简介

LAM项目结合了3D Gaussian Splatting(高斯点云渲染)和大规模预训练模型的优势,解决了传统头部重建方法效率低、依赖多数据的痛点。其背景源于AI生成内容(AIGC)领域对实时、高保真3D头像生成的需求,尤其是在虚拟现实、游戏、虚拟主播等场景中。
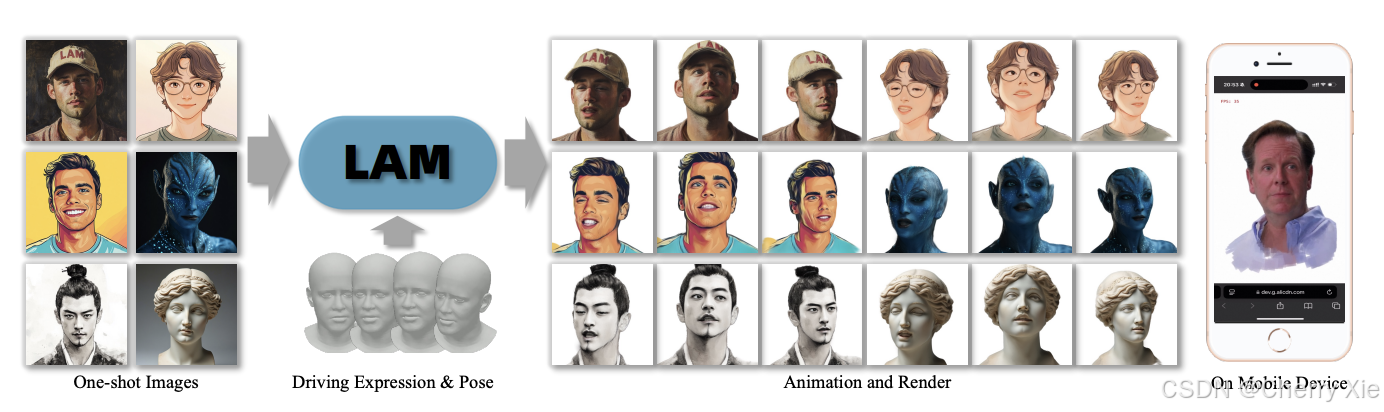
技术背景与研究动机
近年来,3D头部重建和动画生成技术在虚拟现实(VR)、增强现实(AR)、游戏、影视制作以及在线会议等场景中需求日益增加。传统方法通常需要多视角图像或视频序列来训练模型,并且在推理阶段依赖额外的神经网络进行动画和渲染,这导致计算成本高、实时性差。LAM项目的目标是解决这些问题,通过“单张图像输入”(One-shot)生成可立即动画化和渲染的3D头部模型,显著降低使用门槛并提升效率。
该项目受到3D Gaussian Splatting(3DGS)技术的启发,这是一种近年来兴起的3D表示方法,通过高斯分布的点云来高效渲染复杂场景。LAM将这一技术与大规模预训练模型结合,试图在单次前向传播中完成头部重建和动画准备,填补现有技术在实时性和泛化能力上的不足。
核心技术与创新点
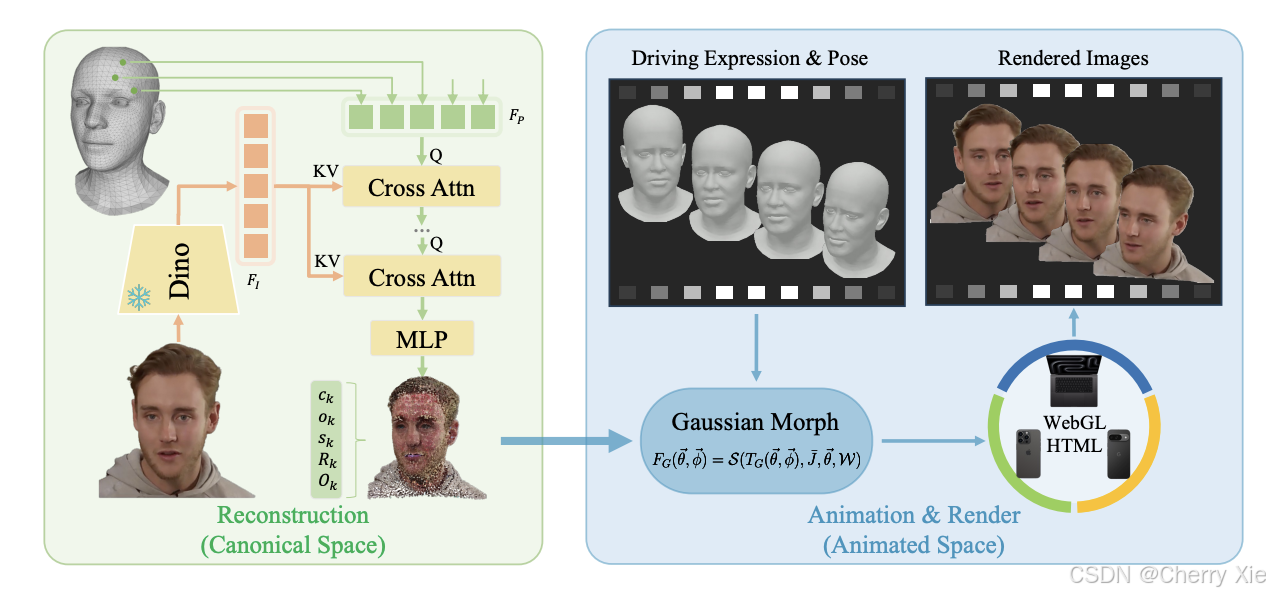
LAM的核心在于其“Canonical Gaussian Attributes Generator”(规范高斯属性生成器),这是一个基于FLAME模型(一种经典的3D可变形头部模型)的框架。具体创新点包括:
-
单张图像重建:通过从单张图像预测3D高斯点云的属性(如位置、颜色、透明度等),LAM避免了多视角输入的需求。
-
实时动画与渲染:生成的3D头部模型直接支持基于FLAME的线性混合蒙皮(Linear Blend Skinning, LBS)和表情修正(Corrective Blendshapes),无需额外的后处理或辅助网络。
-
跨平台兼容性:通过WebGL渲染支持,LAM可以在包括移动设备在内的多种平台上实现实时动画和渲染。
-
多尺度特征融合:利用Transformer架构,将FLAME的规范点与图像的多尺度特征进行交互,提升重建精度和纹理细节。
-
这些特性使LAM在保持高质量重建的同时,显著提高了效率和实用性。
开发历程与现状
-
论文发布:2025年2月23日,LAM的学术论文在arXiv上公开,详细描述了方法论和实验结果,表明其在现有基准测试中超越了当时的最优方法。
-
代码开源:GitHub仓库(aigc3d/LAM)提供了LAM-small(基于VFHQ数据集训练)和LAM-large(基于更大自建数据集训练)的模型,以及安装脚本和推理代码。代码支持CUDA 11.8或12.1环境,并发布了Hugging Face和ModelScope的空间用于展示。
-
功能扩展:项目后续更新包括音频驱动模型(Audio2Expression)和互动聊天头像SDK(OpenAvatarChat),显示其向多模态和实用化方向发展。
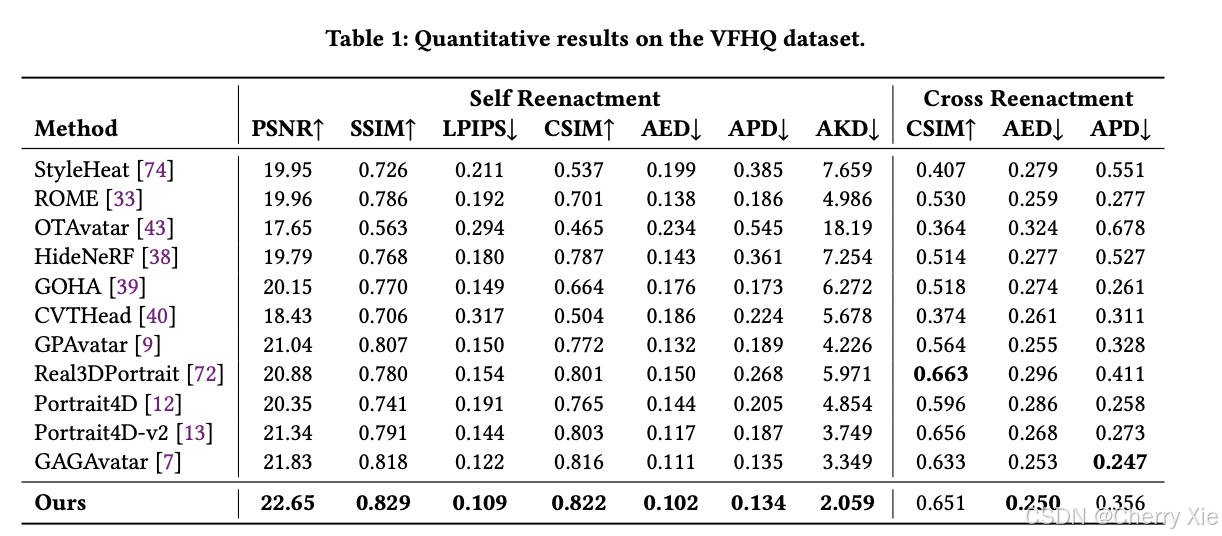
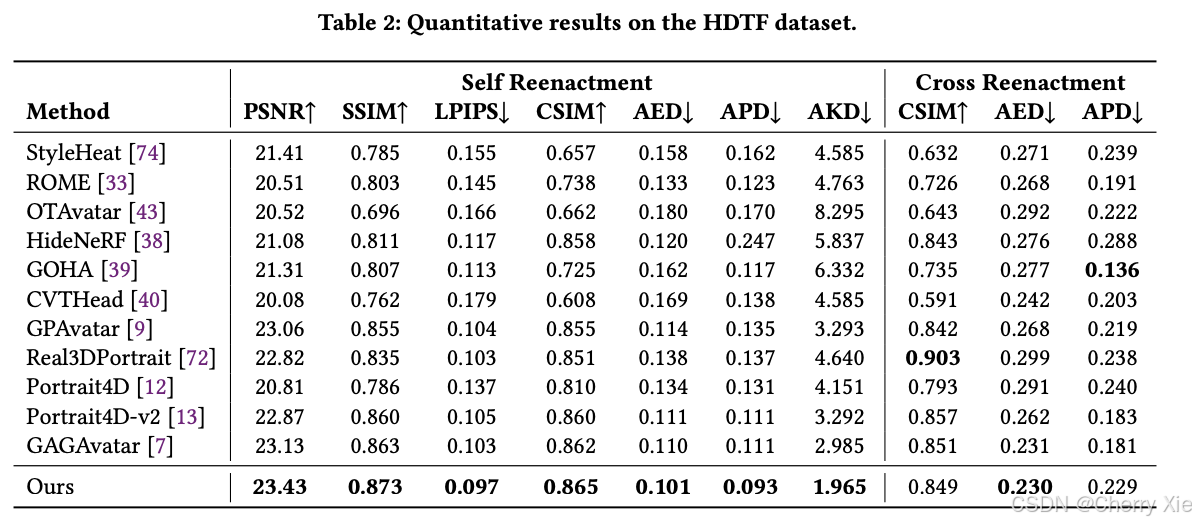
性能对比
详情见技术报告
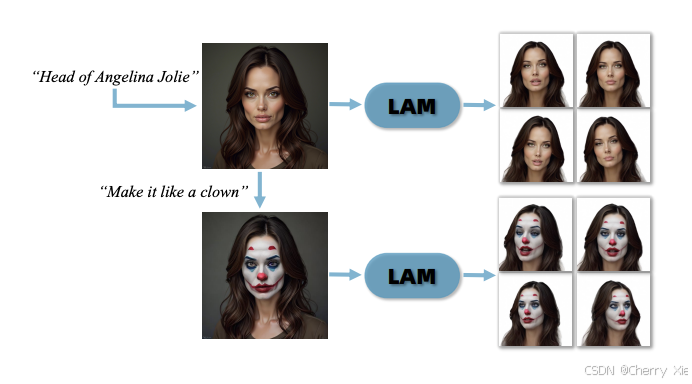
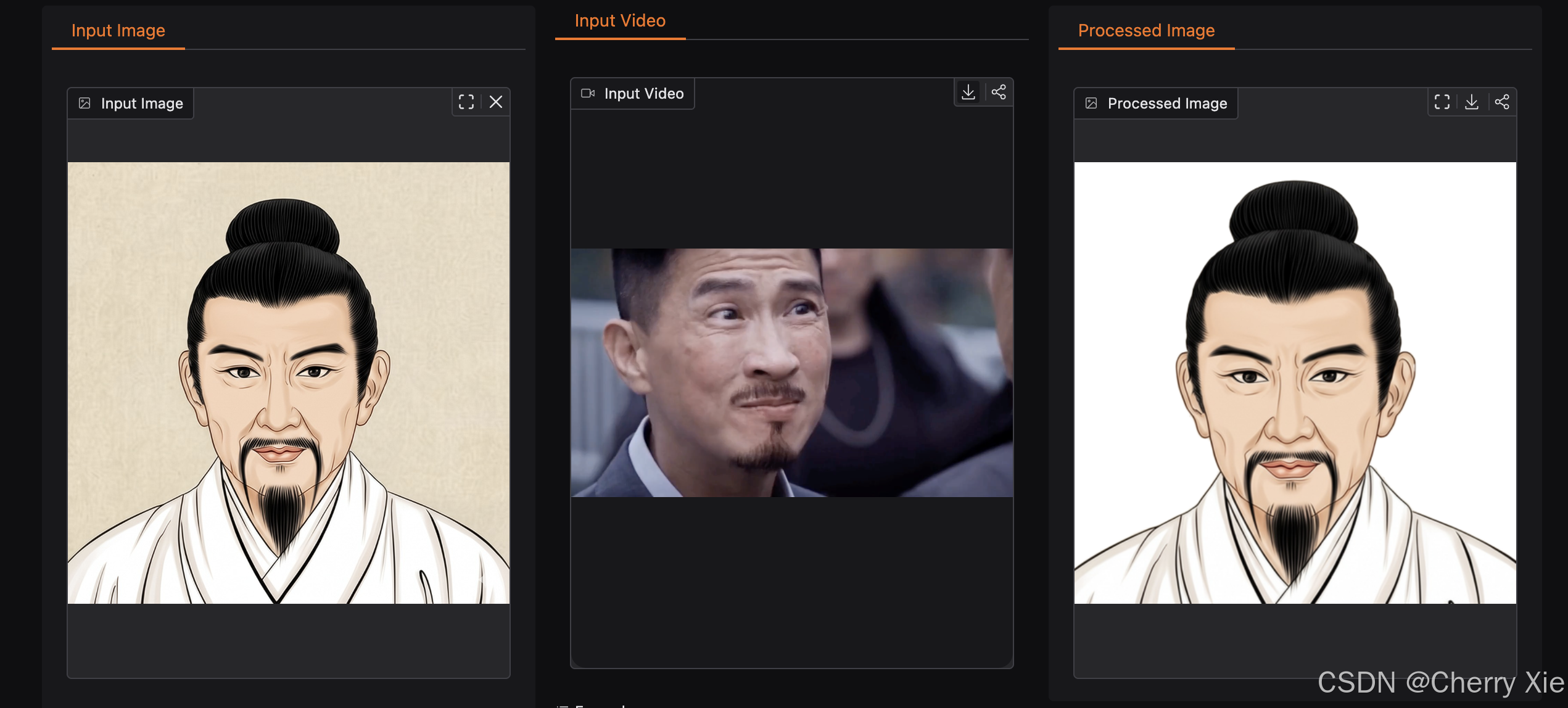
看看效果
相关文献
技术报告:https://arxiv.org/pdf/2502.17796
HF在线体验地址:https://huggingface.co/spaces/3DAIGC/LAM
MS在线体验地址:https://www.modelscope.cn/studios/Damo_XR_Lab/LAM_Large_Avatar_Model
github项目地址:https://github.com/aigc3d/LAM