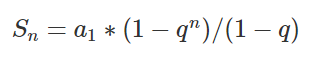前言
这是对Transformer模型的Word Embedding、Postion Embedding内容的续篇。
视频链接:19、Transformer模型Encoder原理精讲及其PyTorch逐行实现_哔哩哔哩_bilibili
文章链接:Transformer模型:WordEmbedding实现-CSDN博客
Transformer模型:Postion Embedding实现-CSDN博客
正文
这里是要构造encoder的self-attention mask,首先介绍一下maks.shape,三维:batch_size, max_src_seg_len, max_src_seg_len,看下去。
首先根据我们src的句子长度,使用torch.ones()生成对应的用1填充的张量:
valid_encoder_pos = [torch.ones(L) for L in src_len][tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]), tensor([1., 1., 1., 1., 1., 1., 1., 1., 1.])]
因为长度不一样,所以需要使用F.pad()填充到长度一致:
valid_encoder_pos = [F.pad(torch.ones(L),(0,max_src_seg_len-L)) for L in src_len][tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.]), tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.])]
然后使用torch.unsqueeze()各扩为二维的张量,这一步是为了后面可以得到一个二维矩阵:
valid_encoder_pos = [torch.unsqueeze(F.pad(torch.ones(L),(0,max_src_seg_len-L)),0) for L in src_len][tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.]]), tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.]])]
使用torch.cat()进行拼接,就得到二维矩阵了:
valid_encoder_pos = torch.cat([torch.unsqueeze(F.pad(torch.ones(L),(0,max_src_seg_len-L)),0) for L in src_len])tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.]])
但是还不够,因为我们要的 maks.shape是三维的,这里只是二维的,我们需要进行扩维,扩第2维,得到2*12*1的张量(batzh_size=2,max_src_seg_len=12):
valid_encoder_pos = torch.unsqueeze(torch.cat([torch.unsqueeze(F.pad(torch.ones(L),(0, max_src_seg_len-L)), 0) for L in src_len]), 2)tensor([[[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[0.]],[[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[0.],
[0.],
[0.]]])
到这一步就可以使用矩阵相乘了,这里这么做的原因是因为公式的要求,我们这里相当于构造了一个Q,之后要乘以K的转置,这里为了方便理解,假设Q就是K,使用torch.bmm()运算:

valid_encoder_pos_matrix = torch.bmm(valid_encoder_pos,valid_encoder_pos.transpose(1,2))tensor([[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],[[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]])
填充的结果是2*12*12,结果也看得出来,src的句子就2个,第一个原先有11位被扩充到12了,所以它自身的内容就是11*11(1的部分就是自身的),第二个句子有9位被扩充到12了,所以它自身的内容就是9*9,但是出来的都是12*12。
【这里放一个我的疑问点,就是encoder的mask都是这样的吗,因为我在看的一个使用bert项目它的mask就是这样的,那Transformer公式里面的Q、K、V这些不用了,啊???我有点疑惑,可能是我真的还没懂,怎么看着跟我看Transformer论文的时候不一样,入门的小白表示很疑惑,之后进一步学习了解一下。】
好,之后要得到bool型的,False表示不需要掩码,True表示要掩码,就需要先得到一个invalid,也就是无效的,内容跟前面的valid刚好相反,直接1-就可以了,然后.to(torch.bool):
invalid_encoder_pos_matrix = 1-torch.bmm(valid_encoder_pos,valid_encoder_pos.transpose(1,2))
mask_encoder_self_attention = invalid_encoder_pos_matrix.to(torch.bool)
tensor([[[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[False, False, False, False, False, False, False, False, False, False, False, True],
[ True, True, True, True, True, True, True, True, True, True, True, True]],[[False, False, False, False, False, False, False, False, False, True, True, True],
[False, False, False, False, False, False, False, False, False, True, True, True],
[False, False, False, False, False, False, False, False, False, True, True, True],
[False, False, False, False, False, False, False, False, False, True, True, True],
[False, False, False, False, False, False, False, False, False, True, True, True],
[False, False, False, False, False, False, False, False, False, True, True, True],
[False, False, False, False, False, False, False, False, False, True, True, True],
[False, False, False, False, False, False, False, False, False, True, True, True],
[False, False, False, False, False, False, False, False, False, True, True, True],
[ True, True, True, True, True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True, True, True, True, True]]])
接下来就是要得到注意力机制的权重概率分布了,首先给出一个假想的score,因为要与encoder的mask匹配,所以同样的三维的。然后对于要掩码的部分进行填充为-1e9,也就是无穷小,这是因为经过softmax之后就变成0了,最后就是使用F.softmax()得到目标注意力机制的权重概率分布:
score = torch.randn(batch_size, max_src_seg_len, max_src_seg_len) # 假想的score
mask_score = score.masked_fill(mask_encoder_self_attention, -1e9) # 掩码的位置填充
prob = F.softmax(mask_score, -1) # 得到注意力权重的概率分布
以下就是假想的score,确实毫无规律可言,毕竟是使用torch.randn()生成的嘛


这里就是掩码的score了,虽然看起来有点乱哈,虽然2个都是12*12,但是还是知道实际有数据含量的也就是11*11和9*9。
tensor([[[ 3.5185e-01, -1.8567e+00, 1.7991e+00, -2.5807e-01, 1.3705e+00, -6.3172e-03, -3.1688e+00, 1.6198e+00, -4.3639e-01, 1.2388e+00, 2.4314e-01, -1.0000e+09], [ 9.2879e-01, -4.8269e-01, -3.2705e-02, 4.1734e-01, -9.0243e-01, -5.4262e-01, -1.8352e-01, 7.9314e-02, 4.9431e-01, -7.9934e-01, 1.6387e+00, -1.0000e+09], [ 2.6967e-01, -1.2333e+00, -6.1750e-01, -1.5155e-01, 4.1788e-01, -1.4133e+00, -7.8446e-02, -2.5991e-02, -7.5509e-01, 7.0632e-01, -2.3135e-01, -1.0000e+09], [ 1.8449e+00, 1.1862e+00, 1.9564e-01, 2.1696e+00, -6.2826e-01, -2.5369e-01, -1.5890e+00, 1.0158e+00, 1.2704e+00, 9.1632e-01, 2.3946e-01, -1.0000e+09], [-1.8323e-01, 1.2978e+00, -7.5807e-01, 3.5337e-01, -5.9706e-02, -6.6573e-02, 1.6678e+00, 1.4584e+00, 6.1482e-01, 3.0707e-01, 6.7967e-01, -1.0000e+09], [-6.2539e-02, 1.5397e+00, 1.5638e+00, -1.5980e+00, 2.7453e-01, -1.0896e-01, -1.5944e+00, -2.7729e-01, -1.0342e+00, -4.3238e-01, 2.9883e+00, -1.0000e+09], [ 9.1462e-01, 4.3064e-01, -2.3169e+00, -1.9580e+00, -5.3637e-01, -9.4548e-01, -4.0131e-01, -1.4772e+00, 1.0383e+00, 3.1411e-01, 5.1660e-01, -1.0000e+09], [-4.6926e-01, 3.6131e-01, 1.1310e-01, 7.1193e-01, -1.4498e+00, -2.0603e-01, -2.0763e+00, 1.2581e+00, -1.2610e-02, 6.7238e-01, -8.1093e-01, -1.0000e+09], [-4.3126e-01, -7.5966e-01, -6.7344e-01, 1.5440e+00, 8.1220e-02, -1.4938e-01, -1.0196e+00, -3.7551e-01, 1.1627e+00, -1.7389e-01, 5.8143e-01, -1.0000e+09], [-2.5140e+00, -1.3095e+00, -3.7930e-02, 1.7673e+00, 6.6269e-01, 9.9375e-02, 4.6851e-01, 1.0931e-01, 6.2925e-02, -6.3525e-01, 1.1961e+00, -1.0000e+09], [-1.6259e+00, -2.8008e+00, -1.9637e-01, -5.9847e-01, -2.3287e-02, 2.3609e-01, -5.5189e-01, -5.1022e-01, 7.7511e-01, -7.4795e-01, 2.2853e-01, -1.0000e+09], [-1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09]], [[ 2.0889e+00, -2.4764e-01, -1.4536e+00, 3.0478e-01, 5.2475e-01, -3.2328e-01, 1.3827e+00, 2.5440e-01, -5.0698e-01, -1.0000e+09, -1.0000e+09, -1.0000e+09], [-4.5635e-01, 1.0401e+00, 1.3199e+00, 1.6464e+00, -1.3669e+00, -1.2365e+00, -1.7893e-01, 7.6988e-01, 2.1611e+00, -1.0000e+09, -1.0000e+09, -1.0000e+09], [-1.4400e+00, -1.0895e-01, -3.4446e-01, -1.2401e+00, -3.7833e-01, -3.5949e-01, 1.1032e+00, -9.7866e-01, 1.3717e-01, -1.0000e+09, -1.0000e+09, -1.0000e+09], [ 2.9807e-01, 3.1396e-01, 9.6897e-01, -2.4864e-01, -3.5340e-01, -2.6608e-01, 1.1089e-01, -1.6505e+00, 1.8138e+00, -1.0000e+09, -1.0000e+09, -1.0000e+09], [ 1.1384e-01, 2.5149e-01, -5.7518e-01, 2.0318e+00, 1.2396e+00, -1.6248e+00, -1.4360e+00, -1.5289e+00, -2.4025e-01, -1.0000e+09, -1.0000e+09, -1.0000e+09], [-7.0956e-02, -1.1549e+00, 1.4916e+00, 1.2946e+00, 1.1741e+00, -1.5321e+00, -8.3102e-01, -1.3340e+00, 5.5966e-01, -1.0000e+09, -1.0000e+09, -1.0000e+09], [-1.8191e+00, 1.0638e-02, -7.9293e-01, 8.9272e-01, -4.1670e-01, -3.8417e-01, 9.4537e-01, 5.8660e-01, -5.2880e-01, -1.0000e+09, -1.0000e+09, -1.0000e+09], [-5.5618e-01, 3.9954e-01, 7.3967e-01, 4.6773e-01, -2.0876e+00, -1.2123e+00, -4.8971e-01, -2.7525e+00, -1.5323e-01, -1.0000e+09, -1.0000e+09, -1.0000e+09], [ 1.2736e-01, 4.9830e-01, 1.0585e+00, -2.5655e-01, -1.9923e+00, -1.3071e-01, 2.0186e-01, -1.5724e+00, -1.4510e-01, -1.0000e+09, -1.0000e+09, -1.0000e+09], [-1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09], [-1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09], [-1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09, -1.0000e+09]]])
这就是最后得到的概率分布了,拿第一个句子来说,前11行的最后1列是0,这是因为它是填充的,所以不必给它信息,把概率分给前面的,最后一行虽然也是因为填充才有的,但是毕竟是整行,要保证每一行的和等于1,所以就均匀给出数值了。


代码
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
# 句子数
batch_size = 2
# 单词表大小
max_num_src_words = 10
max_num_tgt_words = 10
# 序列的最大长度
max_src_seg_len = 12
max_tgt_seg_len = 12
max_position_len = 12
# 模型的维度
model_dim = 8
# 生成固定长度的序列
src_len = torch.Tensor([11, 9]).to(torch.int32)
tgt_len = torch.Tensor([10, 11]).to(torch.int32)
# 单词索引构成的句子
src_seq = torch.cat(
[torch.unsqueeze(F.pad(torch.randint(1, max_num_src_words, (L,)), (0, max_src_seg_len - L)), 0) for L in src_len])
tgt_seq = torch.cat(
[torch.unsqueeze(F.pad(torch.randint(1, max_num_tgt_words, (L,)), (0, max_tgt_seg_len - L)), 0) for L in tgt_len])
# 构造Word Embedding
src_embedding_table = nn.Embedding(max_num_src_words + 1, model_dim)
tgt_embedding_table = nn.Embedding(max_num_tgt_words + 1, model_dim)
src_embedding = src_embedding_table(src_seq)
tgt_embedding = tgt_embedding_table(tgt_seq)
# 构造Pos序列跟i序列
pos_mat = torch.arange(max_position_len).reshape((-1, 1))
i_mat = torch.pow(10000, torch.arange(0, 8, 2) / model_dim)
# 构造Position Embedding
pe_embedding_table = torch.zeros(max_position_len, model_dim)
pe_embedding_table[:, 0::2] = torch.sin(pos_mat / i_mat)
pe_embedding_table[:, 1::2] = torch.cos(pos_mat / i_mat)
pe_embedding = nn.Embedding(max_position_len, model_dim)
pe_embedding.weight = nn.Parameter(pe_embedding_table, requires_grad=False)
# 构建位置索引
src_pos = torch.cat([torch.unsqueeze(torch.arange(max_position_len), 0) for _ in src_len]).to(torch.int32)
tgt_pos = torch.cat([torch.unsqueeze(torch.arange(max_position_len), 0) for _ in tgt_len]).to(torch.int32)
src_pe_embedding = pe_embedding(src_pos)
tgt_pe_embedding = pe_embedding(tgt_pos)
# 构造encoder的mask
valid_encoder_pos = torch.unsqueeze(torch.cat([torch.unsqueeze(F.pad(torch.ones(L),(0,max_src_seg_len-L)),0) for L in src_len]),2)
valid_encoder_pos_matrix = torch.bmm(valid_encoder_pos,valid_encoder_pos.transpose(1,2))
invalid_encoder_pos_matrix = 1-torch.bmm(valid_encoder_pos,valid_encoder_pos.transpose(1,2))
mask_encoder_self_attention = invalid_encoder_pos_matrix.to(torch.bool)
score = torch.randn(batch_size, max_src_seg_len, max_src_seg_len)
mask_score = score.masked_fill(mask_encoder_self_attention, -1e9)
prob = F.softmax(mask_score, -1)