个人主页:仍有未知等待探索-CSDN博客
专题分栏: Linux
目录
一、通信
1、进程为什么要通信?
1.数据的类型
2.父进程和子进程算通信吗?
2、进程如何通信?
3、进程通信的常见方式?
二、管道
1、概念
1.管道的4种情况:
2.管道的5种特征:
2、匿名管道
1.为什么父子进程会向同一个显示器终端打印数据?
2.进程默认会打开三个标准输入输出:0,1,2 ?
3.为什么我们子进程主动close(0/1/2),不影响父进程继续使用显示器文件呢?
4.什么是管道文件?
5.管道文件的特点?
6.管道文件结构图
7.父子既然要关闭不需要的fd,那为什么要打开?
8.可以不关不需要的fd吗?
9.如果想双向通信,怎么办?
10.为什么要单向通信?
11.管道的使用(*)
12.read、write的注意点:
read的返回值:
write:
13.命令行中的管道符号:‘ | ’
14.管道多次创建的示意图(*)
3、命名管道
1.原理
2.匿名管道和命名管道的区别
3.怎么保证两个毫不相干的进程,打开了同一个文件呢?
4.命名管道操作 --- 系统调用篇
5.命名管道操作 --- 指令篇
三、管道的项目 --- 进程池
process_pool.cc
task.hpp
Makefile
一、通信
1、进程为什么要通信?
进程也是需要某种协同的,所以如何协同的前提是通信。
1.数据的类型
通知就绪的、单纯的要传递的数据、控制相关的信息...
2.父进程和子进程算通信吗?
答案:不算。
1、一直通信 和 能通信不是同一个概念。
2、父子进程只能读父子进程共享的变量内容,而且还不能进行修改,修改了就会发生写时拷贝,数据不一致。
2、进程如何通信?
进程间通信的前提是:
让两个进程能同时看到同一份资源(也就是操作系统的一段空间)。
因为不同的进程之间互相是独立的,所以不同的进程独自创建的空间,其他进程是不知道的。所以需要第三方的协助(也就是操作系统)。
但是,操作系统不能被用户直接的访问资源,所以操作系统需要提供对应的系统调用。
如果对于下列的图不明白的话,建议去看看进程相关的知识。
这两篇博客讲的都是和进程相关的内容。
Linux 冯诺依曼体系、操作系统、进程概念、进程状态、进程切换-CSDN博客
Linux 进程优先级、程序地址空间、进程控制-CSDN博客

3、进程通信的常见方式?

二、管道
1、概念
1.管道的4种情况:
1、如果管道内部时空的 && write fd没有关闭,读取条件不具备,读进程会被阻塞 --- wait --- 等到读取条件具备 --- 再进行写入 --- 之后再进行读数据。管道空且写未关,读阻塞
2、如果管道被写满 && 不读且没有关闭,写条件不具备,写进程会被阻塞 --- wait --- 等到写条件具备 --- 写入数据。管道满且读未关,写阻塞
3、管道一直在读&&写端关闭了wfd,读端read返回值会读到0,表示读到文件结尾。读且写关闭,读到文件尾,结束
4、rfd直接关闭,写端wfd一直进行写入。这种管道叫broken pipe,os不做浪费时空的事情,os会杀掉对应的进程,给目标发送(13 SIGPIPE)信号。写且读关闭,写进程被杀掉。
2.管道的5种特征:
1、匿名管道:只能用来进行具有父子进程之间通信。(这里的父子进程是泛泛的,爷孙进程也可以)。
2、管道内部,自带进程之间的同步机制。同步:多执行流执行代码的时候,具有明显的顺序性。
3、管道的生命周期是随进程的。
4、管道在通信的时候,是面向字节流的。 write的次数和读取的次数不是一一匹配的。
5、管道的通信模式,是一种特殊的半双工模式。(半双工:在同一时刻,只能有一个方向的数据传输)
2、匿名管道
1.为什么父子进程会向同一个显示器终端打印数据?
因为父子进程代码和数据在没有修改的时候是属于共享的,所以子进程创建的时候,会直接将父进程的task_struct拷贝一份,当然,也包括其中的文件描述符表,所以只要父进程的文件描述符表中存储了标准输入、标准输出、标准错误,子进程也就会有标准输入、标准输出、标准错误。
bash进程可以想象成树形结构的根节点。所以只要将bash的文件描述符表设置好,所有的进程就都会在运行的之后默认打开这三个标准文件。
2.进程默认会打开三个标准输入输出:0,1,2 ?
bash打开了,所有子进程默认也就打开了,我们只需要做好约定即可!
3.为什么我们子进程主动close(0/1/2),不影响父进程继续使用显示器文件呢?
因为,struct file中也有内存级引用计数。
父子同时打开了显示器文件,所以显示器文件的引用计数为2,当关闭了子进程的显示器文件,引用计数减一,只有当引用计数为0的时候,才会释放资源。
struct file -> ref_count; if (ref_count==0) 释放文件资源。
4.什么是管道文件?
管道文件:管道文件是一种特殊的文件,它存在于内存中,而不是磁盘上。它允许一个进程的输出直接作为另一个进程的输入,从而实现进程间的数据交换和协同工作。
5.管道文件的特点?
管道只允许单向通信。
管道文件不需要刷新到磁盘中(所以需要单独设计通信接口)。
6.管道文件结构图

7.父子既然要关闭不需要的fd,那为什么要打开?
为了让子进程继承下去。
8.可以不关不需要的fd吗?
可以,但是建议关闭,因为可能会误写。
9.如果想双向通信,怎么办?
可以建立两个管道。
一个管道,父读子写;一个管道父写子读。
10.为什么要单向通信?
因为简单,并且保证数据的安全性。
公共资源可能会存在被多个进程同时访问的情况。数据不一致问题。比如说子进程写了一半,父进程就开始读。
11.管道的使用(*)
#include <iostream> #include <string> #include <cerrno> // errno.h #include <cstring> // string.h #include <unistd.h> #include <cstdlib> #include <sys/types.h> #include <sys/wait.h> void subprocess_write(int); void fatherprocess_read(int); // 子写父读 int main() { // 创建管道 int pipefd[2] = {0}; int exitcode = pipe(pipefd); std::cout << "pipefd[0]: " << pipefd[0] << " pipefd[1]: " << pipefd[1] << std::endl; // 创建子进程 int id = fork(); // 子写父读 if (id == 0) { std::cout << "子进程关闭不需要的fd, 准备发消息" << std::endl; sleep(1); // child // 关闭其他权限 close(pipefd[0]); // 子进程写 subprocess_write(pipefd[1]); close(pipefd[1]); exit(0); } std::cout << "父进程进程关闭不需要的fd, 准备收消息" << std::endl; sleep(1); // father // 关闭不需要的fd close(pipefd[1]); // 父进程读 fatherprocess_read(pipefd[0]); close(pipefd[0]); pid_t rid = waitpid(id, nullptr, 0); if (rid > 0) { std::cout << "wait sucessfully\n" << std::endl; } return 0; } std::string other() { static int cnt = 0; std::string messageid = std::to_string(cnt); cnt++; std::string stringid = std::to_string(getpid()); std::string message = messageid + " my pid is " + stringid; return message; } void subprocess_write(int wfd) { std::string message = "i am child: "; while (true) { std::string info = message + other(); write(wfd, info.c_str(), info.size());// 写入管道的时候没有写入'\0' sleep(1); } } void fatherprocess_read(int rfd) { char inbuffer[1024] = {0}; while (true) { std::cout << "---------------------------------" << std::endl; ssize_t n = read(rfd, inbuffer, sizeof(inbuffer) - 1); if(n > 0) { inbuffer[n] = 0; std::cout << inbuffer << std::endl; } else if (n == 0) { std::cout << "读端关闭" << std::endl; break; } else { std::cout << "读入失败" << std::endl; break; } } }


12.read、write的注意点:
read的返回值:
- 返回值 > 0,读取成功,且返回值是读取的字节数。
- 返回值 = 0,读取结束。写端关闭,导致读端读到文件尾结束。
- 返回值 < 0,读取失败。
write:
如果每次写的数据的大小 小于 pipe_buf(<= 512Byte,在Linux中是4096Byte),写入操作的过程是原子的。(原子的意思就是不可再分,证明这个操作是线程安全的)
13.命令行中的管道符号:‘ | ’
命令行中的 |,就是匿名管道,‘|’ 左侧命令的stdout 作为 右侧命令的stdin。
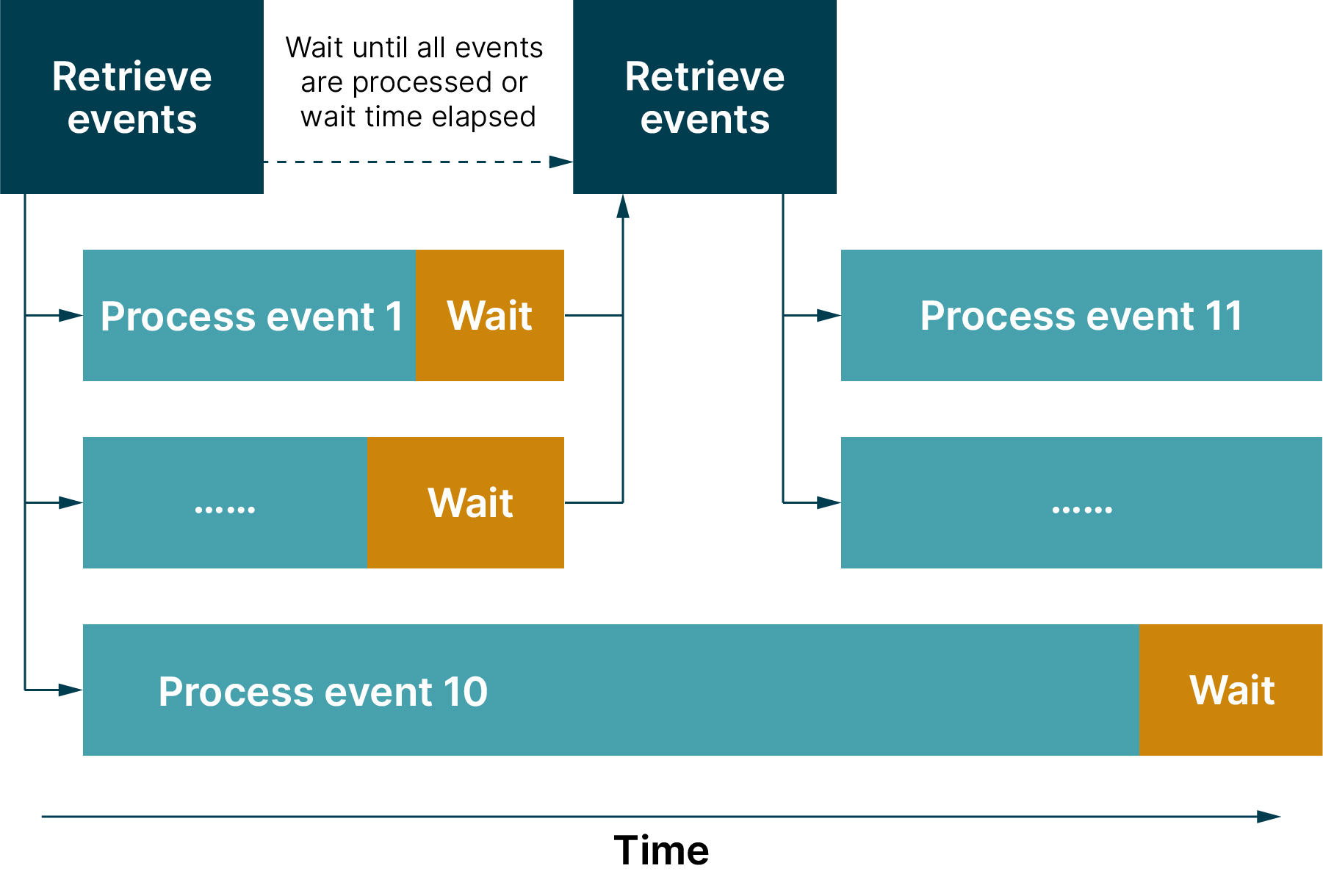
14.管道多次创建的示意图(*)
创建了两个管道:
创建了三个管道:


3、命名管道
1.原理
是不是感觉很眼熟,和匿名管道的文件结构图差不多,其实就是差不多。
只不过这两个管道有一个非常显著的不同。

2.匿名管道和命名管道的区别
- 匿名管道:两个通信的进程之间是有血缘关系的。(父子进程,爷孙进程...)
- 命名管道:两个通信的进程之间没有血缘关系。
- 匿名管道:不需要文件路径。
- 命名管道:需要文件路径。
3.怎么保证两个毫不相干的进程,打开了同一个文件呢?
通过文件的路径来确认。每一个文件,都有文件路径(唯一性)。
4.命名管道操作 --- 系统调用篇

5.命名管道操作 --- 指令篇

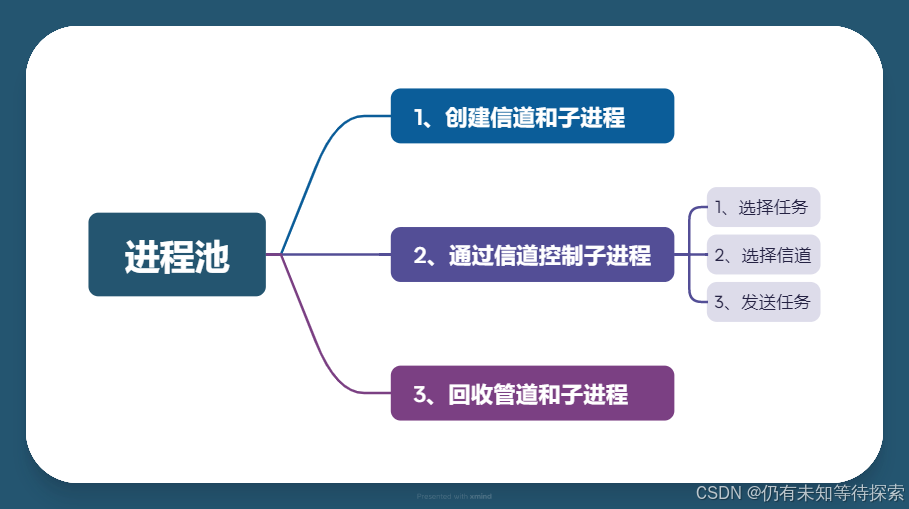
三、管道的项目 --- 进程池
有 n 个管道,n 个任务,要保证每条管道都负载均衡。
process_pool.cc
#include "Task.hpp"
// 父进程写,子进程读
class Channel
{
private:
int _wfd;
int _id;
public:
Channel(int wfd, int id)
: _wfd(wfd), _id(id)
{
}
void close_subprocess()
{
close(_wfd);
}
int get_wfd()
{
return _wfd;
}
int get_id()
{
return _id;
}
};
void work(int rfd);
void create_ChannelAndSubprocess(std::vector<Channel> *channels, int child_number, work_t work);
int next_channel(std::vector<Channel> &channels);
void send_command(Channel &channel, int option_task);
void ctrl_channel(std::vector<Channel> &channels);
void clean_ChannelAndSubprocess(std::vector<Channel> *channels);
int main(int argv, char* argc[])
{
std::vector<Channel> channels;
load_task();
if (argv != 2)
return -1;
int num = std::stoi(argc[1]);
// 1、创建信道和子进程
create_ChannelAndSubprocess(&channels, num, work);
// 2、通过信道控制子进程
ctrl_channel(channels);
// 3、回收管道和子进程
clean_ChannelAndSubprocess(&channels);
return 0;
}
void create_ChannelAndSubprocess(std::vector<Channel> *channels, int child_number, work_t work)
{
for (int i = 0; i < child_number; i++)
{
int pipefd[2] = {0};
int exit_code = pipe(pipefd);
if (exit_code < 0)
{
std::cout << "errno : " << exit_code << std::endl;
exit(1);
}
pid_t id = fork();
if (id == 0)
{
// child;
close(pipefd[1]);
work(pipefd[0]);
exit(0);
}
// father
close(pipefd[0]);
(*channels).emplace_back(pipefd[1], id);
}
std::cout << "创建了:" << channels->size() << "个信道和子进程" << std::endl;
}
int next_channel(std::vector<Channel> &channels)
{
static int count = 0;
int option = count;
count++;
count %= channels.size();
return option;
}
void send_command(Channel &channel, int option_task)
{
write(channel.get_wfd(), &option_task, sizeof(option_task));
}
void ctrl_channel(std::vector<Channel> &channels)
{
// 选择任务
srand(time(nullptr));
int n = task_number;
while (n -- )
{
int option_task = rand() % task.size(); // task[option_task]
// 选择信道
int option_channel = next_channel(channels); // channels[option_task]
// 发送任务
send_command(channels.at(option_channel), option_task);
sleep(1);
}
}
void clean_ChannelAndSubprocess(std::vector<Channel> *channels)
{
for (auto& channel:*channels)
{
channel.close_subprocess();
}
for (auto& channel:*channels)
{
waitpid(channel.get_id(), 0, 0);
}
}task.hpp
#pragma once
#include <iostream>
#include <vector>
#include <string>
#include <cstring>
#include <unistd.h>
#include <cstdlib>
#include <ctime>
#include <sys/types.h>
#include <sys/wait.h>
typedef void (*task_t)();
typedef void (*work_t)(int);
const int size = 4096;
const int task_number = 7;
// 加载
void download()
{
std::cout << "This is a downlaod task!" << std::endl;
}
// 打印
void print()
{
std::cout << "This is a print task!" << std::endl;
}
// 刷新
void flush()
{
std::cout << "This is a flush task!" << std::endl;
}
std::vector<task_t> task;
void load_task()
{
task.push_back(download);
task.push_back(print);
task.push_back(flush);
}
void excute_task(int option_task)
{
if (option_task < 0 || option_task >= task.size())
return;
task.at(option_task)();
}
void work(int rfd)
{
int t = task_number;
int option_task = 0;
int n = read(rfd, &option_task, sizeof(option_task));
if (n > 0)
{
excute_task(option_task);
std::cout << "--------------------------------" << std::endl;
}
}Makefile
process_pool:process_pool.cc
g++ $^ -o $@ -std=c++11
.PHONY:clean
clean:
rm -rf process_pool谢谢大家!