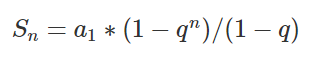自动微分训练模型
简单代码实现:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的线性回归模型
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 输入维度是1,输出维度也是1
def forward(self, x):
return self.linear(x)
# 准备训练数据
x_train = torch.tensor([[1.0], [2.0], [3.0]])
y_train = torch.tensor([[2.0], [4.0], [6.0]])
# 实例化模型、损失函数和优化器
model = LinearRegression()
criterion = nn.MSELoss() # 均方误差损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器
# 训练模型
epochs = 1000
for epoch in range(epochs):
# 前向传播
outputs = model(x_train)
loss = criterion(outputs, y_train)
# 反向传播
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 自动计算梯度
optimizer.step() # 更新模型参数
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
# 测试模型
x_test = torch.tensor([[4.0]])
predicted = model(x_test)
print(f'预测值: {predicted.item():.4f}')
代码分解:
1.定义一个简单的线性回归模型:
LinearRegression 类继承自nn.Module所有神经网络模型的基类 。在 __init__ 方法中,定义了一个线性层 self.linear,它的输入维度是1,输出维度也是1。 forward 方法定义了数据在模型中的传播路径,即输入 x 经过 self.linear 层后得到输出。 class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 输入维度是1,输出维度也是1
def forward(self, x):
return self.linear(x)
2.准备训练数据:
x_train 和 y_train 分别是输入和目标输出的训练数据。每个张量表示一个样本,x_train 中的每个元素是一个维度为1的张量,因为模型的输入维度是1。 x_train = torch.tensor([[1.0], [2.0], [3.0]])
y_train = torch.tensor([[2.0], [4.0], [6.0]])
3.实例化模型,损失函数和优化器:
4.训练模型:
这里进行了1000次迭代的训练过程。 在每个迭代中,首先进行前向传播,计算模型对 x_train 的预测输出 outputs,然后计算损失 loss。 调用 optimizer.zero_grad() 来清空之前的梯度 ,然后调用 loss.backward() 自动计算梯度 ,最后调用 optimizer.step() 来更新模型参数 。 epochs = 1000
for epoch in range(epochs):
# 前向传播
outputs = model(x_train)
loss = criterion(outputs, y_train)
# 反向传播
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 自动计算梯度
optimizer.step() # 更新模型参数
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
5.测试模型:
运行结果:
运行结果如下: