中情况后再做决定。
第五步:拆分in语句
这一步既是上一步的补充,也可以看成是独立的一点。
在正常的sql查询中,也会出现in语句中存在上千甚至上万的数据,严重影响了db性能,甚至出现不走索引的情况,这时就需要拆分in语句了,把一条sql拆成10条,并行执行,然后聚合查询结果。
自己简单实现了下面这个方法。
public static <T> List<T> splitIn(BaseMapper<T> mapper, QueryWrapper<T> wrapper, List<Object> inData, String column, ThreadPoolExecutor pool, int size) {
if (inData.size() <= size*1.1) {
QueryWrapper<T> newWrapper = wrapper.clone();
newWrapper.in(column, inData);
return mapper.selectList(newWrapper);
}
List<List<Object>> partition =ThreadPoolUtils.balancedPartition(inData,size);
Function<List<Object>, List<T>> function = data -> {
QueryWrapper<T> newWrapper = wrapper.clone();
newWrapper.in(column, data);
return mapper.selectList(newWrapper);
};
return AsyncUtil.supplyAsync(partition, function, pool).stream().collect(ArrayList::new, List::addAll, List::addAll);
}public static <P, R> List<R> supplyAsync(List<P> paramList, Function<P, R> apply, ThreadPoolExecutor executor) {
if (CollectionUtils.isEmpty(paramList)) {
return new ArrayList<>(0);
}
List<R> result = new ArrayList<>();
List<CompletableFuture<R>> futures = new ArrayList<>();
for (P p : paramList) {
CompletableFuture<R> future = CompletableFuture.supplyAsync(
() -> apply.apply(p), executor);
futures.add(future);
}
for (CompletableFuture<R> future : futures) {
R r = future.join();
result.add(r);
}
return result;
}public static <T> List<List<T>> balancedPartition(List<T> list, int partitionCount) {
int size = list.size();
int baseSize = size / partitionCount;
int remainder = size % partitionCount;
List<List<T>> result = Lists.newArrayList();
int start = 0;
for (int i = 0; i < partitionCount; i++) {
int end = start + baseSize + (i < remainder ? 1 : 0);
result.add(list.subList(start, Math.min(end, size)));
start = end;
}
return result;
}主要说明三点:
-
inData.size() <= size*1.1这个判断主要是基于一些实际情况,比如size是1000,如果是1001的时候,明明和1000没啥区别,却被迫分组,这种情况下多线程反而比单线程要慢,所以增加了一定的冗余。这个可以根据实际情况做调整。
-
balancedPartition这个方法是让deepseek写的,自己也懒得动脑筋想算法了。原本用的是Lists.partition()做分组,但它的实际效果是,1001个数据按照size=1000分组,会变成一组1000个,一组1个,极度不平均,也会影响异步的总RT,于是就想找个平均拆分的算法。
-
线程池和数量都作为入参传入,所以让不同的场景各自定义不同的数据,甚至可以通过配置中心来实时调整。
第六步:CompletableFuture线程分组
调试过程中,我把第二步优化的每一个方法的RT都打印,把异步的总时间也都打印,发现最慢的一个接口500ms左右,但是异步总时长却在1s左右。
在理想情况下,异步的总时长应该只会比最慢的接口再慢二三十毫秒,现在既然慢了快一倍,那就说明存在线程等待问题。
而解决线程等待的问题上,不是一味的加大线程池数量就可以的,这样治标不治本的,反而会加重CPU的负担。在仔细查看了所有接口的RT后,我决定做线程池分组。
目前分成了heavy和lite两个组,把那种大于300ms的服务放入heavy中,其他的放入lite中。这样可以极大实现线程的复用,这么做了一个简单的分组后,就实现了理想的效果:最慢接口500+ms,异步总时长在550ms左右。
基于此,我们再聊下上面留得一个点,有接口依赖的异步,是用thenAcceptAsync还是放在另一个CompletableFuture中并行调用。
我的理解是,根据实际情况做分析,简单说下我的想法:
-
如果上游接口耗时较短,那么下游接口可以放在thenAcceptAsync调用,毕竟即使这样做了,总时长可能都超不过最慢的接口
-
如果有非常多的接口依赖同一个接口,那不如将它们和其他接口一并放到第二个CompletableFuture中执行。
其实说白了,就是尽最大可能压榨CPU性能,降低RT,哪个方式快用哪个。
最后要说一个必须注意的点,如果没有必要,不要在异步中使用异步,如果一定要使用,那线程池一定要分开,不然会出现主子线程死锁情况。
第七步:并行计算
上面的很多异步情况,其实都是指的IO密集型,如果是CPU密集型的情况下,我们通常是不太会考虑用并行的。但在本次优化中,我发现了这么一个点。
有一个计算金额的方法,速度很快,1~3ms内就能结束,所以for循环去处理也没啥大问题,但调用这个方法的总时长超过了300ms,仔细分析后发现,这里有200多个数据需要计算,虽然每一个都很快,但累积下来也是一个不小的数字了,我将foreach改为list.parallelStream().forEach后,RT骤降到30ms左右。
但还没有结束,list.parallelStream().forEach仅建议用来验证并行能否提高性能,并不建议实际开发中使用,因为它的底层使用的时候ForkJoin框架来拆分任务的,在某些情况下可能会导致主线程阻塞。我在前司就被这个点坑过,为两年前的代码买单。。。
所以如果想要使用并行计算,一定要自定义线程池,不要想着去赌不出问题的概率。
第八步:不要滥用redis
说起来,这个外包项目代码是极度迷信redis,几乎所有的地方都用到了redis,导致大key非常多,调用一次redis的时间比查mysql要慢多了,并且还很容易引发YGC甚至FULLGC。
所以我也对项目中redis的使用进行了一定程度的降温。具体体现在如下几点:
-
针对分页数据,redis可以存全量数据,但仅存核心数据,其余数据都需要通过查表来补充。其实这一步应该用es甚至纯查表来实现,奈何改动量太大,公司还没有es环境,退而求其次了。
-
for循环调用redis的地方,有些都改成了查一次db。这也是经过性能比对后的结果,主要还是redis每次查的数据量太大了。
写到这里,基本上通用的优化方案就说完了。这么一通改造下来,测试环境的RT已经完美的降到1s左右了,想想当初的8s,简直不敢想象。
个性化点
或者说“非通用性优化”。这些优化点可能只适用于我司,因为大部分改动都属于历史代码堆叠导致,改动上没什么借鉴意义,不过可以参考下梳理过程。
第九步:接口拆分
这也算是一个通病,就是如果一个底层服务的部分出参,能满足一个新接口的全部功能,那就直接复用,省时省力。但很多时候,这个底层服务有可能是给一个聚合服务提供的,内部有大量对于新接口无用的功能。
就比如一个查询商品图片的接口,入参productId,出参imgList,controller直接调用了商品详情页接口,把什么商品说明,优惠券,价格详情全查了一遍,但最后只用了其中的imgList。。。
这种改造也很简单,重写一个新的service方法,只调用查商品的下游接口就好(因为懒得针对这种情况专门再写一个只查图片的接口了),结果就是这个查图片的接口RT从500+ms直降到50ms以下
第十步:跳过验签
这是最有意思的一个点,验证了好久才找到原因。
起因是通过日志发现接口仅用了800ms,但是app端的响应就是要1.5s以上。刚开始以为是出参过大(50kb以上)导致下载慢,但是抓包发现它的Waiting(TTFB)就是用时1.3s,下载20多ms。然后还专门去查了TTFB怎么回事,怎么优化之类的,就不表述了。
后来无意中发现,直接调用对应服务器的接口,即:http://192.168.1.101:8080/getXXX,就是800多ms,但是如果通过完整的url调用,即http://test.domain.com/xxxx/xxxx/getXXX这种方式,就是1.5s左右。
然后就跟到了网关代码中,发现原来是鉴权服务非常慢。。。
但是列表页,详情页这些接口,本身就支持非登录状态下查询的,没必要进行鉴权。和产品沟通认可后,对着网关一通改造,做好配置,让详情页接口跳过鉴权,接口瞬间降到1s以下,涉及出参少的详情,甚至200ms就返回了。
//网上找的查看curl执行时长的方法
//使用方法就是,如果原本的curl是curl "http://127.0.0.1",那么就在curl后面先加上下面的内容,再写"http://"
curl -w "Time to Connect: %{time_connect}\nTime to Start Transfer: %{time_starttransfer}\nTotal Time: %{time_total}\n" "http://127.0.0.1:8080/xxxx"
//如果不想要看到出参,就用下面这个方法
curl -o /dev/null -w "Time to Connect: %{time_connect}\nTime to Start Transfer: %{time_starttransfer}\nTotal Time: %{time_total}\n" "http://127.0.0.1:8080/xxxx"第十一步:跳过业务逻辑
就是某些业务逻辑其实是由于业务框架限制导致(原始代码是一套很老的系统),很多代码在公司现业务逻辑中已经没意义了,就用更直接的方式替代。有如下几个点:
-
某个RPC耗时200ms,但十多个出参中,仅用了其中一个值,且该值是一个数据库配置,我就直接改成配置中心配置了。(说明,我是经过确认,该数据库配置已经无意义了,理论上就是一个常量,为了一些考量才用配置中心代替)
-
某个查询会依据上一个查询的结果中某个字段判断,为0的时候才会查,分析后发现,数据库里就没有非0的数据,于是把把前置查询逻辑移除。(说明,经过确认,原始代码是一套sass系统,而现业务非sass,就是固定一套逻辑,这样才删除的前置查询)
-
由于app是后起之秀,很多小程序业务逻辑其实并没有包含,但是底层却是相同的代码。我根据app的出参进行对照后,重写了个app专用接口,删减了大量逻辑,直接让app接口快到飞起,降到100ms左右。(说明,这里就有点定制化的意思了,其实是和业务开发有一些背道而驰,万一以后来个需求,得两个接口一起改了。不过也是咨询过业务和产品,确定app未来的发展方向后,才这么干的)
其他点
这里想说的几个点,就属于极致优化了,对于性能不敏感的接口,是可以忽略这些点的。并且也并不全是本次优化过程中遇到的,也算是总结下自己曾经遇到的一些点吧。
beanCopy
接口中用了大量的BeanUtils.copyProperties,经过验证,总共耗时在10~15ms之间,所以对于性能敏感的接口,还是不建议使用这种方式,推荐用MapStruct进行对象的copy。
由于这个改动量有点大,并且提升有限,我就没有改。不过后续的新逻辑我都是用MapStruct进行处理的。
stream
在不使用parallelStream的前提下,stream理论上是要比普通的for循环慢的,但是太较真的话也没多必要。所以一般来说,我的使用策略是,性能不敏感接口,哪个顺手写哪个;不过如果要对同一个list的多个值做多次聚合的话,我一般都会改成for循环进行分别取值。
但说个例外吧,我确实遇到过对同一个list多维度聚合的,如果真用for去写,就太复杂了,还得考虑空map去new的情况,所以正好接口QPS不高,就用了多次groupingBy。
当然,现在有了更好的选择,将多个stream扔给deepseek让它优化,一般都能给到一个非常好的优化结果。
多次for循环
这个一般存在于历经多次迭代的代码,比如对同一个list先做了一次遍历,对userName进行脱敏处理,后面(可能一年后)又来一次遍历,对新增的价格字段做除以100。这种在没有相互参数依赖的情况下,是可以合并的。
同样,交给ai去优化,省时省力。
@Value取值的List或Set
通常会有一些业务场景,比如灰度,简易的业务配置数据等会通过配置中心来控制。我见过很多代码都是用List接收的,然后在业务代码中,用value.contains(xxx)来进行判断。
要知道list的contains效率是O(n),而set的contains效率是O(1),虽说在小数据量的情况下,他俩差距微乎其微,但毕竟二者在@Value的配置上没什么差异,养成一个好习惯还是不错的。
聊点有意思的
这里说几个我在优化过程中犯的错吧,都是比较低级的。
in语句拆分
这个就是上面第五步所说的,最开始发现in语句有340多个值,怕影响性能就按照100一个进行拆分,最后耗时300+ms,以为是分组不均导致,就改成均分模式,结果依然差不多,后来就决定试一下不分的情况,结果只有几十ms。。
这个点给我的感触就是,过度优化不一定是好优化,还是要根据实际情况进行取舍。
线程死循环
由于整个优化过程耗时3天,到自测的时候,只记得自己大致改了哪些方向,细节的改造早就忘了。在改造完成自测的时候发现,时间范围只有1天时正常,大于1天程序就无响应了,随后抛出超时异常。
因为有历史经验,第一反应是数据量大了以后,线程增多,主子线程池死锁了,于是开始排查线程池,还把好多子线程中的异步都改成了同步进行验证,结果没任何问题。
排查了好久终于定位到一个非常底层的计算方法内,会对时间做循环计算。这里按照上面所说的第四步改造的时候,整出个小bug导致死循环了。最后定位到以后真的是被自己蠢哭了。
不过也就是这次排查才发现上面in语句拆分反而很浪费时间,算是歪打正着吧。
结束
整个优化过程就说完了,最终效果就是8s的接口被优化到了500ms左右,app甚至小于150ms。只能说,能被大幅优化的代码,只能说明之前写的太烂了。
但这话调侃调侃还好,不能认为接手的代码烂,就去喷前任不懂得性能优化。毕竟产生该问题的原因非常多,可能是框架导致,可能是日常迭代导致,可能是数据少没在意,也可能没有预料到业务功能大改。随着时间的推移,没准自己就成了那个被喷的前任了不是?
我们应当保持一个平常心去对待性能优化,并对核心接口做好日常监控,发现RT有明显增幅时去主动了解原因,也许当时没时间改,可以趁着某个需求迭代时顺便改掉。
最后的最后,我想说的是,千万不要忘了,面向开关编程。