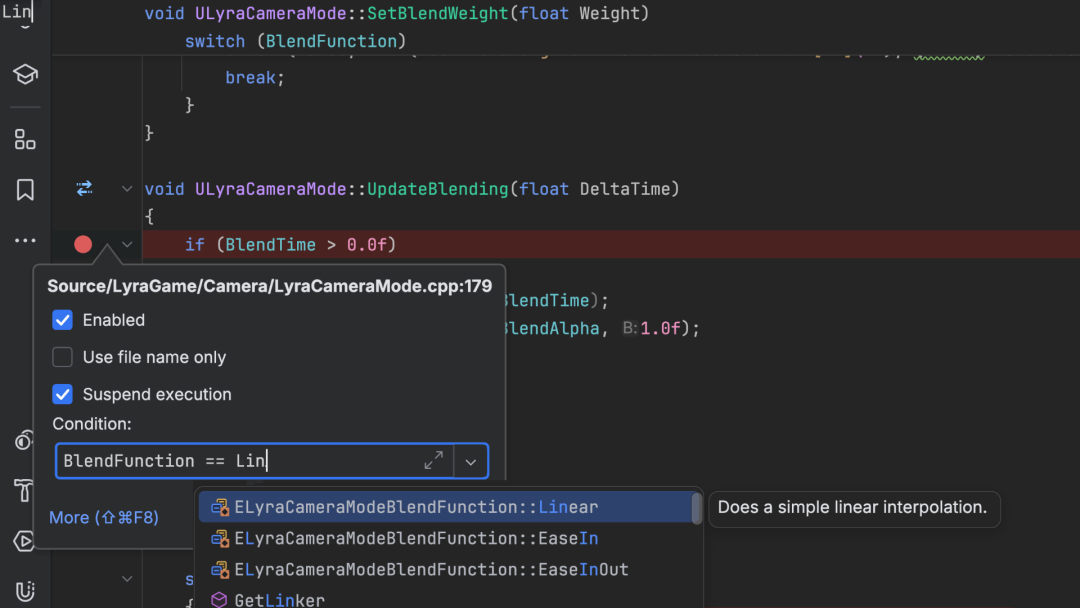
在 Spark 中,当 map 和 filter 这类窄依赖(Narrow Dependency)的算子连续应用时,它们会被合并到同一个 Stage 中,并且在同一个 Task 内按顺序执行。这种优化称为 流水线(Pipeline)执行,其核心目的是减少中间数据的物化(不生成中间 RDD 的物理存储),从而提高执行效率。
详细原理说明
1. Stage 的划分依据
Spark 根据 宽依赖(Shuffle Dependency) 划分 Stage。每个宽依赖会触发 Stage 的切分,而连续的窄依赖操作(如 map → filter)会合并到同一个 Stage。
2. Task 的生成与执行
- Stage 内生成 Task:每个 Stage 会被划分为多个 Task,Task 的数量与 Stage 的最后一个 RDD 的分区数一致。
- Task 的执行逻辑:每个 Task 按顺序执行 Stage 内的所有窄依赖操作(如
map→filter),无需将中间结果写入磁盘或内存。
3. 流水线(Pipeline)优化
- 避免中间数据物化:对于连续的窄依赖操作,Spark 会将它们合并为一个计算链(Compute Chain),在内存中逐条处理数据,而不是先生成
map后的中间结果再执行filter。 - 函数组合:实际上,
map和filter的函数会被合并为一个复合函数,按顺序应用到每条数据上。
示例说明
假设有以下代码:
val rdd = sc.parallelize(1 to 100)
val mapped = rdd.map(x => x * 2) // 窄依赖
val filtered = mapped.filter(x => x > 50) // 窄依赖
filtered.collect()
执行流程
- Stage 划分:由于
map和filter都是窄依赖,它们被合并到同一个 Stage。 - Task 执行:
- 每个 Task 处理一个分区(例如分区0的数据为
[1, 2, ..., 100])。 - Task 内部按顺序执行
map(x => x * 2)和filter(x => x > 50)。 - 数据流:原始数据 → 逐条应用
map→ 立即应用filter→ 最终结果。
- 每个 Task 处理一个分区(例如分区0的数据为
- 无中间存储:
map后的中间结果不会写入磁盘或内存,直接传递给filter。
验证方法
可以通过 Spark UI 或 日志 观察执行计划:
- DAG 可视化:在 Spark UI 的 DAG Visualization 中,
map和filter会被合并为一个 Stage。 - 物理计划:通过
filtered.toDebugString查看 RDD 的血缘关系,确认无 Shuffle 操作。
特殊情况与注意事项
-
缓存(Cache/Persist)会破坏流水线:
- 如果在
map后显式缓存数据(如mapped.cache()),则map和filter会被拆分到不同 Stage。 - 此时,
map的结果会被物化到内存/磁盘,filter的 Task 需要从缓存中读取数据。
- 如果在
-
非连续窄依赖:
- 如果
map和filter之间插入宽依赖操作(如repartition),则会被拆分到不同 Stage。
- 如果
性能影响
- 优势:流水线执行减少了数据序列化、磁盘 I/O 和内存占用,显著提升性能。
- 劣势:如果某个操作非常耗时(如复杂计算),可能无法充分利用流水线的优势。
总结
- 同一 Task 内执行:连续的窄依赖算子(如
map→filter)会在同一个 Task 内按顺序处理。 - 优化核心:通过流水线执行避免中间数据物化,减少资源开销。
- 例外场景:缓存或宽依赖会中断流水线,导致 Stage 切分。