- 1. GPU与CPU并行计算框架
- 2. CUDA编程模型
- 3 CUDA程序
1. GPU与CPU并行计算框架
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device),如下图所示。
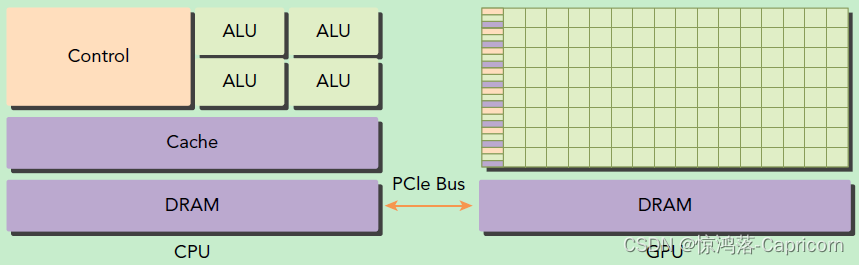 GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,
GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。
CUDA是NVIDIA公司所开发的GPU编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序。CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言。
CUDA编译器:nvcc
CUDA调试器:nvcc-gdb
CUDA性能分析:nsight

2. CUDA编程模型
host指代CPU及其内存,包含host程序。
device指代GPU及其内存,包含device程序。
host与device之间可以进行通信,这样它们之间可以进行数据拷贝。
经典CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用
CUDA的核函数在device上完成指定的运算; - 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
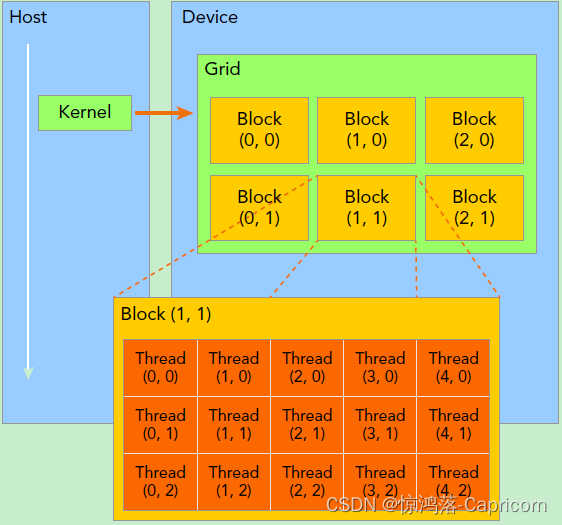
·kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格grid,同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块block,一个线程块里面包含很多线程,这是第二个层次。
 核函数声明:
核函数声明:
·核函数用__global__符号声明
__global__ 返回值类型 核函数名(形参列表){
...
}
核函数调用:
·在调用时需要用<<<grid, block>>>来指定kernel要执行的线程数量,grid是网格块数,block是每块的线程数。grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,xyz的缺省值初始化为1。 因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构。
dim3 grid(3, 2);//一个grid包含6个block
dim3 block(5, 3);//每个block包含15个线程
核函数名<<<grid,block>>>(实参列表)
线程ID:
·在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
因此一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是dim3类型变量,其中blockIdx指明线程所在grid中的位置,而threaIdx指明线程所在block中的位置。
如上图中Thread(1,1)标识如下:
threadIdx.x = 1
threadIdx.y = 1
blockIdx.x = 1
blockIdx.y = 1
一个线程块上的线程是放在同一个流式多处理器(SM)上的,现代GPUs的线程块可支持的线程数可达1024个。
要知道一个线程在blcok中的全局ID,此时就必须还要知道block的组织结构,这是通过线程的内置变量blockDim来获得,它获取线程块各个维度的大小。另外线程还有内置变量gridDim,用于获得网格块各个维度的大小。
·grid的内置变量:x,y,z,gridDim
·block的内置变量:x,y,z,blockDim
host和device函数区分:
由于GPU实际上是异构模型,区别host和device上的函数,主要的三个函数类型限定词如下:
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
内存模型
CUDA的内存模型:每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)。内存结构涉及到程序优化,这里不深入探讨。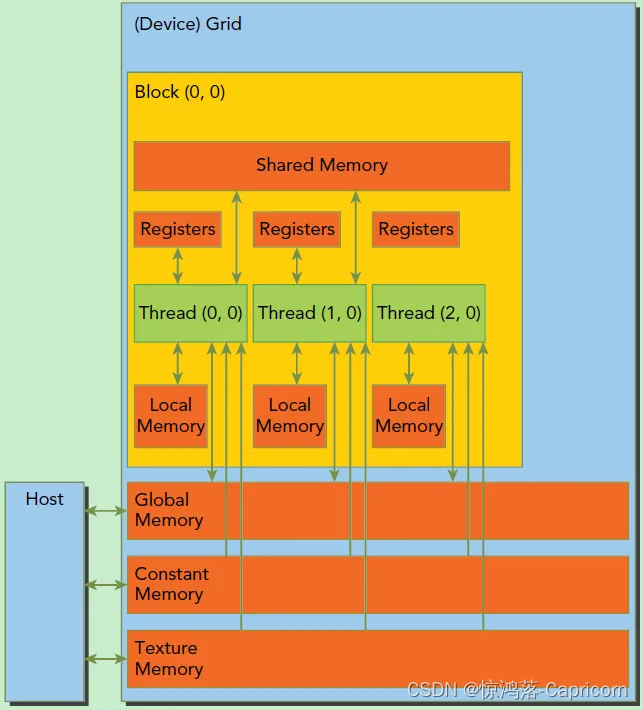 硬件基础
硬件基础
GPU硬件的一个核心组件是SM,前面已经说过,SM是英文名是 Streaming Multiprocessor,翻译过来就是流式多处理器。SM的核心组件包括CUDA核心,共享内存,寄存器等,SM可以并发地执行数百个线程,并发能力就取决于SM所拥有的资源数。当一个kernel被执行时,它的gird中的线程块被分配到SM上,一个线程块只能在一个SM上被调度。SM一般可以调度多个线程块,这要看SM本身的能力。那么有可能一个kernel的各个线程块被分配多个SM,所以grid只是逻辑层,而SM才是执行的物理层。SM采用的是SIMT (Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(warps),线程束包含32个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管线程束中的线程同时从同一程序地址执行,但是可能具有不同的行为,比如遇到了分支结构,一些线程可能进入这个分支,但是另外一些有可能不执行,它们只能死等,因为GPU规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。当线程块被划分到某个SM上时,它将进一步划分为多个线程束,因为这才是SM的基本执行单元,但是一个SM同时并发的线程束数是有限的。这是因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器。所以SM的配置会影响其所支持的线程块和线程束并发数量。总之,就是网格和线程块只是逻辑划分,一个kernel的所有线程其实在物理层是不一定同时并发的。所以kernel的grid和block的配置不同,性能会出现差异,这点是要特别注意的。还有,由于SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。
在进行CUDA编程前,可以先检查一下自己的GPU的硬件配置,这样才可以有的放矢,可以通过下面的程序获得GPU的配置属性:
#include <iostream>
using namespace std;
__global__ void helloFromGPU ()
{
printf("Hello, world! from GPU!\n");
}
int main()
{
cudaDeviceReset();
int dev = 0;
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, dev);
std::cout << "使用GPU device " << dev << ": " << devProp.name << std::endl;
std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl;
std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl;
std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl;
std::cout << "每个EM的最大线程数:" << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "每个SM的最大线程束数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl;
return 0;
}
// 输出如下
使用GPU device 0: NVIDIA GeForce GTX 1650
SM的数量:16
每个线程块的共享内存大小:48 KB
每个线程块的最大线程数:1024
每个EM的最大线程数:1024
每个SM的最大线程束数:32
3 CUDA程序
kernel的这种线程组织结构天然适合vector,matrix等运算
1-dim结构实现两个向量的加法,每个线程负责处理每个位置的两个元素相加,代码如下所示。线程块大小为(256,1,1),然后将长度n的向量均分为不同的线程块来执行加法运算。
CUDA实现向量并行加法:
#include <stdio.h>
#include <cuda.h>
#include "aux.h"
typedef float FLOAT;
/* host, add */
void vec_add_host(FLOAT *x, FLOAT *y, FLOAT *z, int N);
/* device function */
__global__ void vec_add(FLOAT *x, FLOAT *y, FLOAT *z, int N)
{
/* 1D block */
int idx = get_tid();
if (idx < N) z[idx] = z[idx] + y[idx] + x[idx];
}
void vec_add_host(FLOAT *x, FLOAT *y, FLOAT *z, int N)
{
int i;
for (i = 0; i < N; i++) z[i] = z[i] + y[i] + x[i];
}
int main()
{
int N = 20000000;
int nbytes = N * sizeof(FLOAT);
/* 1D block */
int bs = 256;
/* 2D grid */
int s = ceil(sqrt((N + bs - 1.) / bs));
dim3 grid = dim3(s, s);
FLOAT *dx = NULL, *hx = NULL;
FLOAT *dy = NULL, *hy = NULL;
FLOAT *dz = NULL, *hz = NULL;
int itr = 30;
int i;
double th, td;
/* allocate GPU mem */
cudaMalloc((void **)&dx, nbytes);
cudaMalloc((void **)&dy, nbytes);
cudaMalloc((void **)&dz, nbytes);
if (dx == NULL || dy == NULL || dz == NULL) {
printf("couldn't allocate GPU memory\n");
return -1;
}
printf("allocated %.2f MB on GPU\n", nbytes / (1024.f * 1024.f));
/* alllocate CPU mem */
hx = (FLOAT *) malloc(nbytes);
hy = (FLOAT *) malloc(nbytes);
hz = (FLOAT *) malloc(nbytes);
if (hx == NULL || hy == NULL || hz == NULL) {
printf("couldn't allocate CPU memory\n");
return -2;
}
printf("allocated %.2f MB on CPU\n", nbytes / (1024.f * 1024.f));
/* init */
for (i = 0; i < N; i++) {
hx[i] = 1;
hy[i] = 1;
hz[i] = 1;
}
/* copy data to GPU */
cudaMemcpy(dx, hx, nbytes, cudaMemcpyHostToDevice);
cudaMemcpy(dy, hy, nbytes, cudaMemcpyHostToDevice);
cudaMemcpy(dz, hz, nbytes, cudaMemcpyHostToDevice);
/* call GPU */
cudaDeviceSynchronize();
td = get_time();
for (i = 0; i < itr; i++) vec_add<<<grid, bs>>>(dx, dy, dz, N);
cudaDeviceSynchronize();
td = get_time() - td;
/* CPU */
th = get_time();
for (i = 0; i < itr; i++) vec_add_host(hx, hy, hz, N);
th = get_time() - th;
printf("GPU time: %e, CPU time: %e, speedup: %g\n", td, th, th / td);
cudaFree(dx);
cudaFree(dy);
cudaFree(dz);
free(hx);
free(hy);
free(hz);
return 0;
}
参考视频:https://www.bilibili.com/video/BV1vJ411D73S/?spm_id_from=333.999.0.0&vd_source=b2549fdee562c700f2b1f3f49065201b



![[Git] 系列四Push Pull —— Git 远程仓库和高级操作](https://img-blog.csdnimg.cn/fda11a18958d4465896a2ab58e3e14af.png#pic_center)