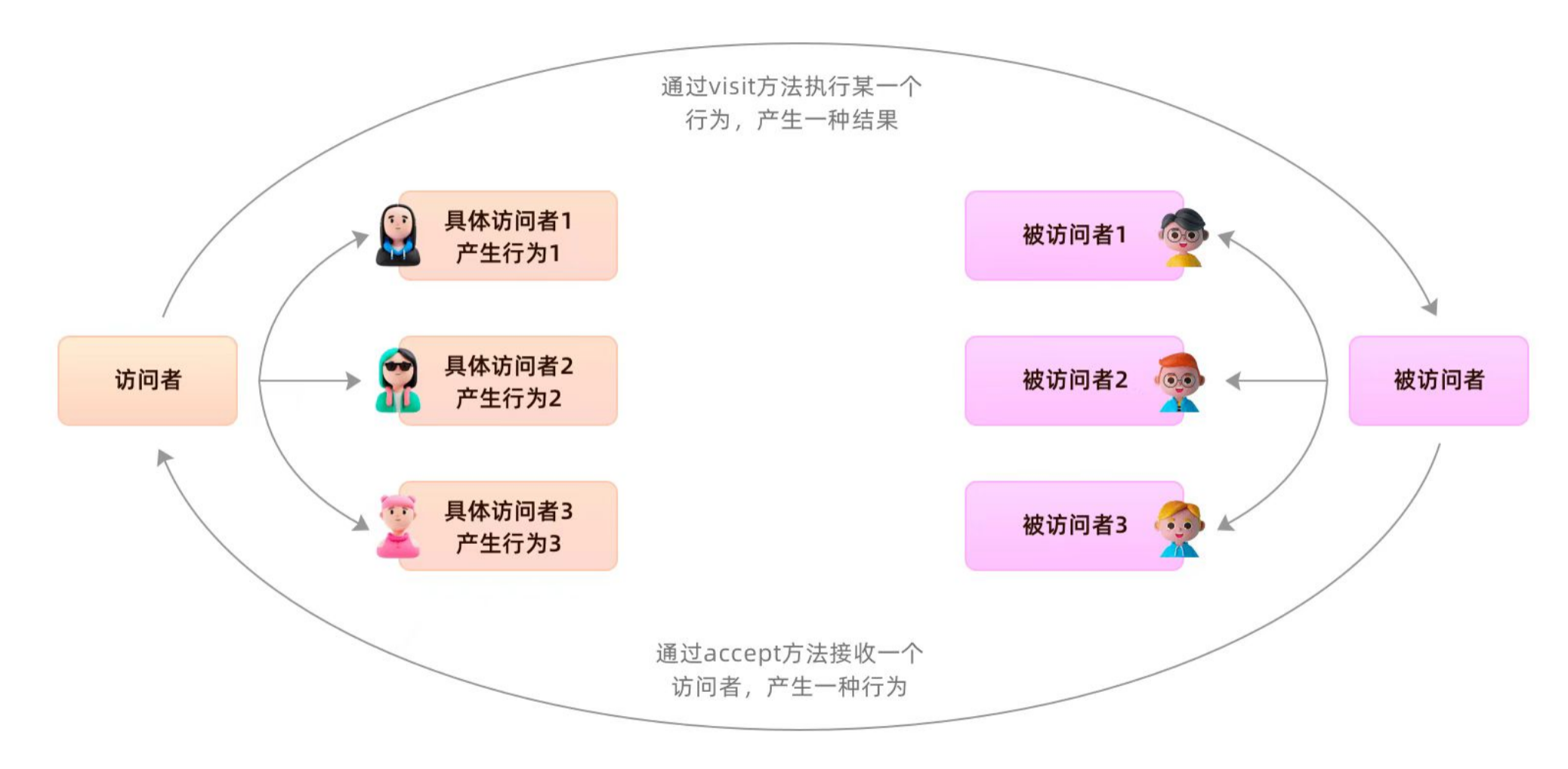
综合对比与选型建议
1. Qwen2.5-0.5B
适用性分析:
• 优势:
• 工业级全流程支持:阿里云提供了完整的预训练、微调、强化学习(RLHF)代码和文档,支持从数据处理到模型部署的全链路实践。
• 性能与场景适配:在轻量级模型中表现突出,尤其在数学推理(MATH基准得分83.1)和代码生成(HumanEval得分86.6)任务上优于同类模型。
• 生态成熟:已集成到Hugging Face、ModelScope等平台,支持量化(如INT4)部署,显存需求最低仅需398MB。
• 局限性:
• 预训练成本较高:持续预训练需16GB显存显卡(如V100),个人设备可能难以满足。
• 复杂度较高:涉及大规模数据处理(18T tokens)和分布式训练优化,学习曲线较陡峭。
适用场景:
• 希望全面学习工业级大模型全流程(预训练→微调→强化学习→部署),且具备中端显卡(如RTX 3060)的用户。
2. MiniMind
适用性分析:
• 优势:
• 极致轻量化:最小模型仅26MB,可在低端显卡(如GTX 1070)或CPU上运行,显存占用低至2GB。
• 快速迭代:支持3小时内从零训练模型,提供预训练、SFT、LoRA、RLHF-DPO全流程代码,适合快速实验。
• 成本极低:官方宣称训练成本仅需3元(云服务),本地部署无需高端硬件。
• 局限性:
• 模型能力受限:参数量小(0.5B以下),复杂任务(如长文本生成、数学推理)表现较弱。
• 生态不完善:社区支持较少,缺乏企业级应用验证。
适用场景:
• 预算极低(仅入门级显卡或CPU)、希望快速验证算法原型(如LoRA微调、蒸馏)的用户。
3. 《大模型白盒子构建指南》
适用性分析:
• 优势:
• 原理深度剖析:从零手搓Transformer架构、RAG框架、Agent系统,显存需求仅2GB,适合彻底理解底层机制。
• 教学导向:提供全流程代码注释和原理讲解(如RoPE位置编码、MoE混合专家),强化理论基础。
• 灵活扩展:支持自定义模型架构(如Tiny Llama3)和评估体系,适合研究型学习。
• 局限性:
• 工业实践不足:未提供大规模预训练代码,更多聚焦于教学复现而非生产级优化。
• 任务覆盖有限:当前版本主要覆盖RAG和Agent,强化学习部分尚在开发中。
适用场景:
• 希望深入理解大模型底层原理(如注意力机制、MoE架构)、具备基础编程能力的学术研究者。
最终推荐方案
根据需求优先级排序:
-
优先选择《大模型白盒子构建指南》:
• 理由:显存需求最低(2GB),且从零手搓全流程(架构→预训练→评估→应用),适合系统性学习底层原理。
• 补充建议:结合Qwen2.5的预训练数据清洗方法,提升数据处理实战能力。 -
次选MiniMind:
• 理由:快速实验成本最低,适合验证微调(如LoRA)和强化学习(DPO)算法。
• 补充建议:后期可迁移至Qwen2.5-0.5B,提升复杂任务处理能力。 -
谨慎尝试Qwen2.5-0.5B:
• 理由:需至少16GB显存显卡(如V100)支持持续预训练,适合有硬件条件的用户。
• 替代方案:仅使用其推理和微调功能(8GB显存),跳过预训练阶段。
学习路径建议
-
第一阶段(理论奠基):
• 使用《白盒子指南》手搓Tiny Transformer,理解位置编码(RoPE)、FFN层等核心模块。
-Qwen2.5的技术报告,学习数据清洗(如18T tokens过滤策略)和混合精度训练技巧。 -
第二阶段(轻量实践):
• 在MiniMind上实现LoRA微调,结合合成数据(如SkyPile-150B)验证模型迭代效果。
• 尝试Qwen2.5-0.5B的INT4量化推理,部署本地问答系统(Ollama框架)。 -
第三阶段(工业级扩展):
• 租用云服务器(如阿里云PAI平台),复现Qwen2.5-0.5B的强化学习流程(DPO+GRPO)。
• 结合白盒子指南的RAG框架,构建垂直领域知识增强应用。
通过以上方案,可在有限预算下平衡理论与实践,逐步掌握大模型全流程核心技术。