📢博客主页:https://blog.csdn.net/2301_779549673
📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 JohnKi 原创,首发于 CSDN🙉
📢未来很长,值得我们全力奔赴更美好的生活✨


文章目录
- 🏳️🌈一、高并发内存池整体框架设计
- 🏳️🌈二、高并发内存池 - thread cache
- 2.1 思想原理
- 2.2 自由链表
- 2.3 哈希桶
- 2.3.1 RoundUp 函数
- 2.3.2 Index 函数
- 2.4 Thread create 类
- 2.4.1 void* Allocate(size_t size);
- 2.4.2 void ThreadCache::Deallocate(void* ptr, size_t size)
- 2.4.3 void* FetchFromCentralCache(size_t index, size_t alignSize);
- 🏳️🌈三、无锁访问
- 👥总结
🏳️🌈一、高并发内存池整体框架设计
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。malloc本身其实已经很优秀,那么,我们项目的原型tcmalloc就是在多线程高并发的场景下更胜一筹, 所以这次我们实现的内存池需要考虑以下几方面的问题。
- 性能问题。
- 多线程环境下,锁竞争问题。
- 内存碎片问题。
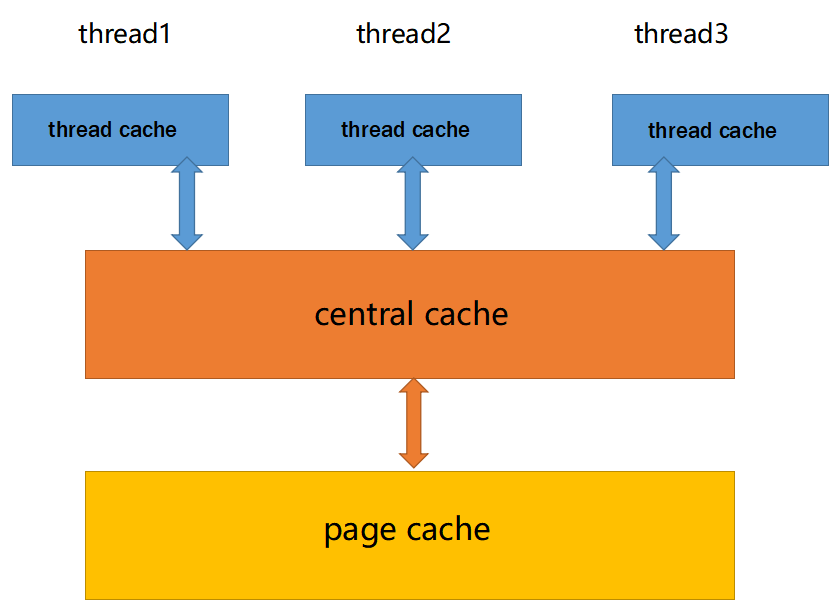
并发内存池(concurrent memory pool) 主要由以下3个部分构成:
- thread cache:线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这也就是这个并发线程池高效的地方。
- central cache:中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对象。central cache 合适的时机回收 thread cache 中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存在竞争的 ,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有thread cache的没有内存对象时才会找central cache,所以这里竞争不会很激烈。
- page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给central cache。当一个span的几个跨度页的对象都回收以后,page cache会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
🏳️🌈二、高并发内存池 - thread cache
2.1 思想原理
上一篇文章中,笔者 模拟了定长内存池,验证了其在大体量内存开辟时,速度大于malloc的特性
但是问题也来了,上一篇的是定长内存池,每一块的内存大小是一样的,所以就导致了 如果我们要申请释放的是不同大小的内存块就会非常麻烦,所以我们可以引入一个 哈希桶 的策略
thread cache 就是哈希桶结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表 。每个线程都会有一个thread cache对象,这样每个线程在这里获取对象和释放对象时是无锁的。
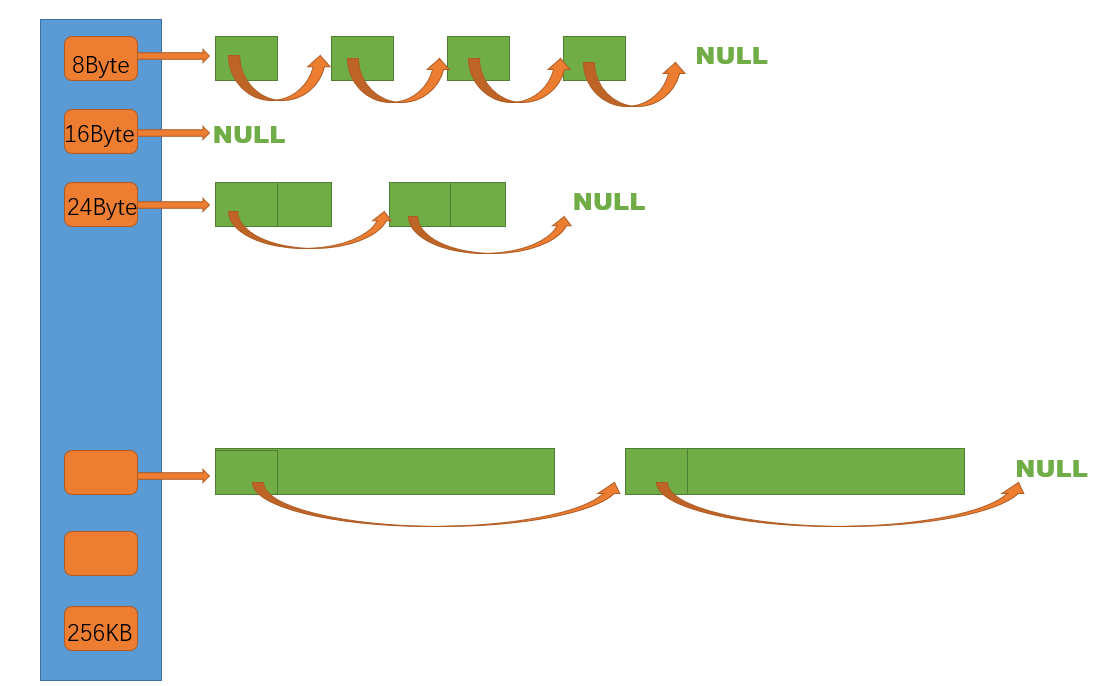
将不同大小的内存请求,通过 分级对齐 和 分组策略,映射到对应的自由链表桶中,实现高效内存管理。关键在于:
- 减少碎片 :同组内对象大小相近,提高内存利用率。
- 快速定位 :通过索引直接找到对应链表,O(1) 时间复杂度。
2.2 自由链表
因为哈希桶背后还是由一个个定长内存池,所以我们仍需要给自由链表定义结构体
这里我们先简单实现一下 push,pop 和 empty 功能,后面的功能等有用到的时候再实现
上篇文章也说了,这里 利用每个节点前面几位,来记录下一个节点的地址
// 管理切分好的小对象的自由链表
class FreeList {
public:
void Push(void* obj) {
// 头插
NextObj(obj) = _freeList;
_freeList = obj;
}
void* Pop() {
assert(_freeList);
// 头删
void* obj = _freeList;
_freeList = NextObj(obj);
return obj;
}
bool Empty() {
return (_freeList == nullptr);
}
private:
void* _freeList;
};
2.3 哈希桶
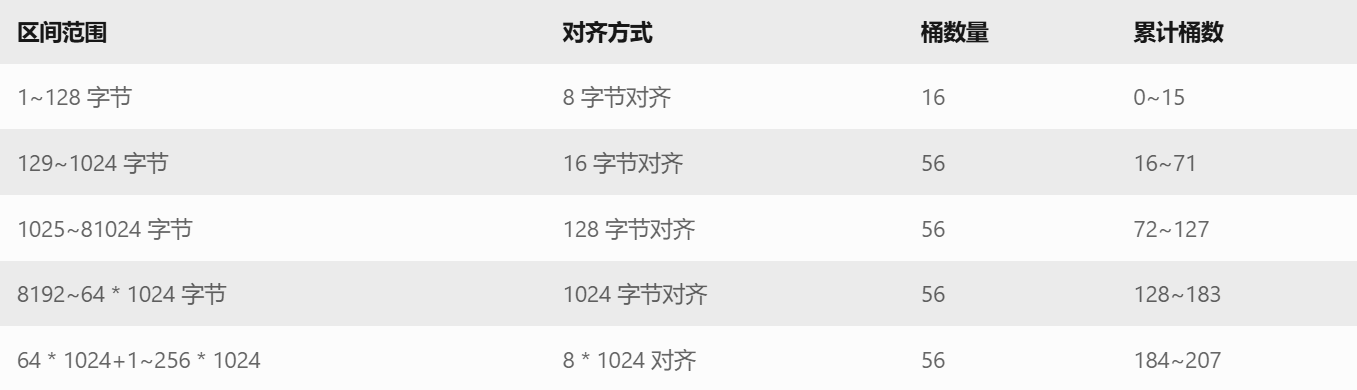
先理解一下哈希桶的映射规则:
根据对象大小,将内存请求分为不同区间,并采用不同的对齐粒度
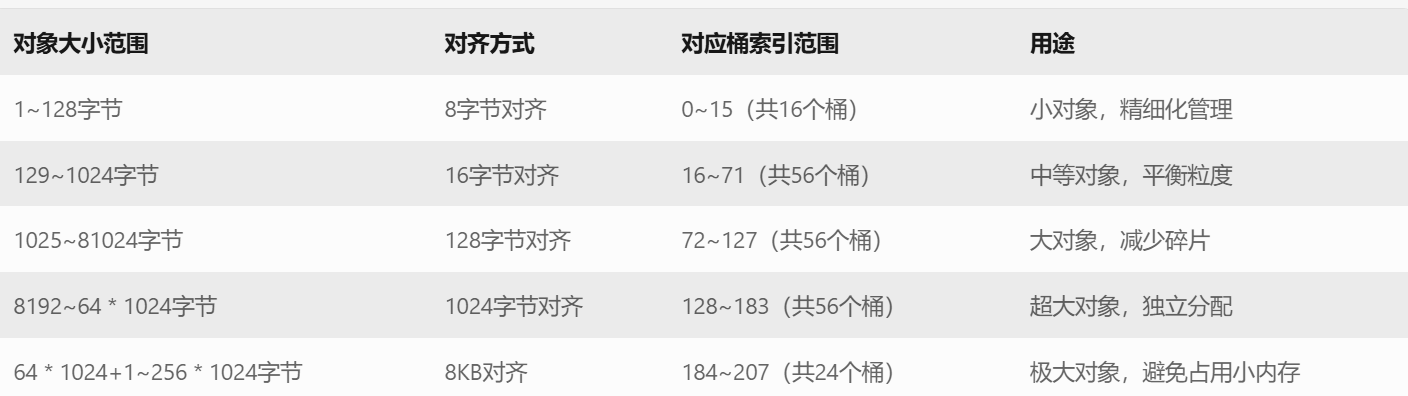
首先,MAX_BYTES 被定义为256 * 1024,也就是256KB,这是内存池能处理的最大对象大小。
接下来是 NFREELISTS,即哈希桶的数量,我们设为208,也就是每个桶管理特定大小范围的内存块。
再接着是 group_array 数组,定义为{16, 56, 56, 56}。这代表每个区间有多少个链。
然后是 RoundUp 函数,它根据请求的大小选择不同的对齐方式。例如,小于等于128字节的对齐到8字节,129到1024的对齐到16字节,依此类推。对齐后的尺寸通过_RoundUp函数计算,这里使用了位运算来高效地进行向上取整。
接下来是 Index 函数,它根据对齐后的尺寸确定对应的自由链表桶索引。这里的分段逻辑比较复杂,涉及到group_array的使用。例如,当请求的字节数超过某个阈值时,会减去之前区间的最大值,然后调用_Index函数计算相对索引,再加上前面区间的桶数总和。
2.3.1 RoundUp 函数
这部分我们计算对齐后的内存大小,可以对请求的内存大小进行判断,位于哪个区间就对齐到哪
// 计算对齐后的内存大小
static inline size_t RoundUp(size_t size) {
if (size <= 128) {
return _RoundUp(size, 8); // 对齐到 8 字节
}
else if (size <= 1024) {
return _RoundUp(size, 16); // 对齐到 16 字节
}
else if (size <= 8 * 1024) {
return _RoundUp(size, 128); // 对齐到 128 字节
}
else if (size <= 64 * 1024) {
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024) {
return _RoundUp(size, 8 * 1024);
}
else {
assert(false);
return -1;
}
}
一般来说,我们所能想到的 _RoundUp 的处理方法是 判断是否达到对齐数,不够填,够了直接返回,也就是
// 小对象(1~128字节):对齐到 8 字节,分配到自由列表的前 16 个槽位(索引 0~15)。
// 中等对象(129~1024字节):对齐到 16 字节,分配到索引 16~71。
// 大对象(1025~81024字节):对齐到 128 字节,分配到索引 72~127。
// 超大对象:对齐到更高粒度(如 1024、8192 字节),避免大对象占用过多小内存块。
// 整体控制在最多10%左右的内碎?浪费
// [1,128] 8byte对? freelist[0,16)
// [128+1,1024] 16byte对? freelist[16,72)
// [1024+1,81024] 128byte对? freelist[72,128)
// [8*1024+1,641024] 1024byte对? freelist[128,184)
// [64*1024+1,256*1024] 8*1024byte对? freelist[184,208)
// version - 1 普通人版
// 将请求的内存大小调整为对齐后的整数倍。
// size 当前请求的内存大小
// alignNum 对齐数
// alignSize 对齐后的内存大小
size_t _RoundUp(size_t size, size_t alignNum) {
size_t alignSize ;
if (size % alignNum != 0) {
alignSize = (size / alignNum + 1) * alignNum;
}
else {
alignSize = size;
}
return alignSize;
}
但是大佬的话,就会有更高级的思路,也就是 位运算
// version - 2 进阶版
// 通过位运算来实现对齐计算,避免了除法和乘法的开销。
// size 当前请求的内存大小
// alignNum 对齐数
// alignSize 对齐后的内存大小
static inline size_t _RoundUp(size_t size, size_t alignNum) {
return ((size + alignNum - 1) & ~(alignNum - 1));
}
2.3.2 Index 函数
这部分的作用就是 根据对齐后的尺寸,计算对应的自由链表桶索引。
根据这个表,我们可以得出 每个对象大小范围,各个桶的索引范围,也就得出了各个范围的桶的数量
接下来就只要根据这个范围划分,分门别类就行了
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
// 计算映射的哪一个自由链表桶
static inline size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
// 每个区间有多少个链
static int group_array[4] = { 16, 56, 56, 56 };
if (bytes <= 128) {
return _Index(bytes, 3);
}
else if (bytes <= 1024) {
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8 * 1024) {
return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];
}
else if (bytes <= 64 * 1024) {
return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];
}
else if (bytes <= 256 * 1024) {
return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];
}
else {
assert(false);
}
return -1;
}
2.4 Thread create 类
先来看看基本的 内存分配流程
graph TD
A[分配请求] --> B{本地链表是否为空?}
B -->|是| C[从链表弹出对象]
B -->|否| D[向中心缓存批量申请]
D --> E[填充本地链表]
E --> C
因为我们实现的是 thread create 类,所以除了要兼顾 定长内存池和哈希桶链表,还需要有能向中心缓存中获取内存空间的方法
2.4.1 void* Allocate(size_t size);
Allocate()函数的作用是申请内存对象,该函数主要分为以下两种情况:
- 通过所给字节数计算出对应的哈希桶下标,如果桶中自由链表不为空,则从该自由链表中取出一个对象进行返回
- 如果此时自由链表为空,那么我们就需要从central cache进行获取了
void* ThreadCache::Allocate(size_t size) {
assert(size <= MAX_BYTES);
// 获取对齐后的内存大小
size_t alignSize = SizeClass::RoundUp(size);
// 获取对应的自由链表索引
size_t index = SizeClass::Index(size);
// 如果此时该索引的自由链表不为空,则直接从自由链表中获取对象
if (!_freeLists[index].Empty()) {
// 有可用对象,直接从自由链表中获取
return _freeLists[index].Pop();
}
else {
// 从中心缓存获取对象
return FetchFromCentralCache(index, alignSize);
}
}
2.4.2 void ThreadCache::Deallocate(void* ptr, size_t size)
通过头插法实现O(1)时间复杂度回收
void ThreadCache::Deallocate(void* ptr, size_t size) {
assert(ptr);
assert(size <= MAX_BYTES);
// 找出对应映射的链表桶,并将对象插入自由链表中
size_t index = SizeClass::Index(size);
_freeLists[index].Push(ptr);
}
2.4.3 void* FetchFromCentralCache(size_t index, size_t alignSize);
这部分是去中心缓存中获取对象,先欠着,后面在将中心缓存的时候会补
🏳️🌈三、无锁访问
每个线程都有一个自己独享的thread cache,那应该如何创建这个thread cache呢?
我们不能将这个 thread cache 创建为全局的,因为全局变量是所有线程共享的,这样就不可避免的需要锁来控制,增加了控制成本和代码复杂度。
要实现每个线程无锁的访问属于自己的thread cache,我们需要用到线程局部存储TLS(Thread Local Storage),这是一种变量的存储方法,使用该存储方法的变量在它所在的线程是全局可访问的,但是不能被其他线程访问到,这样就保持了数据的线程独立性。
// static 保证只在当前文件可见
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
因此我们可以再封装一层申请内存与释放内存的函数,如下
static void* ConcurrentAlloc(size_t size)
{
// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
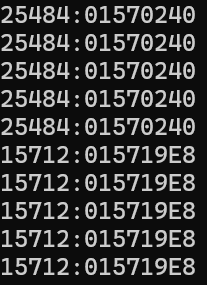
cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;
return pTLSThreadCache->Allocate(size);
}
static void ConcurrentFree(void* ptr, size_t size)
{
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr, size);
}
注意:不是每个线程被创建时就立马有了属于自己的thread cache,而是当该线程调用相关申请内存的接口时才会创建自己的thread cache,因此做是否为空的判断。
我们利用下面的测试代码试试
#define _CRT_SECURE_NO_WARNINGS 1
#include "ObjectPool.hpp"
#include "ConcurrentAlloc.hpp"
void Alloc1()
{
for (size_t i = 0; i < 5; ++i)
{
void* ptr = ConcurrentAlloc(6);
}
}
void Alloc2()
{
for (size_t i = 0; i < 5; ++i)
{
void* ptr = ConcurrentAlloc(7);
}
}
void TLSTest()
{
std::thread t1(Alloc1);
t1.join();
std::thread t2(Alloc2);
t2.join();
}
int main()
{
//TestObjectPool();
TLSTest();
return 0;
}
👥总结
本篇博文对 【从零实现高并发内存池】内存池整体框架设计 及 thread cache实现 做了一个较为详细的介绍,不知道对你有没有帮助呢
觉得博主写得还不错的三连支持下吧!会继续努力的~