1.4.10、内置UDAF函数

1.4.10.1、count
--可以发现count(id)会把id=null的值剔除掉
select count(1),count(*),count(distinct id),count(id) from test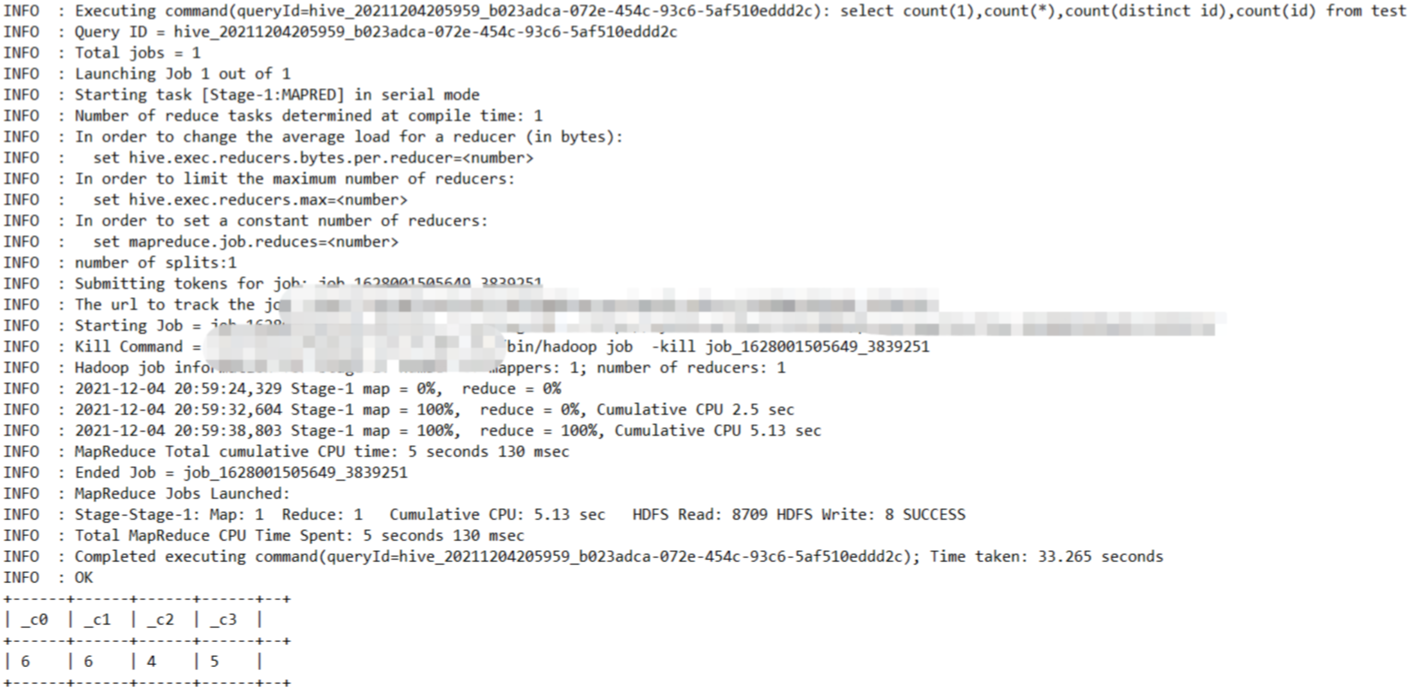
1.4.10.2、sum
select sum(1) from test;
1.4.10.3、avg
该函数太简单了,就不给大家演示了
1.4.10.4、min
该函数太简单了,就不给大家演示了
1.4.10.5、max
该函数太简单了,就不给大家演示了
1.4.10.6、variance
1.4.10.7、var_sample
1.4.10.8、stddev_pop
1.4.10.9、covar_pop
1.4.10.10、covar_samp
1.4.10.11、corr
1.4.10.12、percentile
1.4.10.13、percentile_approx
1.4.10.14、regr_avgx -->Hive2.2.0
1.4.10.15、regr_avgy -->Hive2.2.0
1.4.10.16、regr_count -->Hive2.2.0
1.4.10.17、regr_intercept -->Hive2.2.0
1.4.10.18、regr_r2 -->Hive2.2.0
1.4.10.19、regr_slope -->Hive2.2.0
1.4.10.20、regr_sxx -->Hive2.2.0
1.4.10.21、regr_sxy -->Hive2.2.0
1.4.10.22、regr_syy -->Hive2.2.0
1.4.10.23、histogram_numeric
1.4.10.24、collect_set
select collect_set(id),count(1) from test;
1.4.10.25、collect_list --> Hive0.13.0
select collect_list(id),count(1) from test;
1.4.10.26、ntile --> Hive0.11.0
select
id,
ntile(1) over(partition by id),--分组内的数据切分为1份
ntile(2) over(partition by id),--分组内的数据切分为2份
ntile(3) over(partition by id )--分组内的数据切分为2份
from test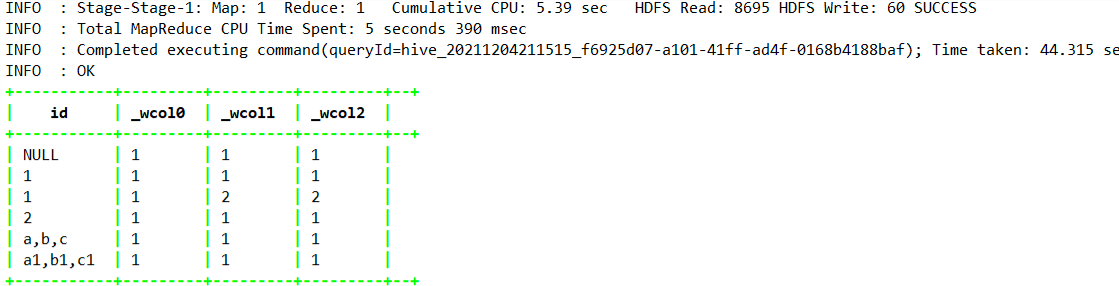
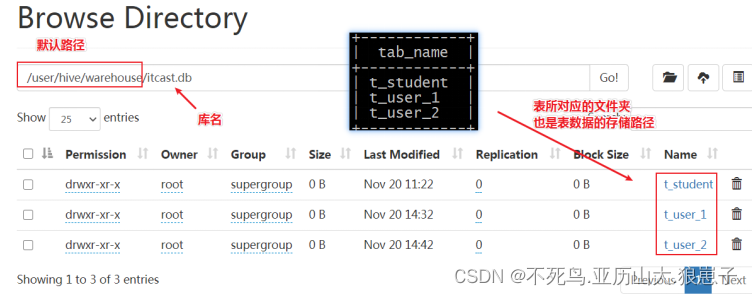
支持版本 | 返回值类型 | 函数名称 | 功能描述 |
BIGINT | count(*), count(expr), count(DISTINCT expr[, expr...]) | count(*) - 返回检索到的总行数,包括包含 NULL 值的行 count(expr) - 返回提供的表达式为非 NULL 的行数. count(DISTINCT expr[, expr]) -返回提供的表达式唯一且非 NULL 的行数。可以使用 hive.optimize.distinct.rewrite 优化此操作的执行. | |
DOUBLE | sum(col), sum(DISTINCT col) | 返回组中元素的总和或组中列的不同值的总和。 | |
DOUBLE | avg(col), avg(DISTINCT col) | 返回组中元素的平均值或组中列的不同值的平均值 | |
DOUBLE | min(col) | 返回组中列的最小值 | |
DOUBLE | max(col) | 返回组中列的最大值。 | |
DOUBLE | variance(col), var_pop(col) | 返回组中数字列的方差 | |
DOUBLE | var_samp(col) | 返回组中数字列的无偏样本方差 | |
DOUBLE | stddev_pop(col) | 返回组中数字列的标准差 | |
DOUBLE | stddev_samp(col) | 返回组中数字列的无偏样本标准差 | |
DOUBLE | covar_pop(col1, col2) | 返回组中一对数值列的总体协方差 | |
DOUBLE | covar_samp(col1, col2) | 返回组中一对数字列的样本协方差 | |
DOUBLE | corr(col1, col2) | 返回组中一对数字列的 Pearson 相关系数 | |
DOUBLE | percentile(BIGINT col, p) | 返回组中列的确切第 p 个百分位数(不适用于浮点类型)。 p 必须介于 0 和 1 之间。注意:只能为整数值计算真正的百分位数。如果您的输入是非整数,请使用 PERCENTILE_APPROX。 | |
array<double> | percentile(BIGINT col, array(p1 [, p2]...)) | 返回组中列的确切百分位数 p1、p2、...(不适用于浮点类型)。 pi 必须介于 0 和 1 之间。注意:只能为整数值计算真正的百分位数。如果您的输入是非整数,请使用 PERCENTILE_APPROX | |
DOUBLE | percentile_approx(DOUBLE col, p [, B]) | 返回组中数字列(包括浮点类型)的近似第 p 个百分位。 B 参数以内存为代价控制近似精度。较高的值会产生更好的近似值,默认值为 10,000。当 col 中不同值的数量小于 B 时,这给出了精确的百分位值 | |
array<double> | percentile_approx(DOUBLE col, array(p1 [, p2]...) [, B]) | 同上,但接受并返回百分位值数组而不是单个值 | |
Hive2.2.0 | double | regr_avgx(independent, dependent) | 相当于 avg(依赖)。从 Hive 2.2.0 开始。 |
Hive2.2.0 | double | regr_avgy(independent, dependent) | 相当于 avg(独立)。从 Hive 2.2.0 开始 |
Hive2.2.0 | double | regr_count(independent, dependent) | 返回用于拟合线性回归线的非空对的数量。从 Hive 2.2.0 开始 |
Hive2.2.0 | double | regr_intercept(independent, dependent) | 返回线性回归线的 y 截距,即等式中 b 的值依赖 = a * independent + b。从 Hive 2.2.0 开始 |
Hive2.2.0 | double | regr_r2(independent, dependent) | 返回回归的决定系数。从 Hive 2.2.0 开始。 |
Hive2.2.0 | double | regr_slope(independent, dependent) | 返回线性回归线的斜率,即等式中 a 的值依赖 = a * independent + b。从 Hive 2.2.0 开始。 |
Hive2.2.0 | double | regr_sxx(independent, dependent) | 相当于 regr_count(independent,dependent) * var_pop(dependent)。从 Hive 2.2.0 开始。 |
Hive2.2.0 | double | regr_sxy(independent, dependent) | 相当于 regr_count(independent,dependent) * covar_pop(independent,dependent)。从 Hive 2.2.0 开始 |
Hive2.2.0 | double | regr_syy(independent, dependent) | 相当于 regr_count(independent,dependent) * var_pop(independent)。从 Hive 2.2.0 开始 |
array<struct {'x','y'}> | histogram_numeric(col, b) | 使用 b 个非均匀间隔的 bin 计算组中数字列的直方图。输出是表示 bin 中心和高度的双值 (x,y) 坐标的大小为 b 的数组 | |
array | collect_set(col) | 返回一组消除了重复元素的对象,可实现去重作用 | |
Hive0.13.0 | array | collect_list(col) | 返回具有重复项的对象列表,(从 Hive 0.13.0 开始。) |
Hive0.11.0 | INTEGER | ntile(INTEGER x) | 将一个有序的分区分成 x 个称为桶的组,并为分区中的每一行分配一个桶号。这允许轻松计算三分位数、四分位数、十分位数、百分位数和其他常见的汇总统计数据。 (从 Hive 0.11.0 开始。) |