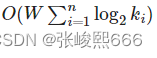文章目录
- 1. Introduction to OS
- 本章涉及
- 1.1 什么是操作系统?
- 1.2 为什么我们需要操作系统?
- 抽象 Abstraction
- 控制程序
- Summary
- 1.3 现代操作系统分类
- 1.4 操作系统结构
- OS结构
- OS是一个程序
- OS的实现
- 单片OS `Monolithic OS`
- 微核OS `Microkernel`
- 虚拟机 `Virtual Machines`
- 2. 进程抽象 `Process Abstraction`
- 2.1 进程管理
- 回忆:C程序和编译代码
- 回忆:程序执行——内存
- 回忆: 通用计算机架构
- 回忆:组件介绍
- 回忆:基本指令执行
- 回忆:你需要知道的
- 2.2 内存层面 Memory Context:函数调用 Function Call
- 2.2.1 函数调用 Function Call
- Function Call: Challenges
- Function Call:控制流和数据 Control Flow and Data
- 2.2.2 栈内存 `Stack Memory`
- 2.2.3 Illustration: Stack Frame v1.0
- 函数调用约定`function call convention`
- 1. 准备进行一个函数调用:
- 2. 调用函数g()
- 3. 结束函数调用,回到调用者
- 帧指针 `frame pointer`
- 保存的寄存器 `saved register`
- 2.2.4 Illustration: Stack Frame v2.0
- 注意,这只是个例子。
- 函数调用小结
- 2.3 内存层面 Memory Context:动态分配内存 Dynamically Allocated Memory
- 堆内存 `Heap memory`
- 2.4 OS context:进程ID和进程状态 ProcessID & Process State
- 2.5 进程表和进程控制块 Process Table & Process Control Block
- 进程表
- 2.6 进程和OS之间交互:系统调用 `System Calls`
- 2.7 进程和OS之间交互:Exception and Interrupt
- Exception
- Interrupt
- Exception / Interrupt Handler
- Summary
- 3. 进程调度 `Process Scheduling`
- 3.1 并发执行 `concurrent execution`
- 简化的并发示例
- 3.2 交错执行 Interleaved Execution:context switch
- 多任务OS
- 3.3 调度 Scheduling
- 进程行为 Process Behavior
- 处理环境 Processing Environment
- 调度算法的评判标准 Criteria for Scheduling Algorithm
- 什么时候执行调度?
- 调度步骤
- 3.4 批处理调度 `Scheduling Fro Batch Processing`
- (1)先到先得 First-Come-First-Served
- (2)短任务优先 Shortest-Job-First SJF
- (3)最短剩余时间 Shortest Remaining Time SRT
- 3.5 交互式系统的调度 Scheduling For Interactive System
- 交互式环境的评判标准
- 确保周期性调度
- Timer & Time Quantum
- 调度算法
- (1)循环赛 Round Robin (RR)
- (2)优先调度 Priority Scheduling
- (3)多级反馈队列 Multi-Level Feedback Queue (MLFQ)
- 规则
- 例子1
- 例子2: 例子1的基础上 + 中间有时候会出现短任务
- 例子3
- (4)彩票调度 Lottery Scheduling
- 性质
- Summary
- 4. 线程 Threads
- 4.1 Motivation for Thread
- 4.2 线程 Thread of Control
- 使用fork()创建多线程
- 使用Thread..do多线程
- Process and Thread
- 进程context交换 vs 线程交换
- 线程优点
- 线程的问题
- 4.3 线程模型 Thread Models
- 用户线程 `User Thread`
- 内核线程 Kernel Thread
- 混合线程模型 Hybrid Thread Model
- 5. 进程间通信 Inter-Process Communication
- 5.1 共享内存 `Shared-Memory`
- POSIX Shared Memory in *nix
- Master Program
- Slave Program
- 5.2 信息传递 Message Passing
- 命名机制:直接通信 Naming Scheme: Direct Communication
- 命名机制:间接通信 Naming Scheme: Indirect Communication
- 两种同步行为 Two Synchronization Behaviors
- 优缺点
- 5.3 Unix Pipes
- Piping in Shell
- Unix Pipes
- Unix Pipes:as an IPC Mechanism
- Unix Pipes: Semantic
- Unix Pipe:System Calls
- 示例代码
- 5.4 Unix Signal
- 6. 进程管理:同步 Process Management: Synchronization
- 并发执行的问题
- 竞争条件 Race Condition
- 临界区 Critical Section
- Critical Section的实现
- (1)汇编层面实现 Assembly Level Implementation
- (2)高级语言层面实现 High-Level-Language Implementation
- (3)高级抽象 High-Level Abstraction
- Wait() and Signal()
- 信号量例子:Critical Section
- 互斥量的非正式证明 Mutex:Correct CS - Informal Proof
- 不正确地使用信号量:死锁
- (4)其他高阶抽象
- 经典的同步问题 Classical Synchronization Problems
- (1)Producer-Consumer
- 生产者-消费者:忙等方式
- 生产者-消费者:阻塞方式
- (2)读者写者 Readers Writers
- 哲学家进餐问题 Dining Philosophers: Specification
- **`Tanenbaum Solution`**
- `有限进食者 Limited Eater `
- 同步的实现 Synchronization Implementations
- POSIX信号量
- pthread 互斥量和条件变量 Mutex and Conditional Variables
- 其他
- 7. 内存抽象 Memory Management:Memory Abstraction
- 7.1 内存基础
- 硬件
- 进程的内存使用
- 操作系统的作用
- Key Topics
- 7.2 内存抽象
- 实际地址-没有内存抽象
- 优点
- 缺点
- 逻辑地址
- 改进:地址搬迁 Address Relocation
- 改进:Base + Limit Registers
- 7.3 连续内存分配
- 多任务、context切换和交换 `Multitasking, Context Switching & Swapping`
- 内存分区 `Memory Partitioning`
- 固定大小分区
- 可变大小分区
- 分配算法 `Allocation Algorithm`
- 合并和压缩 `Merging and compaction`
- Example
- 动态分配算法:伙伴系统 `Buddy system`
- 伙伴系统:分配算法 Buddy System: Allocation Algorithm
- 伙伴系统:释放算法 Deallocation Algorithm
- 如何找到Buddy
- 8. 内存管理:不相交内存 Disjoint Memory Schemes
- 分页 Paging:基本思想
- 页表:查找机制
- 逻辑地址转换
- 逻辑地址转换:基本技巧
- 逻辑地址转换:公式
- 示例:4 个逻辑页,8 个物理帧
- 分页:观察
- 实施分页
- 分页机制:硬件支持
- TLB:对内存访问时间的影响
- TLB 和进程切换
- 分页方案:保护
- 分页方案:页面共享 Page Sharing
- 分割机制 segmentation scheme
- 细分方案:动机
- 分割方案:基本思想
- 分段:逻辑地址转换
- Segementation 优缺点
- 分页分割
- 分页分割:基本思想
- Summary
1. Introduction to OS
本章涉及
操作系统的基本概念:
- 什么是操作系统?
- 操作系统结构:组成部分、kernel的类型
- 虚拟机
Virtual Machines
1.1 什么是操作系统?
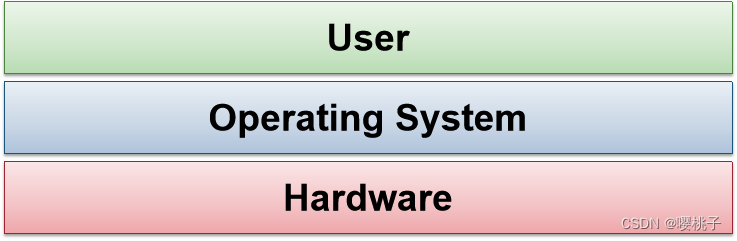
简单定义:在用户和电脑硬件之间的桥梁程序。
操作系统历史:略
1.2 为什么我们需要操作系统?
抽象 Abstraction
- 各种硬件配置之间有很大的差别,同一类硬件有定义清晰且通用的功能(例如硬盘用于存取数据)。
- 操作系统是一种抽象,隐藏了低阶的细节,只展示通用的、高阶的功能给用户。用户可以通过操作系统操作各种重要任务,而不用考虑底层实现的细节。由此提供了高效率和便捷性。
- 程序的执行需要不同的资源(CPU、内存、IO设备等)。为了充分利用资源,多个(使用不同资源)程序应该可以同时执行。OS是一个资源分配者,它管理所有的资源(CPU、内存、IO设备等),处理可能存在冲突的请求,高效和公平地使用资源。
控制程序
- 如果没有OS,程序可能错误地使用电脑硬件,有可能是意外导致(程序bug),也有可能是有意为之(病毒、恶意程序)。
- 不同地用户可以共享某台电脑,而【保证用户空间是相互隔离的】是一件复杂的事情。
- OS是一种控制程序,控制不同程序的执行,防止错误/不正确地使用电脑,提供了安全保障。
Summary
- 管理资源和协调:进程同步,资源共享
- 简化编程:硬件抽象,服务便捷
- 执行使用政策
- 安全和保护
- 用户程序可移植性:跨越不同的硬件
- 效率:复杂的实现;针对特定用途和硬件进行了优化
1.3 现代操作系统分类
1.4 操作系统结构
我们已经确定了OS的主要功能,现在我们来考虑实现这些功能的最好方式。
操作系统的结构是各种组成部分的组织方式,需要考虑这几个重要因素:灵活性Flexibility、稳定性Robustness、可维护性Maintainability。
OS结构
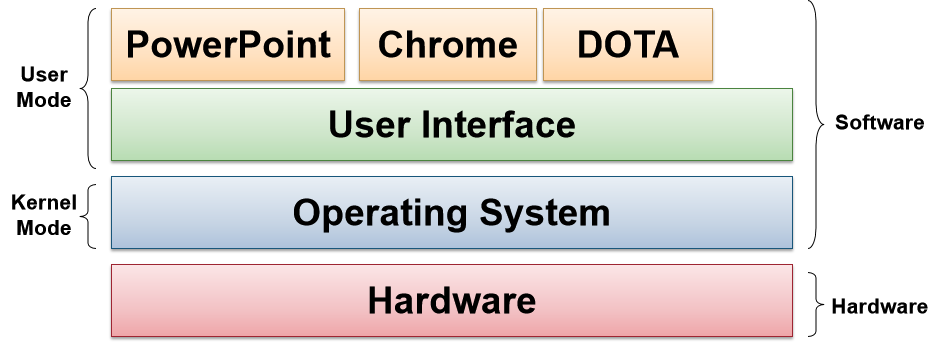
- 操作系统是运行在核心模式下
kernel mode的软件,拥有对所有硬件资源的操作权。 - 其他软件运行在用户模式下
user mode,拥有对硬件资源有限的/被控制的权限。
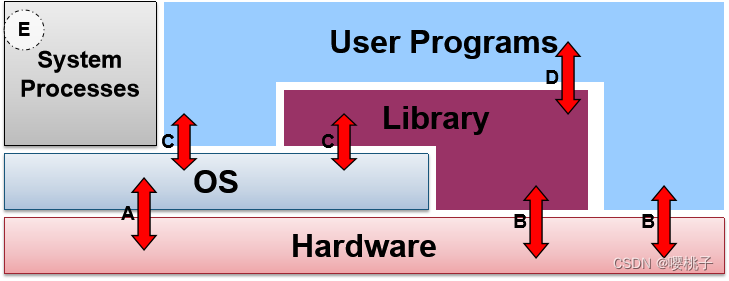
A:OS执行机器指令
B:执行的普通的机器指令(用户程序、库程序)
C:使用系统调用接口来调用OS
D:用户程序调用库程序
E:系统进程:提供了高阶的服务,通常部分是OS
OS是一个程序
- OS也被叫做kernel,其实他就是有一些特殊功能的程序而已,例如:(1)处理硬件事务 (2)提供系统调用接口 (3)中断处理,设备驱动
- kernel程序需要和普通程序有所区别
- kernel代码里没有对系统的调用
- 不使用普通库函数
- 没有通常的I/O
- 考虑这个:普通程序使用OS,那OS用什么呢?
OS的实现
程序语言:
- 原先用的是编译语言/机器指令
- 现在用一些高阶语言
High level language, HLL:C/C++ - 非常依赖硬件架构
常见的代码组织方式:与硬件无关的HHL,依赖硬件的HLL,依赖硬件的编译语言。
挑战:没有其他底层可以给OS依赖(没有包装好的服务),debug很困难,复杂度高,代码复杂
OS的架构方式有:单片Monolithic、微内核Microkernel、分层Layered、客户端服务器Client-Server、外核Exokernel等
我们下面会细致讨论单片Monolithic、微内核Microkernel这两种模式,它们代表了所有的可能性,大多数其他方法是变体或改进。
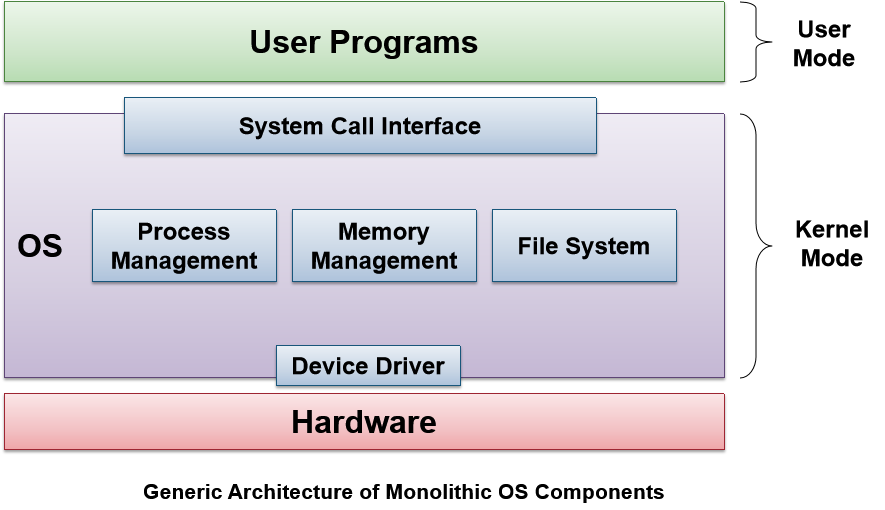
单片OS Monolithic OS
kernel是一个很大的特殊程序,各种服务和组件是不可或缺的一部分。
软件工程原则包括模块化modularization和接口/实现分开seperation of interfaces and implementation。
单片OS是多数Unix变种和Windows NT/XP的实现方式。
- 优点
- 容易理解
- 性能良好
- 缺点
- 各组成部分高度耦合
- 通常会演变成非常复杂的内部结构
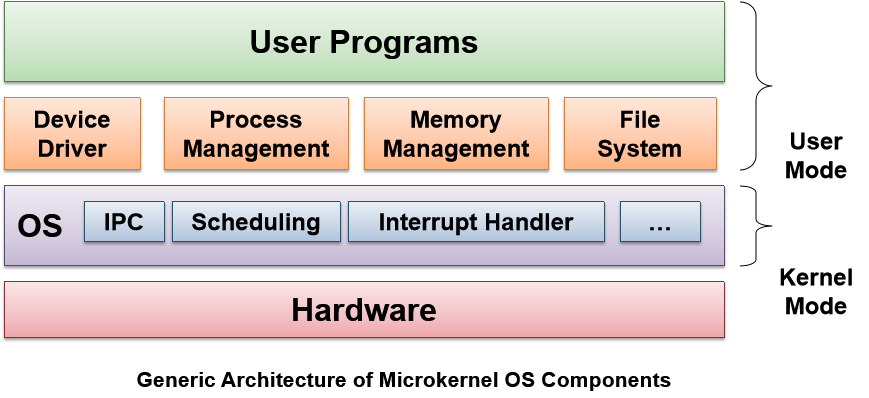
微核OS Microkernel
kernel是非常小且干净的,它只提供基础的、核心的功能,如:
- 进程间通信
Inter-Process Communication, IPC - 地址空间管理
Address space management - 线程管理
Thread Management
高阶的服务:
- 建立在基础功能之上
- 在OS外面作为服务器进程运行
- 使用IPC进行通信。
优点:
- kernel更加稳定、可扩展
- 将kernel和高阶服务独立开来,提高保护性
缺点:
- 低性能
- 分层系统
Layered Systems:- 单体系统的泛化
Generalization of monolithic system - 将组件组织成层的层次结构 :上层调用下层,最低层是硬件,最高层是用户界面
- 单体系统的泛化
- 客户端-服务器模型
Client-Server Model- 微内核模式的变种
- 两类进程:
- 客户端进程从服务器进程请求服务
- 建立在微内核之上的服务器进程
- 客户端和服务器进程可以在不同的机器上
虚拟机 Virtual Machines
操作系统完全控制硬件:如果我们想同时在同一硬件上运行多个操作系统怎么办?
操作系统难以调试/监控:
- 我们如何观察操作系统的工作?
- 我们如何测试具有潜在破坏性的实现?
虚拟机是硬件的软件仿真,将底层硬件虚拟化(将硬件抽象成上层水平:内存、CPU、硬盘等),然后可以在虚拟机之上运行普通(原始)操作系统。
虚拟机也称为管理程序Hypervisor,接下来展示两类hypervisor的实现:
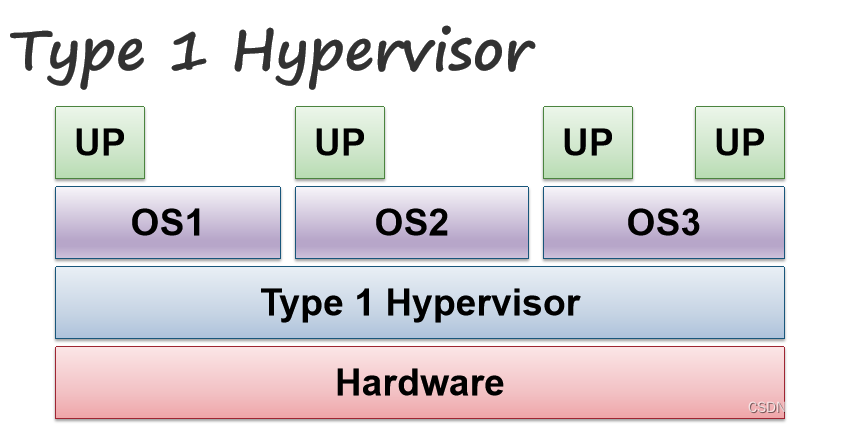
第一类hypervisor:为客户OS提供了独立的虚拟机。例如:IBM VM/37
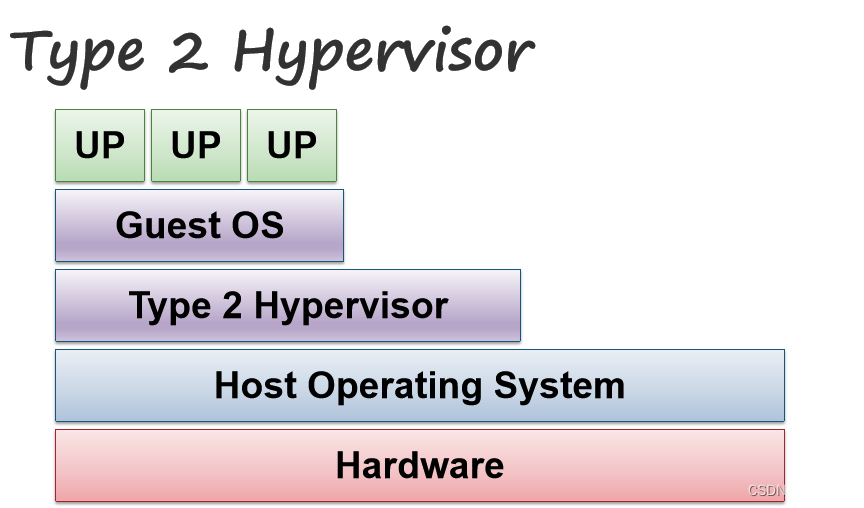
第二类hypervisor:hypervisor在主机OS中运行,客户OS在虚拟机里运行。
2. 进程抽象 Process Abstraction
本章内容:
- 进程管理简介
- 进程抽象:
- 内存context
代码和数据
函数调用
动态分配的内存 - 硬件环境
- 操作系统环境:进程状态
- 进程控制块和进程表
- 内存context
- 操作系统与进程的交互
2.1 进程管理
作为OS,从运行A程序转为运行B程序需要:
- 和A程序执行相关的信息需要存储起来
- 相关信息会被执行B程序所需的信息所替换
因此,我们需要:描述一个在运行中的程序的抽象(也就是进程Process)
主要话题:
- 进程抽象
Process Abstration:描述一个在执行程序的信息 - 进程调度
Process Scheduling:决定要执行哪个进程 - 进程间通信与同步
Inter-Process Communication & Synchronization:在进程之间传递信息 - 进程的替代方案
Alternative to Process:轻量级进程(也就是线程 Thread)
进程抽象:进程/任务/工作 (Process/Task/Job)是一个在执行程序的动态抽象。描述一个在运行程序的信息包括:
- 内存层面:code、data等
- 硬件层面:registers、PC等
- OS层面:process properties、resources used等
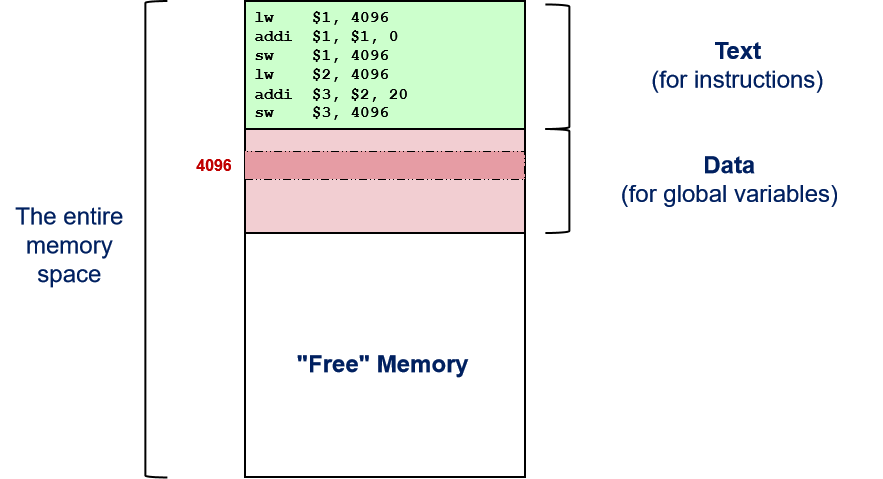
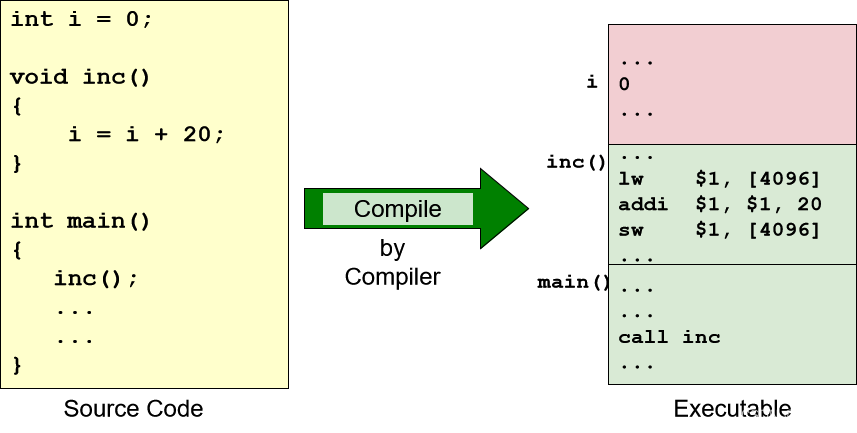
回忆:C程序和编译代码
int i = 0;
i = i + 20;
lw $1, 4096 //Assume address of i = 4096
addi $1, $0, 0 //register $1 = 0
sw $1, 4096 //i = 0
lw $2, 4096 //read iaddi $3, $2, 20 //$3 = $2 + 20
sw $3, 4096 //i = i + 20
回忆:程序执行——内存
回忆: 通用计算机架构
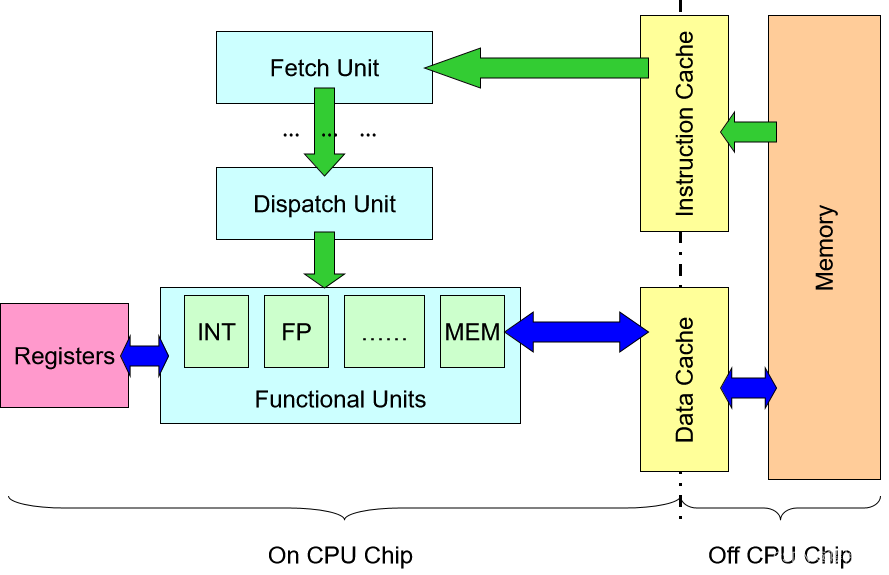
回忆:组件介绍
- 内存
Memory:存储指令和数据 - 缓存
Cache:复制部分内存以加快访问速度,通常分为指令缓存和数据缓存。 - 获取单元
Fetch Unit:将指令从内存载入,特殊寄存器的地址(如程序计数器Program Counter, PC) - 功能单元
Functional Unit:指令执行,不同的指令类型 - 寄存器
registers:为了高速访问的内部存储器,- 通用寄存器
General Purpose Register, GPR:可由用户程序访问(即编译器可见) - 特殊寄存器
Special Register:如程序计数器Program Counter, PC等
- 通用寄存器
回忆:基本指令执行
- 获取指令 X:程序计数器指示的内存位置
- 指令 X 分派到相应的功能单元
- 读取操作数(如果适用)
- 通常来自内存或 GPR
- 计算结果
- 如果适用,写入值:通常写到内存或 GPR
- 指令 X 完成:为下一条指令更新了 PC
回忆:你需要知道的
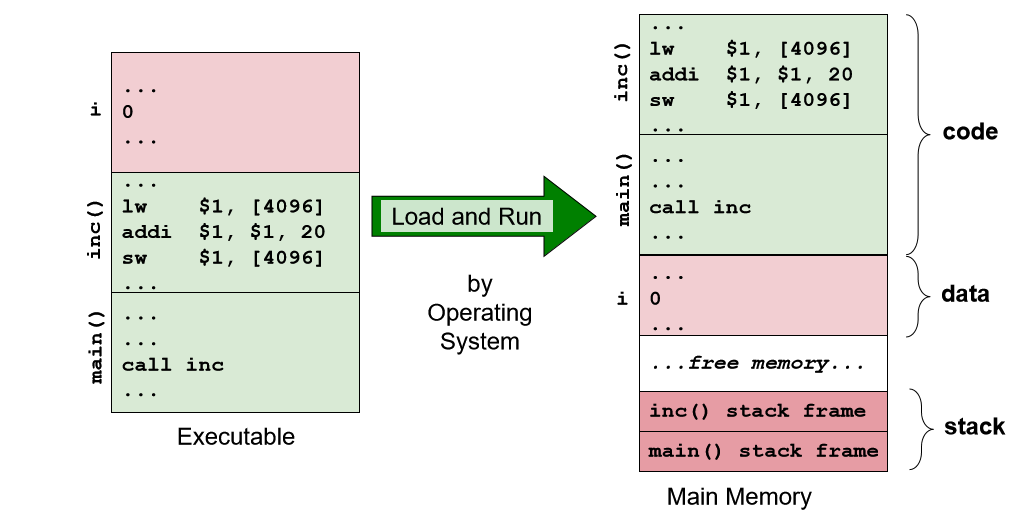
可执行文件(二进制)由两个主要组件组成:指令和数据
当一个程序正在执行时,有更多的信息:
内存层面:文本和数据,
硬件层面:通用寄存器、程序计数器等
实际上,程序执行期间还有其他类型的内存使用。
2.2 内存层面 Memory Context:函数调用 Function Call
2.2.1 函数调用 Function Call
Function Call: Challenges
c程序块:
int i = 0;
i = i + 20;
带函数的c代码:
int g(int i, int j)
{
int a;
a = i + j
return a;
}
考虑:
我们如何为变量 i、j 和 a 分配内存空间?
我们可以只使用“数据”内存空间吗?
有哪些关键问题?
Function Call:控制流和数据 Control Flow and Data
f() 调用 g(),f是调用者caller,g是被调用者callee。
重要步骤:
1. 设置参数
2. 将控制权转移给被调用者
3. 设置局部变量
4. 存储结果(如果适用)
5. 返回给调用者
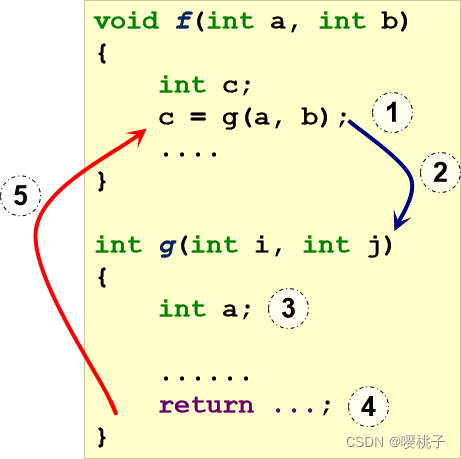
控制流问题:
- 需要跳转到函数体
- 函数调用完成后需要恢复:至少要存储调用者的PC
数据存储问题:
- 需要给函数传参数
- 需要捕获返回结果
- 可能有局部变量声明
⇒ 需要一个新的内存区域,供函数调用动态使用
2.2.2 栈内存 Stack Memory
栈内存区域stack memory region:用于存储信息函数调用的新内存区域
函数调用的信息由栈帧stack frame描述。栈帧包含:
- 调用者的返回地址
- 函数的参数(参数)
- 局部变量的存储
- 其他信息
栈指针 stack pointer:
栈区域的顶部(第一个未使用的位置)在逻辑上由堆栈指针指示:
- 大多数 CPU 都有一个专门用于此目的的寄存器
- 调用函数时在顶部添加栈帧:堆栈“增长”
- 函数调用结束时从顶部移除栈帧:堆栈“收缩”
栈内存 Stack Memory
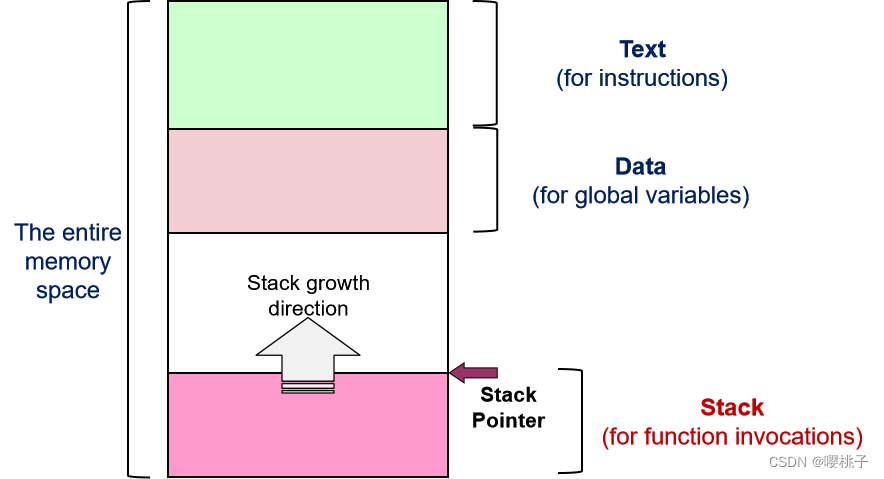
某些系统上的内存布局是翻转的,即栈在顶部,text在底部。
2.2.3 Illustration: Stack Frame v1.0
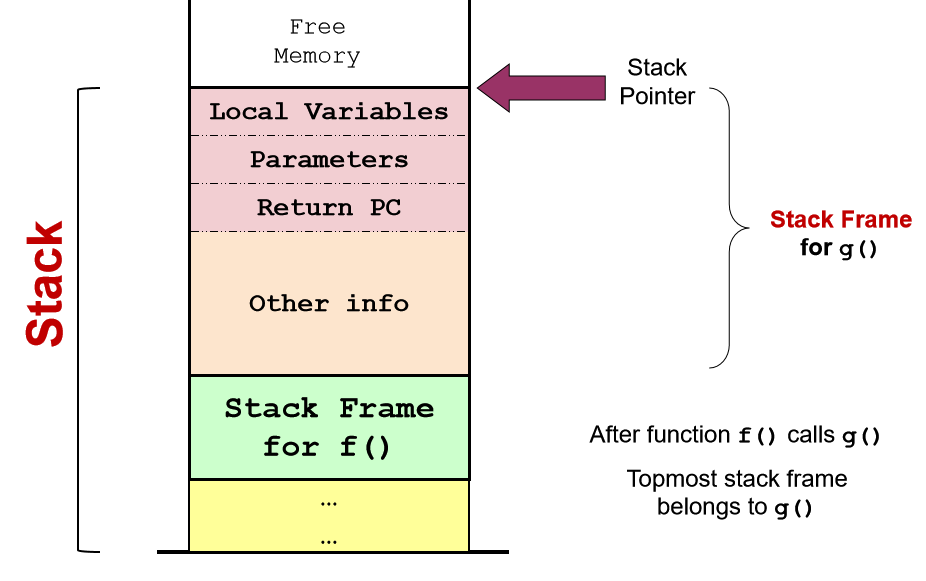
函数调用约定function call convention
设置栈帧的不同方法:称为函数调用约定function call convention
这些方法的主要区别:
- 哪些信息存储在堆栈帧或寄存器中?
- 调用者/被调用者准备了堆栈帧的哪一部分?
- 调用者/被调用者清除了堆栈帧的哪一部分?
- 调用者/被调用者之间谁来调整堆栈指针?
没有万能的方法:取决于硬件和编程语言
接下来描述一个示例方案:
1. 准备进行一个函数调用:

- 调用者:将参数传递给寄存器和/或栈
- 调用者:将返回的程序计数器存储在栈中
- 将控制权从调用者传递给被调用者
- 被调用者:保存旧的栈指针
stack pointer - 被调用者:在栈中为被调用者的局部变量分配空间
- 被调用者:调整栈指针到新的栈顶
2. 调用函数g()

3. 结束函数调用,回到调用者
栈帧分解 stack frame teardown

- 被调用者:在栈中放置要返回的结果(如有)
- 被调用者:恢复保存的栈指针
- 使用保存的程序计数器PC,将控制权还给调用者
- 调用者:使用返回的结果
- 调用者:继续执行接下来的指令
我们已经描述了以下基本思想: - 栈帧
stack frame - 调用约定
calling convention:setup和teardown
让我们看一下堆栈帧中的一些常见附加信息:
- 帧指针
frame pointer - 保存的寄存器
saved registers
帧指针 frame pointer
为了方便各种栈帧项的访问:
- 栈指针很难使用,因为它可以改变
- 一些处理器提供专用寄存器:帧指针
帧指针指向栈帧中的固定位置,其他项目通过相对于帧指针的位移访问
FP 的使用取决于平台。
保存的寄存器 saved register
大多数处理器上的通用寄存器 (GPR) 的数量非常有限:例如, MIPS 有 32 个 GPR,x86 有 16 个 GPR。
当 GPR 用尽时:
- 使用内存临时保存 GPR 值
- 然后可以将该 GPR 重新用于其他目的
- 之后可以恢复 GPR 值
- 这个过程称为寄存器溢出
类似地,函数可以在函数启动之前“溢出”它打算使用的寄存器,在函数结束时恢复那些寄存器。
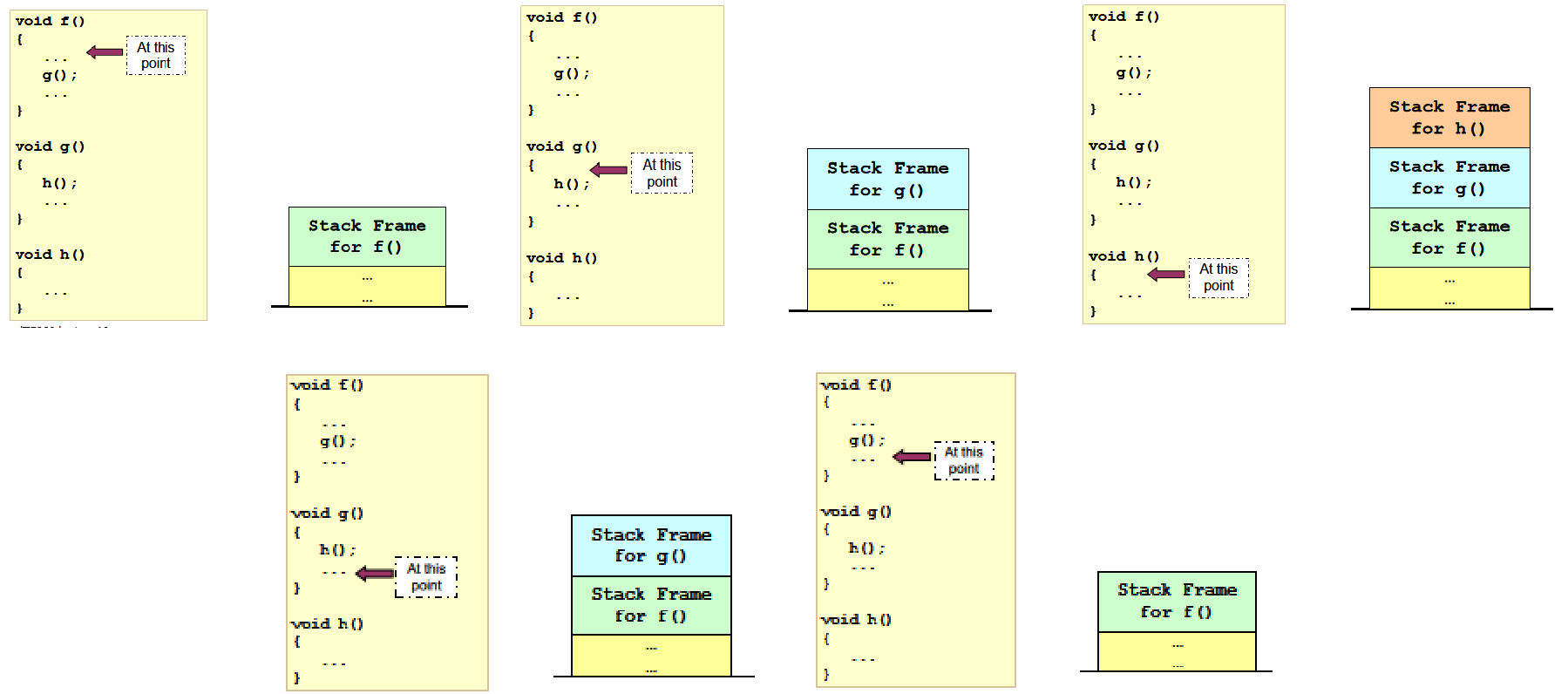
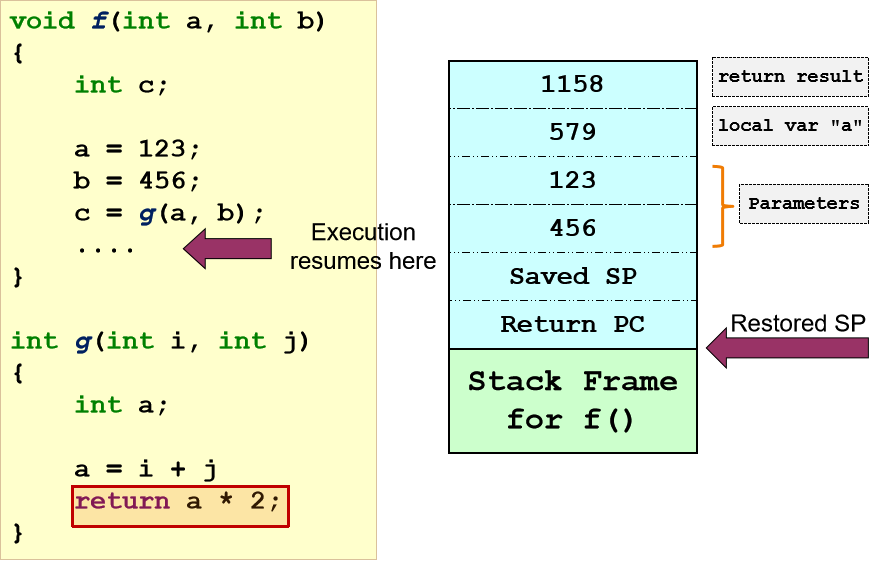
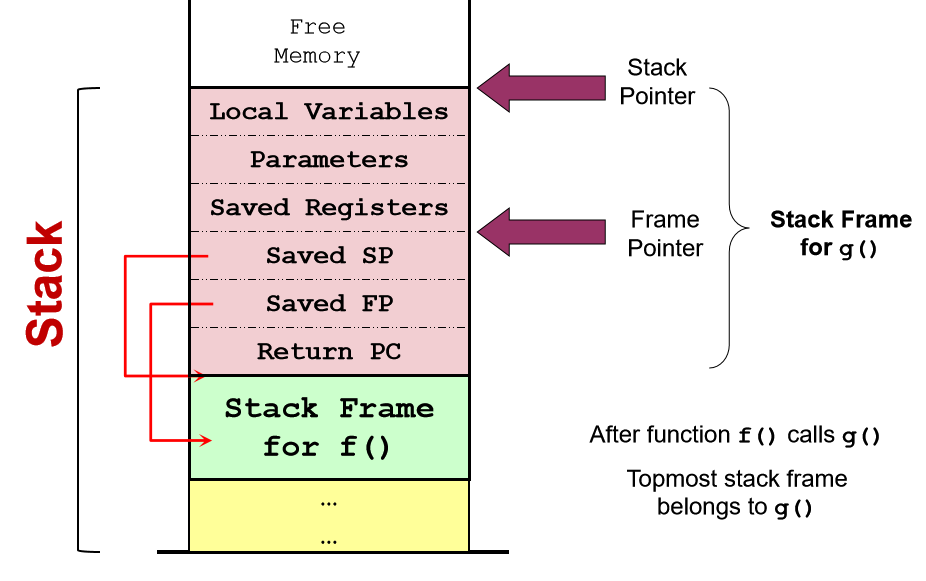
2.2.4 Illustration: Stack Frame v2.0
1. 执行函数调用
- 调用者:将参数传递给寄存器和/或栈
- 调用者:将要返回的PC保存在栈中
- 将控制权从调用者转给被调用者
- 被调用者:保存 被调用者callee 使用的寄存器。保存旧的frame pointer, stack pointer
- 被调用者:为被调用者的局部变量在栈中分配空间
- 被调用者:调整stack pointer,指向最新的栈顶
2. 回到调用者
- 被调用者:重新载入 saved registers, frame pointer, stack pointer
- 将控制权还给调用者
- 调用者:继续执行后续指令
注意,这只是个例子。
函数调用小结
在这一部分中,我们了解到:
- 另一部分内存空间用作栈内存
stack memory - 栈内存使用栈帧
stack frame存储正在执行的函数- 通常存储在栈帧上的信息
- 建立和拆除栈帧的典型方案
- 栈指针
stack pointer和帧指针frame pointer的使用
2.3 内存层面 Memory Context:动态分配内存 Dynamically Allocated Memory
大多数编程语言都允许动态分配内存:
即在执行期间获取内存空间
例子:
在 C 中, malloc() 函数调用
在 C++ 中,new 关键字
在 Java 中,new 关键字
问题:
我们可以使用现有的“数据”或“堆栈”内存区域吗?
观察:
这些内存块有不同的行为:
- 仅在运行时分配,即在编译期间不知道大小 -> 不能放置在数据区域中
- 没有明确的释放时间,例如 可以由 C/C++ 中的程序员来显式释放,可以由 Java 中的垃圾收集器隐式释放 -> 不能放入堆栈区域
解决方案:
设置一个单独的堆内存区域。
堆内存 Heap memory
`
堆内存由于其性质而难以管理:
- 各种不同的尺寸
- 各种不同的分配/释放时间
我们可以构建一个场景:堆内存不断地被分配/释放,从而在内存中创建“洞”,也就是空闲内存块挤在占用内存块之间
Context:
描述进程的信息:
- 内存context:文本、数据、堆栈和堆
- 硬件context:通用寄存器、程序计数器、堆栈指针、堆栈帧指针等。
2.4 OS context:进程ID和进程状态 ProcessID & Process State
区分进程常用的方法是使用进程 ID (PID),这是一个唯一的数字。
有几个取决于操作系统的问题:
- PID 是否被重复使用?
- 它是否限制最大数量。 进程?
- 是否有保留的 PID?
多进程场景中:一个进程可以是:运行或不运行(例如:另一个进程正在运行)
一个进程可以准备好运行,但实际上并没有执行。例如, 等待轮到它使用 CPU。
因此,每个进程都应该有一个进程状态:作为执行状态的指示。
-
简单的进程状态模型
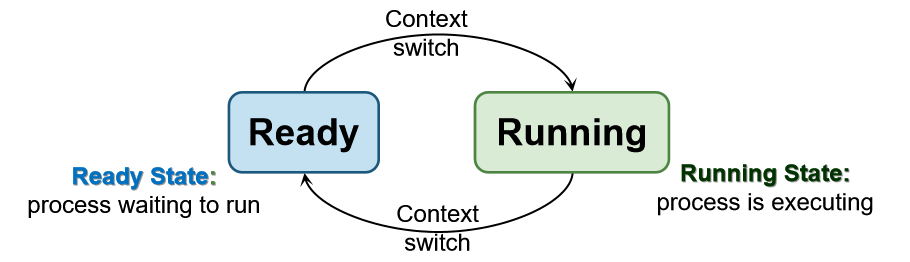
状态和转换的集合称为进程模型process model,描述进程的行为。 -
通用的五状态进程模型
注:通用进程状态,具体在实际操作系统中有所不同。
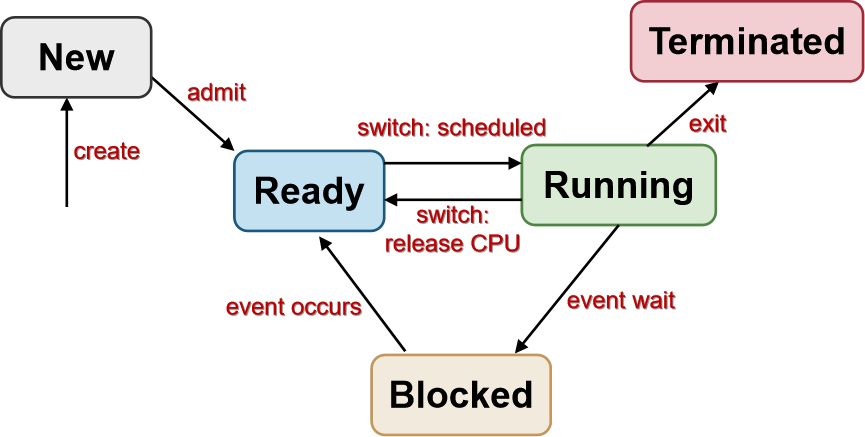
进程状态: -
new:新进程创建。可能仍在初始化中,尚未准备好。
-
ready:进程正在等待运行
-
running:CPU上正在执行的进程
-
blocked:进程因为事件等待(休眠)。在事件可用之前无法执行。
-
terminated:进程已完成执行,可能需要操作系统清理。
状态转换:
- Create (nil → New): 新进程已创建
- Admit (New → Ready):准备运行的进程
- Switch (Ready → Running): 选择运行的进程
- Switch (Running → Ready): 进程主动放弃CPU或被调度器抢占
- Event wait (Running → Blocked): 处理不可用/正在进行的请求事件/资源/服务(例如系统调用,等待 I/O)
- Event occurs (Blocked → Ready): 事件发生 ⇒ 进程可以继续
给定 n 个进程:
使用 1 个 CPU:<= 1 个进程处于运行状态。概念上,一次只有 1 个状态转换transition。
使用 m 个 CPU:<= m个 进程处于运行状态,可能并行转换。
不同的进程可能处于不同的状态,每个进程可能位于其状态图的不同部分。
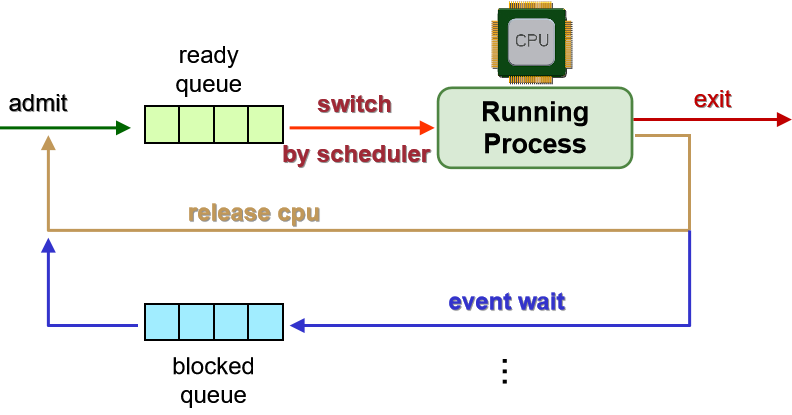
Note:
- 超过 1 个进程可以处于就绪 + 阻塞队列
- 可能有单独的事件队列
- 排队模型提供进程的全局视图,即操作系统怎么观测它们。
Context Updated:
当一个程序正在执行时,有更多的信息:
- Memory Context:文本和数据、栈和堆
- Hardware context:通用寄存器、程序计数器、栈指针、栈帧指针等
- OS context:进程 ID、进程状态等
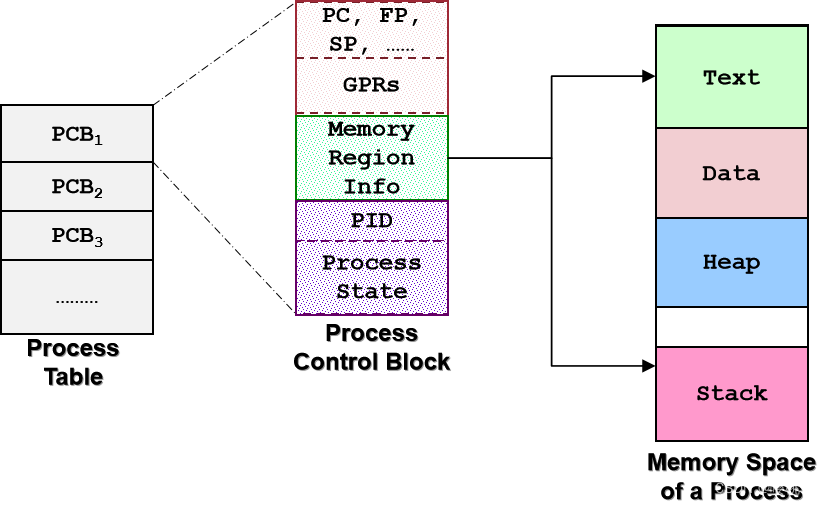
2.5 进程表和进程控制块 Process Table & Process Control Block
进程的整个执行context,传统上称为过程控制块 (Process Control Block, PCB) 或进程表条目(Process Table Entry)。
Kernel 为所有进程维护 PCB,存储为一个代表所有进程的表。
有趣的问题:
- 可扩展性:你可以有多少个并发进程?
- 效率:应提供有效的访问和最小的空间浪费
进程表
2.6 进程和OS之间交互:系统调用 System Calls
到操作系统的应用程序接口 (API) 提供在 kernel 中调用设施/服务的方式,与普通函数调用不同,系统调用必须从用户模式user mode更改为内核模式kernel mode。
不同的操作系统有不同的 API:
- Unix 变体:
- 大多数遵循 POSIX 标准
- 少量调用:~100
- Windows系列:
- 跨不同 Windows 版本使用 Win API
- 新版本的 windows 通常会增加更多的调用
- 大量调用:~1000
Unix 在C/C++中的系统调用:
- 在 C/C++ 程序中,几乎可以直接调用System calls,大多数系统调用具有相同名称和相同参数的库版本
library version(库版本充当函数包装器function wrapper)。 - 除此之外,一些库函数为程序员提供了一个更加用户友好的版本(例如,更少的参数,更灵活的参数值等)。
库版本也能作为功能适配器function adapter

在这个例子里触发的系统调用有:
- getpid()
- write(): 通过printf()这个库函数调用引发。
通常的系统调用机制
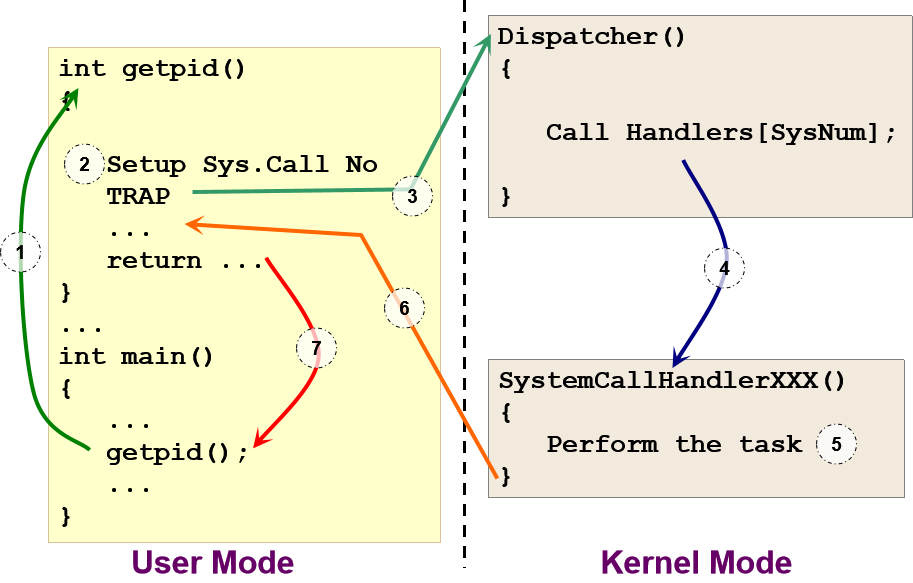
- 用户程序调用库函数:使用普通函数调用机制。
- 库函数(通常在汇编代码中)将系统调用号
system call number放在指定位置。例如: register。 - 库函数执行特殊指令,从用户模式切换到内核模式,该指令通常称为
TRAP。 - 在内核模式下,确定一个合适的系统调用处理程序
appropriate system call handler:使用系统调用号作为索引。这一步通常由调度员dispatcher处理。 - 系统调用处理程序
system call handler被执行:执行实际请求 - 系统调用处理程序结束:控制权返回到库函数,从内核模式切换到用户模式
- 库函数返回用户程序:通过普通的函数返回机制
2.7 进程和OS之间交互:Exception and Interrupt
Exception
- 执行机器级指令可能会导致异常。例如:算术错误 / 上溢、下溢、除以零 / 内存访问错误 / 非法内存地址,未对齐的
unaligned内存访问等。 - Exception是同步的
synchronous,由于程序执行而发生 - Exception的影响:必须执行异常处理程序
exception handler;类似于强制调用函数forced function call。
Interrupt
外部事件可以中断程序的执行。通常与硬件相关,例如:定时器、鼠标移动、键盘按下等;
中断是异步的asynchronous,独立于程序执行而发生的事件
中断效果:程序执行暂停;必须执行中断处理程序interrupt handler。
Exception / Interrupt Handler

- 发生异常/中断:控制权自动转移到处理程序例程
handler routine - 从处理程序例程
handler routine返回:恢复程序执行状态;可能表现得好像什么都没发生。
Summary
使用进程作为运行程序的抽象:
- 程序执行所需的信息(环境)
- 内存、硬件和操作系统环境
从操作系统角度看进程:
- PCB及进程表
操作系统 <= => 进程交互
- 系统调用
- 异常/中断
3. 进程调度 Process Scheduling
本章内容:
- 并发执行
- 进程调度
- 定义
- 进程行为
- 进程环境
- 良好调度的标准
- 进程调度程序
- 调度算法
- 用于批处理系统
- 对于交互式系统
3.1 并发执行 concurrent execution
并发进程:涵盖多任务流程的逻辑概念
- 可能是虚拟并行:平行错觉(psedoparallelism)
- 也可能是物理并行。例如, 多 CPU / 多核 CPU,允许并行执行多个进程
我们可以假设在以下讨论中没有区分这两种形式的并行性。
简化的并发示例
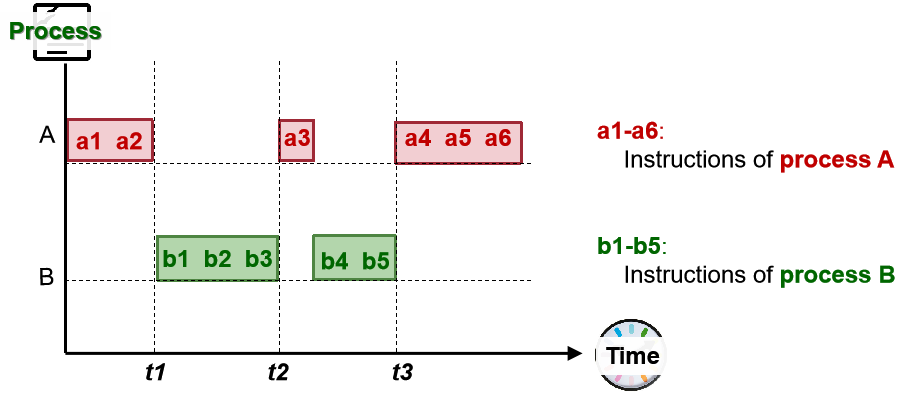
在 1 个 CPU 上并发执行:交错执行来自两个进程的指令,也称为时间片timeslicing。
3.2 交错执行 Interleaved Execution:context switch
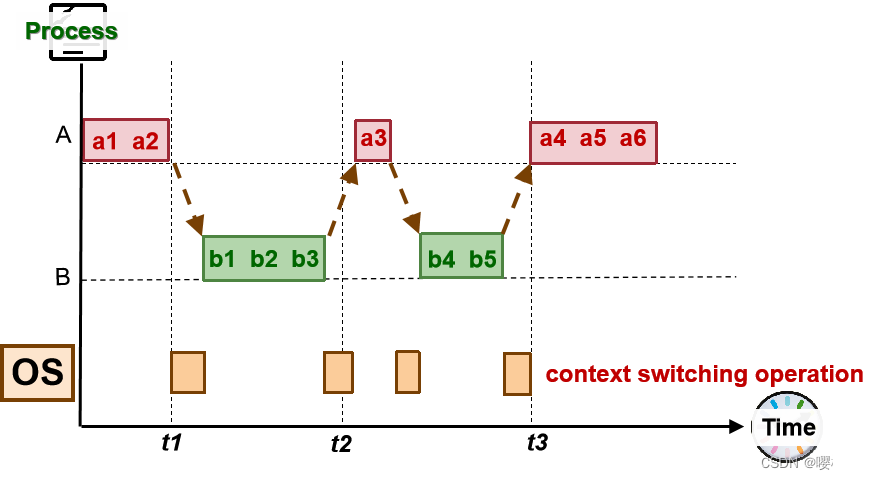
多任务处理需要改变 A 和 B 之间的context:操作系统在切换进程中有一定开销。
多任务OS
- 1 CPU:分时执行任务

- 多处理器:在 n 个 CPU 上进行时间切片
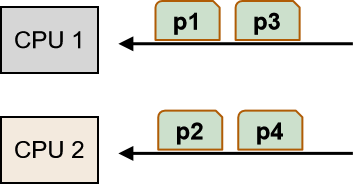
3.3 调度 Scheduling
多个进程的问题:如果ready-to-run进程多于可用CPU,应该选择哪个来运行?(线程级调度中的类似思想)。这也称为调度问题。
术语:
调度器 Scheduler:做出调度决策的操作系统的一部分
调度算法Scheduling algorithm:调度器使用的算法

每个进程对CPU时间的要求不同:Process Behavior
多种分配方式:受进程环境process environment影响;称为调度算法scheduling algorithm。
评估调度程序的一些标准 criteria to evaluate the scheduler
进程行为 Process Behavior
一个典型的进程会经历以下阶段:
- CPU活动:计算(如数字运算)。计算型任务
Compute-Bound Process大多数时间花在这一步。 - IO活动:从IO设备中请求、获取服务(如在屏幕上打印,从文件中读取数据)。IO型任务
IO-Bound Process大多数时间花在这一步。
处理环境 Processing Environment
三类:
- 批量处理:无用户,无需交互,无需响应。
- 交互式(或多道程序):活跃用户与系统交互,应该响应迅速,响应时间一致。
- 实时处理:有最后期限,通常是周期性的过程。
调度算法的评判标准 Criteria for Scheduling Algorithm
评估调度算法的许多标准:
- 受处理环境影响较大
- 可能有冲突
所有处理环境的标准:
- 公平
Fairness:- 应该获得公平的 CPU 时间份额
- 基于每个进程 或 基于每个用户
- 也意味着没有进程“饿死”
starvation
- 应该获得公平的 CPU 时间份额
- 平衡
Balance:- 应利用计算系统的所有部分
什么时候执行调度?
两种调度策略(由何时触发调度定义)
- 非抢占式(合作)
Non-preemptive (Cooperative):进程保持调度(处于运行状态)直到它自愿阻塞或放弃 CPU - 抢先
Preemptive:一个进程被给到一个固定的时间配额来运行,可能会提前阻止或放弃;时间配额结束时,正在运行的进程暂停,(如有另一个进程)将选择另一个进程继续执行。
调度步骤
- 调度器被触发 (OS获得控制权)
- 如果需要进行context交换,当前进程的context会被保存,用阻塞队列/准备队列中的任务的context来代替。
- 根据调度算法,选择一个合适的进程P来执行
- 准备P的context
- 运行进程P
3.4 批处理调度 Scheduling Fro Batch Processing
关于批处理系统:没有用户交互,非抢占式调度占主导地位。
调度算法通常更容易理解和实现,通常使得这种算法可用于其他类型系统的变体/改进。
涵盖了三种算法:
- 先到先得 (First-Come First Served, FCFS)
- 最短作业优先 (Shortest Job First, SJF)
- 下一个最短剩余时间 (Shortest Remaining Time Next, SRT)
批处理的评判标准:
- 周转时间
Turnaround time:总时间,即完成-到达时间。与等待时间相关(等待CPU的时间)。 - 吞吐量
Throughput:单位时间内完成的任务数,即任务完成率。 - CPU利用率
CPU utilization:CPU 处理任务的时间百分比。
(1)先到先得 First-Come-First-Served
想法:
- 任务根据到达时间存储在先进先出 (FIFO) 队列中
- 选择队列中的第一个任务运行,直到任务完成或任务被阻止
- 阻塞的任务从 FIFO 队列中移除。当它再次准备好时,把他放在队列的后面,即就像一个新到的任务。
保证不饿死 Starvation:
FIFO中任务X前面的任务数一直在递减 ⇒ 任务 X 最终会得到它的机会
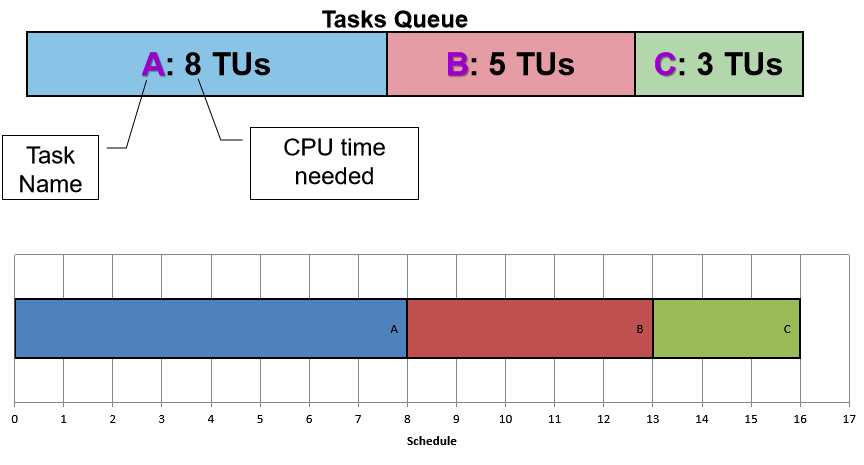
3个任务的平均总等待时间 = (0 + 8 + 13)/3 = 7 个时间单位
缺点:
- 简单的重新排列就可以减少平均等待时间!
- 另外,考虑这种情况:
第一个任务(任务 A)是 CPU 密集型任务,然后是一些 IO 密集型任务 X
任务 A 运行:所有任务 X 在就绪队列中等待(I/O 设备空闲)
任务 A 在 I/O 上阻塞:所有任务 X 快速执行并在 I/O 上阻塞(CPU 空闲)
称为车队效应Convoy Effect
(2)短任务优先 Shortest-Job-First SJF
思想:选择需要最少CPU事件的任务先运行。
Notes:
需要提前知道任务的总 CPU 时间,如果不知道它的执行时间,则必须“猜测”。
给定一组固定的任务:减少平均等待时间
饥饿是可能发生的:因为偏向于短期任务,长期任务可能永远没有获得CPU的机会
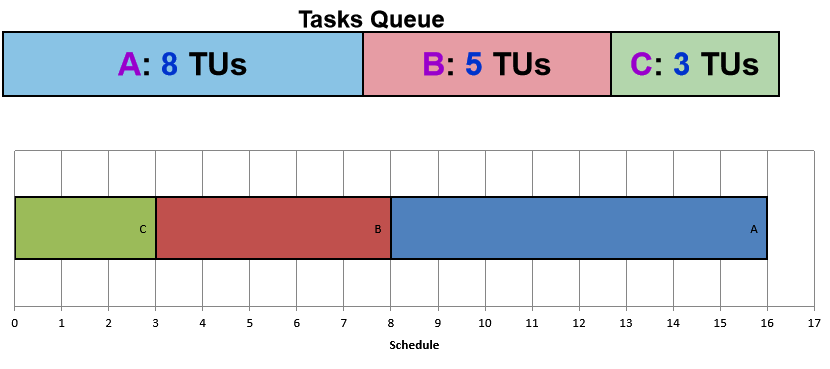
3个任务的平均总等待时间 = (0 + 3 + 8)/3 = 3.66 时间单位
可以证明 SJF 保证最小的平均等待时间。
一个任务通常会经历几个 CPU-Activity 阶段:可以通过之前的 CPU-Bound 阶段猜测未来的 CPU 时间需求
常用方法(指数平均):
P
r
e
d
i
c
t
e
d
n
+
1
=
α
∗
A
c
t
u
a
l
n
+
(
1
−
α
)
∗
P
r
e
d
i
c
t
e
d
n
Predicted_{n+1}= α *Actual_n+(1-α) * Predicted_n
Predictedn+1=α∗Actualn+(1−α)∗Predictedn
Actual_n = 最近一次消耗的 CPU 时间
Predicted_n = 过去的 CPU 时间消耗历史
α = 对最近事件或过去历史的权重
Predicted_{n+1} = 最新预测
(3)最短剩余时间 Shortest Remaining Time SRT
思想:
SJF的变体:使用剩余时间作为选择依据,抢先策略。
选择剩余(或预期)时间最短的工作
Notes:
- 剩余时间较短的新作业可以抢占当前正在运行的作业
- 为短期工作(即使是晚到达的)提供良好的服务
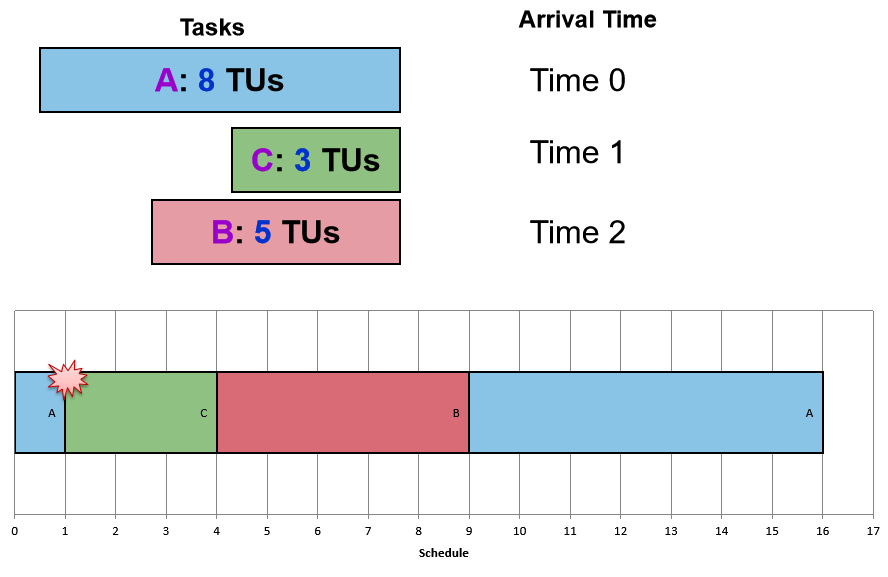
3.5 交互式系统的调度 Scheduling For Interactive System
交互式环境的评判标准
响应时间response time:系统请求和响应之间的时间
可预测性predictability:响应时间的变化,较小的变化 == 更可预测
抢占式调度算法用于确保良好的响应时间 ⇒ 调度器需要周期性地运行
确保周期性调度
问题:
- 调度程序如何定期“接管”CPU?
- 我们如何确保用户程序永远不会阻止调度程序的执行?
答案:
定时器中断 = 周期性中断(基于硬件时钟 clock)
Timer interrupt = Interrupt that goes off periodically (based on hardware clock)
操作系统确保定时器中断timer interrupt不能被任何其他程序拦截 ⇒ 定时器中断处理程序 调用 调度程序 Timer interrupt handler invokes scheduler.
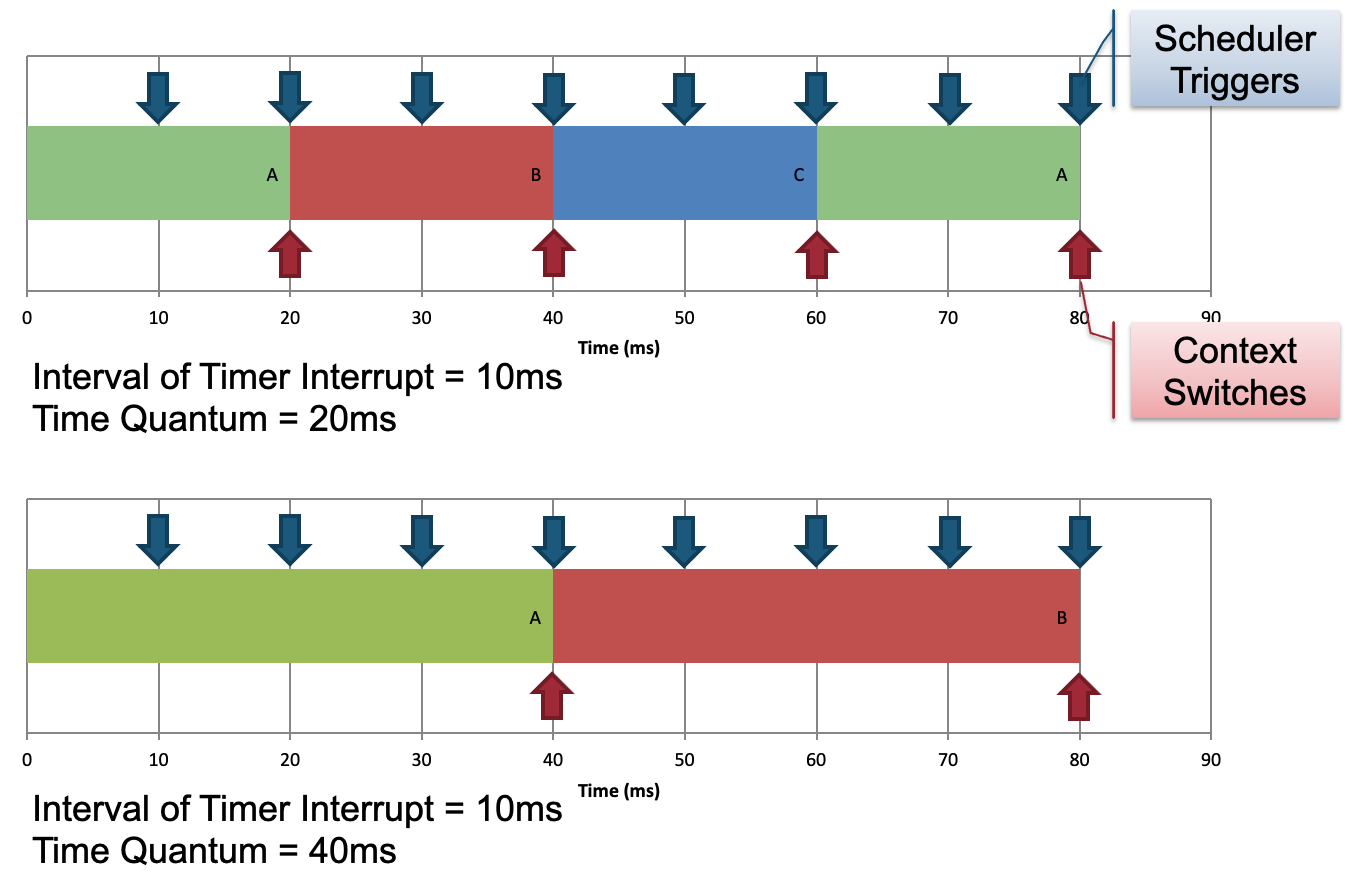
Timer & Time Quantum
定时器中断间隔 (Interval of Timer Interrupt, ITI):
- 每次定时器中断都会触发 OS 调度程序
- 通常的值在1ms 至 10ms之间
时间限额 Time Quantum:
- 给进程的执行时间配额
- 在进程之间可以是常量或变量
- 必须是定时器中断间隔的倍数
- 值范围大:通常为 5 毫秒到 100 毫秒
调度算法
涵盖的算法:
循环赛 Round Robin (RR)
基于优先级Priority Based
多级反馈队列Multi-Level Feedback Queue (MLFQ)
彩票调度Lottery Scheduling
(1)循环赛 Round Robin (RR)
思想:
- 任务存储在 FIFO 队列中
- 从队列前面选择第一个任务运行,直到:
- 经过了固定的时间片(time slice / quantum)
- 任务主动放弃CPU
- 任务阻塞
- 然后将任务放置在队列的末尾以等待另一轮
- 阻塞的任务将被移动到其他队列以等待其请求
- 当阻塞的任务再次就绪时,它被放在队列的末尾
Notes:
- 基本上是 FCFS 的抢占式版
- 响应时间保证:
- 给定 n 个任务和时间配额quantum q
- 任务获得 CPU 之前的等待时间的上界是 (n-1)q
- 需要定时器中断,让调度程序检查时间配额是否到期
- 时间配额持续时间的选择很重要:
- Big Quantum:更好的 CPU 利用率但更长的等待时间
- Small Quantum:更大的开销(更差的 CPU 利用率)但更短的等待时间
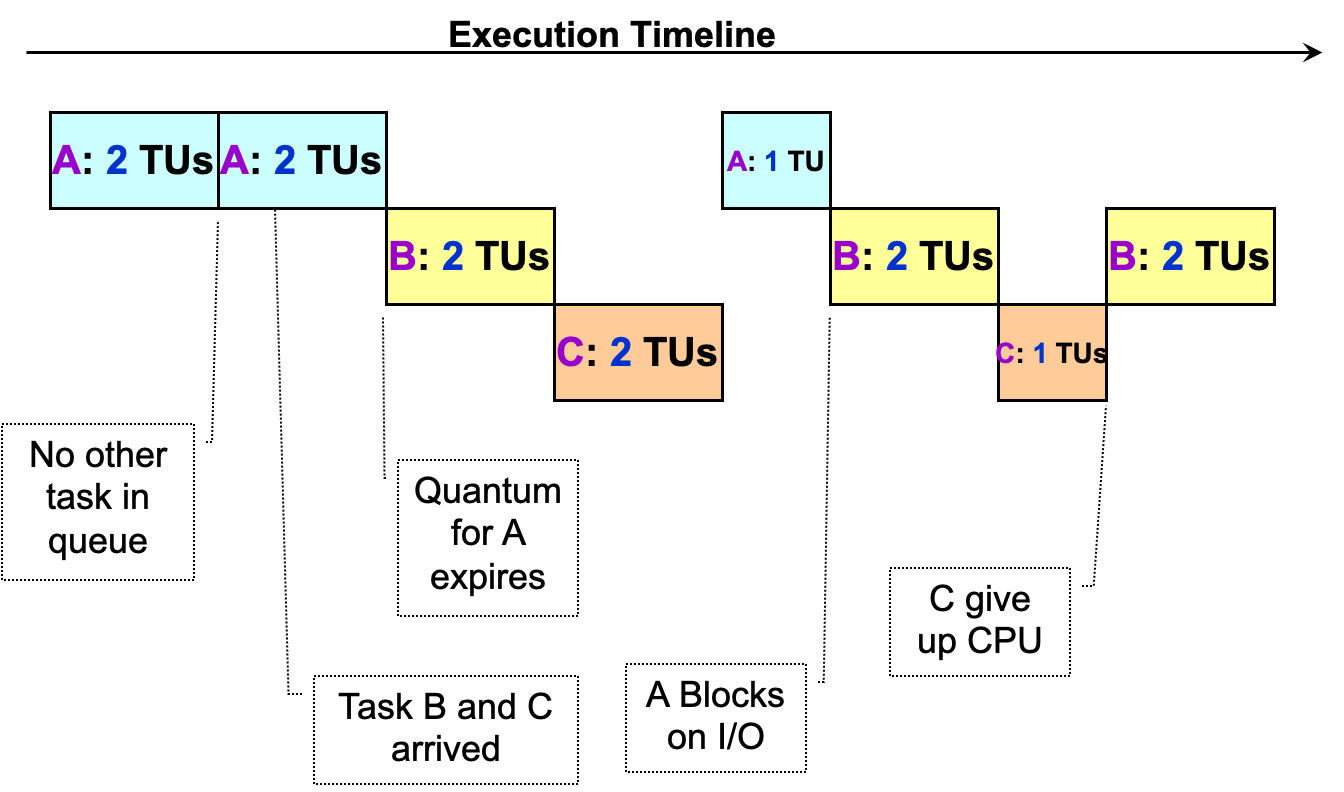
(2)优先调度 Priority Scheduling
思想:
- 有些进程比其他进程重要,不能平等对待所有进程
- 为所有任务分配优先级值
- 选择具有最高优先级值的任务
变体:
- 抢占式版本:优先级高的进程可以抢占正在运行的优先级低的进程
- 非抢占式版本:迟来的高优先级进程必须等待下一轮调度
缺点:
低优先级进程可能饿死:高优先级进程不断占用CPU,这是一种更糟糕的抢占式变体。
可能的解决方案:
- 在每个时间片后降低当前运行进程的优先级,最终低于第二高的优先级。
- 给当前运行的进程一个时间片,下一轮调度不考虑这个进程。
通常,很难保证或控制 分配给使用优先级的进程的 CPU 时间的确切数量
优先级反转Priority Inversion
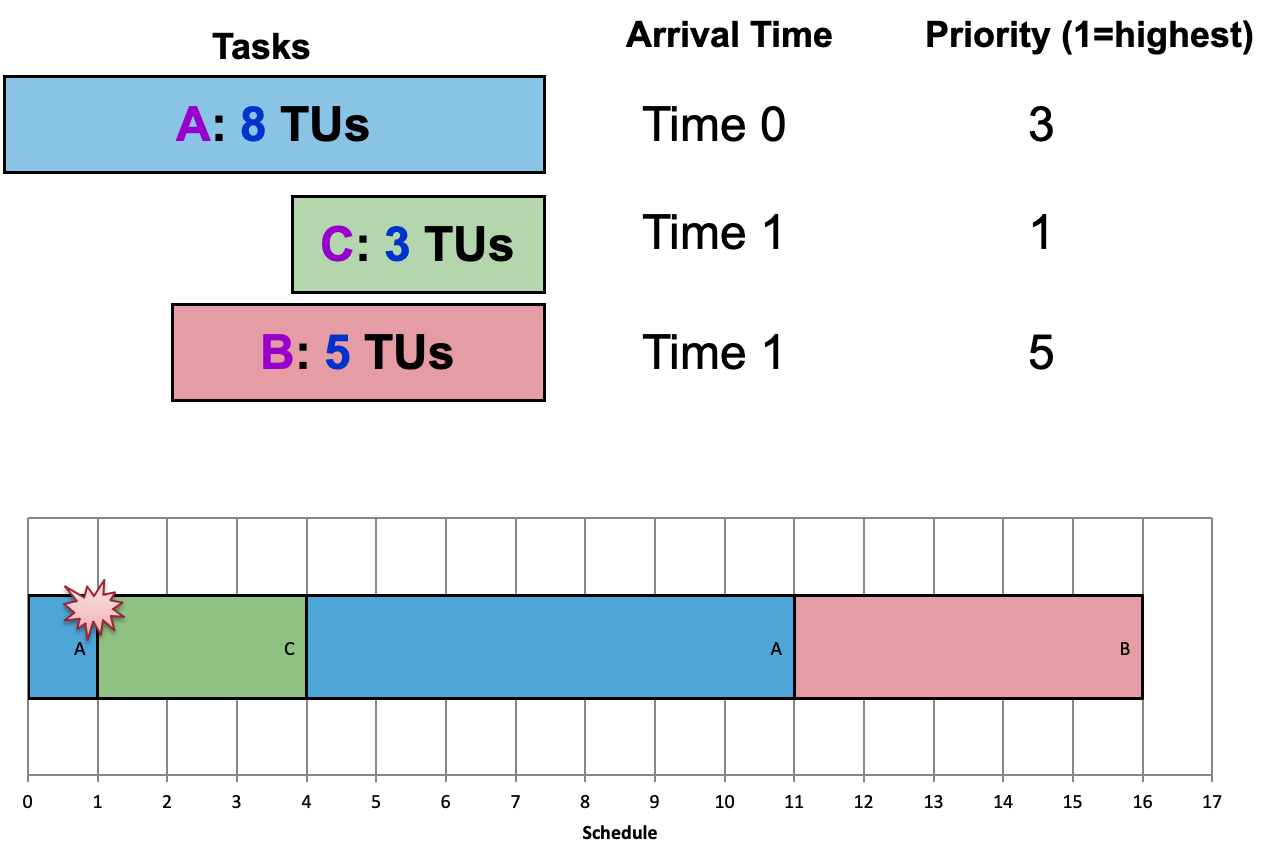
考虑以下场景:
优先级:{A = 1, B=3, C= 5}(1 最高)
任务 C 启动并锁定资源(例如文件)
⇒ 任务 B 抢占 C
⇒ C 无法解锁文件
⇒ 任务 A 到达并需要与 C 相同的资源,但是资源被锁定了!(即使任务 A 具有更高的优先级,任务 B 也会继续执行)
这种情况称为优先级反转:低优先级任务抢占高优先级任务
(3)多级反馈队列 Multi-Level Feedback Queue (MLFQ)
旨在解决一个 BIG + HARD 问题:
- 我们如何在没有完美知识的情况下安排时间?
- 大多数算法都需要某些信息(进程行为
process behavior、运行时间running time等)
MLFQ 是:自适应:“自动学习进程行为” Adaptive: Learn the process behavior automatically
最小化 【IO 密集型进程的响应时间response time for IO-bound processes】和【CPU 密集型进程的周转时间turnaround time for CPU-bound processes】
规则
基本规则:
如果优先级(A) > 优先级(B) ⇒ A 运行
如果 Priority(A) == Priority(B) ⇒ A 和 B 在 RR 中运行
优先级设置/更改规则:
- 新任务 ⇒ 最高优先级
- 如果作业用尽其时间片 ⇒ 优先级降低
- 如果作业在用尽时间片之前放弃/阻塞 ⇒ 保留优先级
例子1
3 个队列:Q2(最高优先级)、Q1、Q0
一个长时间运行的作业

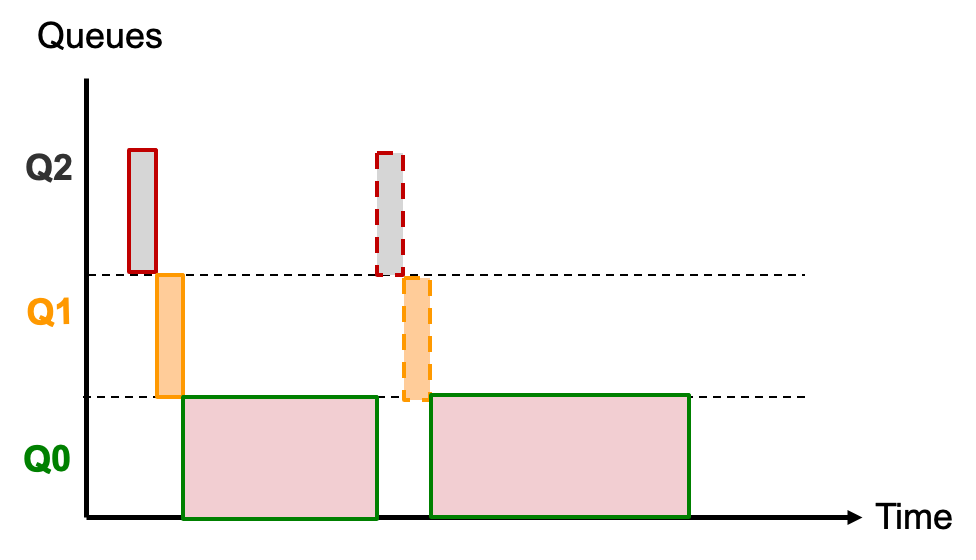
例子2: 例子1的基础上 + 中间有时候会出现短任务
例子3
两种任务:
A = CPU密集型(已经在系统中存在一段时间)
B = I/O密集型
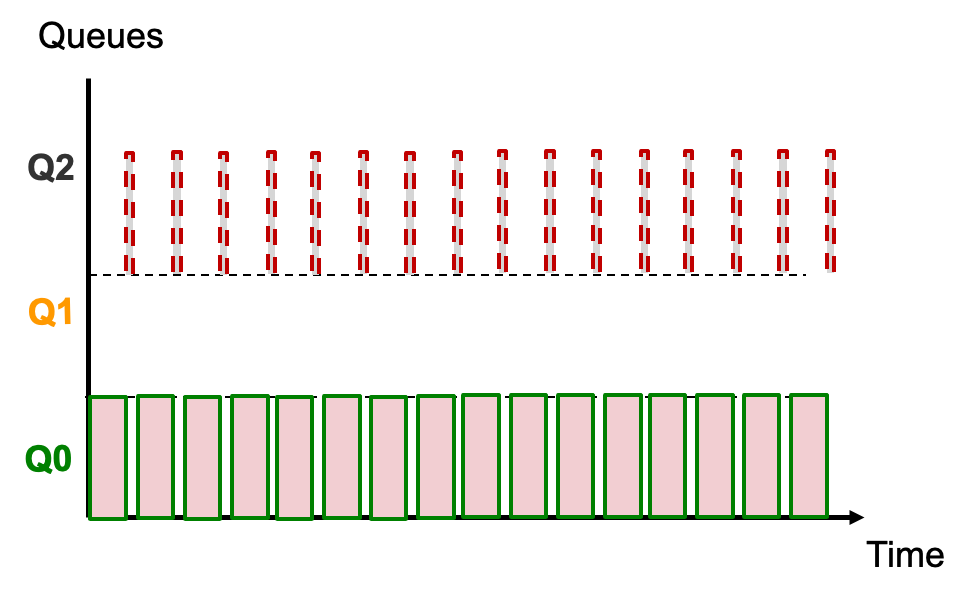
你能想出一种滥用算法的情况吗? ⇒ 等效问题:MLFQ 不适用于什么样的工作组合?
有什么方法可以纠正以上问题?
(4)彩票调度 Lottery Scheduling
进程发放各种系统资源的“彩票”。例如, CPU 时间、I/O 设备等。
当需要调度决策时,在符合条件的彩票中随机抽取一张彩票,获胜者被授予资源。
从长远来看,一个进程持有 X% 的票,就可以赢得所持彩票的X%,即使用资源 X% 的时间
性质
1. 响应式responsive: 一个新创建的进程可以参与下一次抽奖
2. 提供良好的控制水平provides good level of control:
- 可以给一个进程 Y 数量的彩票,然后它可以分发给它的子进程。
- 一个重要的过程可以给更多的彩票,可以控制使用比例。
- 每个资源都可以有自己的一组票,每个任务每个资源的不同使用比例。
3. 实现简单
Summary
操作系统中的调度:
基本定义
影响调度的因素
工艺、环境
良好调度的标准
调度算法:
批处理系统——FCFS、SJF、SRT
交互式系统—— RR、优先级、多级队列、MLFQ 和彩票调度
4. 线程 Threads
本章内容:
线程:动机、基本理念
线程模型:内核与用户线程Kernel vs User Thread、混合模型 Hybrid Model
Unix 中的线程:POSIX 线程:创建、退出、同步、勘探
4.1 Motivation for Thread
进程的开销很大:
- fork() 模型下的进程创建:
- 重复的内存空间
- 复制大部分进程context等
- context切换:需要保存/恢复进程信息
独立进程之间很难相互通信:
他们各自有独立的内存空间 ⇒ 没有简单的方法传递信息 ⇒ 需要进程间通信 (IPC)
发明线程是为了克服进程模型的问题 ,最初是一种“快速破解 quick hack”,最终成熟为非常流行的机制
基本思想:
- 传统进程有一个控制线程
thread of control:任何时候整个程序只有一条指令在执行 - 我们“简单地”向同一个进程添加更多的控制线程:程序的多个部分在概念上同时执行
4.2 线程 Thread of Control
假设我们正在准备午餐,其中包括以下任务:蒸饭 \ 炸鱼 \ 煮汤
一个伪 C 程序:
int main()
{
steamRice( twoBowls );
fryFish( bigFish );
cookSoup( cornSoup );
printf( "Lunch READY!!\n“ );
return 0;
}
单线程的进程会按顺序执行这三项任务。
假设任务之间是相互独立的,尝试使用多线程。
使用fork()创建多线程

使用Thread…do多线程
(下面这个是伪代码,这三个线程是并发的)

Process and Thread
- 一个进程可以有多个线程 :称为多线程进程
- 同一进程中的线程共享以下资源 :
- 内存context:文本、数据、堆
- 操作系统context:进程 ID、文件等其他资源
- 每个线程所需的唯一信息 :
- 标识(通常是线程 ID)
- 寄存器(通用和特殊)
- “堆栈”(稍后会详细介绍)
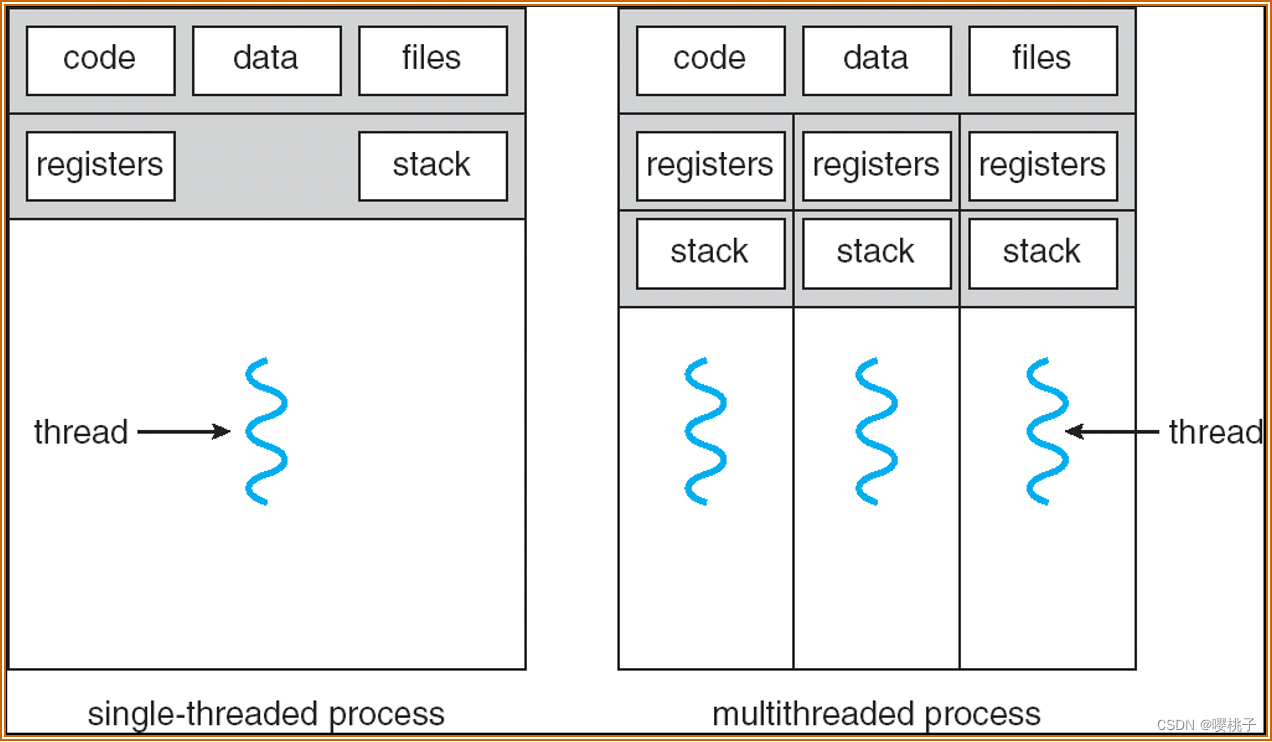
进程context交换 vs 线程交换
- 进程context切换涉及:操作系统context、硬件context、内存context
- 同一进程内的线程切换涉及:硬件context(寄存器、stack【实际上只是改变 FP 和 SP 寄存器】)
线程比进程“轻”得多:又名轻量级进程 lightweight process
线程优点
- 经济
economy:与多个进程相比,同一进程中的多个线程需要更少的资源来管理。 - 资源共享
resource sharing:线程共享进程的大部分资源,不需要额外的机制来传递信息。 - 响应及时
responsiveness:多线程程序的响应速度可能会更快 - 可扩展性
scalability:多线程程序可以利用多个 CPU
线程的问题
系统调用并发 Sysytem call concurrency:
多线程并行执行 ⇒ 可能并行进行系统调用(必须保证正确性并确定正确的行为)
进程行为 Process behavior:
对进程操作的影响
例子:
- fork() 复制了一份进程,线程呢?
- 如果单个线程执行exit(),那么整个进程呢?
- 如果单个线程调用 exec(),那么其他线程呢?
4.3 线程模型 Thread Models
用户线程 User Thread:
- 线程作为用户库
user library实现,运行时系统(在进程中)将处理与线程相关的操作 - 内核感受不到进程中的线程
内核线程 kernel thread:
- 线程在操作系统中实现,线程操作作为系统调用被处理
thread operation is handled as system calls - 线程级调度是可以做到的:内核按线程调度,而不是按进程
- 内核可以使用线程来执行它自己
用户线程 User Thread
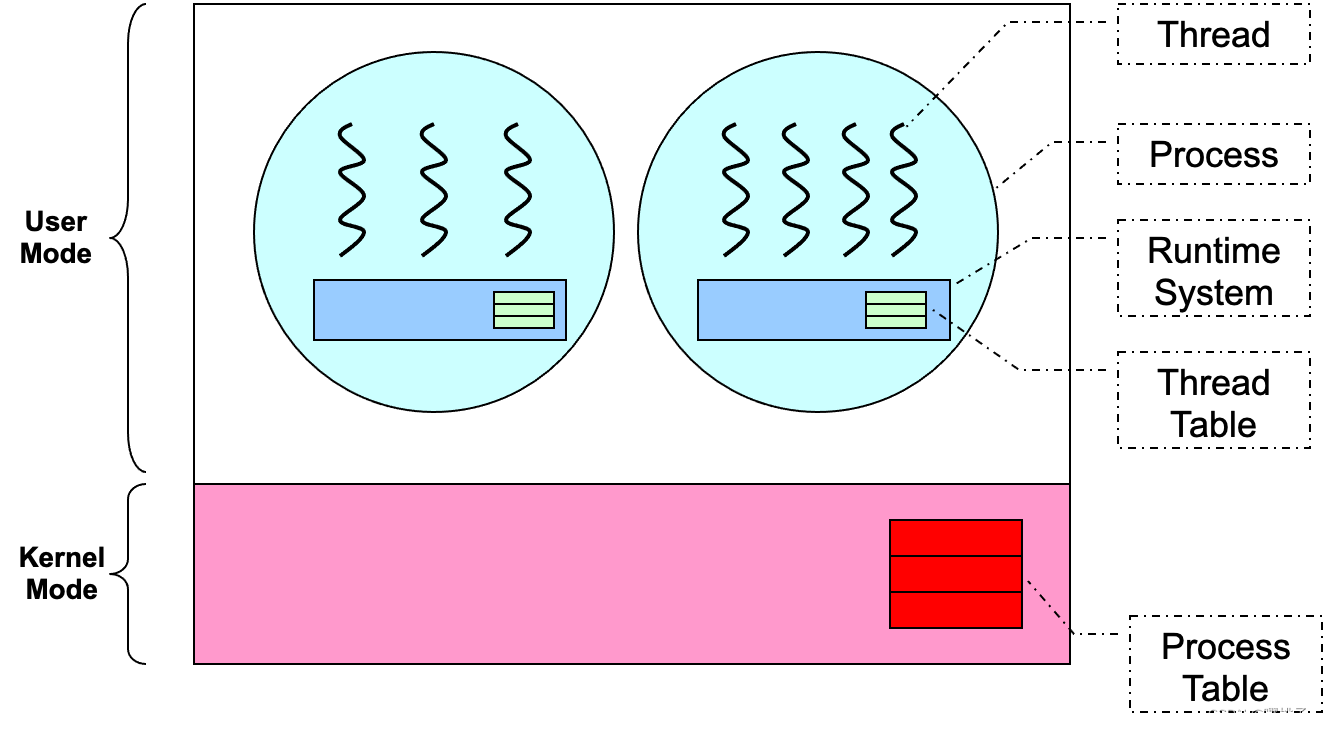
优点:
- 可以在任何操作系统上拥有多线程程序
- 线程操作只是库调用
library calls - 通常更具可配置性和灵活性
configurable and flexible。例如,可以自定义线程调度策略。
缺点:
- 操作系统不知道线程,调度是在进程级别 执行的
- 一个线程阻塞 ⇒ 进程阻塞 ⇒ 所有线程阻塞
- 无法利用多个 CPU
内核线程 Kernel Thread
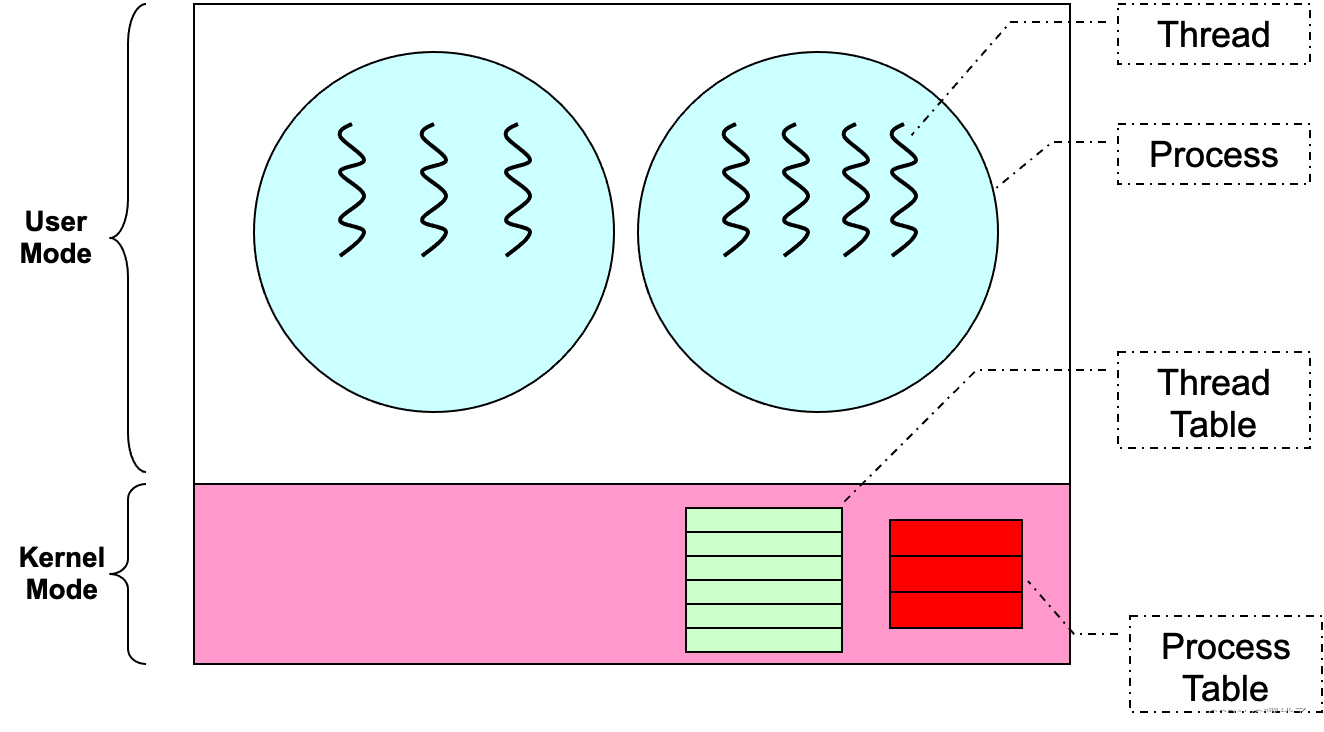
优点:
- 内核可以在线程级别上进行调度:
- 同一进程中的 1 个以上线程可以在多个 CPU 上同时运行
缺点:
- 线程操作现在是一个系统调用 ⇒ 速度较慢且更加资源密集
- 通常不太灵活:因为由所有多线程程序使用。如果实现了许多功能:开销很大,简单的程序可能会被复杂化。如果实现的功能很少:对于某些程序不够灵活。
混合线程模型 Hybrid Thread Model
同时拥有内核和用户线程:仅内核线程上的OS调度;用户线程可以绑定到内核线程。
提供极大的灵活性:可以限制任何进程/用户的并发
Solaris混合线程模型
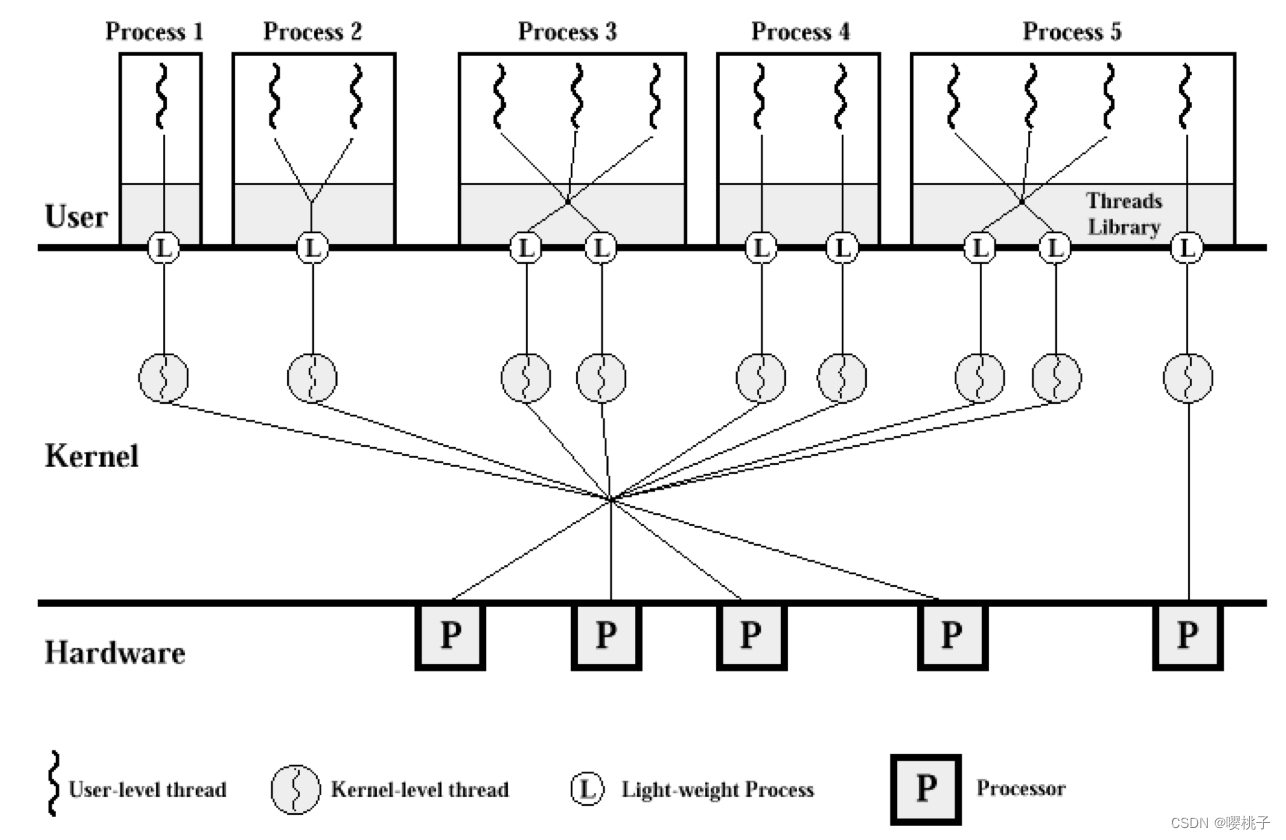
线程最初是一种软件机制。User space library ⇒ OS aware mechanism
现代处理器有硬件支持: 本质上提供多组寄存器(GPR 和特殊寄存器)以允许线程在同一内核上 本地并行运行,称为同时多线程(simultaneous multi-threading, SMT)。
例子:英特尔处理器上的超线程 hyperthreading
5. 进程间通信 Inter-Process Communication
本章内容:
- Motivation
- Common communication mechanisms
- Shared memory
- Message passing
- Pipe (Unix specific)
- Signal (Unix specific)
协作进程很难共享信息,因为内存空间是独立的,所以需要进程间通信机制(IPC)。
两种常见的IPC机制:共享内存Shared-memory和消息传递message passing
两种特定于 Unix 的 IPC 机制:管道pipe和信号signal
5.1 共享内存 Shared-Memory
思想:
- 进程 P1 创建一个共享内存区域 M
- 进程 P2 将内存区域 M 附加到它自己的内存空间
- P1 和 P2 现在可以使用内存区域 M 进行通信
- M 的表现与普通内存区域非常相似
- 但所有其他方都可以看到对该区域的任何写入
同一模型适用于共享同一内存区域的多个进程。
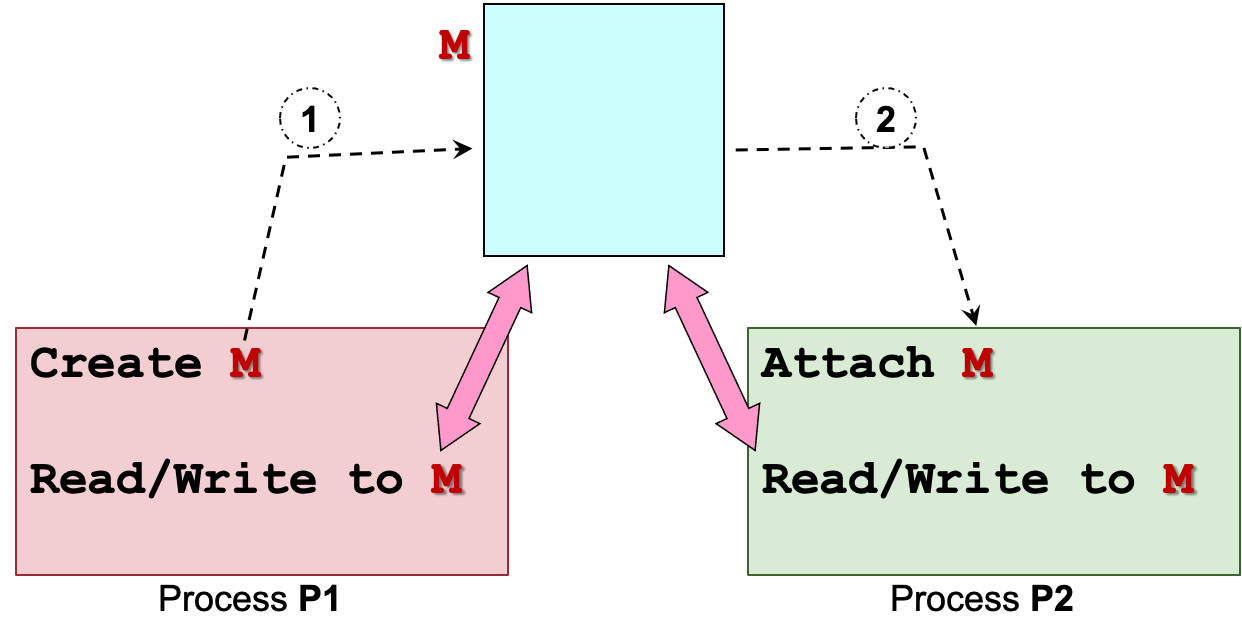
OS只参与步骤1和2。
优点:
- 高效:OS只参与初始化的步骤(也就是创建和绑定共享内存区域
create and attach shared memory region) - 使用方便:共享内存区域的行为与普通内存空间相同,即任何类型或大小的信息都可以轻松写入
缺点:
- 同步
Synchronization:共享资源 ⇒ 需要同步访问 - 实施通常更难
POSIX Shared Memory in *nix
基本使用步骤:
- 创建/定位共享内存区域 M
- 将 M 添加到进程内存空间
- 读取/写入 M:写入的值对所有共享 M 的进程可见
- 使用后从内存空间中解除绑定 M
- 销毁M:只有一个进程需要这样做,仅当 M 未附加到任何进程时才能销毁
Master Program


Slave Program

5.2 信息传递 Message Passing
思想:
进程 P1 准备消息 M 并将其发送给进程 P2
⇒ 进程 P2 收到消息 M
⇒ 消息发送和接收通常作为系统调用
附加属性:
命名naming:如何识别通讯中的对方
同步synchronization:发送/接收操作的行为
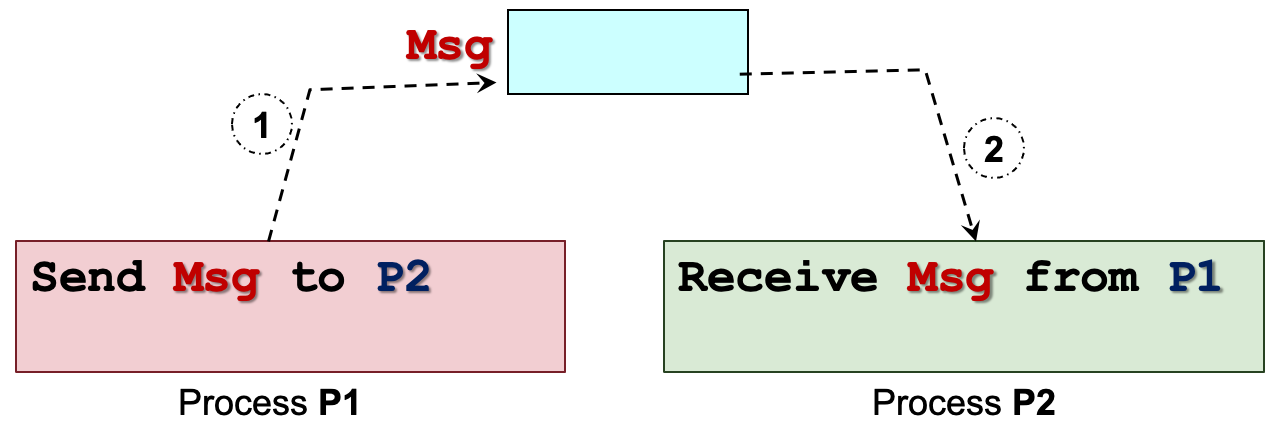
Msg 必须存储在内核内存空间中。
每个发送/接收操作都需要通过操作系统(即系统调用)。
命名机制:直接通信 Naming Scheme: Direct Communication
消息的发送者/接收者需要明确表明对方是谁
例子:
Send(P2, Msg):向进程P2发送消息Msg
Receive(P1, Msg):从进程P1接收消息Msg
特征:
- 每对通信进程一个链接
- 需要知道对方的身份
命名机制:间接通信 Naming Scheme: Indirect Communication
消息被发送到消息存储/从消息存储接收sent to / received from message storage:通常称为邮箱或端口 mailbox or port
例子:
Send(MB,Msg):发送消息Msg到邮箱MB
Receive(MB, Msg) : 从邮箱 MB 接收消息 Msg
特征:
一个邮箱可以在多个进程之间共享
两种同步行为 Two Synchronization Behaviors
阻塞原语(同步) Blocking Primitives (Synchronous):
Send():发送者被阻塞,直到收到消息
Receive():接收者被阻塞,直到消息到达
非阻塞原语(异步)Non-Blocking Primitives (asynchronous):
Send():发送方立即恢复操作
Receiver():如果有消息,接受者接收消息;如果没有,接受者接收【消息还未准备好】的指示信息。
优缺点
优点:
可移植portable:可以很容易地在不同的处理环境中实现,例如 分布式系统、广域网等
更容易同步Easier synchronization:例如,当使用同步原语时,发送者和接收者是隐式同步的
缺点:
低效Inefficient:通常需要操作系统干预
更难使用harder to use:消息的大小和/或格式通常受到限制
5.3 Unix Pipes
在Unix里,一个进程有三个默认的通信通道。
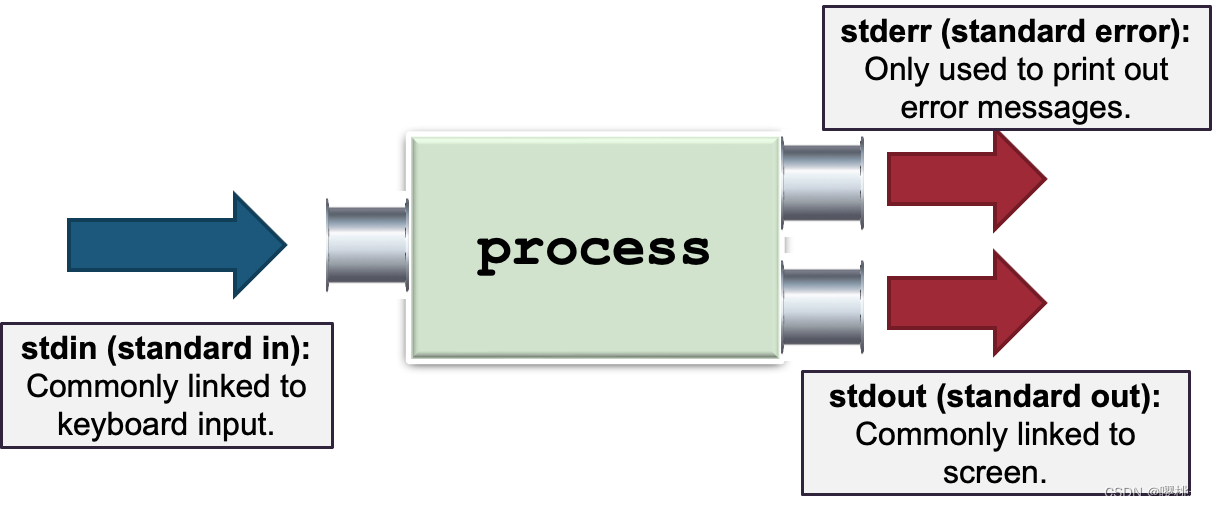
例子:
在典型的 C 程序中,printf() 使用标准输出,scanf() 使用标准输入。
Piping in Shell
Unix shell 提供了“|” 将一个进程的输入/输出通道链接到另一个进程的符号,这称为管道piping
例如(“A | B”):
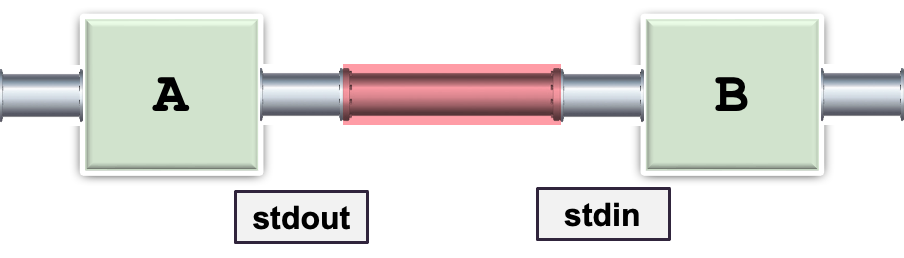
A 的输出(而不是进入屏幕)直接进入 B 作为输入(就好像它来自键盘一样)
Unix Pipes
最早的IPC机制之一
思想:
一个通信通道由 2 个端点创建:一个读端,一个写端。就像现实世界中的水管。
在shell里的piping “|” 在内部就是使用这种机制实现的:

Unix Pipes:as an IPC Mechanism
管道可以在两个进程之间共享,是生产者-消费者关系的一种形式
- P 产生(写入)n 个字节
- Q 消耗(读取)m 个字节
像一个匿名文件。
FIFO ⇒ 必须按顺序访问数据。
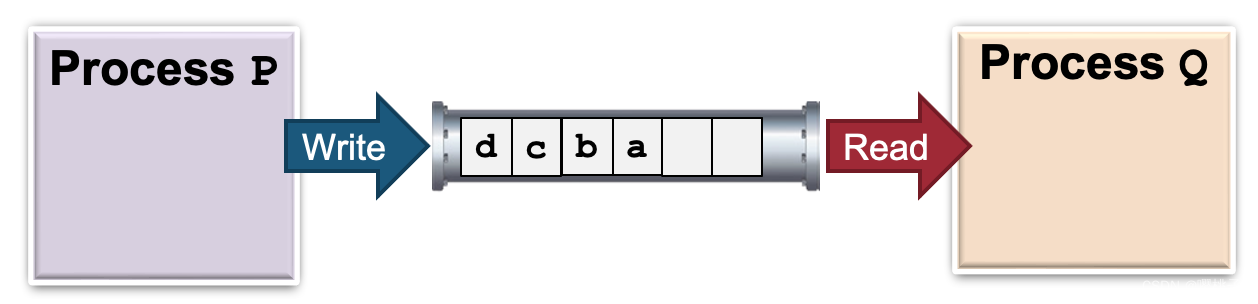
Unix Pipes: Semantic
管道作为具有隐式同步的循环有界字节缓冲区circular bounded byte buffer with implicit synchronization:
- 当缓冲区已满时 写入程序等待
- 缓冲区为空时 读者等待
变体:
- 可以有多个读者/作者:普通 shell 管道有 1 个写入器和 1 个读取器
- 取决于 Unix 版本,管道可能是半双工的或全双工
- 半双工
half-duplex:单向unidirectional:有一个写端和一个读端 - 全双工
full-duplex:双向bidirectional:读/写的任何一端
- 半双工
Unix Pipe:System Calls

返回内容:
0表示成功; !0 表示错误
返回一个 文件描述符 数组:
fd[0] == 读取结束
fd[1] == 写结束

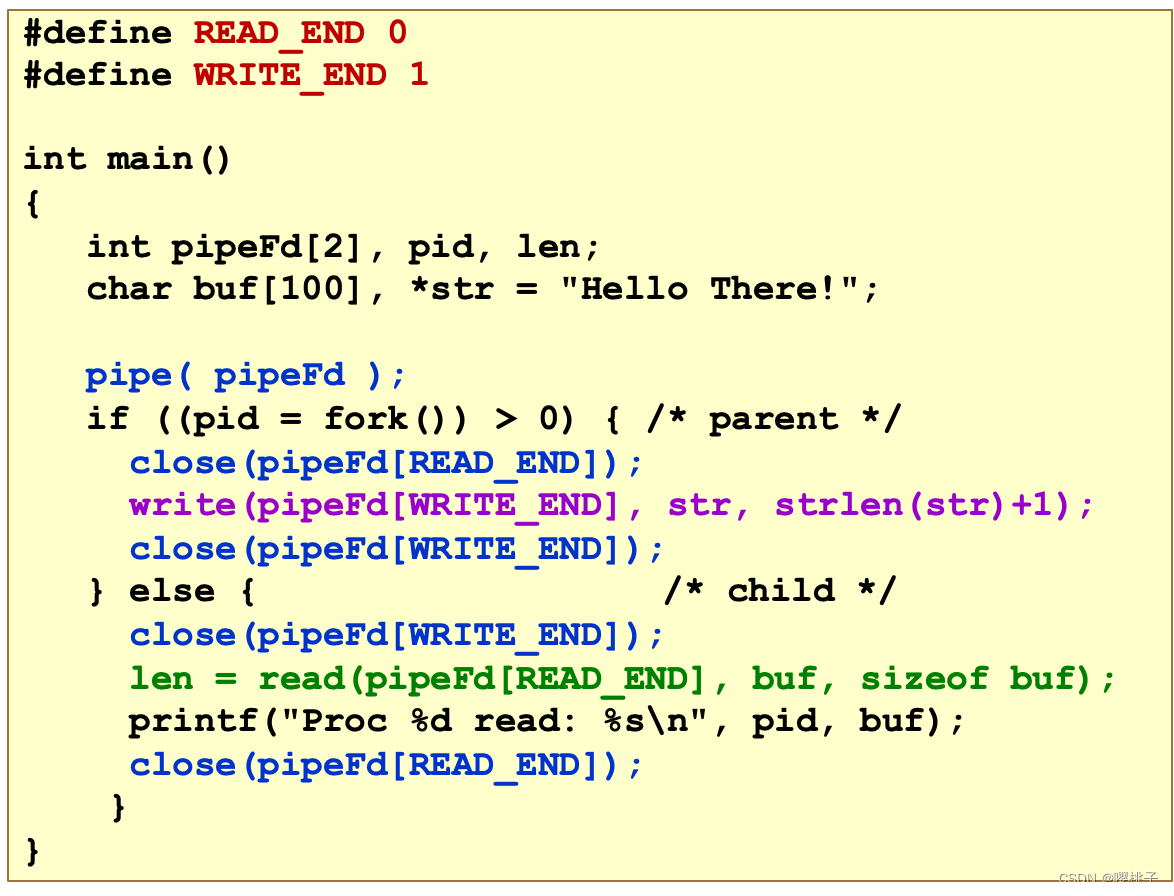
示例代码
我们在读写的时候,需要关闭另外一边。如果执行读操作,要关闭写入口;如果执行写操作,要关闭读入口,否则就会丢失End of File标志。
我们可以将标准通信通道(stdin、stdout、stderr)附加/更改 attach/change到其中一个管道,也就是将输入/输出从一个程序重定向到另一个程序。
Unix system calls需要考虑:dup()、dup2()。
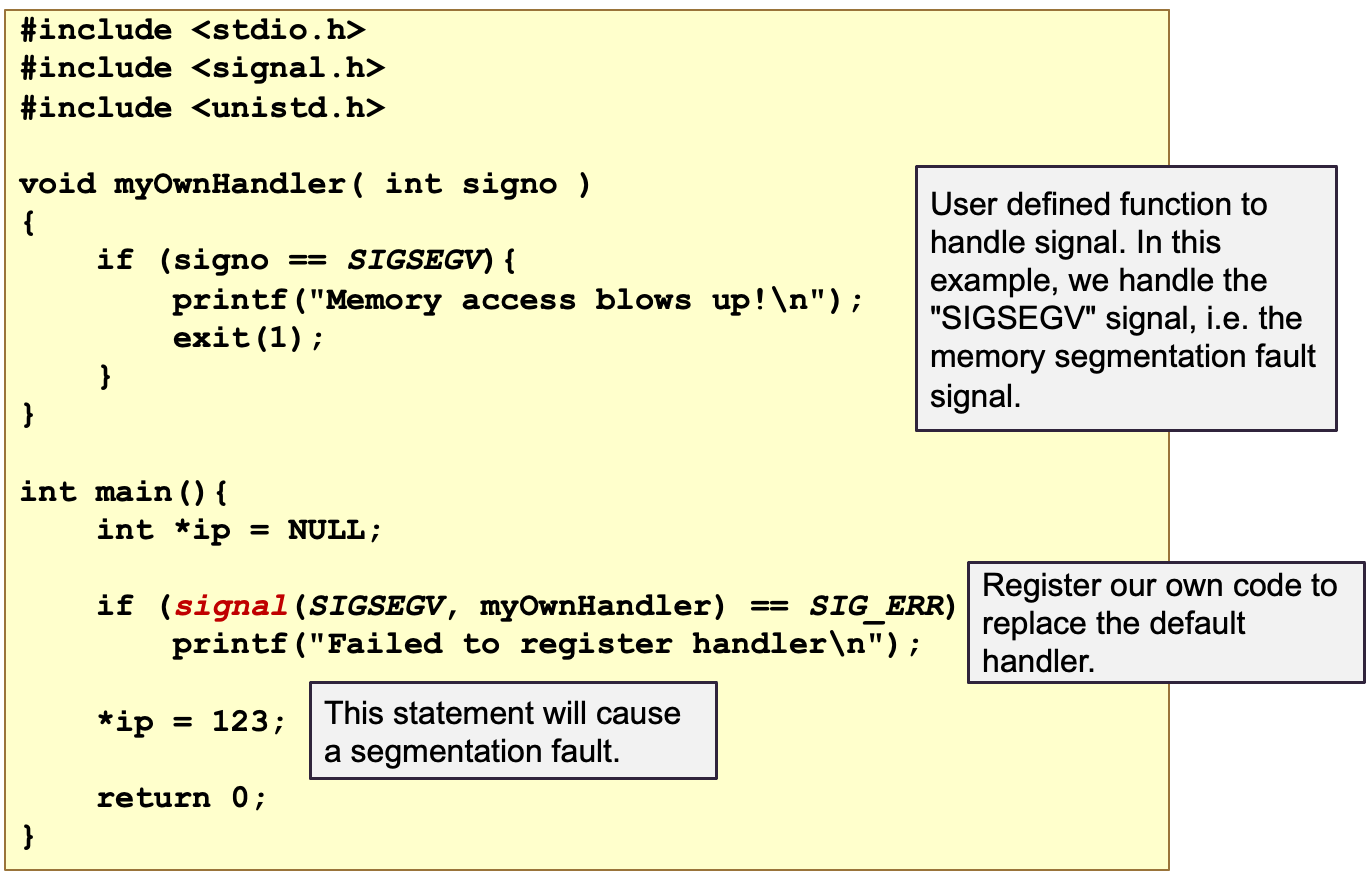
5.4 Unix Signal
Unix SIgnal是进程间通信的一种形式
- 关于事件的异步通知
An asynchronous notification regarding an event - 发送到进程/线程
sent to a process/thread
信号的接收者必须通过以下方式处理信号:一组默认处理程序a default set of handlers或用户提供的处理程序(仅适用于某些信号)user supplied handler
Unix中的常见信号:杀死、停止、继续、内存错误、算术错误等。kill, stop, continue, memory error, arithmetic error
6. 进程管理:同步 Process Management: Synchronization
Race Condition :Problems with concurrent execution
Critical Section
- Properties of correct implementation
- Symptoms of incorrect implementation
Implementations of Critical Section - Low level
- High level language
- High level abstraction
Classical synchronization problems
并发执行的问题
当有两个或多个进程时:进程以交错方式同时执行 并且 共享可修改的资源 ⇒ 这可能导致同步问题
- 单个顺序过程的执行是确定的
deterministic,重复执行将得到相同的结果。 - 执行并发进程可能是不确定的,执行结果取决于访问/修改共享资源的顺序(也就是取决于竞争条件
race conditions)
竞争条件 Race Condition
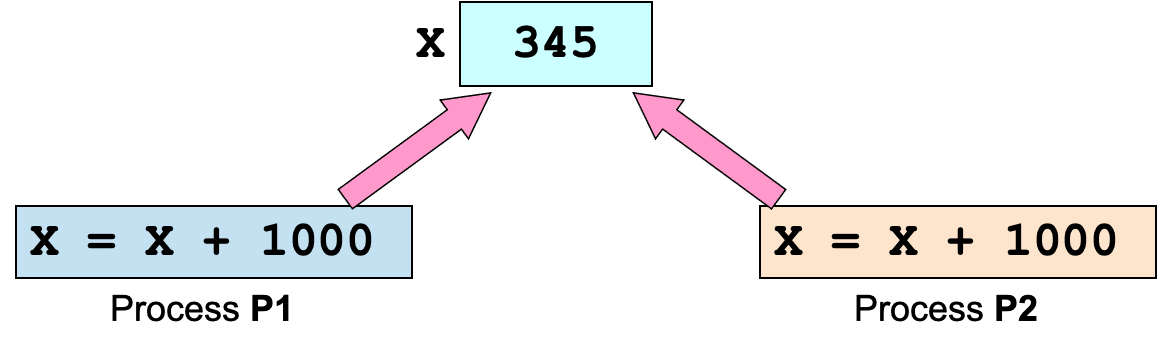
进程 P1 和 P2 共享一个变量 X
X = X + 1000 可以大致翻译为以下机器指令:
- Load X ⇒ register1
- Add 1000 to register1
- Store register1 ⇒ X
良好表现:给出正确结果2345

出错情况:交错执行,结果出错,例如下面这样

解决方法:
不正确的执行是由于对共享的可修改资源的不同步访问 unsynchronized access to a shared modifiable resource
- 将具有竞争条件 的代码段指定为临界区
critical section - 在任何时刻,只有一个进程可以在临界区执行 ⇒ 防止其他进程进入同一临界区
临界区 Critical Section

操作示例:
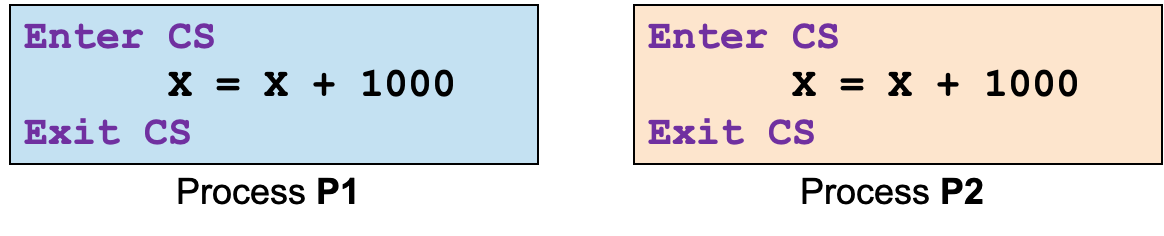
Critical Section的正确实现需要具备以下特征:
- 互斥
Mutual Exclusion:如果进程 Pi 在临界区执行,则所有其他进程都无法进入临界区。 - 推进
Progress:如果临界区中没有进程,则应将访问权限授予等待进程之一。 - 有界等待
Bounded Wait:在进程 Pi 请求进入临界区后,其他进程可以在 Pi 之前进入临界区的次数存在上限。 - 独立
Independence:不在临界区执行的进程永远不应该阻塞其他进程。
错误的同步有以下特征:
- 死锁
Deadlock:所有进程都阻塞,没有任何进展。 - 活锁
Livelock:通常与死锁避免机制有关,进程不断改变状态以避免死锁并且没有取得其他进展,通常进程不会被阻塞。(反复横跳,P1占用R1,P2占用R2,P1需要R2,但是等不到,他俩都释放,然后又分别锁定R1、R2,他们就只能不断地锁定-释放-锁定-释放) - 饿死
Starvation:某些进程永远被阻止。
Critical Section的实现
汇编层面实现:处理器提供的机制
高级语言层面实现:仅使用正常的编程结构
高级抽象:提供一种有额外特性的抽象机制,通常由汇编级机制实现
(1)汇编层面实现 Assembly Level Implementation
Test and Set:一个原子指令。Atomic Instruction
处理器提供的用于实现同步的通用机器指令: TestAndSet Register, MemoryLocation
这个指令会做到:
- 将位于
MemoryLocation的内容载入Register - 将一个
1放入MemoryLocation
这两个过程作为一个单一的机器操作来实现 ⇒ 原子性 atomic
为了便于讨论,假设 TestAndSet 机器指令具有等效的高级语言版本。

这种方式是可以实现锁的。但是,它采用忙等的方式Busy Waiting(不断检查条件,直到可以安全进入临界区)⇒ 浪费处理能力
大多数处理器上都存在此指令的变体:
- 比较交流
Compare and Exchange - 原子交换
Atomic Swap - 加载链接/存储条件
Load Link /Store Conditional
(2)高级语言层面实现 High-Level-Language Implementation
尝试: 竞争锁
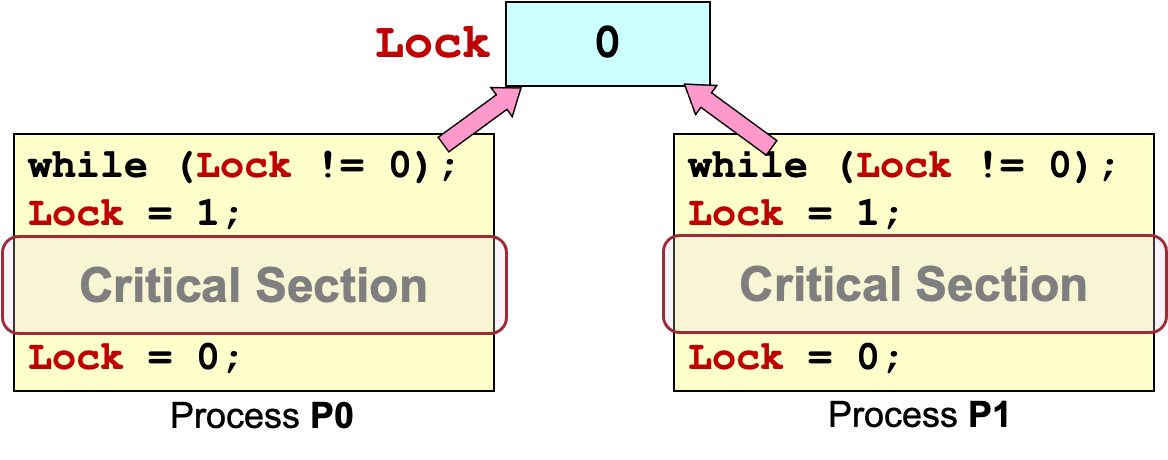
这看起来好像可以,其实并不。因为读写锁不是原子性的,可能在P0读到lock为0时,进程切换到P1,此时P1也读到lock为0,两者同时进入Critical Section。这样违反了互斥Mutual Exclusion的条件(如果进程 Pi 在临界区执行,则所有其他进程都无法进入临界区)。
我们可以通过防止进程切换来解决问题:
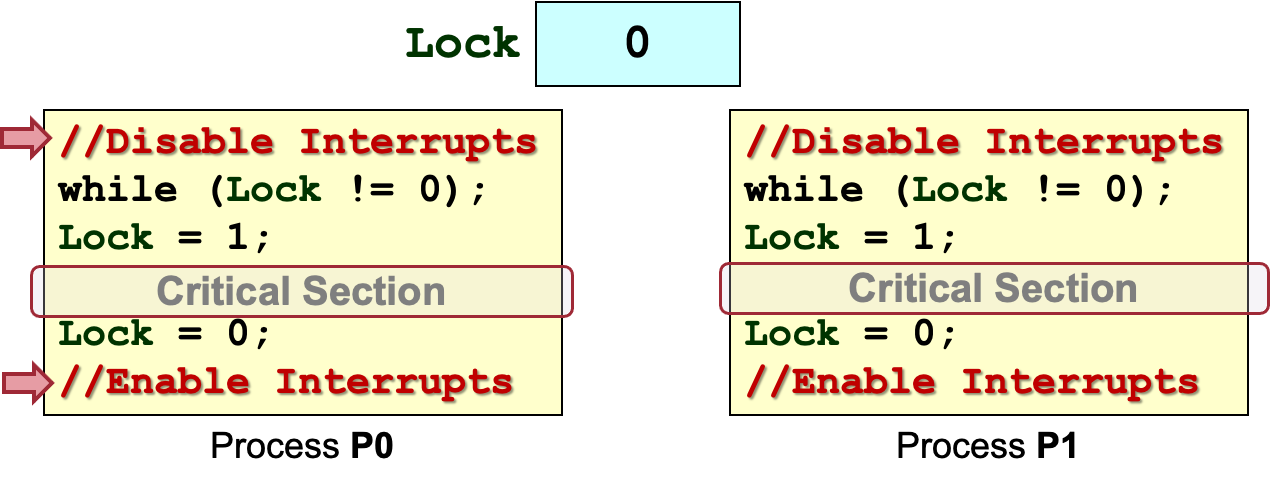
然而这种方式仍然存在以下问题:
- buggy的critical section可能会使整个系统停滞
- 忙等
busy waiting - 需要禁用/启用中断的权限
让进程P0和P1轮流进入Critical Section:
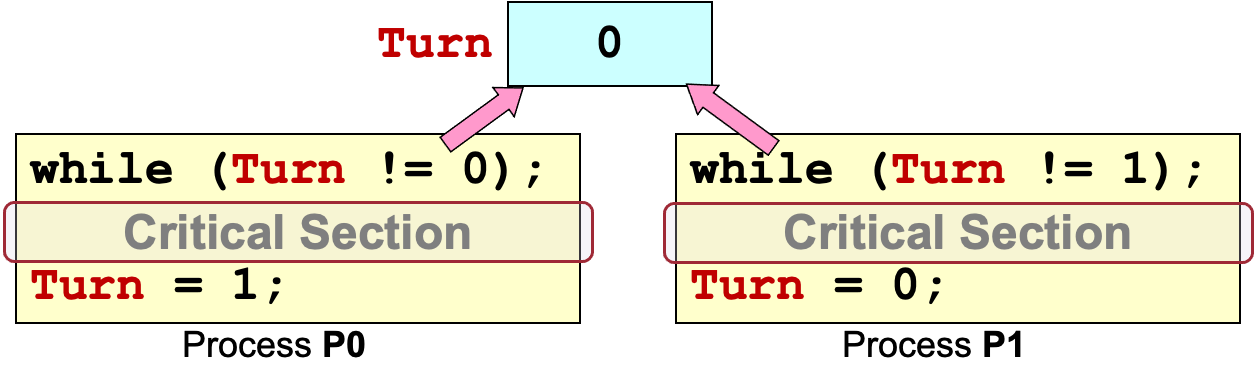
但是,如果P0没进入Critical Section,P1就会饿死。这样违反了独立independence原则。
进一步解决独立性问题:如果 P0 或 P1 没在Critical Section里,另一个进程仍然可以进入 Critical Section。
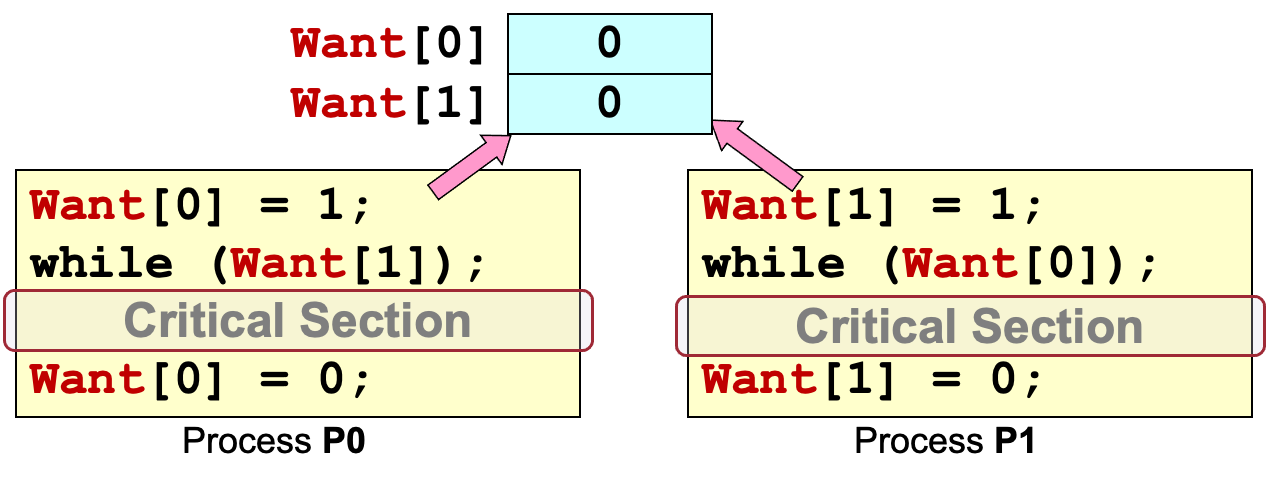
这样做可能导致死锁,互相等待对方释放资源。
接下来我们看Peterson算法:
假设写入Turn是一个原子性操作。
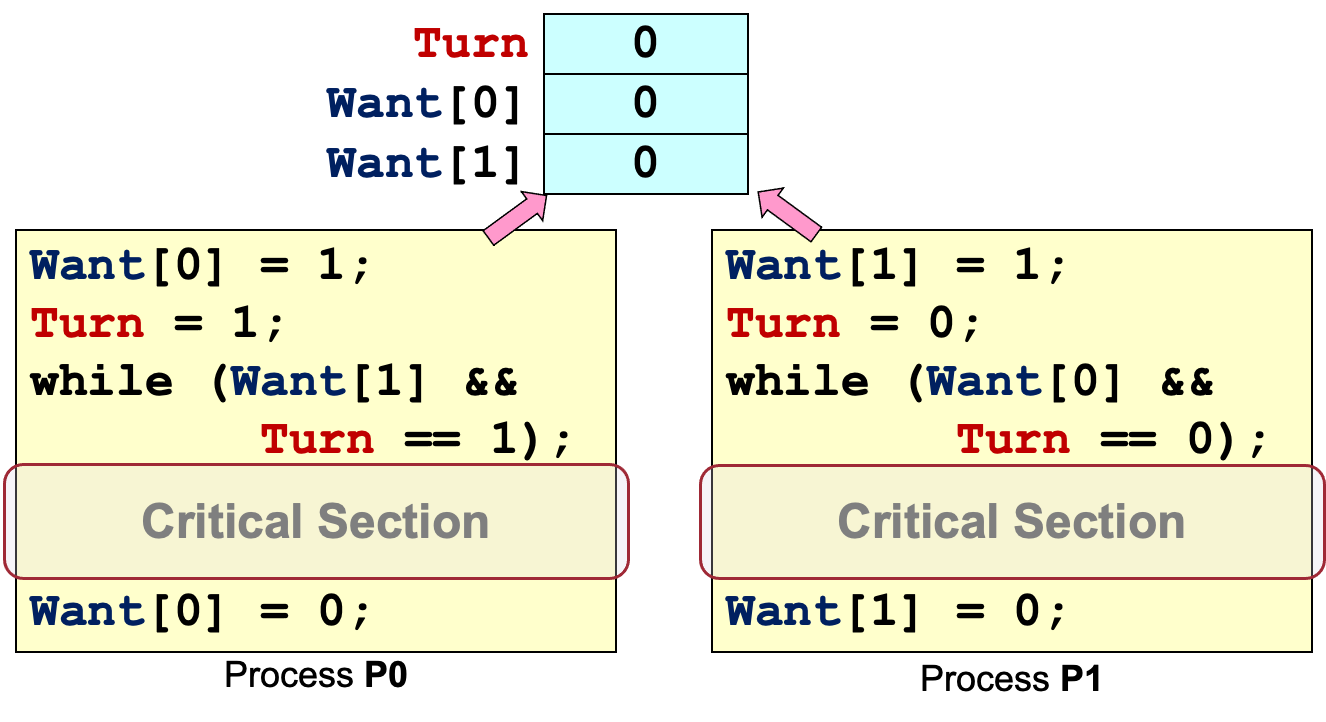
Peterson算法的缺点:
- 忙等:在等待的进程会反复测试 while 循环条件而不是进入阻塞状态;
- 这是一种低阶的设计:可以使用更高级的编程构造:使用简化互斥、不易出错的方式
- 不具备一般性:我们希望同步机制是可以泛化的,不仅仅是互斥。
(3)高级抽象 High-Level Abstraction
信号量 semaphore是一种通用的同步机制,仅指定需要有什么表现,可以有不同的实现。
信号量提供了一种阻塞多个进程的方法,称为休眠进程sleeping process
信号量提供了一种解锁/唤醒一个或多个休眠进程的方法。
Wait() and Signal()
信号量 S 包含一个整数值,最初可以初始化为任何非负值
两个原子信号量操作:
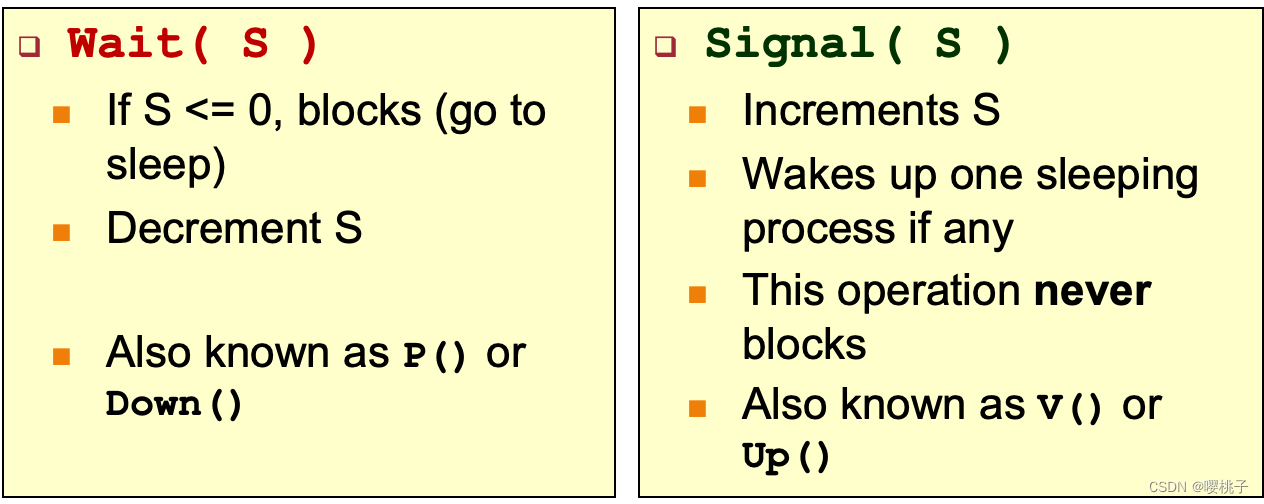
注意:上面说的是这两个方法应该有怎样的表现,而不是具体实现。
为了更好地理解信号量,我们可以将其可视化为:一个protected的Integer和一list的等待中的进程。

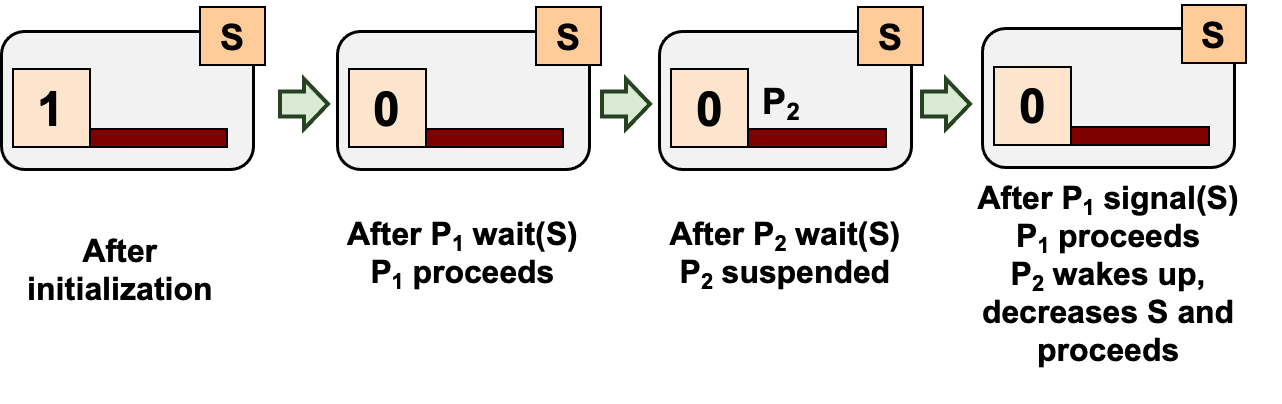
信号量的特性:
给定:
S
i
n
i
t
i
a
l
>
=
0
S_{initial} >= 0
Sinitial>=0
以下不变量invariant应该恒为真:
S
c
u
r
r
e
n
t
=
S
i
n
i
t
i
a
l
+
#
s
i
g
n
a
l
(
S
)
−
#
w
a
i
t
(
S
)
S_{current} = S_{initial} + \#signal(S) - \#wait(S)
Scurrent=Sinitial+#signal(S)−#wait(S)
#signal(S):执行signals()操作的次数
#wait(S):执行成功wait()的次数
- 通用信号量S
General semaphore: S > = 0 ( S = 0 , 1 , 2 , 3 , . . . ) S>=0 (S = 0, 1, 2, 3, ...) S>=0(S=0,1,2,3,...),也称作计数信号量。 - 二元信号量S
Binary semaphore: S = 0 o r 1 S = 0 or 1 S=0or1
为方便起见,存在通用信号量,实际上二元信号量就足够了,即通用信号量可以被二进制信号量模拟。
信号量例子:Critical Section
二元信号量S=1
对于任意进程:

在这种情况下,S可以是0或1,可由信号量不变量semaphore invariant推导出来。
信号量的这种用法通常称为互斥量(互斥)mutex, mutual exclusion。
互斥量的非正式证明 Mutex:Correct CS - Informal Proof

- 死锁
Deadlock意味着所有的进程都卡在wait(S) ⇒ S_current = 0 && N_cs = 0 ⇒ 这违背了 S_current + N_cs = 1的不变量 - 饿死:假设P1阻塞在wait(S),P2在Critical Section中,通过signal(S)退出Critical Section。如果没有其他进程在休眠,P1被唤醒;如果有其他进程,在公平调度下,P1最终也会被唤醒。
不正确地使用信号量:死锁
假设信号量初始化为 P = 1, Q = 1。
P0先Wait§ ⇒ P = 0,切换到P1 Wait(Q) ⇒ Q = 0,切换到P0,无法获得资源,因为已经被P1锁定了,同理切换到P1,需要的资源也被P0锁定了,双方都在等待对方释放资源,陷入死锁。
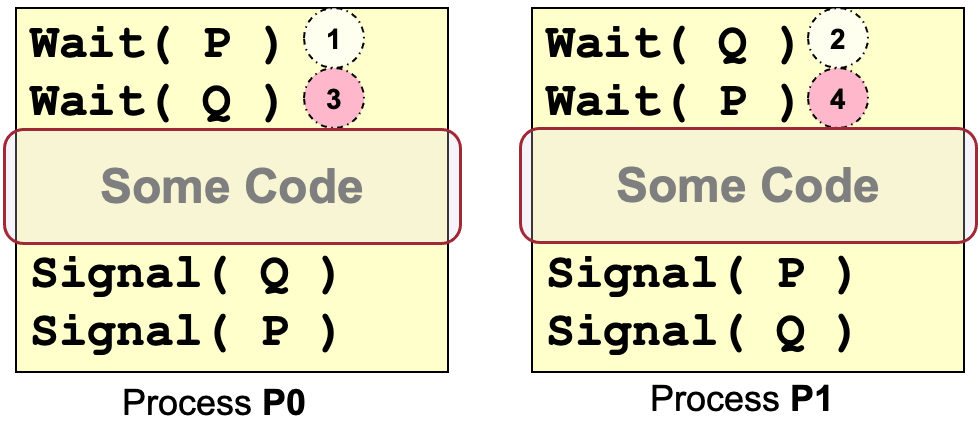
(4)其他高阶抽象
信号量非常强大:
到目前为止,信号量没有无法解决的同步问题
其他高级抽象实质上提供了单独使用信号量难以实现的扩展功能
常见的替代方案:条件变量 Conditional Variable
- 允许任务等待特定事件发生
- 具有广播
broadcast能力,即唤醒所有等待任务 - 与监控者
monitor有关
经典的同步问题 Classical Synchronization Problems
(1)Producer-Consumer
进程共享一个大小为K的有界缓冲区
- 生产者 Producer:生产任务,当缓冲区未满时,插入缓冲区(< K items)。
- 消费者 Consumer:当缓冲区非空时,移除任务(> 0 items)。
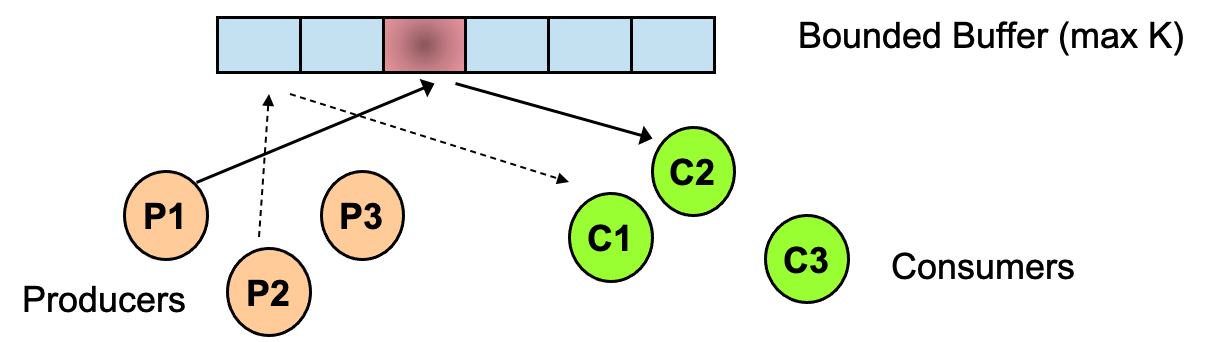
生产者-消费者:忙等方式

初始值:
count = in = out = 0
mutex = S(1) (初始值为1的信号量)
canProduce = TRUE
canConsume = FALSE
- canConsume:触发消费者去获取一个item
- canProduce:触发生产者去生产一个item
- wait(mutex) + signal(mutex):创建一个Critical Section
- in = (in + 1) % K
- out = (out + 1) % K:循环队列
这段代码可以解决问题,但存在忙等问题。
生产者-消费者:阻塞方式

初始值:
count = in = out = 0
mutex = S(1), notFull = S(K), notEmpty = S(0)
- wait(notFull):让生产者休眠
- wait(notEmpty):让消费者休眠
- signal(notFull):一个消费者唤醒一个生产者
- signal(notEmpty):一个生产者唤醒一个消费者
这段代码也可以正确地解决问题,不存在忙等问题,不需要的生产者/消费者会根据各自的信号量情况进入睡眠。
(2)读者写者 Readers Writers
进程共享数据结构D
- Reader:从D中获取数据
- Writer:在D中修改数据
一次只能有一个写者,但是可以有多个读者。
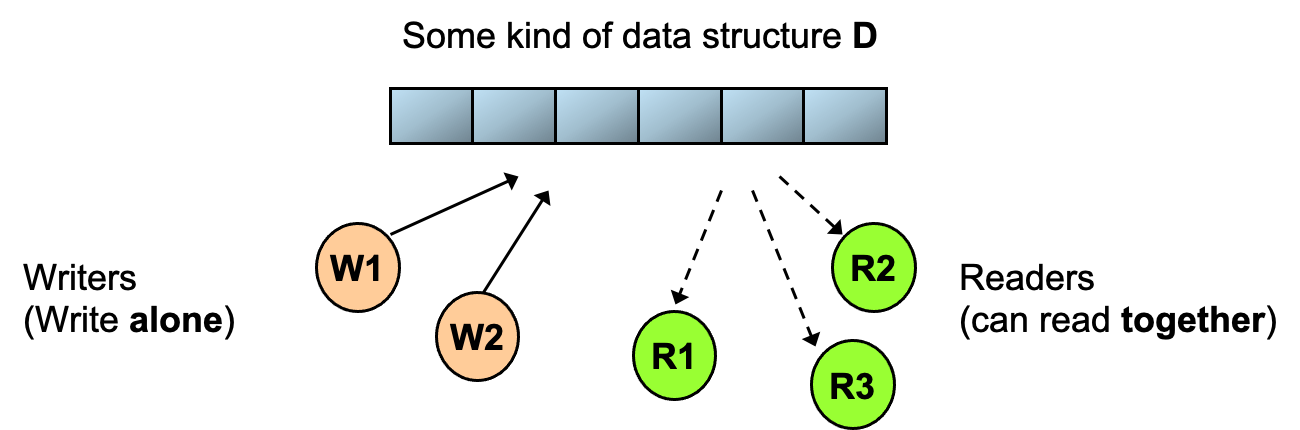
Readers Writers:简单版本

当房间是空的时候,writer可以进入并修改数据,否则他要等到roomEmpty信号量为1时才能进入。
当一个读者进入房间时,将roomEmpty信号量置为0,可以有多个读者,当最后一个读者离开房间时,将roomEmpty置为1。
哲学家进餐问题 Dining Philosophers: Specification
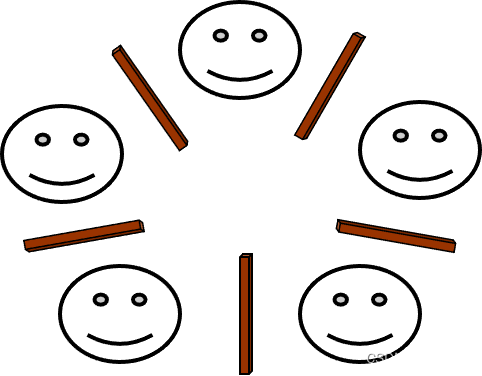
五位哲学家围坐在一张桌子旁,每对哲学家之间放着五根筷子。
任何哲学家想吃饭时,他/她都必须从他/她的左右手拿筷子
设计一种无死锁和无饥饿的方式让哲学家自由进食
尝试1:
对于哲学家i,当他思考完毕后,他拿起左边的筷子、右边的筷子,吃东西,然后放下左边的筷子、右边的筷子。

死锁:所有哲学家同时拿起左筷子,无人能继续
尝试解决这个死锁:
如果右筷子拿不到,让哲学家放下左筷子,稍后再试
没有死锁 ⇒ 也可能有活锁:所有哲学家左筷子拿起,放下,拿起,放下,…………
尝试2:
使用互斥锁mutex将拿筷子-吃-放筷子变成一个原子操作。

这确实可以没有死锁问题,但是本来同一时间至少有两个人能吃东西,现在只能一个人了,效率降低。
Tanenbaum Solution
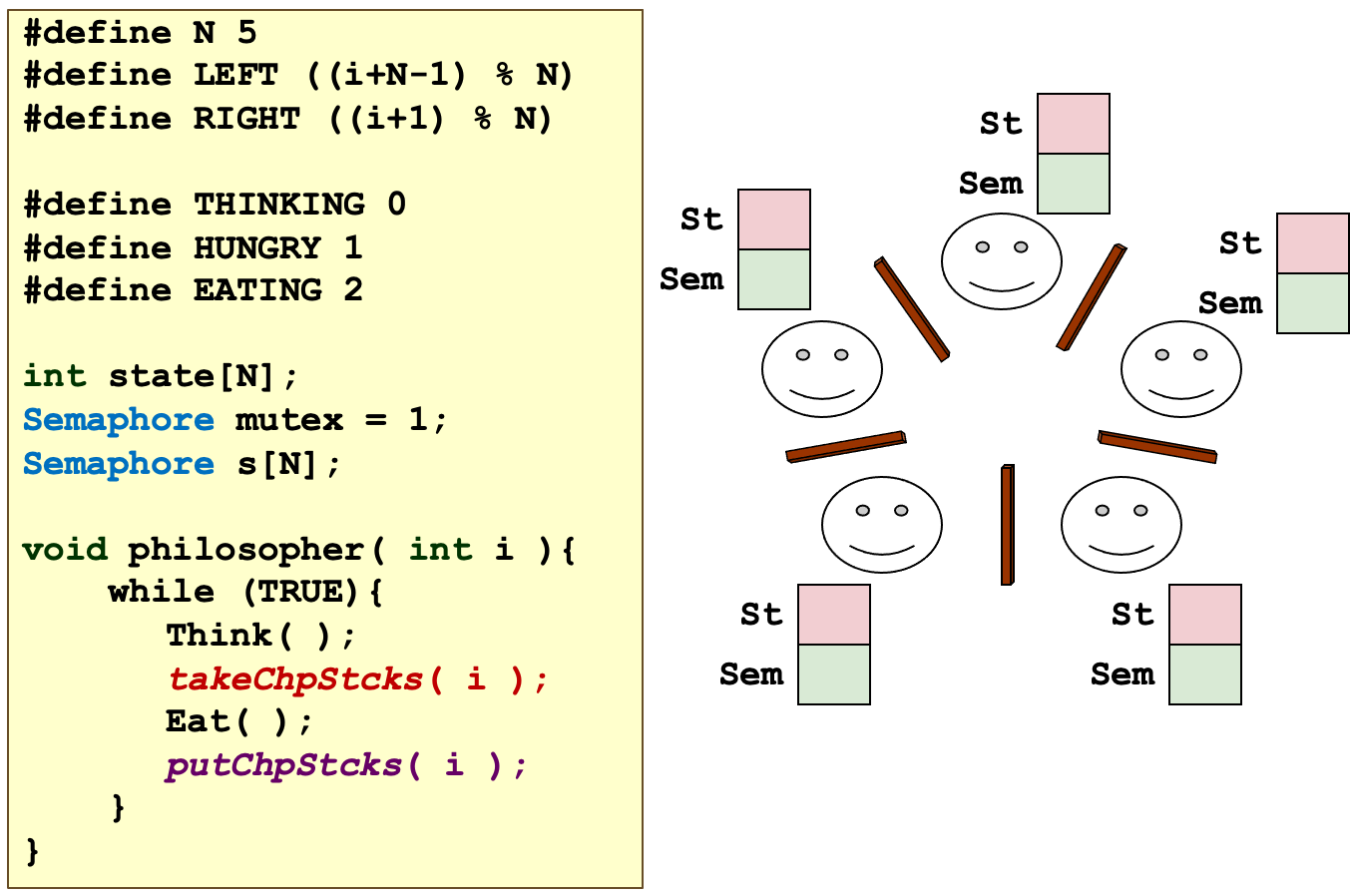
#define N 5
#define LEFT ((i+N-1) % N)
#define RIGHT ((i+1) % N)
#define THINKING 0
#define HUNGRY 1
#define EATING 2
int state[N];
Semaphore mutex = 1;
Semaphore s[N];
void philosopher( int i ){
while (TRUE){
Think( );
takeChpStcks( i );
Eat( );
putChpStcks( i );
}
}
void takeChpStcks( i )
{
wait( mutex );
state[i] = HUNGRY;
safeToEat( i );
signal( mutex );
wait( s[i] ); // 如果safeToEat不成功,等待左右来唤醒他
}
void safeToEat( i )
{
if( (state[i] == HUNGRY) &&
(state[LEFT] != EATING) &&
(state[RIGHT] != EATING) ) {
state[ i ] = EATING;
signal( s[i] ); // 这一步是用于唤醒左右去吃
}
}
void putChpStcks( i )
{
wait( mutex );
state[i] = THINKING;
safeToEat( LEFT );
safeToEat( RIGHT );
signal( mutex );
}
有限进食者 Limited Eater
如果最多允许 4 位哲学家坐在桌子旁(留一个空位)⇒ 死锁就不会发生

(chpstck=s(1)[5]指的是对五个筷子,都设置chpstk为S(1))
同步的实现 Synchronization Implementations
POSIX信号量
Unix下信号量的常见实现
头文件:#include <信号量.h>
编译标志:gcc something.c –lrt,代表“实时library”
基本用法:初始化一个信号量,在信号量上执行 wait() 或 signal()
pthread 互斥量和条件变量 Mutex and Conditional Variables
pthread 的同步机制
互斥量(pthread_mutex):
- 二进制信号量(即等效的信号量(1))。
- 锁:pthread_mutex_lock()
- 解锁:pthread_mutex_unlock()
条件变量( pthread_cond ):
- wait:pthread_cond_wait()
- signal:pthread_cond_signal()
- broadcast:pthread_cond_broadcast()
其他
支持线程的编程语言会有某种形式的同步机制
例子:
Java:所有对象都有内置锁(mutex)、同步方法访问等
Python:支持互斥量、信号量、条件变量等
C++:在C++11中添加了内置线程; 支持互斥量、条件变量
7. 内存抽象 Memory Management:Memory Abstraction
7.1 内存基础
硬件
物理内存存储:
随机存取存储器 (Random Access Memory, RAM),可以被视为一个字节数组。每个字节都有一个唯一的索引,称为物理地址physical address。
一个连续的内存区域:连续地址的间隔an interval of consecutive addresses。

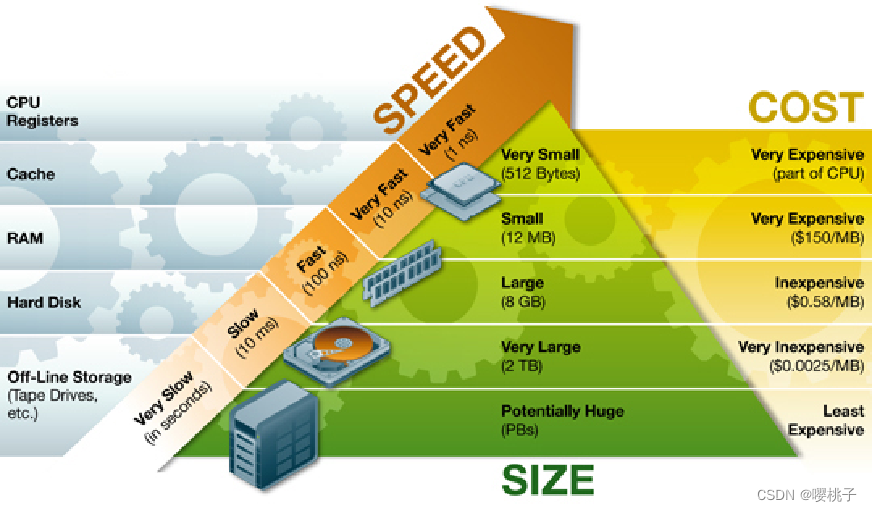
在说内存时通常是指RAM。
Flash RAM不是很robust,通常用在PC,而不是server。
进程的内存使用
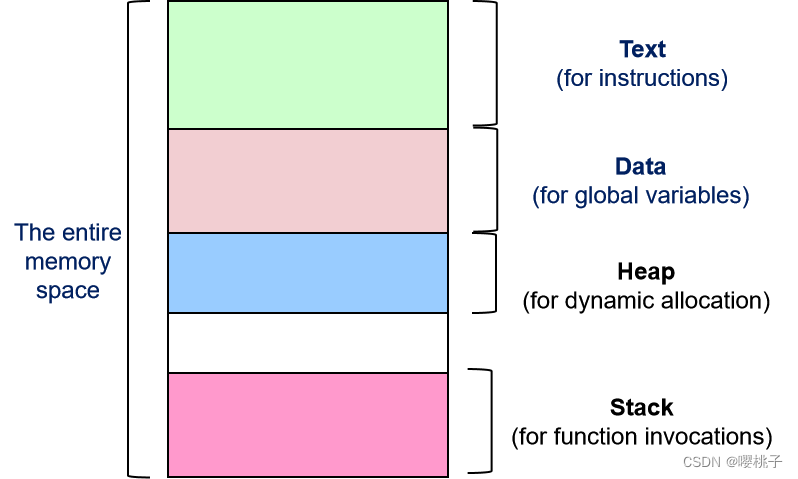
可执行文件通常包含:代码(用于文本区域)、数据布局data layout(用于数据区域)
通常,一个进程中有两种类型的数据:
- 瞬态数据
Transient Data:
仅在有限的时间内有效,例如,在函数调用期间。
例如,参数,局部变量。 - 持久数据
Persistent Data:
在计划期间有效,除非明确删除(如果适用)
例如 全局变量、常量变量、动态分配内存
两种类型的数据部分都可以在执行期间增长/缩小。
操作系统的作用
操作系统处理以下与内存相关的任务:
- 为新进程分配内存空间
- 管理进程的内存空间(如进程需要更多的内存空间)
- 保护进程各自的内存空间(如chrome每一个tag是一个进程,不能读其他进程的信息)
- 给进程提供与内存相关的系统调用
- 管理内部使用的内存空间
Key Topics
- Memory Abstraction:为内存访问提供逻辑接口
- Contiguous Memory Allocation:分配和管理连续的内存块
- Disjoint Memory Allocation:在不相交的区域分配和管理内存
- Virtual Memory Management:使用辅助存储作为扩展内存区域
7.2 内存抽象
实际地址-没有内存抽象
假设一个进程直接使用物理地址:即没有内存抽象
使用示例代码,让我们思考 :
如何访问进程中的内存位置?
多个进程可以正确共享物理内存吗?
进程的地址空间是否可以轻松保护?
优点

内存访问很简单
程序中的地址 == 物理地址
无需转换/映射
在编译期间固定地址
缺点

如果两个进程占用相同的物理内存:
冲突:两个进程都假设内存从 0 开始
⇒ 难以保护内存空间
逻辑地址
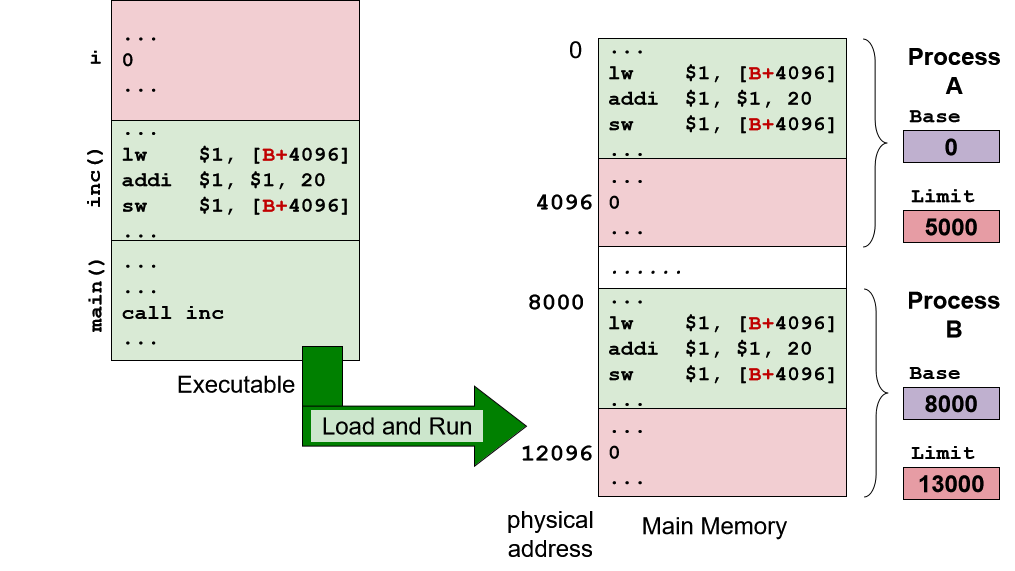
改进:地址搬迁 Address Relocation
【这是由OS做的】
进程加载到内存时重新计算内存引用:
例如,为进程 B 中的所有内存引用添加 8000 的偏移量(进程 B 在地址 8000 处开始)
问题:
加载时间慢
不容易区分内存引用memory reference和普通整数常量normal iteger constant
改进:Base + Limit Registers
【这是由CPU做的】
-
使用特殊寄存器作为所有内存引用的基础:称为基本寄存器
Base Register
在编译期间,所有内存引用都编译为相对于该寄存器的偏移量
在加载时,基址寄存器被初始化为进程内存空间的起始地址 -
添加另一个特殊寄存器来指示当前进程的内存空间范围:称为极限寄存器
limit register
所有内存访问都根据限制检查以保护内存空间完整性
超过范围会引发segementation fault。
问题:
- 访问地址 Adr:实际 = 基础地址 + Adr
- 检查实际地址 < 有效边界
因此,每次内存访问都会产生一个加法和比较
这个想法非常有用:
后来推广到分割机制segmentation mechanism,内存抽象:进程 A 和 B 中的地址 4096 不再是同一个物理位置
在程序中嵌入物理内存地址是个坏主意
逻辑地址的思想:
- 逻辑地址 == 进程如何查看其内存空间
- 逻辑地址 != 一般的物理地址
相反,需要逻辑地址和物理地址之间的映射 - 每个进程都有一个自包含的、独立的逻辑内存空间
7.3 连续内存分配
进程在执行期间必须在内存中
- 存储内存概念
store memory concept - 加载存储内存执行模型
Load-store memory execution model
让我们假设:
- 每个进程占用一个连续的内存区域
- 物理内存足够大,可以容纳一个或多个具有完整内存空间的进程
这些假设在后面的主题中不会再重复说。
多任务、context切换和交换 Multitasking, Context Switching & Swapping
多任务处理需要允许多个进程同时在物理内存中,这样我们就可以从一个进程切换到另一个进程。
当物理内存已满时,通过以下方式释放内存:删除终止的进程 / 将阻塞的进程交换到辅助存储secondary storage(harddisk / SSD)。
内存分区 Memory Partitioning
内存分区:分配给单个进程的连续内存区域
两种分配分区的方案:
- 固定大小的分区
物理内存被分成固定数量的分区
一个进程将占用其中一个分区 - 可变大小分区
根据进程的实际大小创建分区
操作系统跟踪占用和空闲的内存区域,必要时进行拆分和合并splitting and merging
固定大小分区

如果一个进程没有占用整个分区,剩余的空间就都被浪费了,这些浪费的空间称为内部碎片internal fragmentation。
优点:
- 易于管理
- 快速分配
- 每个空闲分区都一样 ⇒ 无需选择
缺点:
- 分区大小需要足够大以包含最大的进程
- 较小的进程会浪费内存空间 ⇒ 内部碎片
可变大小分区
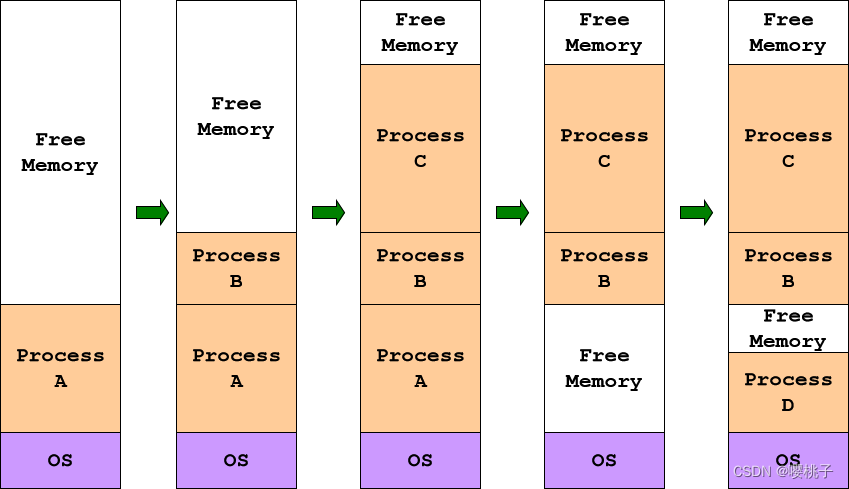
空闲内存空间称为空洞 hole
通过进程创建/终止/交换 ⇒ 往往有大量的空洞,称为外部碎片 external fragmentation ⇒ 导致本来够放的空间变得支离破碎不够放了
通过移动占用的分区来合并空洞可以创建更大的空洞(更有可能有用)
- 优点:
灵活并消除内部碎片 - 缺点:
需要在操作系统中维护更多信息
需要更多时间来找合适的区域
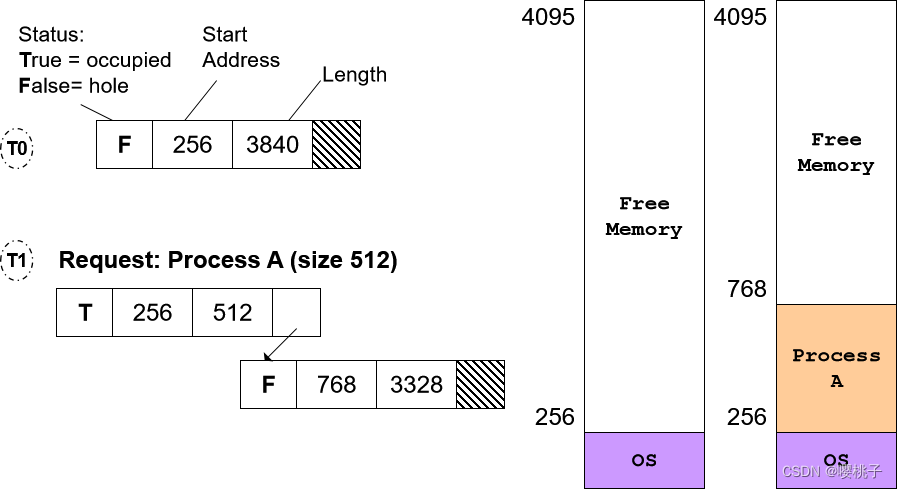
分配算法 Allocation Algorithm
假设操作系统维护一个分区和空洞列表 a list of partitions and holes
定位大小为 N 的分区的算法:
- 搜索大小为 M > N 的空洞。几种变体:
- 首次拟合
First Fit:
取第一个足够大的空洞 - 最合适
Best-Fit:
找到足够大的最小孔
可以按大小排列holes,然后找第一个大于N的hole
这种做法可能导致M-N非常小,以至于不能有其他用处了 - 最差拟合
Worst-Fit:
找到最大的洞
- 首次拟合
- 把洞分成N和M-N
N 将是新的分区
M-N 将是剩余空间 ⇒ 一个新洞
合并和压缩 Merging and compaction
当一个占用的分区被释放时,如果周围有洞,就与相邻的洞合并
也可以使用压缩compation:移动占用的分区以合并洞(不能太频繁调用,因为它非常耗时)
Example
操作系统为分区信息维护一个链表:使用 First-Fit 算法

动态分配算法:伙伴系统 Buddy system
伙伴内存分配算法提供高效的:
- 分区拆分
partition splitting - 自由分区(洞)定位
locating good match of free partition (hole) - 分区解除分配和合并
patition de-allocation and coalescin
思想:
- 空闲块被重复分成两半以满足请求,这两半形成兄弟块(伙伴块
sibling blocks, buddy blocks)。 - 当伙伴块都空闲时,可以合并形成更大的块
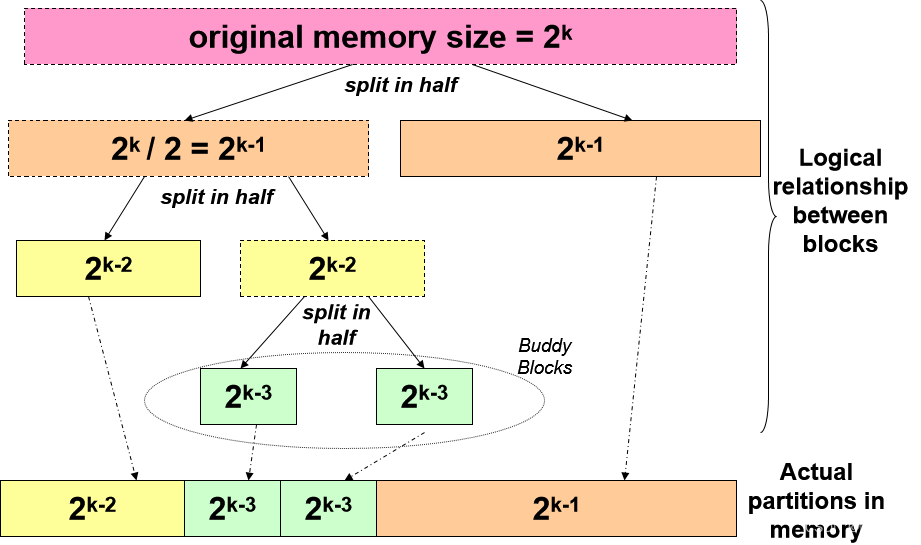
保留一个数组 A[0…K],其中 2^K 是最大可分配块大小
- 每个数组元素 A[J] 是一个链表,用于跟踪大小为 2^J 的空闲块
- 每个空闲块仅由起始地址标识
在实际实现中,也可能有一个最小的可分配块大小 ,因为太小的区块管理起来不划算(我们将在讨论中忽略这一点)
伙伴系统:分配算法 Buddy System: Allocation Algorithm
分配大小为 N 的块:
- 找到最小的 S,使得 2S >= N
- 访问 A[S] 以获得空闲块
- 如果存在空闲块:
- 从空闲块列表中删除块
- 分配块
- 否则
- 从 S+1 到 K 中找到最小的 R,使得 A[R] 有一个空闲块 B
- 对于(R-1 至 S)
- 反复拆分 B ⇒ A[S…R-1] 有一个新的空闲块
- 转到第 2 步
- 如果存在空闲块:
伙伴系统:释放算法 Deallocation Algorithm
要释放块 B:
- 检查 A[S] ,其中 2 S = = s i z e o f B 2^S == size of B 2S==sizeofB
- IF B 的好友 C 存在且空闲
- a. 从列表中删除 B 和 C
- b. 合并 B 和 C 以获得更大的块 B’
- c. 转到步骤 1,其中 B ⇐ B’
- Else(B的好友还没空闲) ⇒ 将 B 插入到 A[S] 中的列表中
如何找到Buddy
观察到:
- 给定块地址 A 是 xxxx00…00
- 拆分后得到2个一半大小的块:
B = xxxxx0…00 和 C = xxxxx1…00
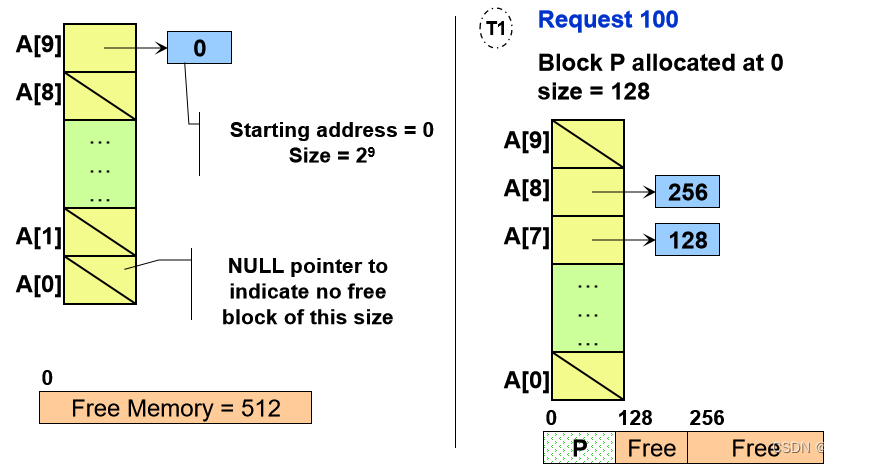
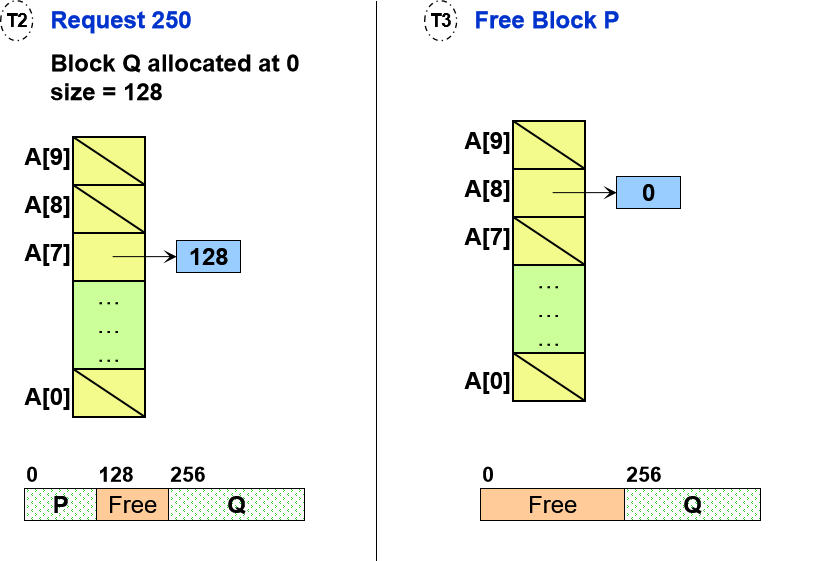
Example:
A = 0 (000000),大小 = 32
拆分后:
B = 0 (000000),大小 = 16
C = 16 (010000),大小 = 16
因此,两个块 B 和 C 是大小为 S 的伙伴,B和C的第S位是补码complement,B 和 C 的第 S 位之前的前导位相同。
Example:
假设:
- 最大的块是 512 (2^9)
- 最初只有一个大小为 512 的空闲块
8. 内存管理:不相交内存 Disjoint Memory Schemes
在第 17 课中,我们在两个假设下讨论了内存管理:
- (1)进程在连续的物理内存中
- (2)物理内存足够大,可以容纳整个进程
让我们在本章中删除假设(1):进程内存空间现在可以位于不相交的物理内存位置,通过分页机制paging
分页 Paging:基本思想
物理内存被分成固定大小的区域(由硬件决定),称为物理帧 physical frame
进程的逻辑内存同样被分成相同大小的区域,称为逻辑页logical page
在执行时,进程的页面被加载到任何可用的内存帧中
⇒ 逻辑内存空间保持连续
⇒ 占用的物理内存区域可以分离
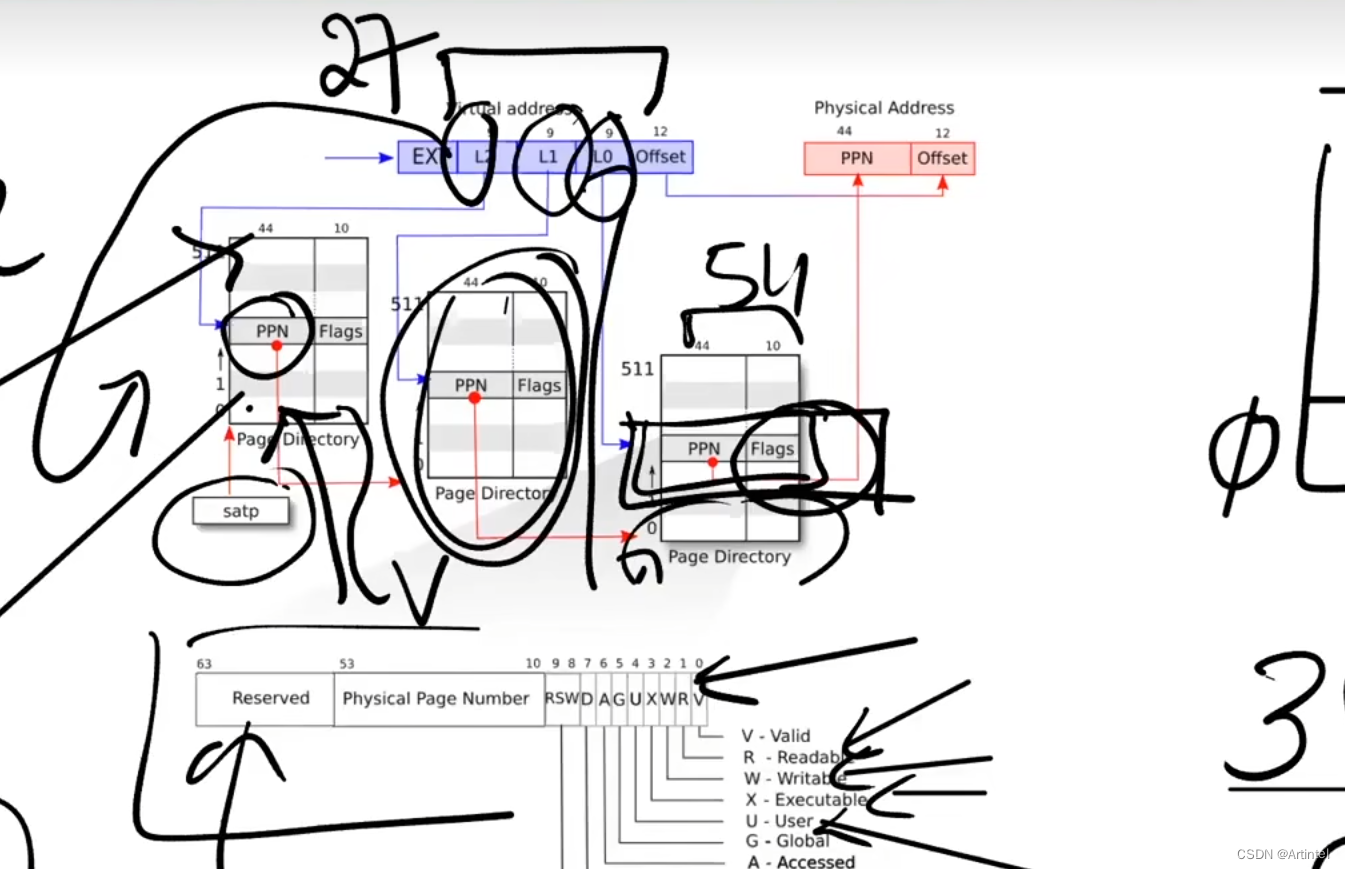
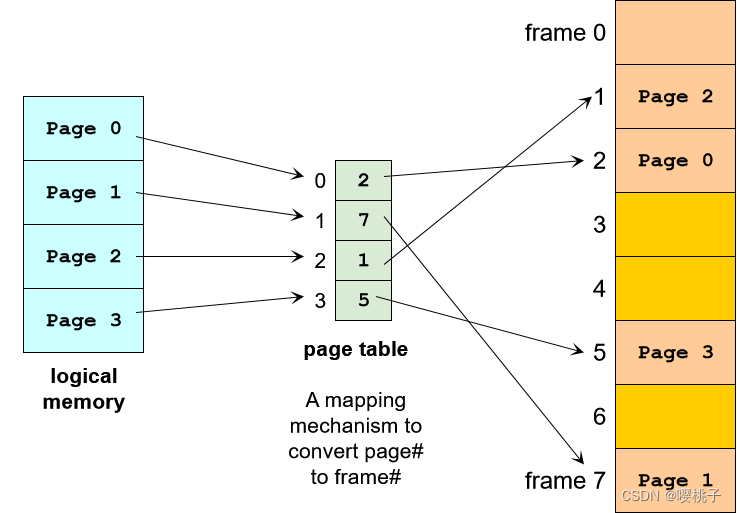
页表:查找机制
在连续内存分配中,跟踪进程的使用情况非常简单:base + limit (起始地址和进程大小)
在分页机制下:
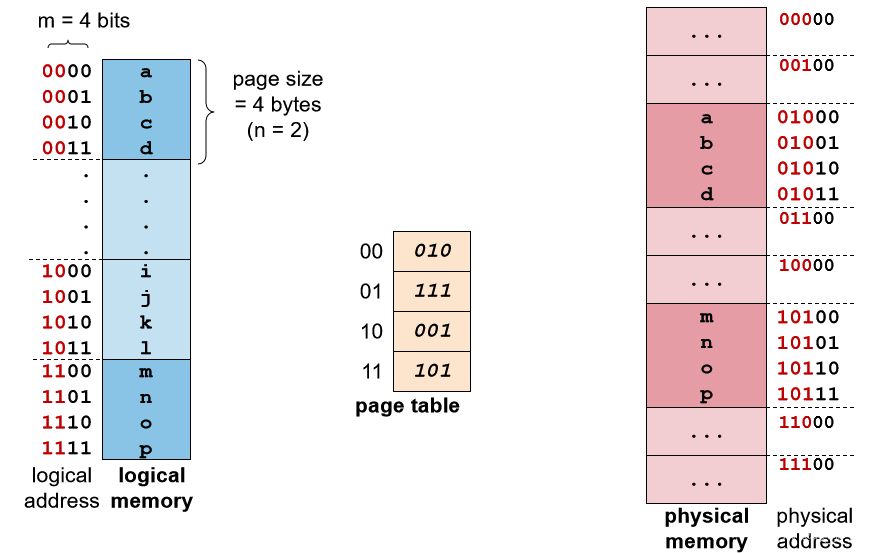
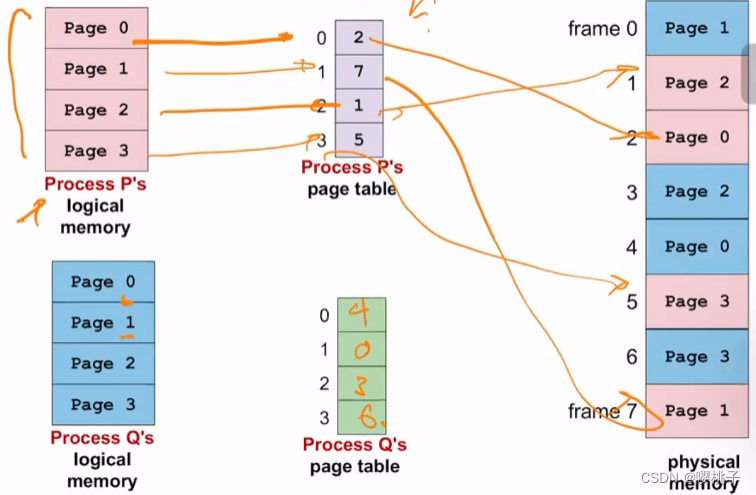
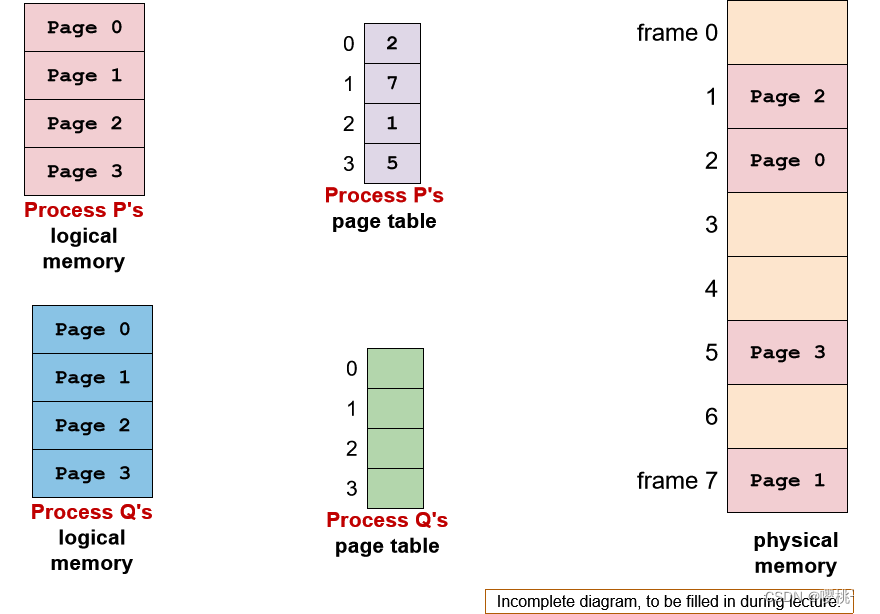
逻辑页面 ⇐ ⇒ 物理帧映射不再简单,需要一个查找表来提供转换,这种结构称为页表
有一个page table register来定位page table的起始点。
逻辑地址转换
程序代码使用逻辑内存地址
但是,要实际访问该值,需要物理内存地址
要在分页方案中定位物理内存中的值,我们需要知道:
F:物理帧号
offset:从物理帧开始的位移
实际地址 = F x 物理帧大小 + 偏移量
逻辑地址转换:基本技巧
两个重要的设计简化了地址转换计算
- 将帧大小(page大小)保持为 2 的幂
- 物理帧大小 == 逻辑页面大小
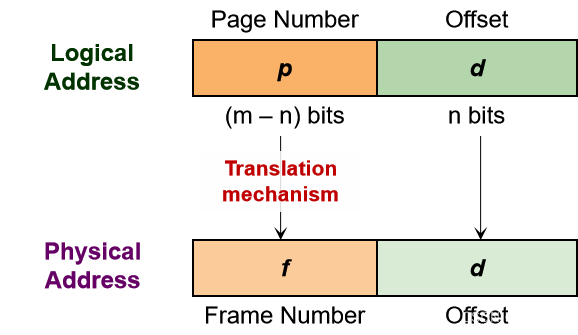
逻辑地址转换:公式
给定:
页面/帧大小为 2^n
m位逻辑地址
逻辑地址 Logical Address LA:
p = LA 的最高有效 m-n 位
d = LA 的剩余 n 位
使用 p 找到帧号 f
根据页表等映射机制
物理地址 PA:
PA = f*2^n + d
示例:4 个逻辑页,8 个物理帧
分页:观察
分页消除外部碎片 external fragmentation
没有剩余的物理内存区域
所有空闲的帧都可以使用,没有浪费
分页仍然可以有内部碎片 internal fragentation
逻辑内存空间不能是页面大小的倍数
逻辑和物理地址空间的清晰分离
灵活性大
地址转换简单
实施分页
常见的纯软件解决方案:
操作系统将页表信息与进程信息一起存储(例如 PCB)
进一步理解 ⇒ 进程的内存context == 页表
问题:
每个内存引用都需要两次内存访问 ⇒ 慢
- 第一次访问是读取索引页表条目以获取帧号
- 第二次访问是访问实际的内存项
分页机制:硬件支持
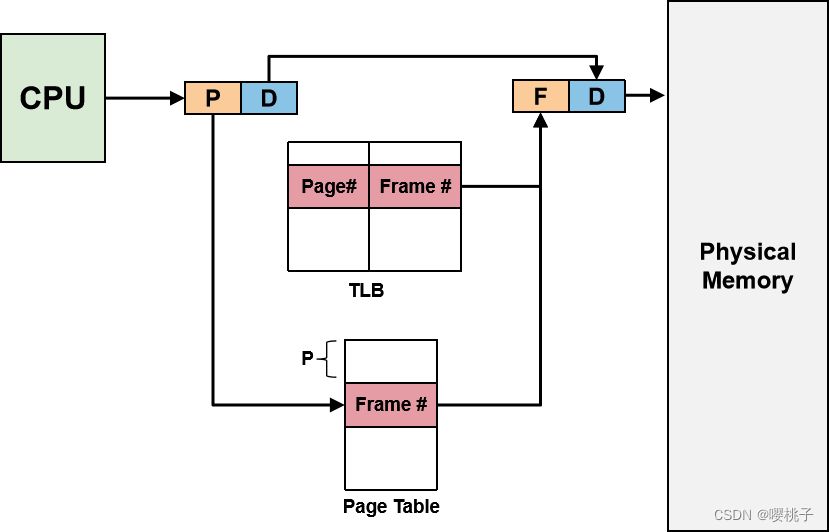
现代处理器提供专门的芯片上的组件来支持分页,称为转换后备缓冲区 (Translation Look-Aside Buffer, TLB),TLB 充当一些页表条目的缓存。very small, fully associated
使用 TLB 进行逻辑地址转换:
- 使用页码关联搜索 TLB
- 找到条目(TLB-Hit):获得帧号以生成物理地址
- 未找到条目(TLB-Miss):访问整个页表的内存,检索到的帧号用于生成物理地址和更新 TLB。
TLB:对内存访问时间的影响
假设:
TLB 访问耗时 1ns
主存访问需要 50ns
如果 TLB 包含整个页表的 40%,则平均内存访问时间是多少?
内存访问时间
= TLB hit + TLB miss
= 40% x (1ns + 50ns) + 60%(1ns + 50ns + 50ns)
= 81ns
Note: 忽略填入 TLB 条目的开销和缓存的影响。
TLB 和进程切换
进一步理解:TLB 是进程硬件context的一部分
当发生context切换时:TLB 条目被刷新,这样新进程就不会被错误转换。
因此,当进程恢复运行时,会遇到许多 TLB miss 来填入 TLB。所以在最初可以放置一些条目,例如 放入一些代码页以减少 TLB miss。
分页方案:保护
基本的分页方案可以很容易地扩展,以保护进程之间的内存,通过:
- 访问权限位
access-right bits - 有效位
valid bit
访问权限位 access-right bits: 每个页表条目都附加了几个bit来标识 【是否可写、可读、可执行】。例如,包含代码的页面应该是可执行的,包含数据的页面应该是可读可写的等。
可以根据访问权限位 检查内存访问权限。
我们可以观察到:
所有进程的逻辑内存范围通常是一样的;然而,并非所有进程都使用了整个范围 ⇒ 某些page超出一些进程的范围
有效位 valid bit: 附在每一页table 条目,标识进程访问是否可以有效访问页面。
操作系统将在进程运行时设置有效位。
通过有效位检查内存访问权限:超出范围的访问将被操作系统处理。
分页方案:页面共享 Page Sharing
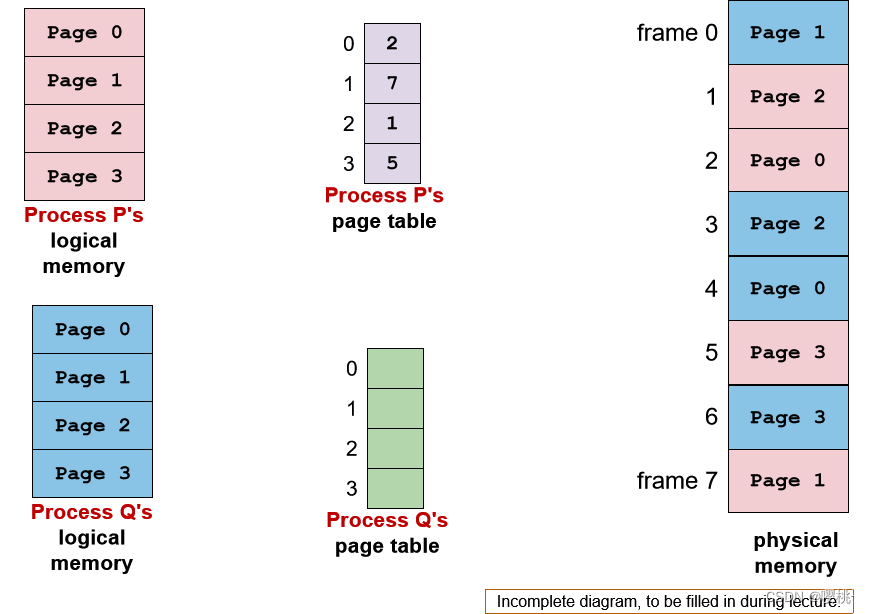
页表可以允许多个进程共享同一个物理内存帧。在页表条目中使用相同的物理帧号。
可能的用法:
- 共享代码页:一些代码会被多个进程使用,例如C标准库,系统调用等
- 实现写时复制
copy-on-write:像我们在前面“进程抽象”章节讨论的,父进程和子进程可以共享一个页面,直到其中一个进程尝试更改它的值。
分页方案:页面共享
分页方案:写时复制
分割机制 segmentation scheme
为什么内存错误通常被称为分段错误segmentation fault?
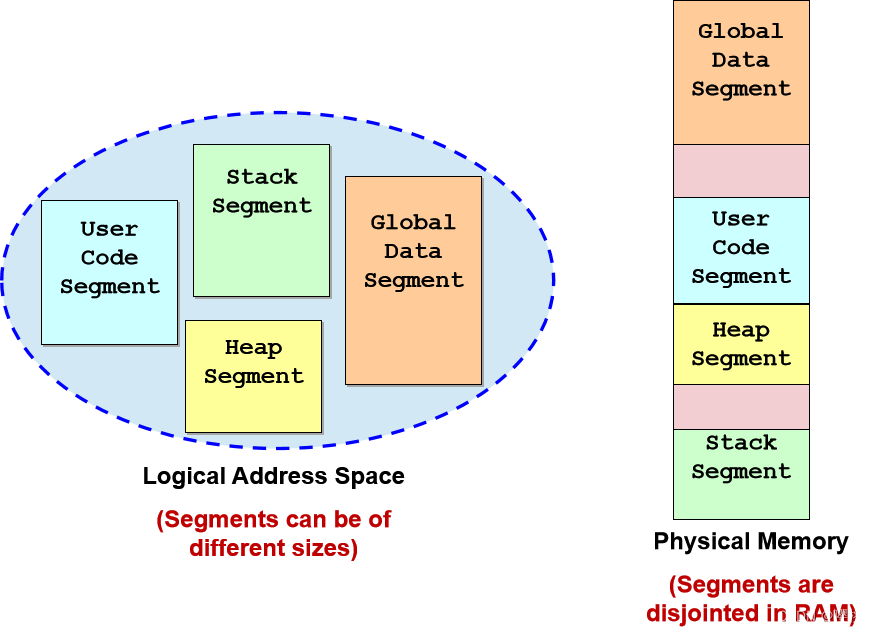
细分方案:动机
到目前为止,进程的内存空间被视为单个实体。然而,一个进程中实际上有许多不同用途的内存区域。
例如,在典型的 C 程序中:
- 用户代码区域
- 全局变量区域:静态数据(只要程序执行就一直存在)
- 堆区域:动态数据(只要用户不免费就一直存在)
- 堆栈区域
- 库代码区域等
某些区域在执行时可能会增长/缩小。例如,栈区、堆区、库代码区。
很难将不同的区域放置在连续的内存空间中,并且仍然允许它们自由增长/收缩,也很难检查一个区域中的内存访问是否在范围内。
分割方案:基本思想
将区域分成多个内存段:进程的逻辑内存空间现在是内存段segments的集合
每个内存段:有自己的名字name(便于引用),有限制limit(表示内存段的范围)
所有内存引用现在指定为:段名 + 偏移量
分段:逻辑地址转换
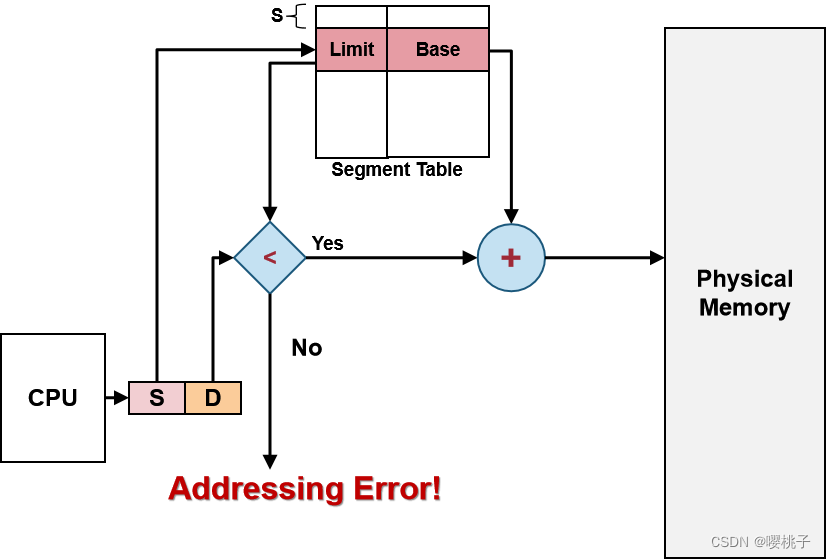
- 每个段都映射到一个连续的物理内存区域,有一个基地址和一个范围限制。
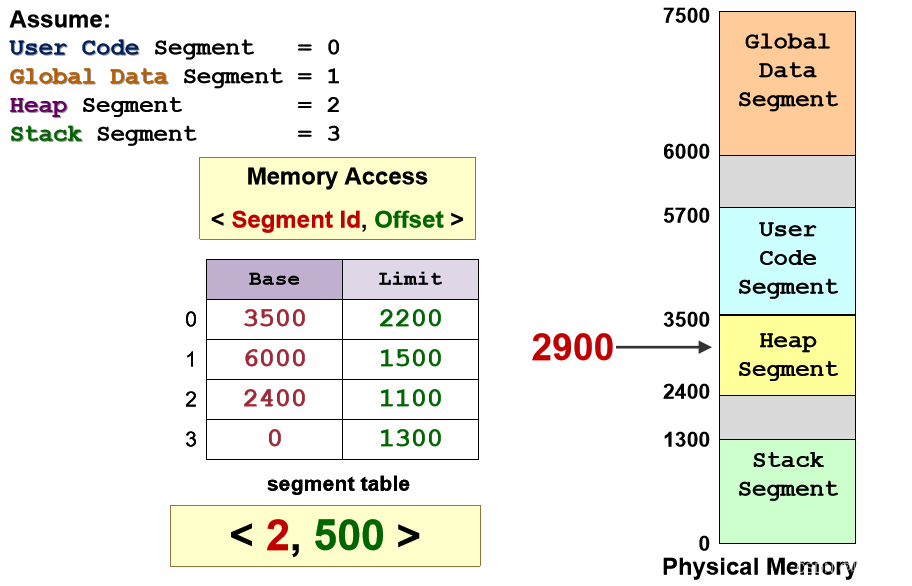
-分段名称通常表示为单个数字,称为段 id - 逻辑地址<SegID, Offset>:
- SegID用于在段表中查找段的<Base, Limit>
- 物理地址 PA = Base + Offset
- 偏移量 < 有效访问上限范围 (这里的limit是最大offset)
硬件支持:
Segementation 优缺点
优点:
每个段是一个独立的连续内存空间
⇒ 可以独立增长/收缩
⇒ 可以独立保护/共享
缺点:
分段需要可变大小的连续内存区域 ⇒ 可能导致外部碎片
Important observation:
分段不等于分页,他们解决不同的问题
分页分割
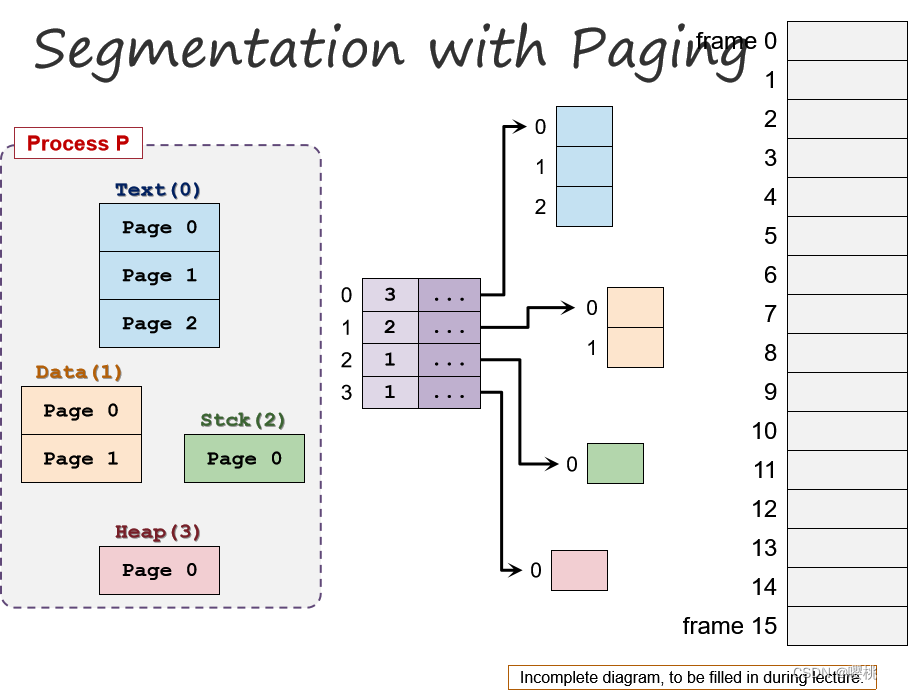
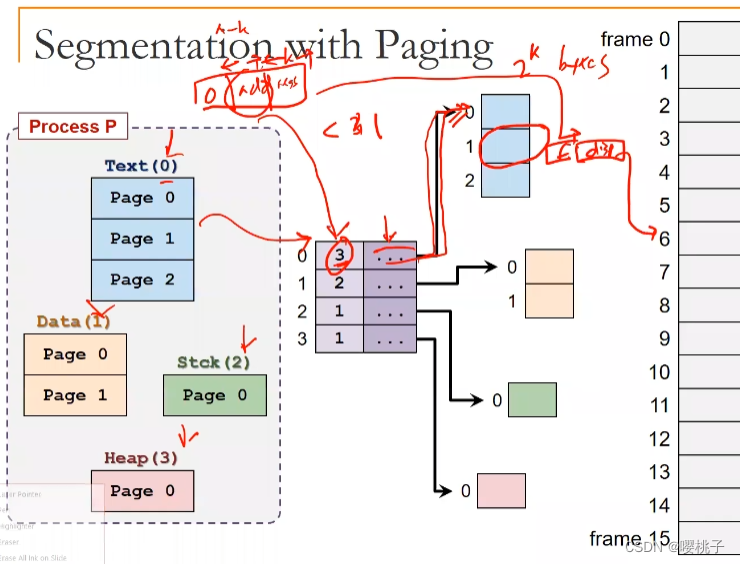
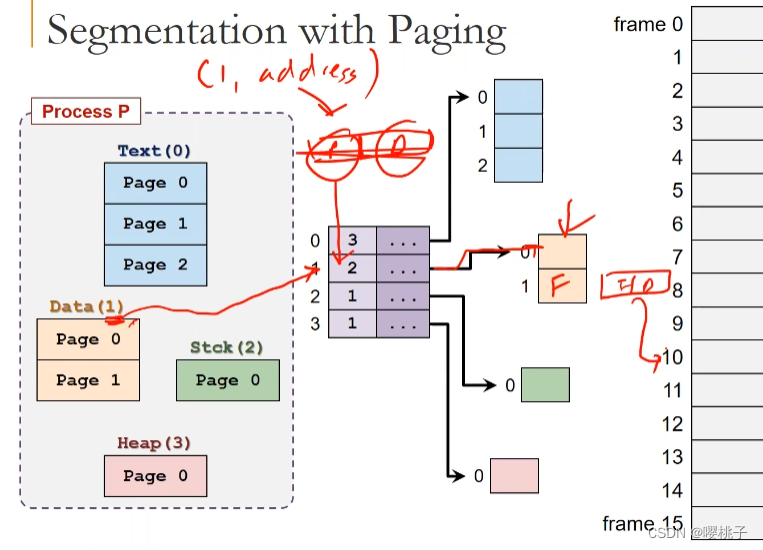
P 好; S也不错;那就S+P吧!
分页分割:基本思想
直观的下一步是将分段与分页结合起来
基本理念:
每个段现在由几个页面而不是一个连续的内存区域组成。本质上,每个段都有一个页表。
内存段可以通过分配新页面来增长,然后添加到它的页表中,收缩也同理。
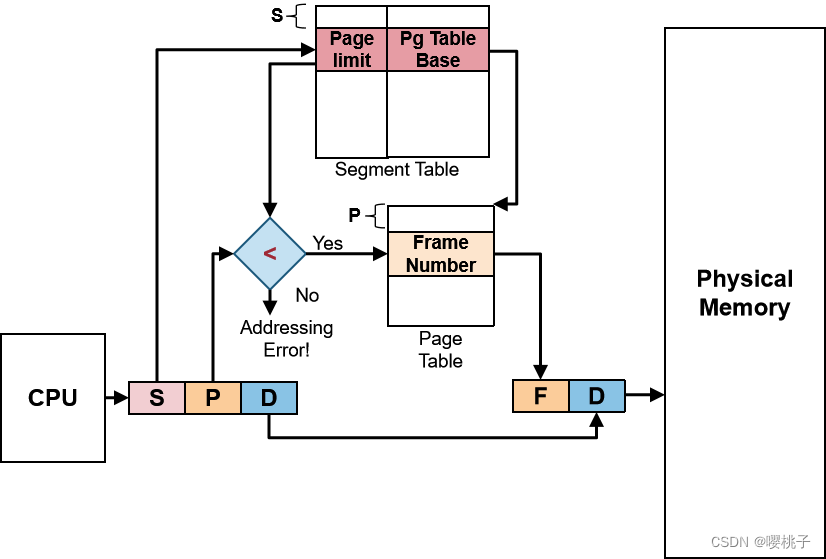
每个segment都有一个page table。
Summary
讨论了两种流行的内存管理方案
两者都允许逻辑地址空间位于分离的物理区域
分页将逻辑地址拆分为固定大小的页面
存储在固定大小的物理内存帧中
分段根据用途将逻辑地址分成可变大小的段
存储在可变大小的物理分区中