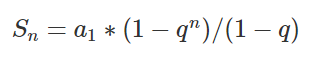综合示例: shell脚本实现查看网站分数
使用编辑器编辑文件jw.sh为如下内容:
#!/bin/bash
save_file="score" # 临时文件
semester=20102 # 查分的学期, 20102代表2010年第二学期
jw_home="http://jwas3.nju.edu.cn:8080/jiaowu" # 测试网站首页地址
jw_login="http://jwas3.nju.edu.cn:8080/jiaowu/login.do" # 登录页面地址
jw_query="http://jwas3.nju.edu.cn:8080/jiaowu/student/studentinfo/achievementinfo.do?method=searchTermList&termCode=$semester" # 分数查询页面地址
name="09xxxxxxx" # 你的账号
passwd="xxxxxxxx" # 你的密码
# 请求jw_home地址, 并从中找到返回的cookie. cookie信息在http头中的JSESSIONID字段中
cookie=`wget -q -O - $jw_home --save-headers | \
sed -n 's/Set-Cookie: JSESSIONID=\([0-9A-Z]\+\);.*$/\1/p'`
# 用户登录, 使用POST方法请求jw_login地址, 并在POST请求中加入userName和password
wget -q -O - --header="Cookie:JSESSIONID=$cookie" --post-data \
"userName=${name}&password=${passwd}" "$jw_login" &> /dev/null
# 登录完毕后, 请求分数查询页面. 此时会返回html页面并输出到标准输出. 我们将输出重定向到文件"tmp"中.
wget -q -O - --header="Cookie:JSESSIONID=$cookie" "$jw_query" > tmp
# 获取分数列表. 因为教务网站的代码实在是实现得不太规整, 我们又想保留shell的风味, 所以用了比较繁琐的sed和awk处理. list变量中会包含课程名称的列表.
list=`cat tmp | sed -n '/<table.*TABLE_BODY.*>/,/<\/table>/p' \
| sed '/<--/,/-->/d' | grep td \
| awk 'NR%11==3' | sed 's/^.*>\(.*\)<.*$/\1/g'`
# 对list中的每一门课程, 都得到它的分数
for item in $list; do
score=`cat tmp | grep -A 20 $item | awk "NR==18" | sed -n '/^.*\..*$/p'`
score=`echo $score`
if [[ ${#score} != 0 ]]; then # 如果存在成绩
grep $item $save_file &>/dev/null # 查找分数是否显示过
if [[ $? != 0 ]]; then # 如果没有显示过
# 考虑到大家可能没有安装notify-send工具, 这里改成echo
# notify-send "新成绩:$item $score" # 弹出窗口显示新成绩
echo "新成绩:$item $score" # 在终端里输出新成绩
echo $item >> $save_file # 将课程标记为已显示
fi
fi
done
运行这个例子需要在命令行中输入bash jw.sh, 用bash解释器执行这一脚本. 如果希望定期运行这一脚本, 可以使用Linux的标准工具之一: cron. 将命令添加到crontab就能实现定期自动刷新.
为了理解这个例子, 首先需要一些HTTP协议的基础知识. HTTP请求实际就是来回传送的文本流——浏览器(或我们例子中的爬虫)生成一个文本格式的HTTP请求, 包括header和content, 以文本的形式通过网络传送给服务器. 服务器根据请求内容(header中包含请求的URL以及浏览器等其他信息), 生成页面并返回.
用户登录的实现, 就是通过HTTP头中header中的cookie实现的. 当浏览器第一次请求页面时, 服务器会返回一串字符, 用来标识浏览器的这次访问. 从此以后, 所有与该网站交互时, 浏览器都会在HTTP请求的header中加入这个字符串, 这样服务器就"记住"了浏览器的访问. 当完成登录操作(将用户名和密码发送到服务器)后, 服务器就知道这个cookie隐含了一个合法登录的帐号, 从而能够根据帐号信息发送成绩.
得到包含了成绩信息的html文档之后, 剩下的事情就是解析它了. 我们用了大量的sed和awk完成这件事情, 同学们不用去深究其中的细节, 只需知道我们从文本中提取出了课程名和成绩, 并且将没有显示过的成绩显示出来.
欢迎关注公众号,与Joker一起探索测试之道。