文章目录
- CPU 使用率飙高
- 事务问题
- 导致服务挂掉
CPU 使用率飙高
每条数据都有些业务逻辑,如果单线程导入所有的数据,导入效率会非常低。于是改成了多线程导入。
如果 excel 中有大量的数据,很可能会出现 CPU 使用率飙高的问题。
我们都知道,如果代码出现死循环,cpu 使用率会飚的很多高。
因为代码一直在某个线程中循环,没法切换到其他线程,cpu 一直被占用着,所以会导致 cpu 使用率一直高居不下。
而多线程导入大量的数据,虽说没有死循环代码,但由于多个线程一直在不停的处理数据,导致占用了 cpu 很长的时间。也会出现 cpu 使用率很高的问题。
那么,如何解决这个问题呢?
答:使用 Thread.sleep 休眠一下。
在线程中处理完一条数据,休眠 10 毫秒
当然 CPU 使用率飙高的原因很多,多线程处理数据和死循环只是其中两种,
还有比如:频繁 GC、正则匹配、频繁序列化和反序列化等。
事务问题
在实际项目开发中,多线程的使用场景还是挺多的。如果 spring 事务用在
多线程场景中,会有问题吗?
例如:
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser (userModel);
new Thread (() -> {
roleService.doOtherThing ();
}).start ();
}
}
@Service
public class RoleService {
@Transactional
public void doOtherThing() {
System.out.println ("保存 role 表数据");
}
}
从 上 面 的 例 子 中 , 我 们 可 以 看 到 事 务 方 法 add 中 , 调 用 了 事 务 方 法doOtherThing,但是事务方法 doOtherThing 是在另外一个线程中调用的。
这样会导致两个方法不在同一个线程中,获取到的数据库连接不一样,从而是两个不同的事务。如果想 doOtherThing 方法中抛了异常,add 方法也回滚是不可能的。
如果看过 spring 事务源码的朋友,可能会知道 spring 的事务是通过数据
库连接来实现的。当前线程中保存了一个 map,key 是数据源,value 是数
据库连接。
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
我们说的同一个事务,其实是指同一个数据库连接,只有拥有同一个数据库连 接才能同时提交和回滚。如果在不同的线程,拿到的数据库连接肯定是不一样 的,所以是不同的事务。
所以
不要在事务中开启另外的线程,去处理业务逻辑,这样会导致事务失效
导致服务挂掉
使用多线程会导致服务挂掉,这不是危言耸听,而是确有其事。
假设现在有这样一种业务场景:
在 mq 的消费者中需要调用订单查询接口,查到数据之后,写入业务表中。本来是没啥问题的。
突然有一天,mq 生产者跑了一个批量数据处理的 job,导致 mq 服务器上堆积了大量的消息。
此时,mq 消费者的处理速度,远远跟不上 mq 消息的生产速度,导致的结果是出现了`大量的消息堆积``,对用户有很大的影响
为了解决这个问题,mq 消费者改成多线程处理,直接使用了线程池,并且最大线程数配置成了 20。
这样调整之后,消息堆积问题确实得到了解决。
但带来了另外一个更严重的问题:订单查询接口并发量太大了,有点扛不住压力,导致部分节点的服务直接挂掉
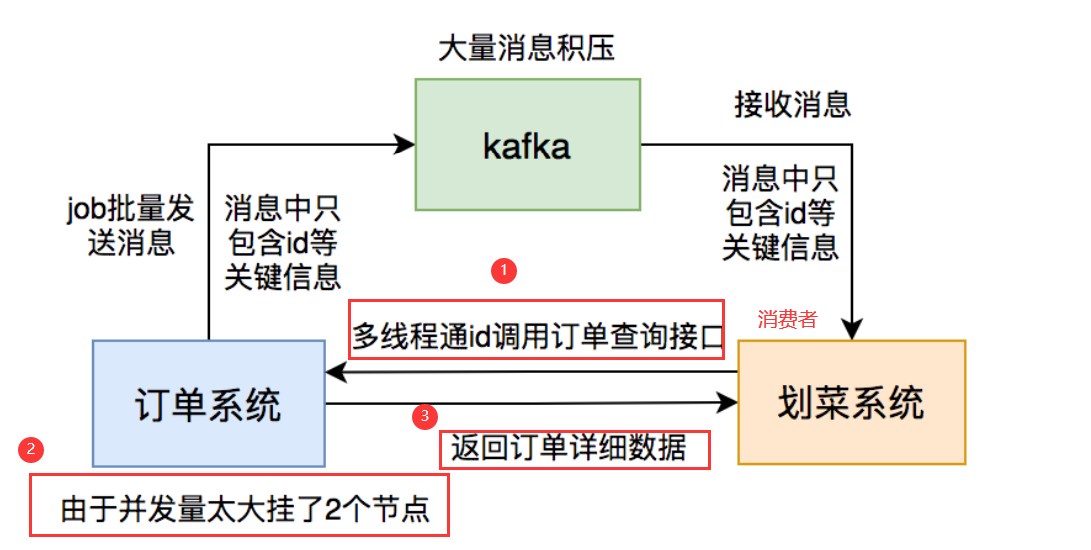
为了解决问题,不得不临时加服务节点。
在 mq 的消费者中
使用多线程,调用接口时,一定要评估好接口能够承受的最大访问量,防止因为压力过大,而导致服务挂掉的问题