「AI秘籍」系列课程:
- 人工智能应用数学基础
- 人工智能Python基础
- 人工智能基础核心知识
- 人工智能BI核心知识
- 人工智能CV核心知识
- AI 进阶:企业项目实战
可直接在橱窗里购买,或者到文末领取优惠后购买:
可以与任何模型一起使用的所有强大方法
一位[不可知论者]1思考上帝的存在。值得庆幸的是,机器学习还没有达到那种程度。当我们谈论不可知论方法时,我们指的是可以用于任何模型的方法。我们将详细阐述这一定义,重点放在可解释性的不可知论方法上。我们将讨论这些可解释性方法的不同分类。即全局解释与局部解释以及排列与替代模型。有些方法不是与模型无关的。我们将以讨论这些方法作为结束。

模型无关方法
模型无关方法可以应用于任何模型。使用模型无关方法时,模型训练完成后,可以将其视为黑盒。换句话说,该方法不需要我们研究模型的内部工作原理。如果我们想在其他模型上使用该方法,我们只需将它们换掉即可。但是方法要做什么呢?
首先,大多数评估指标与模型无关。以图 1 中的准确度计算为例。我们首先使用模型对测试集进行预测。准确度是正确预测的实际值的百分比。要进行此计算,我们只需将测试数据与预测值进行比较。有些模型可能比其他模型更准确,但计算结果相同。其他评估指标(如准确率、召回率和 MSE)都与模型无关。
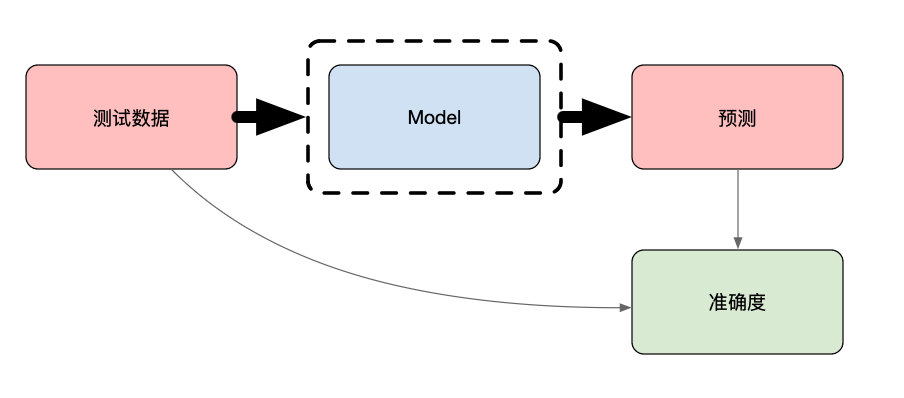
模型无关评估方法在模型选择方面提供了灵活性。你不必为每种模型类型开发不同的评估框架。这还允许你使用相同的指标比较许多模型。当你想要比较模型性能时,这种一致性至关重要。
可解释的机器学习
在实践中,将评估指标称为模型不可知论并不常见。当我们谈论可解释的 ML 或可解释的 AI 方法时,这个术语最为突出。这些方法用于了解模型如何进行预测。我们将讨论这些方法的一些示例以及如何对它们进行分类/分组。在本节结束时,我们将讨论一些方法在理论上是不可知论的,但在实践中并非总是如此。
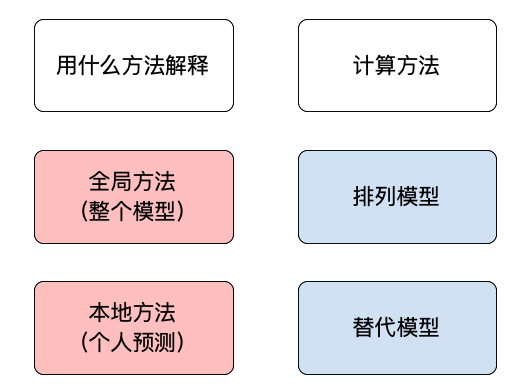
全局方法与本地方法
我们对模型不可知论方法进行分类的第一种方法是根据它们试图解释的内容。局部解释旨在了解个体预测是如何做出的。这就是每个模型特征如何改变预测。我们可以使用全局解释来解释模型如何整体地进行预测。这意味着我们只能对所有预测的趋势做出断言。
为了更好地理解这一点,我们在图 2 中提供了一个部分依赖图 (PDP) 的示例。这是一种常见的全局可解释性方法。此图是用于预测二手车价格的模型创建的。在 x 轴上,我们列出了对汽车进行的维修次数。y 轴(部分 yhat)给出了平均预测价格。由此我们可以看出,汽车价格往往与维修次数呈非线性关系。但是,我们不能对每辆汽车都说同样的话。

我们不会详细介绍如何创建这个 PDP。如果你感兴趣,以后我会专门写一篇相关文章《查找并可视化非线性关系》2,文中我打算逐步指导你如何创建图表。并且还会讨论其他全局模型无关方法。那就是相互信息和特征重要性。
使用部分依赖图 (PDP)、互信息和特征重要性分析非线性关系
对于局部解释,SHAP 是一种常用方法。在图 3 中,你可以看到单个预测的 SHAP 瀑布图。这是来自用于预测鲍鱼壳环数的模型。在这里,我们将模型的预测 f(x) 与平均预测 E[f(x)] 进行比较。我们可以看到每个特征对预测的贡献。例如,去壳重量的值使预测的环数增加了 1.81。

因此,我们可以看到 SHAP 是如何用来解释单个预测的。我们还可以汇总 SHAP 值,以了解模型如何整体地进行预测。从这个意义上讲,局部解释和全局解释之间的界限可能会变得模糊。你可以在图 4 中的蜂群图中看到一个示例。在这里,我们绘制了模型做出的所有预测的 SHAP 值。

蜂群图只是我们聚合 SHAP 值的方法之一。
排列模型与替代模型
我们可以对解释方法进行分类的第二种方法是根据它们的计算方式。置换方法涉及更改输入数据并测量模型预测的变化。这就是上面的 PDP 的创建方式。对于每辆汽车,我们更改/置换维修特征值并记录模型预测。然后我们取每个维修值的平均预测。其他方法,如 ICE 图、特征重要性和 SHAP 都是置换方法。
另一种方法是使用替代模型,你可以在图 5 中看到概述。在这里,首先训练一个模型并用于进行预测。然后使用原始模型的预测来训练替代模型。这代替了目标变量。重要的是,替代模型是一种固有可解释的模型。这些模型,如线性回归或决策树,不需要 SHAP/PDP 之类的技术。可以通过直接查看模型的结构或参数来解释它们。
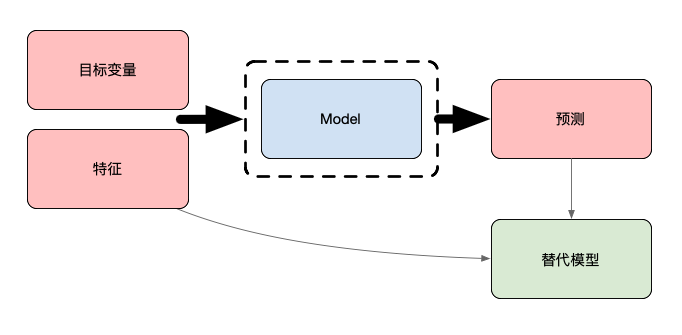
最终,我们可以通过直接解释替代模型来了解原始模型的预测。如果我们对所有预测都这样做,它就被称为全局替代模型。与其他全局方法一样,这些方法可以帮助我们整体理解原始模型。其他方法,如 LIME,可用于创建局部替代模型。它们结合了排列和替代模型来训练单个预测的模型。
原则上与实践上的模型无关
我们讨论的所有方法在理论上都是与模型无关的。要实际使用它们,我们需要实现它们。实现不一定支持所有建模包。例如,Friedman 的 h 统计量是一种用于突出显示模型中重要交互的方法。Python 中没有此方法的与模型无关的实现。据我所知,只有一个针对 scikit-learn 梯度提升模型的实现3。
说到 SHAP,另一个需要考虑的问题是,存在不同的近似值方法。KernelSHAP 是一种真正的模型无关方法。但是,它比 TreeSHAP 慢得多。缺点是 TreeSHAP 只能与基于树的算法一起使用。这意味着,如果你想节省时间,你需要将自己限制在这些算法上。
使用 SHAP,还可以扩展该方法。也就是说,特征的贡献可以分解为其主要效应和交互效应。这使我们能够分析数据中的交互作用。但是,此方法的实现仅适用于基于树的算法。这是因为我们上面提到的计算成本。KernelSHAP 需要很长时间才能近似主要效应和交互效应。
非不可知论方法
不可知论方法的好处在于它们很常见。但仍有一些方法只能用于特定模型。首先,我们上面提到了固有可解释的模型。这些可以直接解释。然而,解释它们的确切方式将取决于你使用的模型。
我们在以前的文章《使用 Python 创建你的第一个情绪分析模型》中有一个示例。我们在这里建立了一个模型来预测推文的情绪。这是使用词袋方法和支持向量机 (SVM) 完成的。在训练 SVM 的过程中,训练集中的每个 N-gram 都被赋予权重。我们通过查看这些权重来解释 SVM。
你可以在图 6 中看到这些权重的一些示例。具有正权重的 N-gram 与积极情绪相关。换句话说,如果推文包含其中一个词,我们更有可能预测积极情绪。同样,具有负权重的词与消极情绪相关。也存在没有相关情绪的词的情况。

以这种方式解释 SVM 是一种非不可知论方法。我们无法以这种方式解释决策树或随机森林等模型。这是因为它们没有参数权重。同样,它不适用于神经网络。这些模型可能有参数权重,但它们太复杂了,无法以这种方式可视化。
对于本质上不可解释的模型,还开发了非不可知方法。由于深度学习的成功,这在神经网络中最为常见。其中一些方法包括逐像素分解和deepLIFT4。最终,这些方法只能用于神经网络。在某些情况下,它们只能用于特定的神经网络架构。
希望这篇文章对你有所帮助!你还可以阅读我的其他文章,或者查看有关企业 AI 实战项目的教程,相信会让你拥有更多收获。

参考
M.T. Ribeiro, S. Singh, and C. Guestrin, Model-agnostic interpretability of machine learning (2016) https://arxiv.org/abs/1606.05386
C. Molnar, Interpretable Machine Learning (2021) https://christophm.github.io/interpretable-ml-book/shap.html
Hennie de Harder Model-Agnostic Methods for Interpreting any Machine Learning Model (2020) https://towardsdatascience.com/model-agnostic-methods-for-interpreting-any-machine-learning-model-4f10787ef504
不可知论,维基百科, https://zh.wikipedia.org/wiki/%E4%B8%8D%E5%8F%AF%E7%9F%A5%E8%AE%BA ↩︎
《查找并可视化非线性关系》,日后计划 ↩︎
梯度提升模型的实现, https://pypi.org/project/sklearn-gbmi/ ↩︎
DeepLIFT, https://github.com/kundajelab/deeplift ↩︎