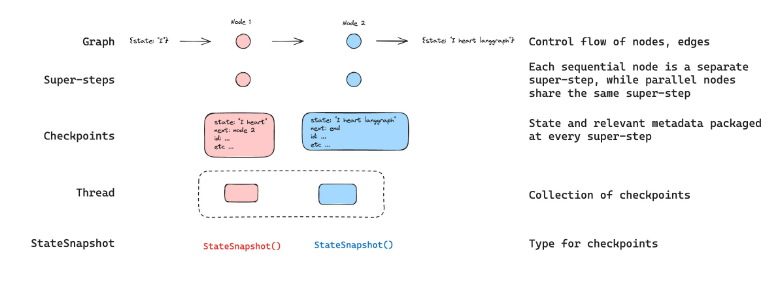
LangGraph 内置了一个持久化层,通过检查点(checkpointer)机制实现。当你使用检查点器编译图时,它会在每个超级步骤(super-step)自动保存图状态的检查点。这些检查点被存储在一个线程(thread)中,可在图执行后随时访问。由于线程允许在执行后访问图的状态,因此实现了人工介入(human-in-the-loop)、记忆(memory)、时间回溯(time travel)和容错(fault-tolerance)等强大功能。具体操作指南提供了端到端示例,说明如何为图添加并使用检查点器。下文我们将分别的详细讨论这些概念。
什么是内存(memory)?
记忆是一种认知功能,允许人们存储、检索和使用信息来理解他们的现在和未来。想象一下,与一个总是忘记你告诉他们事情的同事合作是多么令人沮丧,这需要不断地重复!随着人工智能代理承担涉及众多用户交互的更复杂任务,为它们配备记忆功能对于提高效率和用户满意度同样至关重要。通过记忆功能,代理可以从反馈中学习,并适应用户的偏好。
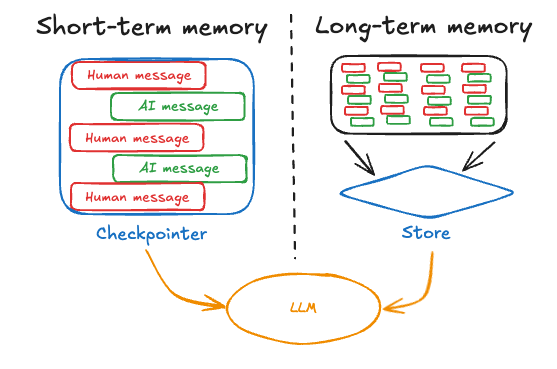
短期记忆(Short-term memory,),或称为线程范围内的记忆,可以在与用户的单个对话线程中的任何时间被回忆起来。LangGraph将短期记忆管理为代理状态的一部分。状态会被使用检查点机制保存到数据库中,以便对话线程可以在任何时间恢复。当图谱被调用或者一个步骤完成时,短期记忆会更新,并且在每个步骤开始时读取状态。
这种记忆类型使得AI能够在与用户的持续对话中保持上下文和连贯性,确保了交互的流畅性和效率。例如,在一系列的询问、回答或命令执行过程中,用户无需重复之前已经提供的信息,因为AI能够记住这些细节并根据需要利用这些信息进行响应或进一步的操作。这对于提升用户体验,尤其是复杂任务处理过程中的体验至关重要。
长期记忆(Long-term memory)是在多个对话线程之间共享的。它可以在任何时间、任何线程中被回忆起来。记忆的范围可以限定在任何自定义命名空间内,而不仅仅局限于单个线程ID。LangGraph提供了存储机制,允许您保存和回忆长期记忆。
这种记忆类型使得AI能够在不同对话或用户交互中保留和利用信息。例如,用户的偏好、历史记录或特定的上下文信息可以跨会话保存下来,并在未来的任何交互中被调用。这种方式为用户提供了一种无缝体验,无论他们何时或以何种方式与AI交互,AI都能根据过去的信息做出更个性化、更智能的响应。这对于构建深度用户关系和增强系统适应性至关重要。
持久化
许多AI应用需要记忆功能来在多次交互中共享上下文。在LangGraph中,这种类型的记忆可以通过线程级别的持久化添加到任何StateGraph中。
通过使用线程级别的持久化,LangGraph允许AI在与用户的连续对话或交互过程中保持信息的连贯性和一致性。这意味着,在一个交互中获得的信息可以被保存并在后续的交互中使用,极大地提升了用户体验。例如,用户在一个会话中表达的偏好可以在下一个会话中被记住和引用,使得交互更加个性化和高效。这种方法对于需要处理复杂或多步骤任务的应用特别有用,因为它确保了用户无需重复提供相同的信息,同时也让AI能够更好地理解和响应用户的需求。
LangGraph中使用 Memory
在创建任何LangGraph图时,您可以通过在编译图时添加一个检查点来设置其状态的持久化。这样做可以确保图的状态(包括短期和长期记忆中的信息)能够被保存下来,以便在未来的时间点恢复和继续执行。
如下面例子
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
graph.compile(checkpointer=checkpointer)
我们先尝试一下定义普通图,不使用memory,那么对话的上下文将不会在交互之间持续存在。
import os
os.environ["OPENAI_API_KEY"] = 'sk-XXXXXXXXXXXXX'
os.environ["OPENAI_API_BASE"] = 'https://openkey.cloud/v1'
os.environ["SERPAPI_API_KEY"] = 'XXXXXXXXX'
os.environ["TAVILY_API_KEY"] = 'tvly-XXXXXX'
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, MessagesState, START
def call_model(state: MessagesState):
response = llm.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_edge(START, "call_model")
graph = builder.compile()
input_message = {"role": "user", "content": "hi! I'm bob"}
for chunk in graph.stream({"messages": [input_message]}, stream_mode="values"):
chunk["messages"][-1].pretty_print()
input_message = {"role": "user", "content": "what's my name?"}
for chunk in graph.stream({"messages": [input_message]}, stream_mode="values"):
chunk["messages"][-1].pretty_print()
得到下面结果,大模型交互的时候并没有记忆力
================================ Human Message =================================
hi! I'm bob
================================== Ai Message ==================================
Hi Bob! How can I assist you today?
================================ Human Message =================================
what's my name?
================================== Ai Message ==================================
I'm sorry, but I don't have access to personal information about you unless you share it with me. How can I assist you today?
为了添加持久性,我们需要在编译图表时传递检查台。这个时候当我们给Graph添加上面MemorySaver_的时候,我们就可以与代理商进行互动,并看到它记住以前的消息!
config = {"configurable": {"thread_id": "1"}}
input_message = {"role": "user", "content": "hi! I'm bob"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
hi! I'm bob
================================== Ai Message ==================================
Hi Bob! How can I assist you today?
这个时候我们再问一下大模型我们的名字
input_message = {"role": "user", "content": "what's my name?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
what's my name?
================================== Ai Message ==================================
Your name is Bob! How can I help you today?
如果我们想开始一个新的对话,可以通过传递不同的会话标识符或配置来实现。这意味着为新的交互创建一个独立的上下文,确保新对话不会受到之前对话状态的影响,从而保持数据和记忆的隔离。
input_message = {"role": "user", "content": "what's my name?"}
for chunk in graph.stream(
{"messages": [input_message]},
{"configurable": {"thread_id": "2"}},
stream_mode="values",
):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
what's my name?
================================== Ai Message ==================================
I'm sorry, but I don't have access to personal information about users unless it has been shared with me in the course of our conversation. How can I assist you today?
这样子所有的回忆都消失了。
LangGraph中使用 InMemoryStore
InMemoryStore是一个基于内存的存储系统,用于在程序运行时临时保存数据。它通常用于快速访问和存储短期记忆或会话数据。我们可以使用使用 langgraph 和 langchain_openai 库来创建一个基于内存的存储系统(InMemoryStore),并结合 OpenAI 的嵌入模型 (OpenAIEmbeddings) 来处理嵌入向量。
大家可能有疑惑,我们不是用了MemorySaver持久化消息吗,为啥还要用InMemoryStore,他们的主要区别在于数据的持久性和应用场景。InMemoryStore主要用于短期、临时的数据存储,强调快速访问;而MemorySaver则侧重于将数据从临时存储转移到持久存储,确保数据可以在多次程序执行间保持不变。在我们设计系统时,可以根据具体需求选择合适的存储策略。对于只需要在会话内保持的数据,可以选择InMemoryStore;而对于需要长期保存并能够在不同会话间共享的数据,则应考虑使用MemorySaver或其他形式的持久化存储解决方案。
下面给大家展示一个结合两种方式的例子,我们实现了一个对话模型的调用逻辑,通过从存储系统中检索与用户相关的记忆信息并将其作为上下文传递给模型,同时支持根据用户指令存储新记忆,确保每个用户的记忆数据独立且自包含,从而提升对话的个性化和连贯性。
from langgraph.store.memory import InMemoryStore
from langchain_openai import OpenAIEmbeddings
in_memory_store = InMemoryStore(
index={
"embed": OpenAIEmbeddings(model="text-embedding-3-small"),
"dims": 1536,
}
)
import uuid
from typing import Annotated
from typing_extensions import TypedDict
from langchain_anthropic import ChatAnthropic
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.memory import MemorySaver
from langgraph.store.base import BaseStore
model = ChatAnthropic(model="claude-3-5-sonnet-20240620")
def call_model(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
memories = store.search(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# Store new memories if the user asks the model to remember
last_message = state["messages"][-1]
if "remember" in last_message.content.lower():
memory = "User name is Bob"
store.put(namespace, str(uuid.uuid4()), {"data": memory})
response = model.invoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=MemorySaver(), store=in_memory_store)
然后运行图
config = {"configurable": {"thread_id": "1", "user_id": "1"}}
input_message = {"role": "user", "content": "Hi! Remember: my name is Bob"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
得到下面结果
================================ Human Message =================================
Hi! Remember: my name is Bob
================================== Ai Message==================================
Hello Bob! It's nice to meet you. I'll remember that your name is Bob. How can I assist you today?
我们先改变一下config
config = {"configurable": {"thread_id": "2", "user_id": "1"}}
input_message = {"role": "user", "content": "what is my name?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
得到下面结果
================================ Human Message =================================
what is my name?
================================== Ai Message ==================================
Your name is Bob.
现在,我们可以检查我们的store,并验证我们实际上已经为用户保存了记忆:
for memory in in_memory_store.search(("memories", "1")):
print(memory.value)
得到结果
{'data': 'User name is Bob'}
现在,让我们为另一个用户运行这个图,以验证关于第一个用户记忆是独立且自包含的。
config = {"configurable": {"thread_id": "3", "user_id": "2"}}
input_message = {"role": "user", "content": "what is my name?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
可以看到,我们之前存储的名字,换了用户id之后大模型已经忘了。
================================ Human Message =================================
what is my name?
================================== Ai Message ==================================
I apologize, but I don't have any information about your name. As an AI assistant, I don't have access to personal information about users unless it has been specifically shared in our conversation. If you'd like, you can tell me your name and I'll be happy to use it in our discussion.